







题目:Video Person Re-identification with Competitive Snippet-similarity Aggregation and Co-attentive Snippet Embedding
- 作者 : Dapeng Chen, Hongsheng Li, Tong Xiao(商汤)
1.解决的问题
- Video Person Re-id
2.介绍
现有的很多方法是将一段视频的每一帧抽出一个特征向量,然后将特征向量做一个max-pooling或者mean-pooling代表这段视频的特征向量。但是在视频里面有丰富的信息,一个特征向量无法很好的代表这种信息,会丢失掉很多的重要信息。
作者在这里将一个长视频分割成很多片段(每个片段有很多帧),当给两个长视频作为比较的时候(比如比较是不是同一个人),可以计算片段与片段之间的相似度,然后选取topk的相似度作为最终长视频的相似度。因为每段视频拍的角度可能不同,但视频A的某一个片段和视频B的某一个片段也许很相近,就可以选出来作为相似度。
作者提出了一个temporal co-attentive embedding 方法,用于计算片段之间的相似度。利用了一个query q 来指导进行距离度量。
3.方法
3.1. Competitive Snippet-similarity Aggregation
- 用 p 来代表probe sequence,g 代表 gallery sequence,我们的目标是计算p与g之间的相似度。首先,将一个sequence 切分成很多个snippets,每个snippet 都用固定的长度L帧。
- 用 pn p n 和 gk g k 代表 p 和 g 中的任意一个snippet,那么它们的相似度可以用 m(pn,gk) m ( p n , g k ) 来表示,那么p和g的所有可能相似度可以用 M(p,g)={m(pn,gk)|pnϵSp,gkϵSg} M ( p , g ) = { m ( p n , g k ) | p n ϵ S p , g k ϵ S g } 表示,即使同一个人的两个序列,可能会因为角度不同,遮挡等原因有很大区别,所以这里就在 M(p,g) M ( p , g ) 中选择 top-ranked 相似度(top t%),形成一个新的集合,然后以这个集合的平均相似度作为两个长视频 p 和 g 的相似度。
3.2. Coattentive Snippet Embedding
