







前言
小崖又收到用户投稿啦。今天分享的是构建YashanDB Exporter的核心设计理念和关键方法,希望也能为你的运维实战加分!
背景
在数据库运维工作中,数据库监控是至关重要的一环。常见的数据库监控方案有:Prometheus+Grafana、Zabbix、Nagios等。其中,Prometheus+Grafana是目前业界较为流行的监控解决方案之一,广泛应用于:实时资源监控、监控结果可视化、资源异常告警、监控数据分析等场景。该方案中包含几个关键组件,其核心功能的简要说明如下:

根据上述核心组件的工作原理,我们可以分析出一个完整的监控流程:
-
Exporter负责收集特定的监控指标,并且按特定的格式组织结果;
-
Prometheus Server定时抓取Exporter提供的数据,解析数据并存储;
-
同时,如果指标触发告警条件,Prometheus Server会向Alert Manager推送告警信息;
-
Alert Manager收到推送后对告警进行相应处理,例如:使用短信、邮件等方式通知运维人员;
-
Grafana Server接入Prometheus Server作为数据源,将查询到的监控数据进行可视化展示。
综上所述,本方案中实现YashanDB监控的关键点在于——实现适用于YashanDB的Prometheus Exporter,后续我们称其为:YashanDB Exporter。至于其他组件,均为通用组件,使用官方发布的稳定软件包即可。下面就让我们一起探讨,如何构建YashanDB Exporter。
功能设计
1 整体架构设计
基于Prometheus+Grafana监控YashanDB,整体架构设计图如下。其中YashanDB Exporter可以抓取多个数据库实例的监控指标。Prometheus Server通过拉取YashanDB Exporter的Metrics接口,获取指标数据,并将数据存储到其后台时序数据库TSDB中。其他组件的工作流程在上文的背景中已经说明,在此不再赘述。
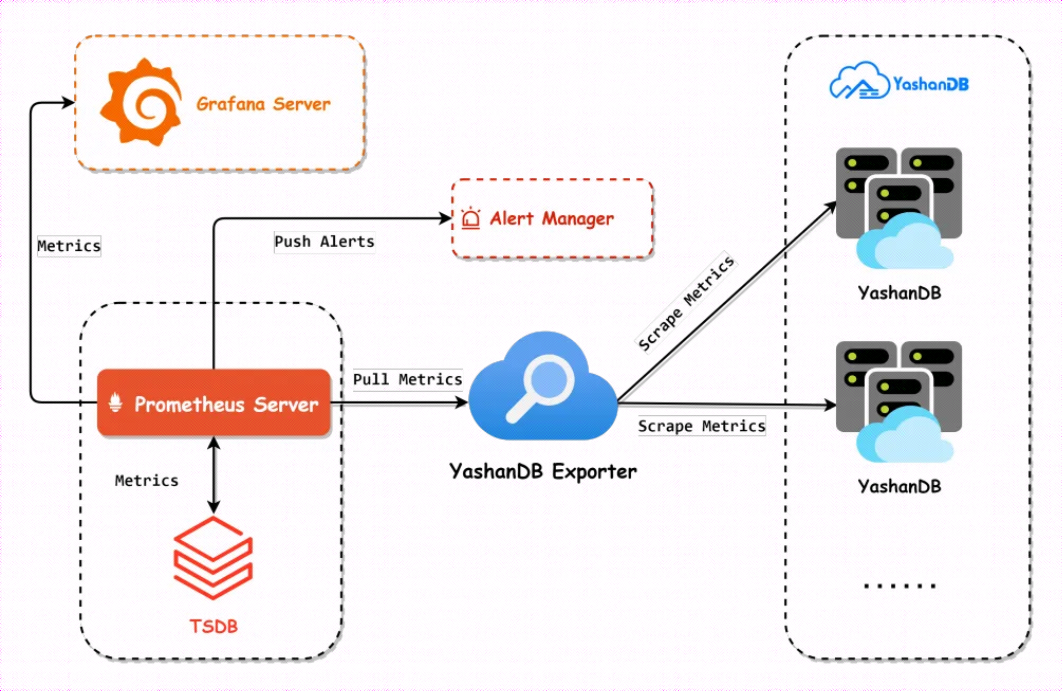
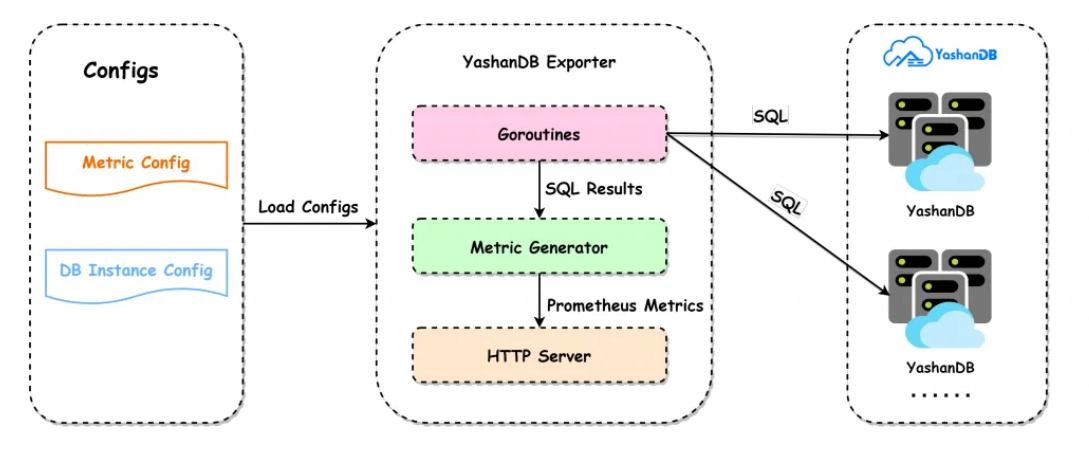
2 YashanDB Exporter架构设计
YashanDB Exporter的功能还是比较简单的,核心工作主要分成三大步骤:采集数据、包装数据以及分享数据。
1.采集数据:主要是借助协程池(Goroutines)并发使用SQL查询数据库的指标信息;
2.包装数据:把数据库的指标结果转换成Prometheus Server能够解析的数据格式(Prometheus Metrics);
3.分享数据:对外提供HTTP服务,外部服务通过请求Metrics接口就能够获取Exporter采集到的数据。
此外,为了灵活控制YashanDB Exporter的行为,我们需要两个配置文件:指标配置文件(Metric Config)和崖山数据库实例配置文件(DB Instance Config)。
1.指标配置文件:定义了用于查询数据的SQL,后续用户也可以通过编辑该文件来控制需要采集的指标;
- 崖山数据库实例配置文件:主要用于定义数据库实例的基本信息和连接信息,控制需要采集哪些数据库实例的信息。整体架构图如下:
背景与挑战
