







1.Activity生命周期以及onResume()和onStart()的区别
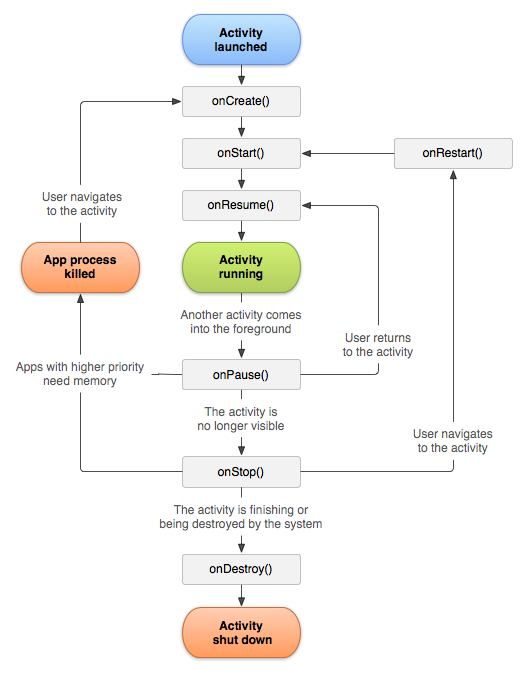
我们不能没有onStart(),因为Activity调用onStart()后的状态对于用户来说是可见(visible)的,但是不能与用户进行交互(interact)。是否能够和用户交互就是onStart()和onResume()的区别。想象一个人站在一扇玻璃门后面,你可以看见这个人但是你不能和他进行交互(说话、听、握手)。onResume()就像你和这个人之间开了一扇门。
另外,onRestart()才是最难理解的一个函数。我们问一个这样的问题:Activity调用onStop()之后为什么不直接调用onStart()或者onResume(),而去调用onRestart()。如果我们注意到下面这点,那回答这个问题就很容易:当Activity的onCreate()没有被执行的时候,onRestart()是部分等价于onCreate()的。这两个回调函数都会向下执行onStart()(这样才能让Activity显示),所以这两个回调函数都有准备显示控件的功能,只不过onCreate()的另外一个功能就是创建将要显示的控件。
所以他们的代码结构可能是这样的:
onCreate()
{
createNecessaryObjects();
prepareObjectsForDisplay();
}
onRestart()
{
prepareObjectsForDisplay();
}其他函数的解释应该是这样的:
onCreateAndPrepareToDisplay() [instead of onCreate() ]
onPrepareToDisplay() [instead of onRestart() ]
onVisible() [instead of onStart() ]
onBeginInteraction() [instead of onResume() ]
onPauseInteraction() [instead of onPause() ]
onInvisible() [instead of onStop]
onDestroy() [no change] Activity生命周期的另一种解读如下图:
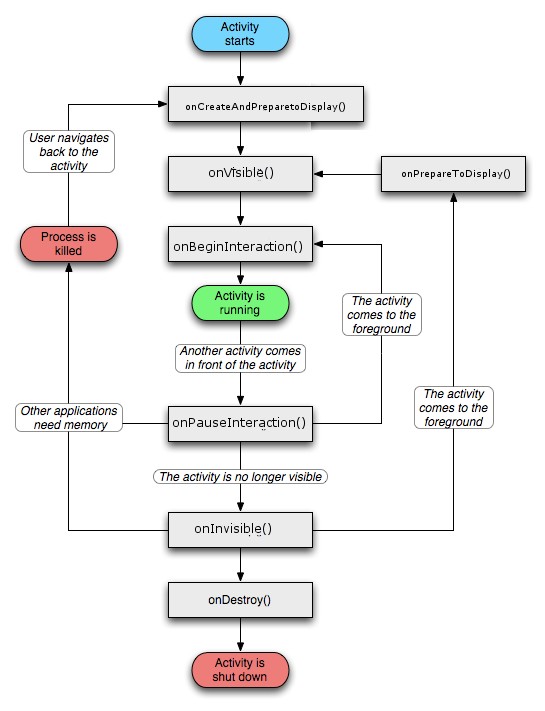
现在对Activity生命周期的理解又深了一层,感谢这些老外
2.这个问题是我项目中的一个问题,服务器中的数据库与本地数据库如何同步
3.带权有向图的从A点到B点的最短路径
Dijkstra算法
算法思想:设G=(V,E)是一个带权有向图,把顶点集V分成两组,第一组为已求出最短路径的顶点集合,第二组为未确定最短路径的顶点集合,按照从源点到第二组顶点长度的递增次序依次把第二组的顶点加入到第一组中。
算法步骤:
a. 初始时,S只包含源点,S={v},v的距离为0。U包含除了V之外的所有顶点,即U={其余顶点},若v与U中的顶点u右边,则(u,v)等于权值,若u不是v的邻接点,则(u,v)的权值为无穷大。
b. 从U中选取一个距离v最小的顶点k,把k加入S集合中
c. 以k为新的中间点,修改U中个顶点的距离,若源点v到顶点u的距离(经过k)比原来的距离短,则修改顶点u的距离值,修改后的距离值为k的值加上k到u的距离
d. 重复步骤b和c知道所有顶点都包含在S中。
算法代码(C语言版)
const int MAXINT = 32767;
const int MAXNUM = 10;
int dist[MAXNUM];
int pre[MAXNUM];
int A[MAXNUM][MAXNUM];
void Dijkstra(int v0)
{
bool S[MAXNUM];
for (int i = 0; i < MAXNUM; i++)
{
dist[i] = A[v0][i];
S[i] = false;
if (dist[i] == MAXINT)
pre[i] = -1;
else
pre[i] = v0;
}
dist[v0] = 0;
S[v0] = true;
for (int i = 0; i < MAXNUM; i++)
{
int min = MAXINT;
int u = v0;
for (int j = 0; j < MAXNUM; j++)
{
if ((!S[j]) && dist[j] < min)
{
u = j;
min = dist[j];
}
}
S[u] = true;
for (int j = 0; j < MAXNUM;j++)
{
if ((!S[j]) && A[u][j] < MAXINT)
{
if (dist[u] + A[u][j] < dist[j])
{
dist[j] = dist[u] + A[u][j];
pre[j] = u;
}
}
}
}
}4.A文件和B文件的结构都是一行行的URL,求两个文件中相同的URL
比如说:
D:/url1.txt
www.baidu.com
www.baidu.com
www.muc.edu.cn
www.nchu.edu.cn
www.abc.com.cn
D:/url1.txt
www.baidu.com
www.nchu.edu.cn
www.c.com
www.c.com
www.muc.edu.cn要找出两个文件都有的url
解决方案: 将两个文件分别存储在两个set中,再获取两个set的交集,也就是调用retainAll()函数。
public class main {
public static void main(String[] args) {
File url1 = new File("D:/url1.txt");
File url2 = new File("D:/url2.txt");
Set<String> url1Set = new HashSet<String>();
Set<String> url2Set = new HashSet<String>();
try {
BufferedReader reader1 = new BufferedReader(new FileReader(url1));
BufferedReader reader2 = new BufferedReader(new FileReader(url2));
String line = null;
while ((line = reader1.readLine()) != null) {
url1Set.add(line);
}
while ((line = reader2.readLine()) != null) {
url2Set.add(line);
}
url1Set.retainAll(url2Set);
System.out.println(url1Set);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}运行结果:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









