





将文档中的文本对齐可以使整体内容排版整洁有序,对于Word的操作我们都比较熟悉,那么PDF文件中的文本对齐方式要怎么修改呢?
这里我们需要使用到PDF编辑器进行处理,先用极速PDF编辑器打开需要调整的PDF文档(下载安装编辑器后,在PDF文档处右击选择以极速PDF编辑器打开即可)
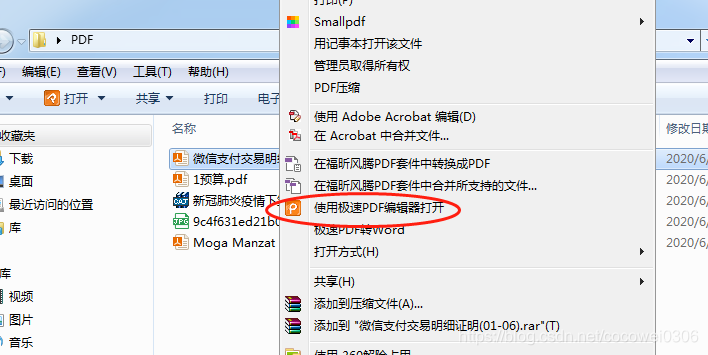
接着选择编辑器工具栏中的“文本工具”就能选中需要操作的文本或段落;
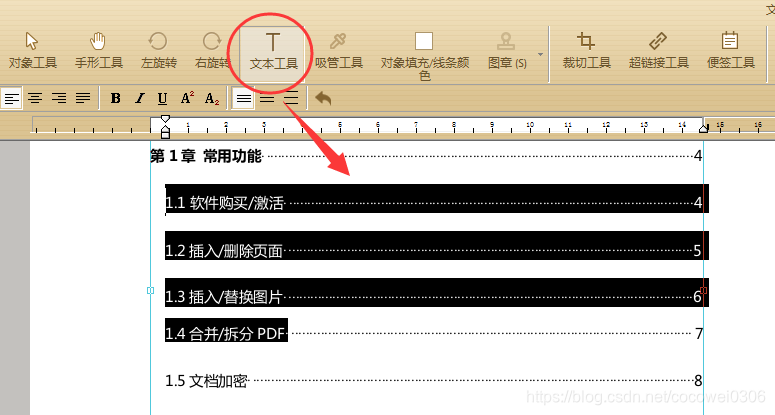
最后在文本处右击选择“文本”,然后在右侧下拉选项中选择一种对齐方式即可。
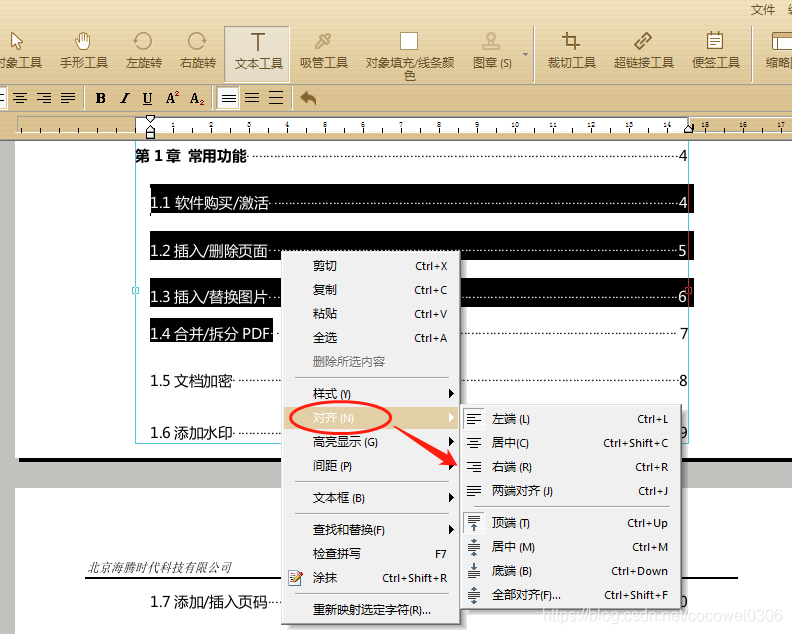
或者点击右上角导航栏中的“文本”—“对齐”也能直接进行操作。
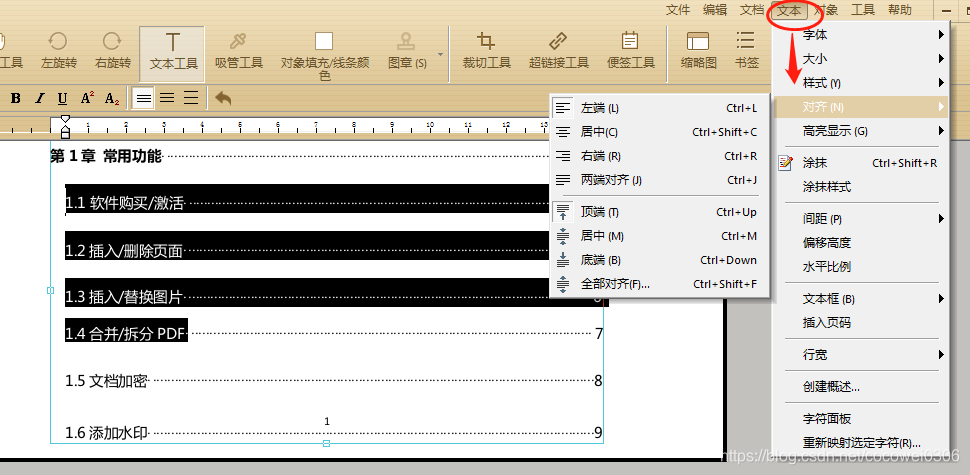

将文档中的文本对齐可以使整体内容排版整洁有序,对于Word的操作我们都比较熟悉,那么PDF文件中的文本对齐方式要怎么修改呢?
这里我们需要使用到PDF编辑器进行处理,先用极速PDF编辑器打开需要调整的PDF文档(下载安装编辑器后,在PDF文档处右击选择以极速PDF编辑器打开即可)
接着选择编辑器工具栏中的“文本工具”就能选中需要操作的文本或段落;
最后在文本处右击选择“文本”,然后在右侧下拉选项中选择一种对齐方式即可。
或者点击右上角导航栏中的“文本”—“对齐”也能直接进行操作。
 9551
425
9551
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