我们可以采用Go语言编码,利用官方提供的github.com/prometheus/client_golang开发包,快速构建YashanDB Exporter。
1. 程序入口
在程序入口中,我们定义了一个名为yashandb_exporter的命令行工具。启动程序时,核心工作流程如下:
1.首先执行必要的初始化工作;
2.其次根据配置,创建一个exporter实例;
3.通过prometheus.MustRegister(exporter)注册实例;
4.定义HTTP服务,将指标处理逻辑绑定到Mertics接口;
- 启动HTTP服务,对外提供Mertics接口。
const servername = "yashandb_exporter"
var (
httpsConfig = kingpinflag.AddFlags(kingpin.CommandLine, ":9100")
pprofAddr = kingpin.Flag(
"web.pprof-address",
"Address to listen on for pprof debug. (env: YAS_EXPORTER_PPROF_ADDRESS)").
Envar("YAS_EXPORTER_PPROF_ADDRESS").String()
metricsURL = kingpin.Flag(
"web.telemetry-path",
"Telemetry path under which to expose metrics. (env: YAS_EXPORTER_TELEMETRY_PATH)").
Default("/metrics").Envar("YAS_EXPORTER_TELEMETRY_PATH").String()
metricsConf = kingpin.Flag(
"yashandb.metrics",
"File with metrics in a YAML file. (env: YAS_EXPORTER_METRICS)").
Default("yashandb-metrics.yml").Envar("YAS_EXPORTER_METRICS").String()
databaseTargets = kingpin.Flag(
"yashandb.targets",
"File with database targets in a YAML file. (env: YAS_EXPORTER_TARGETS)").
Default("yashandb-targets.yml").Envar("YAS_EXPORTER_TARGETS").String()
scrapeTimeout = kingpin.Flag(
"scrape.timeout",
"Scrape timeout (in seconds). (env: YAS_EXPORTER_SCRAPE_TIMEOUT)").
Default("15").Envar("YAS_EXPORTER_SCRAPE_TIMEOUT").Uint()
scrapeMaxConcurrency = kingpin.Flag(
"scrape.max-concurrency",
"Maximum number of concurrent scrape tasks at the same time. (env: YAS_EXPORTER_SCRAPE_MAX_CONCURRENCY)").
