







hadoop1.0和hadoop2.0架构差异

hadoop1.0:HDFS和MapReduce
两个重要的进程:jobtracker和tasktracker
- jobtracker:负责资源管理、任务调度与监控
- tasktracker:负责各个节点的任务调度与监控

hadoop2.0:HDFS、yarn(集群资源管理系统)、计算框架{MapReduce、Spark、Storm……}
yarn:Hadoop集群的资源管理系统,相当于集群操作系统
- ResourceManager(RM)集群资源管理器:负责资源管理与调度
- ApplicationMaster(AM):任务调度与监控
- NodeManager(NM):负责每个节点的资源监控与管理

重构的思想:将Jobtracker两个主要功能分离成单独的组件,这两个功能是资源管理(RM)和任务调度与监控(AM)。
资源对比

- Hadoop1.0:MR作业的资源是以slot为单位,map slot和reduce slot,每一个资源是均匀的,如果任务所需要的资源多出一点点,就需要一个slot来填补,很容易浪费资源。
- Hadoop2.0:所有的任务application在NodeManager上所需要的资源都是按需分配的,避免资源浪费。
yarn架构

yarn
- Hadoop集群的资源管理系统,相当于集群操作系统(资源CPU,IO,内存)
- Hadoop2.0对MapReduce框架做了彻底的重构
- Hadoop2.0的MapReduce称为MRv2/Yarn
- 负责集群的资源管理和调度
- 使得多种计算框架可以运行在一个集群中mapreduce,spark,flink,storm…
- yarn中的job被换成application这个概念

RM(master)
- RM处理客户端请求,接收jobsubmit提交的作业,(按照作业的上下文信息run.sh提交的参数,以及NM收集的资源监控信息)启动调度过程,分配一个container作为AM。
- 与运行在每个节点上的NM进程交互,通过心跳机制达到监控NM的目的。
- RMapplicationManager监控AM的状态,如果AM挂掉,RM负责重启AM,不超过4遍,已完成的部分不会重新运行,只会运行未完成的一部分。
- RM资源调度依赖于一个可插拔的调度器组件Scheduler(纯粹的调度器,不负责应用的监控与状态跟踪,不保证应用失败对task的重启)
NM(slave)
- 角色相当于tasktracker,负责处理RM的任务。
- 接收并处理AM的Container启动、停止。
- 负责启动application的container,并监控资源使用情况,并汇报给RM,同时监控Container的运行状态。
AM(slave)
- applicationmaster,每一个任务对应一个AM,生命周期和application相同
- 负责一个application生命周期的任务调度与监控
- 与RM协商申请资源,一个周期会向RM汇报app的进展情况
Container(slave)
- 任务运行环境的抽象封装
- AM向NM提供更多的信息来启动Container
- 申请的资源依据提交的run.sh中的参数,如没有设置,则按照yarn默认参数
- 资源container进行封装,按需分配,需要多少资源就分配多少资源
yarn框架的运行过程

Client提交application任务,向RM申请资源,RM根据资源分布情况来分配一个NodeManager下的container作为AM,初始化任务所需的资源并向RM发出资源请求,RM分配指定NodeManager下的container资源计划,然后,AM根据RM分配的资源计划去指定的NodeManager来启动对应的container,任务运行时,对应的container通过心跳机制向AM汇报任务的运行情况,从而达到监控任务的目的。NodeManager监控该节点下的container的资源使用情况并向RM汇报(心跳机制)。AM在一定周期内会向RM汇报该任务的进度。
yarn容错能力
- RM挂掉:单点故障,RM可以基于Zookeeper实现HA高可用集群,为主RM设置一个备用RM,主RM提供服务,备用RM同步主RM的信息,一旦主RM挂掉,立刻切换到备用RM。
- NM挂掉:当一个NM挂掉后,会通过心跳机制通知RM,RM将情况通知对应的AM,AM进一步做处理。
- AM挂掉:当AM挂掉时,RM负责重启,选择另一个AM来执行上一个AM未完成的task。事实上RM有一个RMApplicationManager(AM的Amanager),保存着已经完成的task,若重启AM,无需重新运行已完成的task
yarn特点
- 良好的扩展性、高可用
- 对多个类型、多版本的应用进行统一管理和调度
- 自带了多种用户调度器FIFO、Fair公平调度,适合共享集群环境
- 相比传统模式,提高了资源利用率、降低运维成本和数据共享成本
NameNode HA
NameNode记录数据块block的元数据(目录),一般存放在内存以便集群能快速定位到数据具体位置。Namenode新增加的信息会同步到SecondNameNode(磁盘)
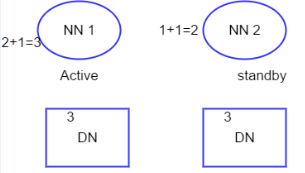
问题1:Hadoop1.0的NM在HDFS中只有一个,存在单点故障风险,一旦NN挂掉,整个集群无法使用
解决方案:NameNode的HA将通过在同一集群中运行两个NameNode(active和standby)来解决

原理:
两个NN(Active和standby),各自对应的FC所监控NN的状态,通过心跳机制发送给ZK(分布式锁),ZK会选择一个NN作为Active,而另一个NN处于Standby状态。当一个NN处于Active时,此NN对DN、JN集群拥有读写的权限,而另一个NN没有此权限。Active的NN会更新DataNode新增的数据信息,同步到JN集群(一般3个节点,保证容错性)。当此NN挂掉时,另一个NN会由ZK切换到Active状态,该NN处于standby状态。Active的NN会立刻将JN集群上新增的数据同步到NN,此时,Active的NN拥有读写的权限。
问题2:集群水平扩展导致NameNode内存不足问题:单个NameNode存放在有限的内存空间,因此集群水平扩展可能导致NN无法继续存储

解决方案:集群提供多个NN,每个NN有独立的namespace,对应的namespace有block pools,分别负责管理集群DataNode中的blocks。(NameNode联盟)
问题3:为什么zookeeper集群节点数量一般为奇数,通常取3个?
leader选举规则:可用节点数量>总节点数量/2
- 防止由脑裂造成的集群不可用
- 容错能力相同的情况下,奇数台更节省资源
集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的master节点,导致原有的集群出现多个master节点的情况,这就是脑裂。















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









