






问题
设计一个公平的洗牌算法
问题分解
首先,必然明确这是一个随机算法
其次,要考虑公平
问题剖析
关于随机
看到随机我们大多数时候想起来的是,把所有的数都放到一个数组里,每次取两个数进行交换,随机 n 次。
那么此时又一个新的问题出现了,n 要取值为多少?如果数组中有 1000 个元素,随机 1000 次,还是 1000000 次?
显然 n 不应该取一个固定的值。而我们通常自然而然会将 n 与数组元素大小相关起来,比如将 n 取为数组大小。那么我们现在再来思考第二个问题,这么做公平吗?
关于公平
细化问题
对于这个问题,显然公平是最重要的。如何定义这个公平是我们要先思考的问题。
在概率学上这并不是一个难的问题,一副牌有 n 个元素,那么最终洗牌能得到的结果排列应一共有 n!个,很显然,公平的洗牌算法应该做到可以等概率地获取到这 n!个结果中的任意一个。
解决实现
暴力方式
在定义完公平后,最简单的实现就是暴力算法了:生成所有的 n!个排列结果,然后随机取出一个作为结果。
这么做绝对是公平的,但是也有个显而易见的问题————算法的复杂度相当高,为 O(n!)。n 个元素一共有 n!种排列,我们要求出所有的排列至少需要 n!的时间。我们都知道指数爆炸,n!在 n>=4 开始,就能以极快的速度超越 2n,毕竟 n!是 n 个数字相乘,除了 1 以外所有的数字都是大于等于 2 的。所以我们在此可以看出虽然暴力算法公平,但其时间复杂度过高。
换位思考
对于公平我们同样可以转变一下思维,对于最后的排列结果,每一个元素都可以等概率的出现在任何一个位置。这个思想逻辑上要更为简单,我们使用一个循环就可以解决:
for (int i=n-1;i>=0;i--){
swap(arr[i],arr[rand()%(i+1)])
}这个算法已经可以保证每一个位置都能等概率地放置每个元素。从后向前,每次随机[0…i]之间的元素,然后将其与 arr[i]交换。rand()%(i+1)是为了使元素索引保持在 0~i 之间。这就是著名的 Knuth-Durstenfeld Shuffle 随机洗牌算法。
算法原理
接下来我们来证明一下为什么该算法能保证随机的公平性。以下过程将让你感觉到简单到泪流。
我们使用 5 个数字进行模拟说明:
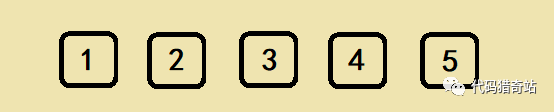
我们从最后一位 5 开始,
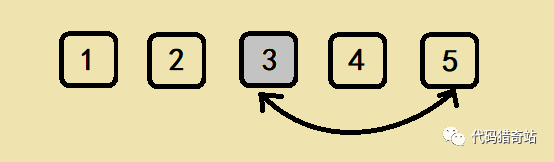
3 出现在最后一个位置的概率显然是1/5,任意一个数出现在最后一位的概率都是1/5的

那么最后一位到此为止,我们接下来要管的是前 4 位。
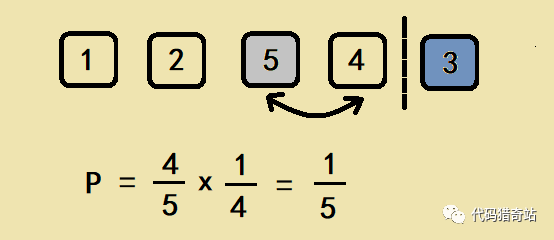
假设出现在倒数第二个位置的是 5,则 5 和 4 进行交换,计算方式中,5 逃出了第一轮的筛选,第一轮有 5 个元素,概率是4/5,但没逃过第二轮的筛选,第二轮有 4 个元素,被选中的概率是1/4。故 5 出现在倒数第二个位置的概率是1/5,如图:
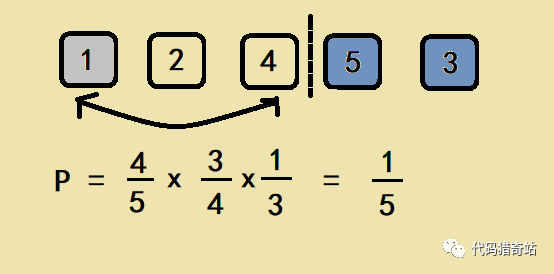
后续的计算过程和原理同下图:
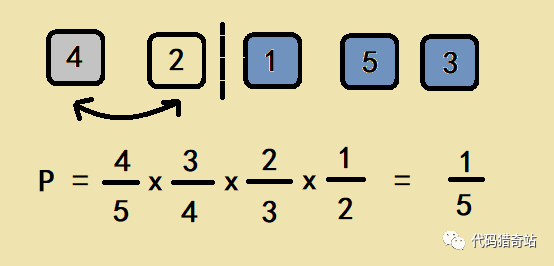
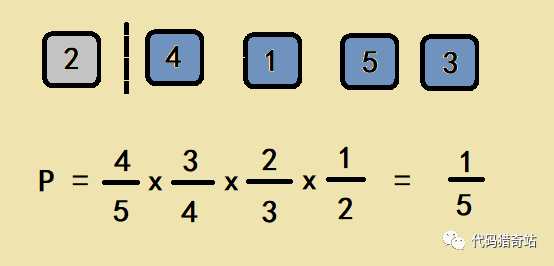

本期文章就到这里啦,祝大家清凉一夏
















 3584
3584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