Default("512").Envar("YAS_EXPORTER_SCRAPE_MAX_CONCURRENCY").Uint()
logLevel = kingpin.Flag(
"log.level",
"Log level of YashanDB Exporter. One of: [debug, info, warn, error]. (env: YAS_EXPORTER_LOG_LEVEL)").
Default("info").Envar("YAS_EXPORTER_LOG_LEVEL").String()
maxOpenConns = kingpin.Flag(
"max.open.conns",
"Max open connections of database. (env: YAS_EXPORTER_MAX_OPEN_CONNS)").
Default("3").Envar("YAS_EXPORTER_MAX_OPEN_CONNS").Uint()
)
func init() {
commons.InitBasePath()
commons.InitAuth()
}
func generateResponse(code int, message string) []byte {
res := &struct {
Code int `json:"code"`
Message string `json:"message"`
}{Code: code, Message: message}
data, _ := json.Marshal(res)
return data
}
func main() {
kingpin.Version(fmt.Sprintf("%s-%s", servername, commons.Version))
kingpin.HelpFlag.Short('h')
kingpin.Parse()
initLog(*logLevel)
log.Sugar.Infof("Starting %s-%s", servername, commons.Version)
exporterOpts := []collector.ExporterOpt{
collector.WithScrapeMaxConcurrency(*scrapeMaxConcurrency),
collector.WithScrapeTimeout(*scrapeTimeout),
collector.WithMaxOpenConns(*maxOpenConns),
}
exporter, err := collector.NewExporter(*databaseTargets, *metricsConf, exporterOpts...)
if err != nil {
log.Sugar.Fatalf("load configs failed: %s", err)
}
prometheus.MustRegister(exporter)
logger, _ := zap.NewStdLogAt(log.Logger, zap.ErrorLevel)
opts := promhttp.HandlerOpts{
ErrorLog: logger,
ErrorHandling: promhttp.ContinueOnError,
}
mux := http.NewServeMux()
mux.Handle(*metricsURL, promhttp.HandlerFor(prometheus.DefaultGatherer, opts))
mux.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/html; charset=UTF-8")
_, _ = w.Write(generateServerHome(*metricsURL))
})
if *pprofAddr != "" {
go debug.StartHTTPDebuger(*pprofAddr)
}
server := &http.Server{
Handler: mux,
ReadHeaderTimeout: 32 * time.Second,
}
promlogger := promlog.New(&promlog.Config{})
if err := web.ListenAndServe(server, httpsConfig, promlogger); err != nil {
log.Sugar.Fatal("Error running HTTP server:", err)
}
}
2. Collector接口
在3.1小节中,我们通过prometheus.MustRegister(exporter)注册实例后,再通过mux.Handle(*metricsURL, promhttp.HandlerFor(prometheus.DefaultGatherer, opts))就可以完成Metrics接口的构建。其中的关键在于如何实现exporter实例。通过查看prometheus.MustRegister函数,发现其参数是一个Collector接口,那么我们的exporter实例只需要实现Collector接口即可。接口定义如下:
type Collector interface {
Describe(chan<- *Desc)
Collect(chan<- Metric)
}
接口有两个函数:Describe和Collect。Describe会在prometheus.MustRegister时调用,执行一次标准的采集动作。而Collect则会在收到Metrics接口请求的时候调用,执行一次标准的采集动作。从Exporter的功能上来说,关键点在于Collect,而Describe就算不做任何事情也不会影响整体的功能。所以我们可以聚焦Collect函数,代码内容如下:
func (e *Exporter) Describe(ch chan<- *prometheus.Desc) {}
func (e *Exporter) Collect(ch chan<- prometheus.Metric) {
e.mu.RLock()
yashandbList := e.originalYashandbList.DeepCopy()
metricList := e.originalMetricList.DeepCopy()
e.mu.RUnlock()
e.scrape(ch, yashandbList, metricList)
e.sendInstanceDisconnected(ch, yashandbList)
ch <- e.duration
ch <- e.totalScrapes
ch <- e.success
e.scrapeErrors.Collect(ch)
ch <- e.up
}
可以看到,关键在于e.scrape(ch, yashandbList, metricList)。传入的参数有三个:指标信息接收通道(ch)、YashanDB实例列表(yashandbList)以及采集的指标列表(metricList)。展开分析该函数:
func (e *Exporter) scrape(ch chan<- prometheus.Metric, yashandbList *YashanDBList, metricList *MetricList) {
e.reset()
e.totalScrapes.Inc()
e.up.Set(1)
defer func(begun time.Time) {
s := time.Since(begun).Seconds()
e.duration.Set(s)
log.Sugar.Debugf("scrape total time: %0.4fs", s)
}(time.Now())
scrapeSuccess := true
