







【标题】主备延迟故障分析方法
【问题分类】故障分析
【关键字】Yashandb、主备延迟
【问题描述】当数据库备机出现回放延迟时,需要通过一些手段分析延迟的原因。通过数据库的系统视图或操作系统监控数据可以辅助分析回放延迟的瓶颈。
【问题原因分析】
备延迟手段
当前备库的复制情况

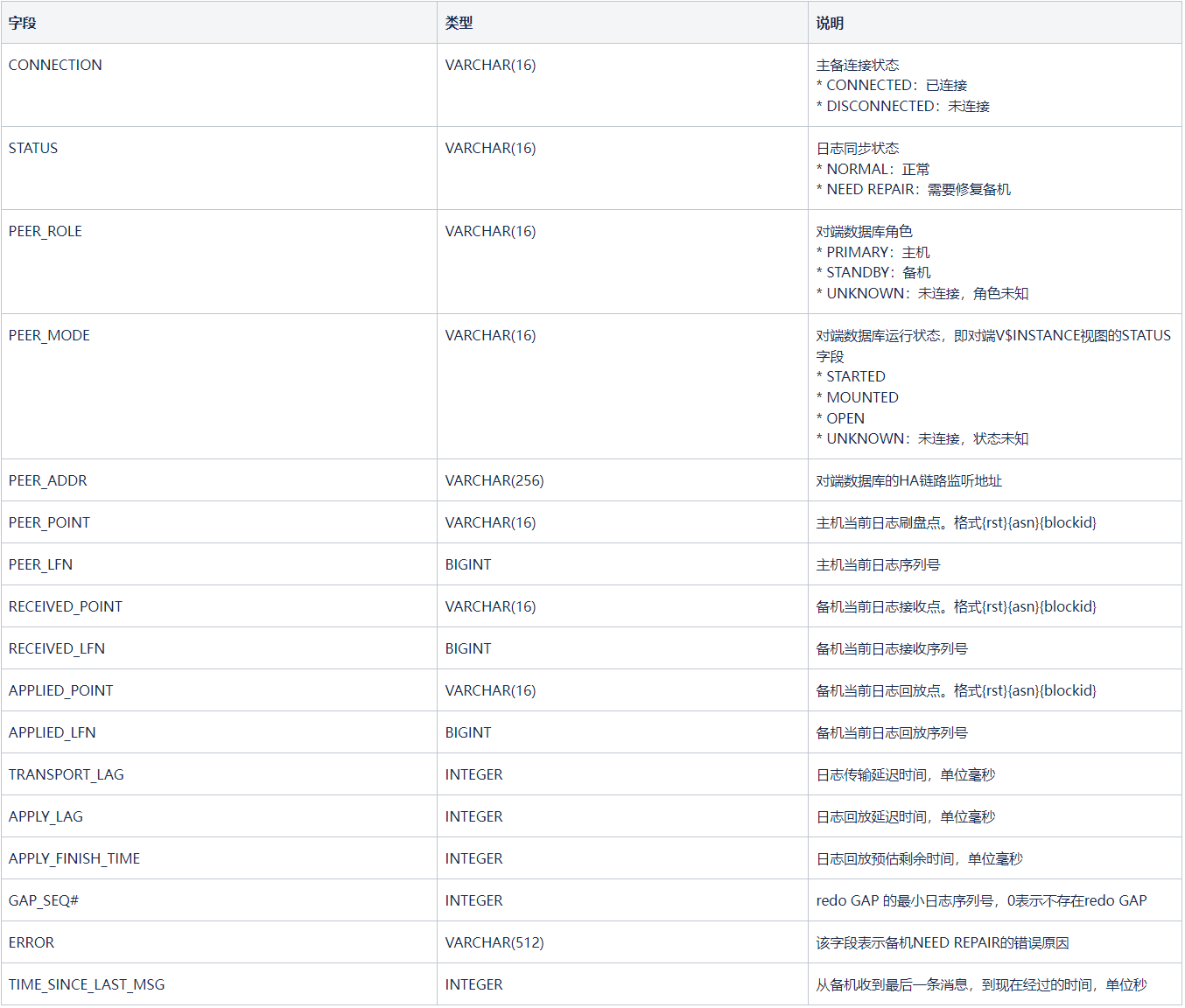
Note:
{rst}{asn}{blockid}
rst:为reset id,每次failover后,数据库新产生的redo文件的reset id会加1。
asn: 归档序列号,archive sequence number,每产生一个redo,ASN会加1,每个redo的ASN不相同。
blockid:redo文件内页面所在ID,页面的偏移量为 block id*block size。
