







技术简介:使用Python技术、B/S架构、MYSQL数据库等实现。
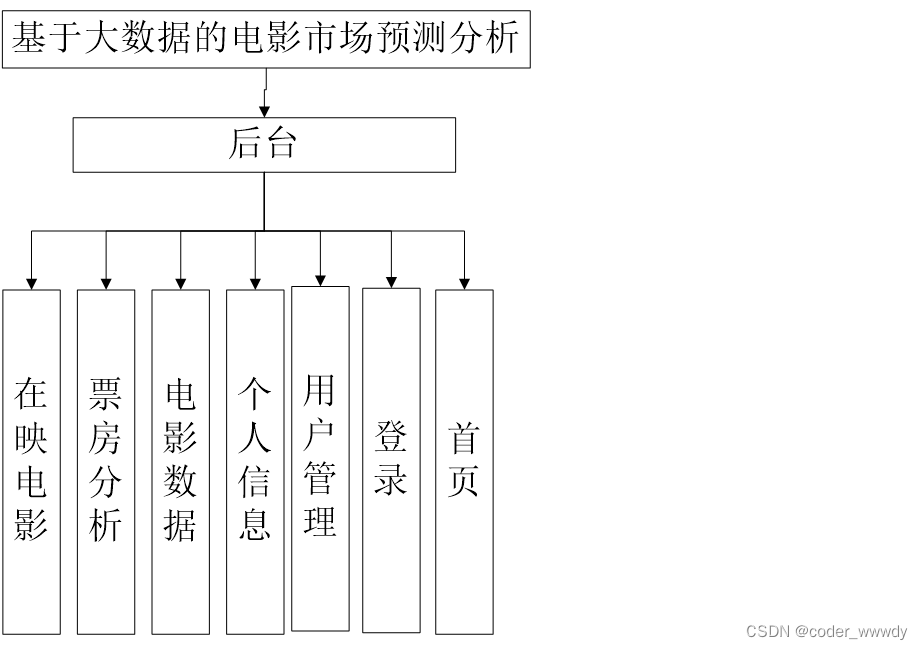
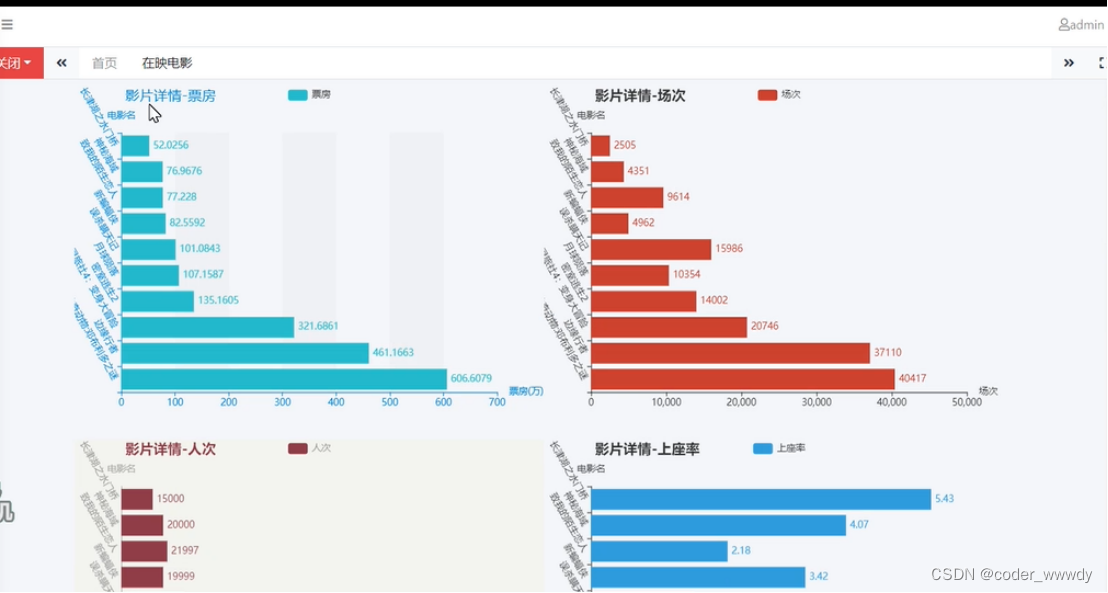
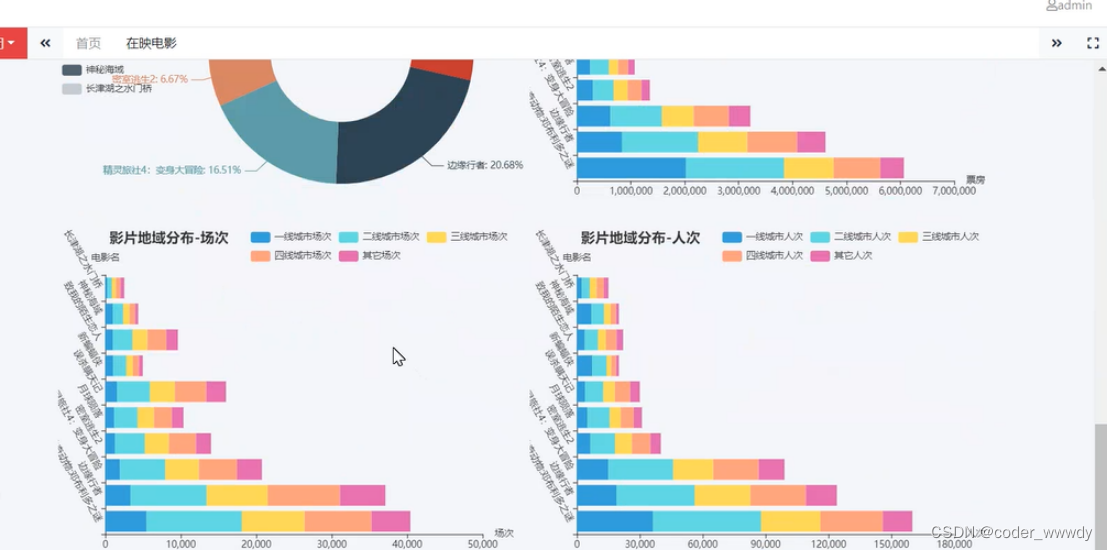
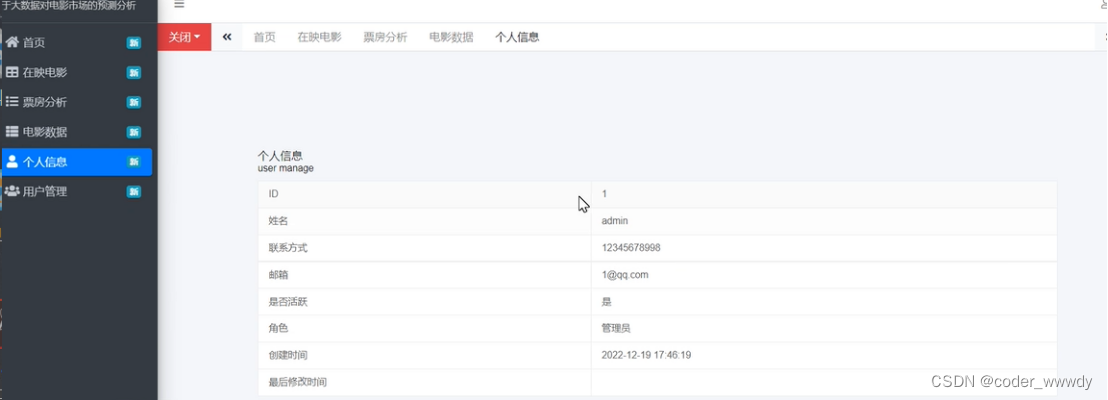
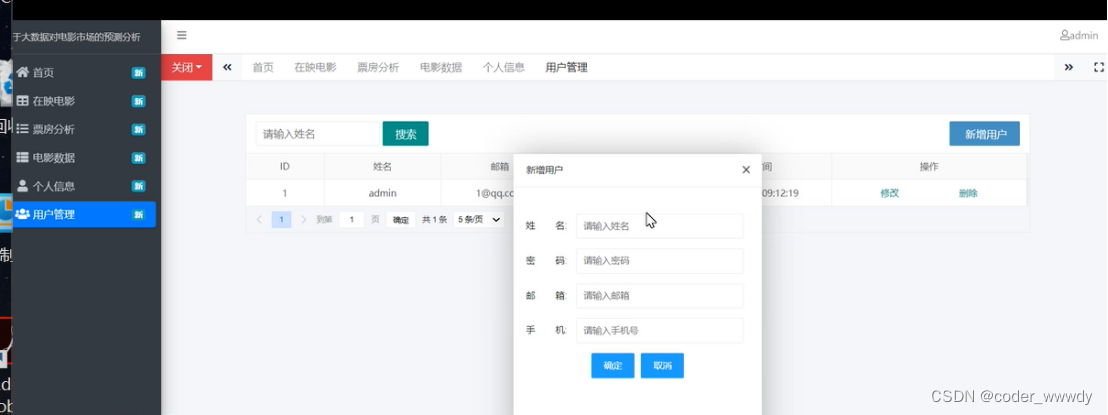
系统简介:系统都需要简单的安全登陆检查,在登陆成功之后要进行在映电影的分析、票房分析、电影数据等功能相关性的数据统计,为了使用方便这些统计型的数据使用图表来进行表达,还要有针对用户、人个信息等的功能。
