







MapReduce概述
- MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
- MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
- 这两个函数的形参是key、value对,表示函数的输入信息。
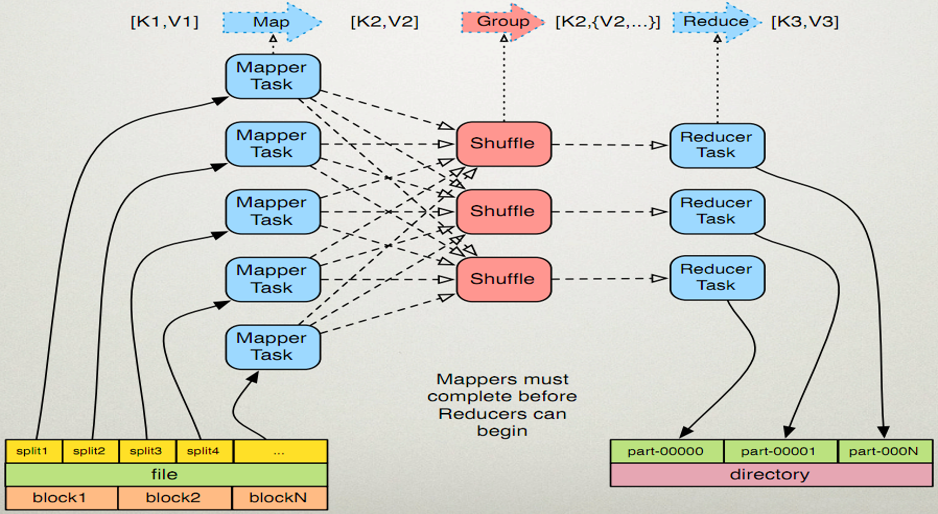
执行步骤
map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
reduce任务处理
2.1 在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。
2.2 写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。