lfn:log flush number,日志序列号,每次redo刷盘,LFN加1。
备机回放进度视图

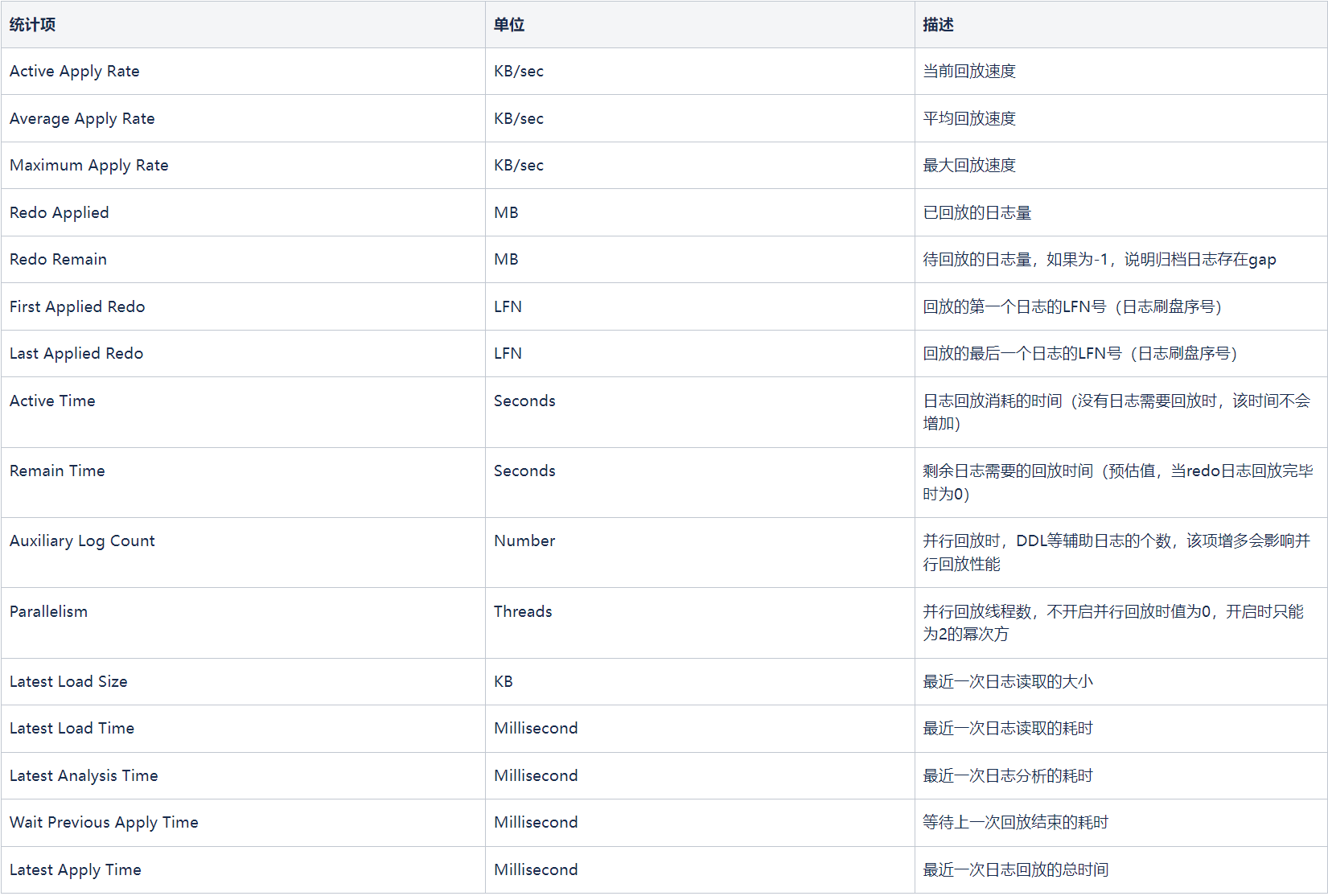
数据库从MOUNT到OPEN阶段,统计的是重启回放信息,视图中Redo Remain项随着回放会减小。主机OPEN后,视图项不再变化。但是备机OPEN后,可能会重置视图内容,并且Redo Remain项和Remain Time项表示当前剩余日志对应的大小和回放时间。
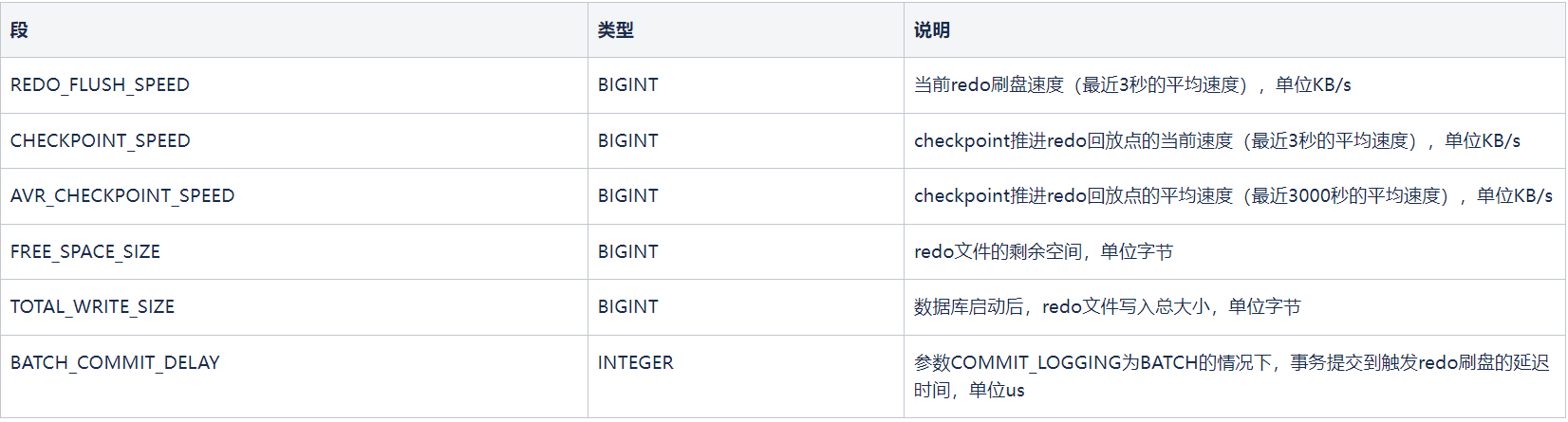
检查redo的落盘速度

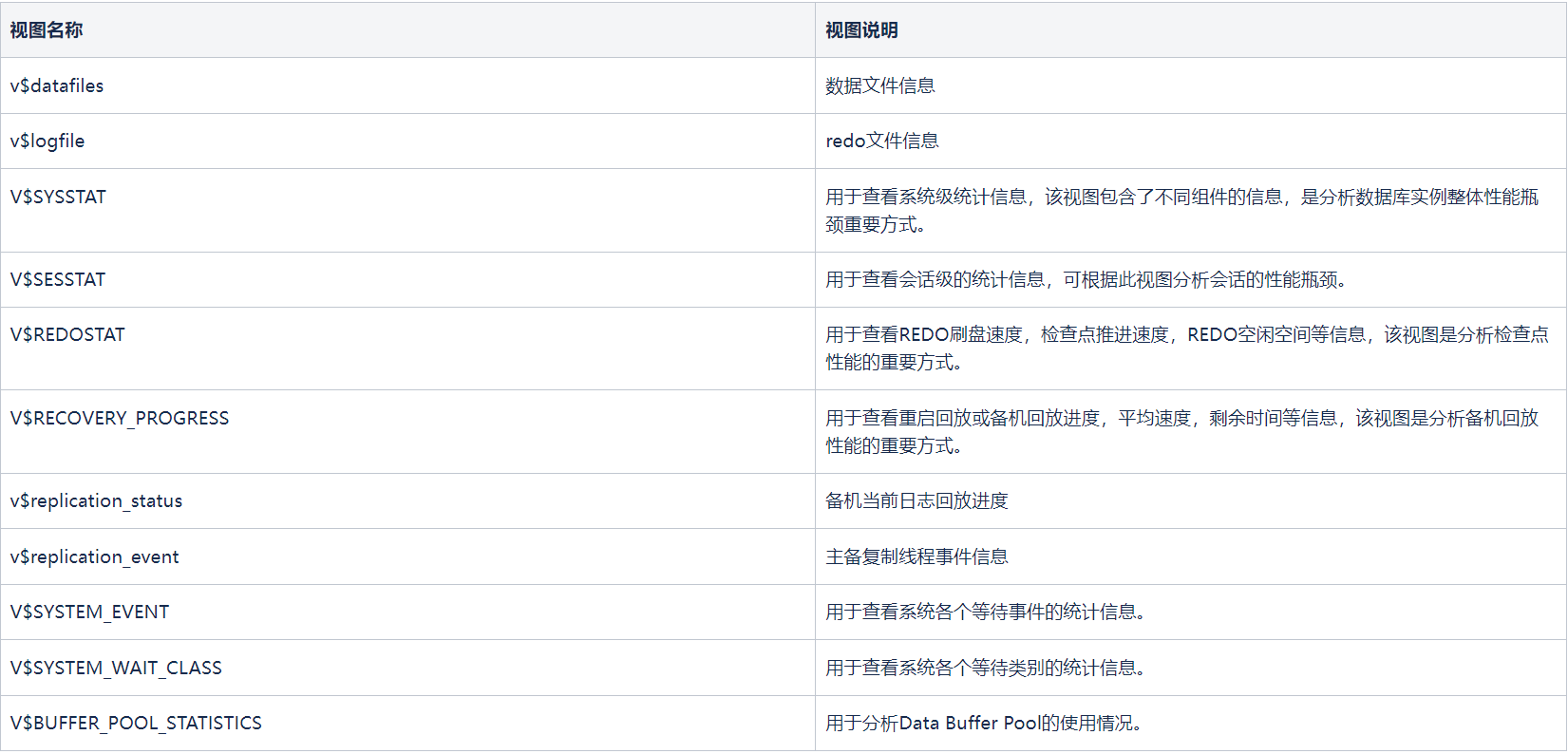
其他辅助分析视图介绍
检查磁盘的IO性能