智慧是推动生活和生产方式变革的关键因素,尤其在软件技术领域,智慧的体现尤为显著。在现代社会,优秀的创意和创新方法往往是改变人们生活方式的重要动力。最直接的例子就是各种软件的创新思维:京东利用非典疫情推广了线上电子商务模式;淘宝则凭借其独特的商业模式,推动了电子商务的繁荣发展。这些不同的解决方案考验着我们对社会问题的洞察力,而软件信息化仅仅是实现这些解决方案的一种手段,也可以说是一种工具。
目前,各行各业都在通过信息化手段不断进行变革。企业通过信息化推动智能制造的发展;高校利用信息化技术建设智慧校园;城市则通过信息化手段打造智慧城市等。电影娱乐作为我们生活中常见的一种休闲方式,其市场的广泛性让我们意识到,除了电影的情节和内容外,通过数据分析来预测电影市场的趋势才是关键。
基于大数据的电影市场分析不仅可以让我们深入了解市场的动态,掌握电影相关的各种指标和属性,还能使电影产业更加数据化,将电影数据转化为有说服力的信息。
本文的核心内容是设计和实现基于Python的电影市场预测分析系统。我们利用Python技术对当前电影市场的各种信息进行预测分析,确保我们的数据来源是真实可靠的。在数据库方面,我们选择了MySQL,这不仅降低了成本,而且便于快速部署和使用。通过这种方式,我们能够更准确地把握电影市场的脉搏,为电影产业的决策提供有力的数据支持。
技术项目本质上是技术应用的具体化,而大学期间我们所学习的语言均为当前流行的编程语言。以后台开发为例,我们通常会接触到Python、Java等语言;在数据库领域,则有MySQL、SQL Server等技术。这些技术都是大学课程中常见的内容,因此我们所接触的都是当前主流的开源技术。
一旦在技术实践中遇到难题,我们可以通过互联网搜索解决方案,或者向同学求助,从而获得必要的帮助。这样的支持网络确保了在技术实施上,我们能够找到解决问题的途径,从而保证了技术实施的可行性。
目录
内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