swg := sizedwaitgroup.New(int(e.scrapeMaxConcurrency))
for _, yashandb := range yashandbList.YashanDBs {
for _, i := range yashandb.ScrapeInstances {
for _, m := range metricList.Metrics {
swg.Add()
go e.scrapeWithMetric(&swg, ch, yashandb, i, m, &scrapeSuccess)
}
}
}
swg.Wait()
if scrapeSuccess {
log.Sugar.Debug("scrape all metrics successfully")
e.success.Set(1)
}
}
func (e *Exporter) scrapeWithMetric(
swg *sizedwaitgroup.SizedWaitGroup,
ch chan<- prometheus.Metric,
yashandb *YashanDB,
scrapeInstance *ScrapeInstance,
metric *YasMetric,
scrapeSuccess *bool,
) {
defer swg.Done()
start := time.Now()
if err := metric.Scrape(yashandb, scrapeInstance, ch, e); err != nil {
*scrapeSuccess = false
log.Sugar.Errorf("%0.4fs %s failed to scrape <%s>: %s", time.Since(start).Seconds(), scrapeInstance.Mark(), metric.Name, err)
return
}
if len(metric.SubMetrics) == 1 {
log.Sugar.Debugf("%0.4fs %s succeeded to scrape <%s>", time.Since(start).Seconds(), scrapeInstance.Mark(), metric.Name)
} else {
for _, sub := range metric.SubMetrics {
log.Sugar.Debugf("%0.4fs %s succeeded to scrape <%s_%s>", time.Since(start).Seconds(), scrapeInstance.Mark(), metric.Name, sub.ColName)
}
}
}
上述代码中,采用了一个拥有最大并发数控制的协程池,对于每个数据库下每个实例的每个指标,都使用协程去并发采集数据。由此可见,一次采集所需的时间就是所有协程中耗时最长的协程的采集时间。根据代码我们可以看到,具体的采集操作是由metric.Scrape(yashandb, scrapeInstance, ch, e)函数执行的。查看函数的具体内容如下:
func (m *YasMetric) Scrape(yashandb *YashanDB, i *ScrapeInstance, ch chan<- prometheus.Metric, e *Exporter) error {
if i.genQuery(m) == "" {
log.Sugar.Debugf("%s, skip empty query", m.Name)
return nil
}
if err := i.Query(yashandb, m, ch, e.scrapeTimeout); err != nil {
i.scrapeFailedOnce = true
return err
}
i.scrapeSuccessOnce = true
return nil
}
可以看到,核心功能在于i.Query(yashandb, m, ch, e.scrapeTimeout),查看Query函数的相关内容如下所示。在该函数中,主要是使用YashanDB的Go语言驱动,通过SQL查询数据库信息,并把它转换成Prometheus Metric格式。最后把采集的指标通过i.exposeMetrics(yashandb, ch, prometheusMetrics)发送到指标信息接收通道。其中还引入了超时机制,如果本次查询达到最大超时时间,则终止查询,指标采集失败,协程超时返回。这样可以有效控制Metrics接口的返回时间,避免接口长时间无法返回数据。
func (i *ScrapeInstance) Query(yashandb *YashanDB, m *YasMetric, ch chan<- prometheus.Metric, timeout uint) error {
var prometheusMetrics []prometheus.Metric
errCh := make(chan error)
done := make(chan struct{})
defer close(done)
go func() {
defer func() {
if err := recover(); err != nil {
log.Sugar.Errorf("recover error: %v", err)
log.Sugar.Warnf("debug stack warn: %s", string(debug.Stack()))
}
}()
var err error
defer func() {
select {
case <-done:
case errCh <- err:
}
close(errCh)
}()
query := i.genQuery(m)
if query == "" {
return
}
ctx, cancel := context.WithTimeout(context.Background(), time.Second*time.Duration(timeout))
defer cancel()
rows, err := i.db.QueryContext(ctx, query)
if err != nil {
return
}
defer rows.Close()
err = rows.Err()
if err != nil {
return
}
cols, err := rows.Columns()
if err != nil {
return
}
result := []map[string]string{}
for rows.Next() {
columnData := make([]interface{}, len(cols))
scanArgs := make([]interface{}, len(cols))
for i := range columnData {
scanArgs[i] = &columnData[i]
}
err = rows.Scan(scanArgs...)
if err != nil {
return
}
row := make(map[string]string)
for i, colName := range cols {
if columnData[i] == nil {
columnData[i] = ""
}
row[strings.ToLower(colName)] = fmt.Sprintf("%v", columnData[i])
}
result = append(result, row)
}
for _, row := range result {
metrics, err := m.genPrometheusMetrics(yashandb, i, row)
if err != nil {
return
}
prometheusMetrics = append(prometheusMetrics, metrics...)