WordCountApp的驱动代码
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //加载配置文件
Job job = new Job(conf); //创建一个job,供JobTracker使用
job.setJarByClass(WordCountApp.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.1.10:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000/output"));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}MR流程
◆ 代码编写
◆ 作业配置
◆ 提交作业
◆ 初始化作业
◆ 分配任务
◆ 执行任务
◆ 更新任务和状态
◆ 完成作业
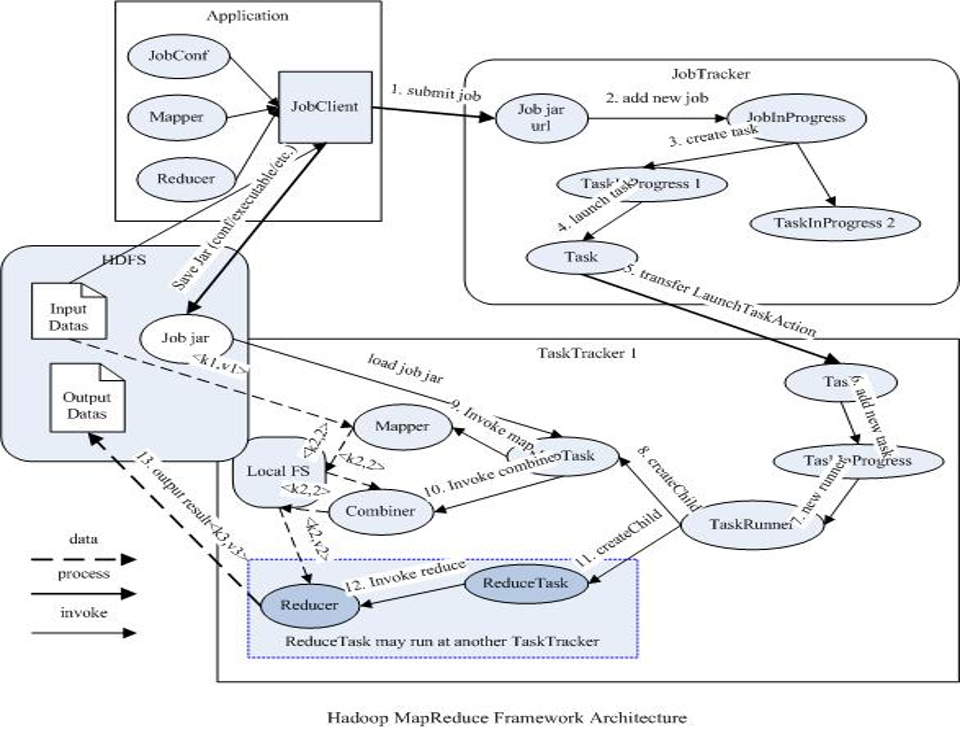
MR过程各个角色的作用
◆ jobClient:提交作业
◆ JobTracker:初始化作业,分配作业,TaskTracker与其进行通信,协调监控整个作业
◆ TaskTracker:定期与JobTracker通信,执行Map和Reduce任务
◆ HDFS:保存作业的数据、配置、jar包、结果
作业提交
◆ 提交作业之前,需要对作业进行配置
- 编写自己的MR程序
- 配置作业,包括输入输出路径等等
◆ 提交作业
- 配置完成后,通过JobClient提交
◆ 具体功能
- 与JobTracker通信得到一个jar的存储路径和JobId
- 输入输出路径检查
- 将jobj ar拷贝到的HDFS
- 计算输入分片,将分片信息写入到job.split中
- 写job.xml
- 真正提交作业
作业初始化
◆ 客户端提交作业后,JobTracker会将作业加入到队列,然后进行调度,默认是FIFO方式
◆ 具体功能
- 作业初始化主要是指JobInProgress中完成的
- 读取分片信息
- 创建task包括Map和Reduce任创建task包括Map和Reduce任务
- 创建TaskInProgress执行task,包括map任务和reduce任务
任务分配
- TaskTracker与JobTracker之间的通信和任务分配是通过心跳机制实现的
- TaskTracker会主动定期向JobTracker发送心态信息,询问是否有任务要做,如果有,就会申请到任务。
任务执行
- 如果TaskTracker拿到任务,会将所有的信息拷贝到本地,包括代码、配置、分片信息等
- TaskTracker中的localizeJob()方法会被调用进行本地化,拷贝job.jar,jobconf,job.xml到本地
- TaskTracker调用launchTaskForJob()方法加载启动任务
- MapTaskRunner和ReduceTaskRunner分别启动java child进程来执行相应的任务
状态更新
- Task会定期向TaskTraker汇报执行情况
- TaskTracker会定期收集所在集群上的所有Task的信息,并向JobTracker汇报
- JobTracker会根据所有TaskTracker汇报上来的信息进行汇总
作业完成
- JobTracker是在接收到最后一个任务完成后,才将任务标记为成功
- 将数结果据写入到HDFS中
错误处理
- JobTracker失败
- 存在单点故障,hadoop2.0解决了这个问题
- TraskTracker失败
- TraskTracker崩溃了会停止向JobTracker发送心跳信息。
- JobTracker会将TraskTracker从等待的任务池中移除,并将该任务转移到其他的地方执行
- JobTracker将TaskTracker加入到黑名单中
- Task失败
- 任务失败,会向TraskTracker抛出异常
- 任务挂起
JobTracker
- 负责接收用户提交的作业,负责启动、跟踪任务执行。
- JobSubmissionProtocol是JobClient与JobTracker通信的接口。
- InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
TaskTracker
- 负责执行任务。
JobClient
- 是用户作业与JobTracker交互的主要接口。
- 负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。
MapReduce调度框架
序列化机制
序列化概念
- 序列化(Serialization)是指把结构化对象转化为字节流。
- 反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。
- Java序列化(java.io.Serializable)
Hadoop序列化的特点
- 序列化格式特点:
- 紧凑:高效使用存储空间。
- 快速:读写数据的额外开销小
- 可扩展:可透明地读取老格式的数据
- 互操作:支持多语言的交互
Hadoop的序列化格式:Writable
Hadoop序列化的作用
- 序列化在分布式环境的两大作用:进程间通信,永久存储。
- Hadoop节点间通信。
实例
序列化和反序列化过程 http://elon33.com/2017/hadoop-mapreduce-advanced/#example
Writable接口
- Writable接口, 是根据 DataInput 和 DataOutput 实现的简单、有效的序列化对象.
MR的任意Key和Value必须实现Writable接口.
MR的任意key必须实现WritableComparable接口