- 现在问题转变为了计算两个snippet之间的相似度,首先将一个snippet,我们这里用 s 表示,之前提过,这个s有L帧,使用一个CNN来提取每一帧的特征向量 Ψl(s) Ψ l ( s ) ,那么一个snippet的特征向量就是所有帧的特征向量的集合 Ψ(s)=Ψl(s)Ll=1 Ψ ( s ) = Ψ l ( s ) l = 1 L
3.2.1. Attention with Query and Key-value Features
对于一个snippet来说, Ψ(s) Ψ ( s ) 其实包含着很多冗余的信息,因为帧与帧之间的差别很小。所以这里提出一个attention机制来选择那些有判别力的信息。如下图:
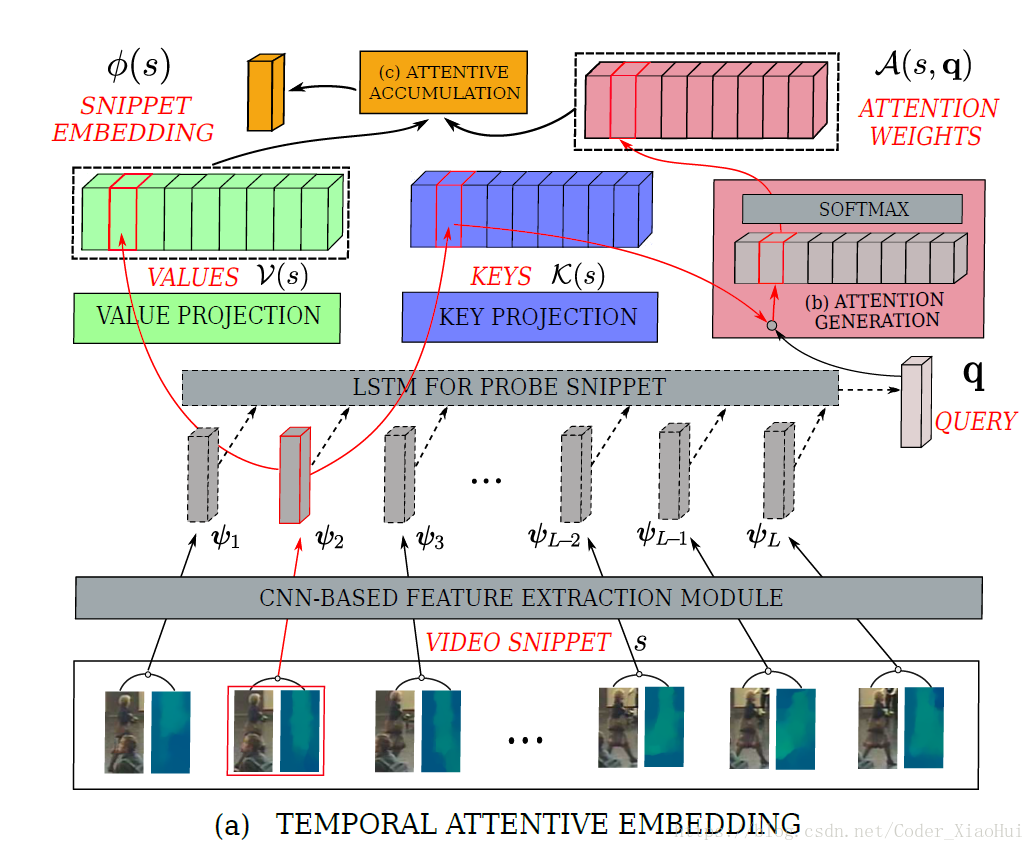
VALUE PROJECTION 和 KEY PROJECTION 都是线性映射,Attention的计算如下图所示:

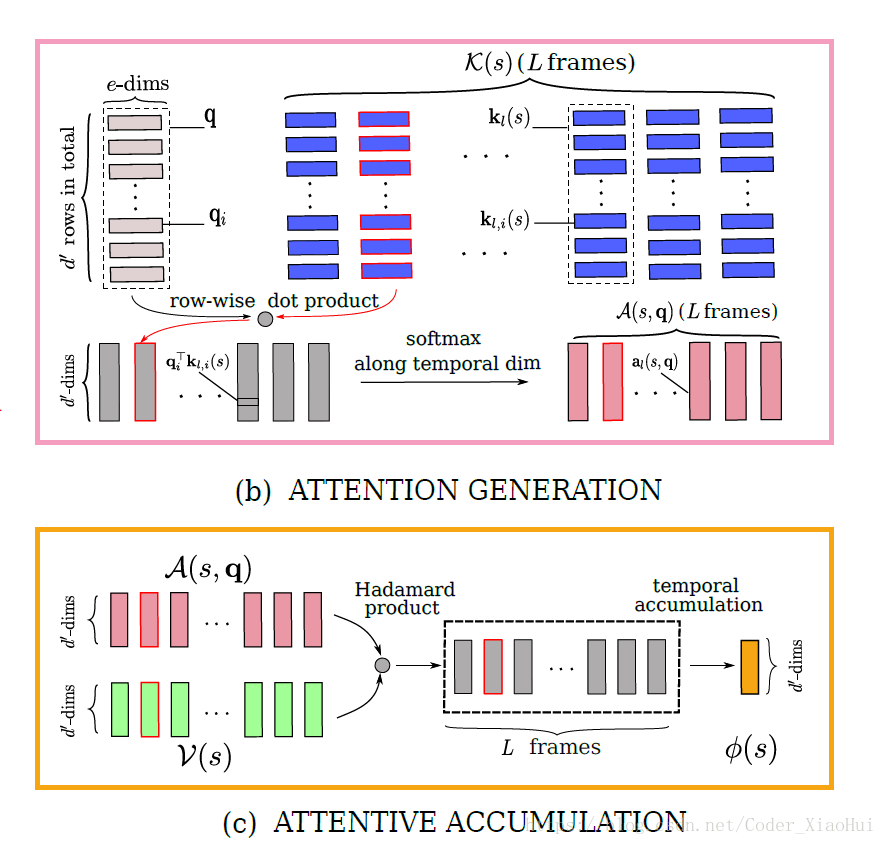
3.2.2. Snippet Similarity with Co-attentive Embedding
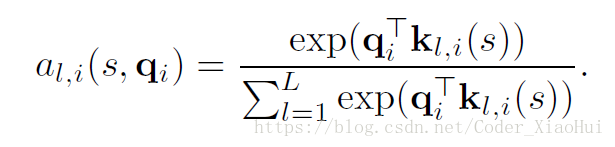
- query vector q q 用LSTM的最后一步的隐藏层向量表示,权重a可以用过上面公式计算得到,那么对于每个snippet来说都可以求出其特征向量,对于probe snippet来说,得:
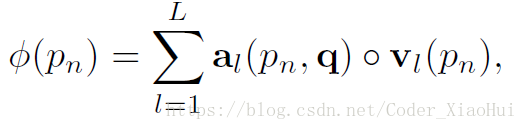
对于gallery snippet来说,得:
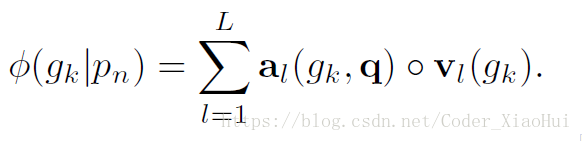
得到了两个snippet得特征向量,可以求 了,论文中用下面公式来计算,f 代表全连接层,m越大越好。
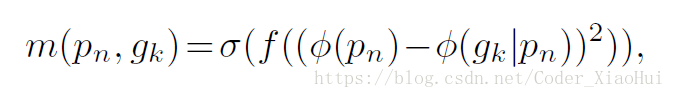
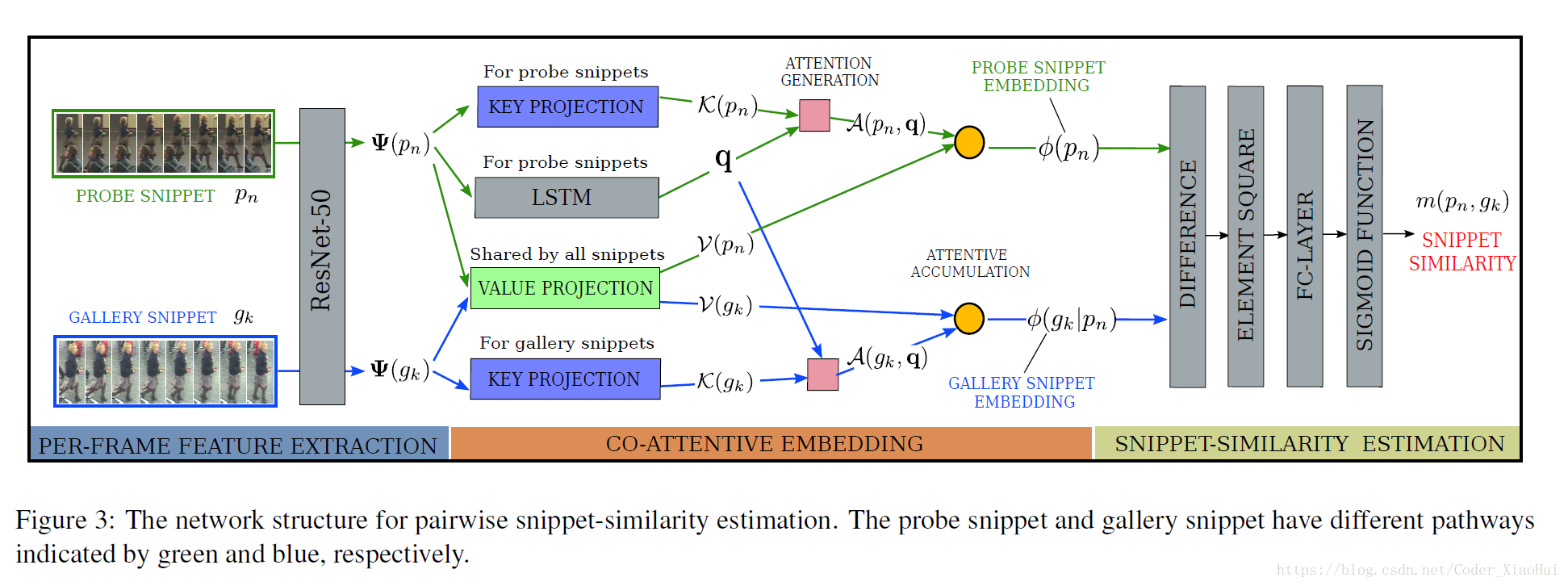
3.2.3. The Network Structure
整体网络结构如下图:
Loss用的是交叉熵,训练样本是成对的,每一个batch选择随机的32个人,每个人从不同的video选出两个snippets,一个作为probe snippet,另一个作为gallery snippet,构造出32个正样本,和32*3个随机选择的负样本。
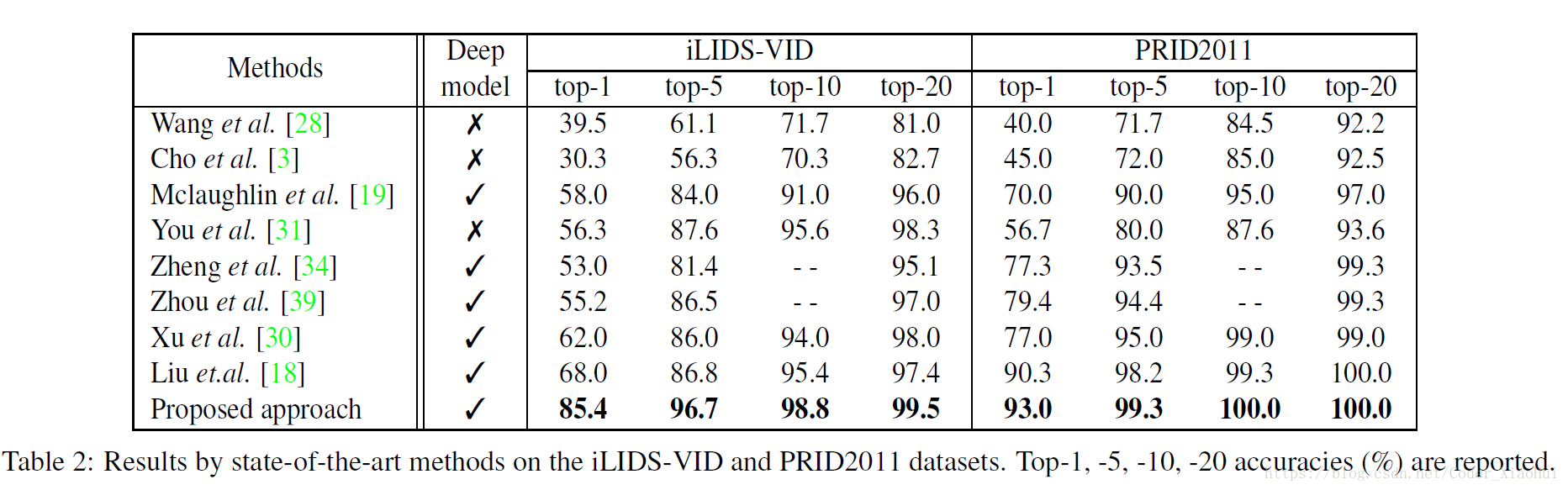
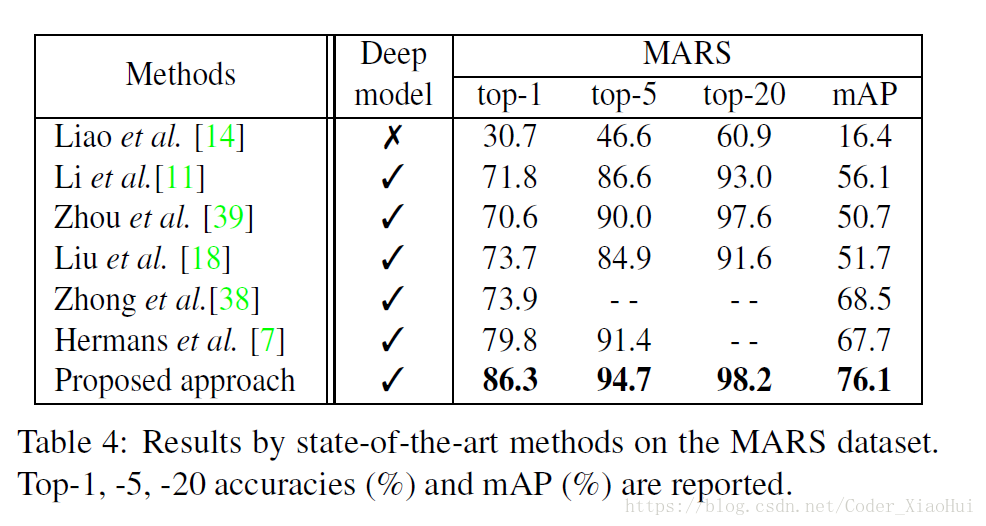
4.结果














 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