输出信息说明
Device :磁盘名
rrqm/s :每秒进行的 merge 读数目
wrqm/s :每秒进行的 merge 写数目
r/s :每秒读 I/O 次数
w/s :每秒写 I/O 次数
rkB/s :每秒读设备的字节数(单位:K字节)
wkB/s :每秒写设备的字节数(单位:K字节)
avgrq-sz:平均每次设备I/O操作的数据大小
avgqu-sz:平均I/O队列长度
r_await :每个读操作的平均所需时间(包含列队等待时间)
w_await :每个写操作的平均所需时间(包含列队等待时间)
await :平均每次设备 IO 操作的等待时间(平均响应时间不超过5ms,单位:ms)
svctm :平均每次设备 IO 操作的服务时间(单位:ms)
%util :磁盘繁忙程度(注意:每块磁盘后面都有表示是否繁忙)
如果 svctm 与 await 比较接近,说明 IO 几乎没有等待。
如果 await 远高于 svctm ,说明 IO 队列太长 响应太慢,需要优化,可以从 avgqu-sz 队列长度看出来。
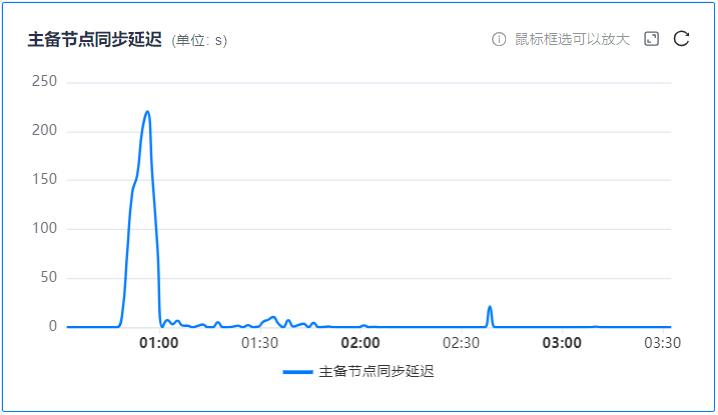
YCM监控主备延迟情况
V23.2.1.100 的ycm可以监控主备延迟,如下图
使用gstack查看线程状态
gstack yasdb进程 > gstack.txt
典型案例
问题单:生产数据迁移完毕后数据库延迟比较大
二线分析文章:《主备日志回放延迟高问题》
IO性能测试工具















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