常用的Writable实现类
Text一般认为它等价于java.lang.String的Writable。针对UTF-8序列。
例:
Text test = new Text("test");
IntWritable one = new IntWritable(1);Writable
- write 是把每个对象序列化到输出流
- readFields是把输入流字节反序列化

- 实现WritableComparable.
- Java值对象的比较:一般需要重写toString(),hashCode(),
equals()方法
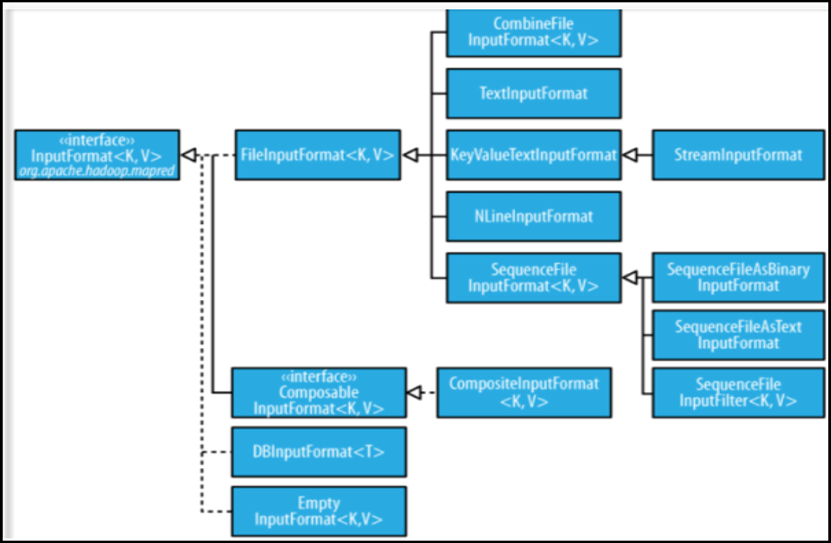
MapReduce输入的处理类
FileInputFormat
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
InputFormat

InputFormat 负责处理MR的输入部分.
有三个作用:
- 验证作业的输入是否规范.
- 把输入文件切分成InputSplit.
- 提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理.
InputSplit
◆ 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
◆ FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
◆ 如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
◆ 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
TextInputFormat
◆ TextInputformat是默认的处理类,处理普通文本文件。
◆ 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
◆ 默认以\n或回车键作为一行记录。
◆ TextInputFormat继承了FileInputFormat。
其他输入类
◆ CombineFileInputFormat
相对于大量的小文件来说,hadoop更合适处理少量的大文件。
CombineFileInputFormat可以缓解这个问题,它是针对小文件而设计的。
◆ KeyValueTextInputFormat
当输入数据的每一行是两列,并用tab分离的形式的时候,KeyValueTextInputformat处理这种格式的文件非常适合。
◆ NLineInputformat
可以控制在每个split中数据的行数。
◆ SequenceFileInputformat
当输入文件格式是sequencefile的时候,要使用SequenceFileInputformat作为输入。
自定义输入格式
1)继承FileInputFormat基类。
2)重写里面的getSplits(JobContext context)方法。
3)重写createRecordReader(InputSplit split,TaskAttemptContext context)方法。
Hadoop的输出
◆ TextOutputformat
默认的输出格式,key和value中间值用tab隔开的。
◆ SequenceFileOutputformat
将key和value以sequencefile格式输出。
◆ SequenceFileAsOutputFormat
将key和value以原始二进制的格式输出。
◆ MapFileOutputFormat
将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
◆ MultipleOutputFormat
默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。
思考题
◆ MapReduce框架的结构是什么
MapReduce框架结构 https://www.cnblogs.com/shipengzhi/articles/2487429.html
◆ Map和Reduce在整个MR框架中作用是什么
一个完整的job会自动依次执行Mapper、Combiner(在JobConf指定了Combiner时执行)和Reducer,其中Mapper和Combiner是由MapTask调用执行,Reducer则由ReduceTask调用,Combiner实际也是Reducer接口类的实现。Mapper会根据job jar中定义的输入数据集按















 8359
8359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