}
}()
select {
case err := <-errCh:
if err != nil {
return err
}
i.exposeMetrics(yashandb, ch, prometheusMetrics)
return nil
case <-time.After(time.Second * time.Duration(timeout)):
return errors.New("query timeout")
}
}
至此,我们已经完整个Exporter的核工作原理介绍:通过配置文件控制需要监控的指标以及数据库实例;再通过实现Collector接口,利用prometheus.MustRegister(exporter)注册完成后,通过promhttp.HandlerFor(prometheus.DefaultGatherer, opts)快速构建一个Metrics接口处理器;最后将处理器绑定到HTTP服务上,并启动服务即可。
3. 配置文件说明
配置文件其实就是一些数据结构的设计和简单的数据输入,能够获取到需要的数据即可。本方案中设计的配置文件示例如下:
指标配置文件示例如下,在配置文件中我们定义了数据库启动时间和数据库最大会话数两个简单指标。实际使用时,可以通过配置文件内置所需的监控指标,也可以后续增加自定义指标。
metrics:
- name: uptime
query: select EXTRACT(DAY FROM (sysdate - startup_time)) * 60 * 60 * 24 +
EXTRACT(HOUR FROM (sysdate - startup_time)) * 60 * 60 +
EXTRACT(MINUTE FROM (sysdate - startup_time)) * 60 +
EXTRACT(SECOND FROM (sysdate - startup_time)) AS uptime
from v$instance
sub_metrics:
- col: uptime
type: gauge
description: Uptime of the database instance (in seconds).
- name: max_sessions
query: select value as max_sessions from sys.v$parameter where name = 'MAX_SESSIONS'
sub_metrics:
- col: max_sessions
type: gauge
description: Maximum number of database sessions.
数据库实例配置文件示例如下,在配置文件中我们定义了一个名为yasdb的数据库,其拥有两个数据库实例:
targets:
- type: SE
name: yasdb
pkgVersion: 23.2.0.13
nodes:
- id: 1-1
type: yasdn
group: "1"
name: instance1
connection:
ip: 127.0.0.1
port: 1688
- id: 1-2
type: yasdn
group: "1"
name: instance2
connection:
ip: 127.0.0.1
port: 1690
结果展示
1.首先部署YashanDB,我们快速部署一个单机单节点数据库,实例的监听地址设置为:127.0.0.1:1688。
2.然后编辑数据库实例配置文件,设置好数据库地址等信息。接着在9100端口启动YashanDB Exporter,此时访问Metrics接口已经可以看到采集到的数据库信息:

3.随后,我们可以通过docker快速拉起Prometheus Server和Grafana Server。先拉取docker镜像:
docker pull prom/prometheus
docker pull grafana/grafana
4.启动Prometheus Server:
# 生成配置文件
mkdir /opt/prometheus
cd /opt/prometheus/
vim prometheus.yml
# 键入以下内容并保存
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090'] # Prometheus服务本身
labels:
instance: prometheus
- job_name: yashandb_exporter
static_configs:
- targets: ['127.0.0.1:9100'] # YashanDB Exporter服务
labels:
instance: localhost
# 在9090端口启动服务
docker run -d \
-p 9090:9090 \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
5.启动Grafana Server:
