






 本文介绍如何使用极速PDF编辑器的查找功能,通过输入关键字、设置字符格式化、选择搜索范围及高级查找选项,实现对PDF文档内容的快速定位。
本文介绍如何使用极速PDF编辑器的查找功能,通过输入关键字、设置字符格式化、选择搜索范围及高级查找选项,实现对PDF文档内容的快速定位。
有时我们打开一个PDF文档后,由于页面较多,为了快速查看某一内容,使用查找关键字快速定位是比较方便的,那么应该如何操作才能进行查找呢?
首先用极速PDF编辑器打开文档后,直接使用快捷键“Ctrl+F”就能打开查找设置窗口。
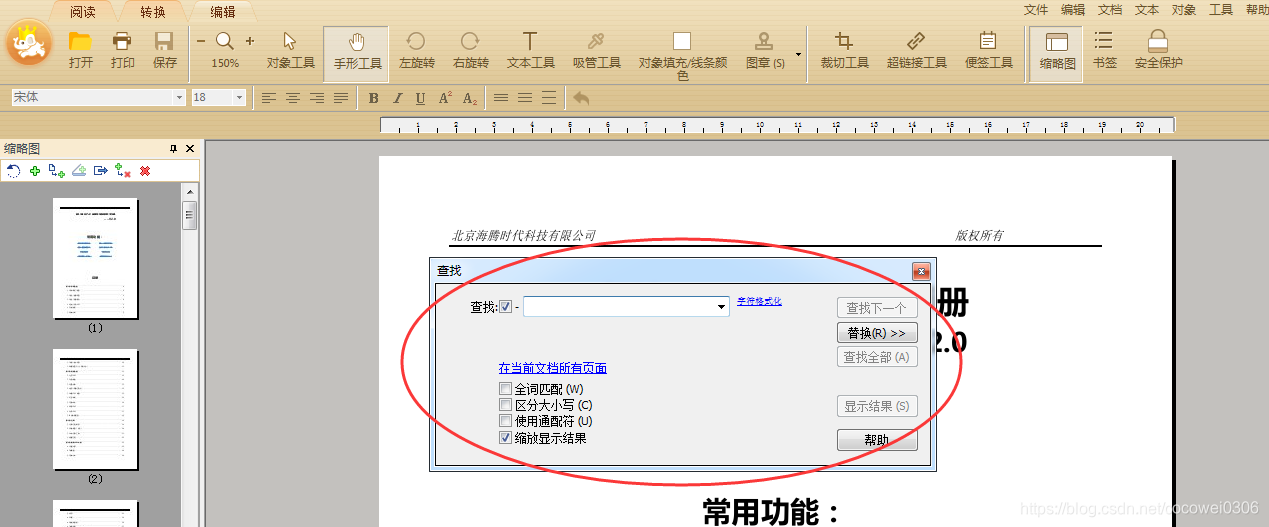
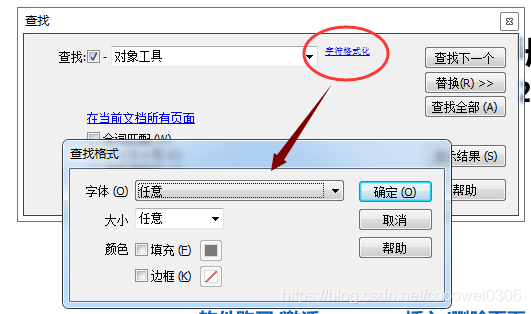
在“查找”输入框输入需要查找的关键字即可;点击右侧“字符格式化”会弹出“查找格式”设置窗口,可根据需求进行字体、字号、填充等更精确的设定来定位查找。
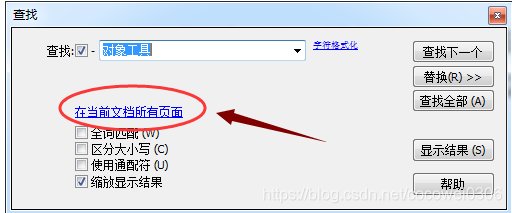
点击在“当前文档所有页面”蓝色字体,可修改搜索的页面范围,根据需求进行相应设置后,点击“确认”。(默认是搜索整个文档所有页面)
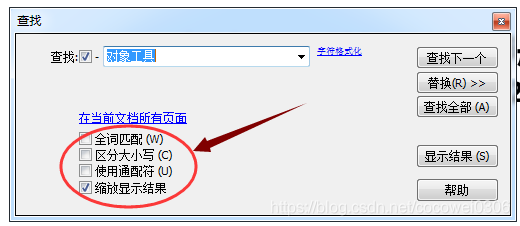
另外还可根据需求选择“全词匹配”/”区分大小写”/”使用通配符”等进行更精确的条件查找,可同时勾选多项,设置完成后点击键盘“enter”开始查找,或设置窗口右侧“查找下一个”或“查找全部”均可。页面会自动跳转,并将查找的关键字黑色高亮显示。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