# 新建空文件夹grafana-storage
mkdir /opt/grafana-storage
# 设置权限,测试环境设置777,比较简单粗暴!
chmod 777 -R /opt/grafana-storage
# 在3000端口启动服务
docker run -d \
-p 3000:3000 \
--name=grafana \
-v /opt/grafana-storage:/var/lib/grafana \
grafana/grafana
6.访问3000端口登录Grafana Server,初始用户名和密码均为:admin。
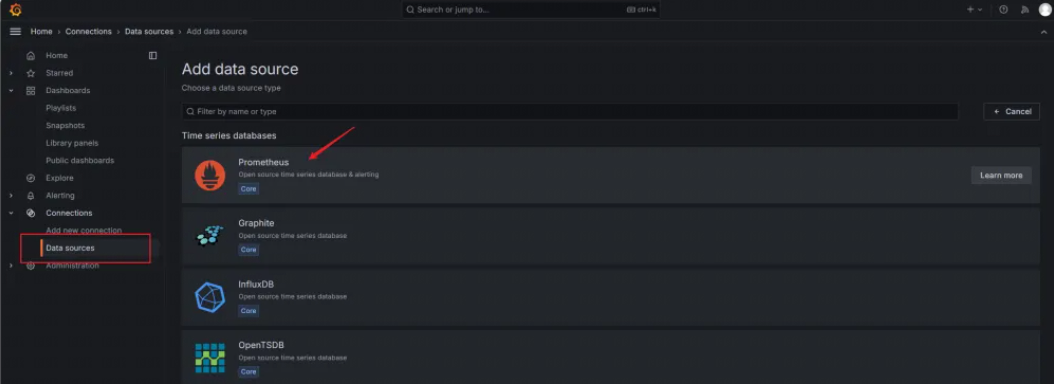
7.配置Grafana Server的数据源,选择Prometheus。根据我们前面的配置,其在9090端口运行:

8.添加Dashboard,以监控数据库实例的启动时间(yashandb_uptime)为例:
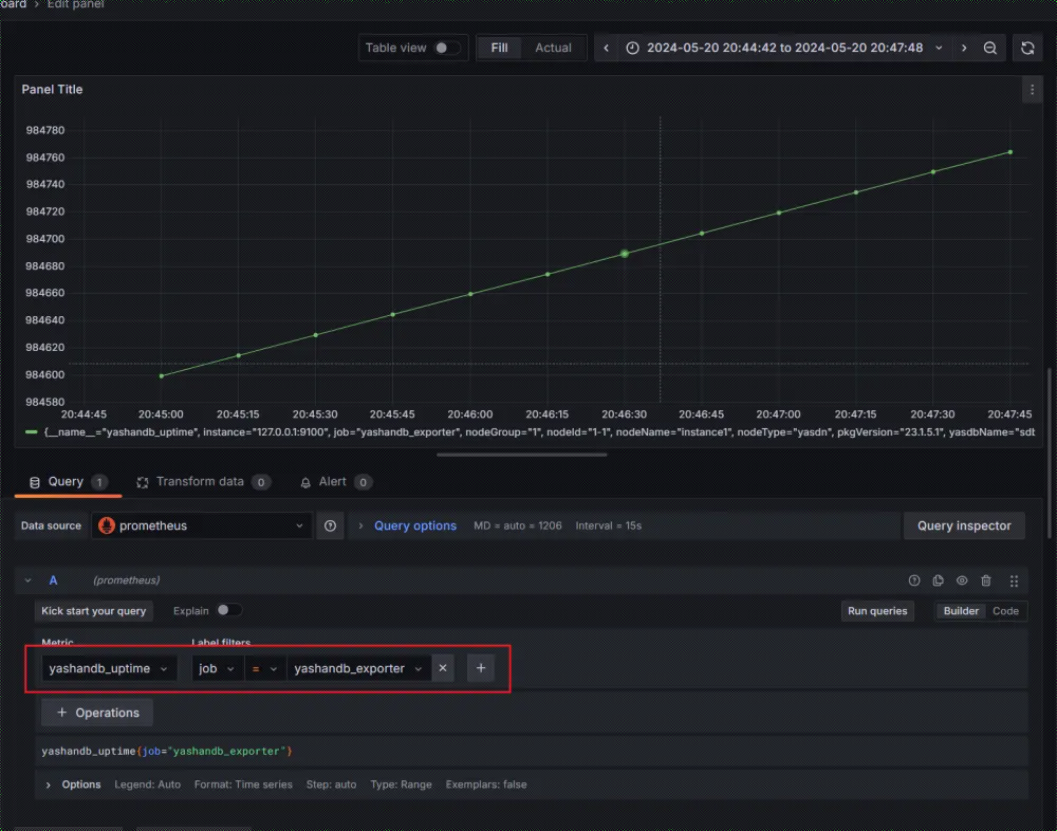
以上就是我通过第三方开发包快速搭建YashanDB Exporter的实战记录啦。YashanDB作为近年来关系数据库领域的后起之秀,其数据库生态也在不断蓬勃发展中。欢迎小伙伴们一起来探讨学习,共同摸索更多运维的高效方法。















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









