









题目描述:
请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。
实现 LFUCache 类:
- LFUCache(int capacity) - 用数据结构的容量 capacity 初始化对象
- int get(int key) - 如果键 key 存在于缓存中,则获取键的值,否则返回 -1 。
- void put(int key, int value) - 如果键 key 已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量 capacity 时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 最近最久未使用 的键。
为了确定最不常使用的键,可以为缓存中的每个键维护一个 使用计数器 。使用计数最小的键是最久未使用的键。
当一个键首次插入到缓存中时,它的使用计数器被设置为 1 (由于 put 操作)。对缓存中的键执行 get 或 put 操作,使用计数器的值将会递增。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入:
[“LFUCache”, “put”, “put”, “get”, “put”, “get”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [3], [4, 4], [1], [3], [4]]
输出:
[null, null, null, 1, null, -1, 3, null, -1, 3, 4]
解释:
// cnt(x) = 键 x 的使用计数
// cache=[] 将显示最后一次使用的顺序(最左边的元素是最近的)
LFUCache lfu = new LFUCache(2);
lfu.put(1, 1); // cache=[1,_], cnt(1)=1
lfu.put(2, 2); // cache=[2,1], cnt(2)=1, cnt(1)=1
lfu.get(1); // 返回 1
// cache=[1,2], cnt(2)=1, cnt(1)=2
lfu.put(3, 3); // 去除键 2 ,因为 cnt(2)=1 ,使用计数最小
// cache=[3,1], cnt(3)=1, cnt(1)=2
lfu.get(2); // 返回 -1(未找到)
lfu.get(3); // 返回 3
// cache=[3,1], cnt(3)=2, cnt(1)=2
lfu.put(4, 4); // 去除键 1 ,1 和 3 的 cnt 相同,但 1 最久未使用
// cache=[4,3], cnt(4)=1, cnt(3)=2
lfu.get(1); // 返回 -1(未找到)
lfu.get(3); // 返回 3
// cache=[3,4], cnt(4)=1, cnt(3)=3
lfu.get(4); // 返回 4
// cache=[3,4], cnt(4)=2, cnt(3)=3
思路:
与LRU问题相似,但是要比LRU问题的处理更难,同样有调库OrderedDict和dict+双向链表两种方式。
- OrderedDict 会超时,时间复杂度不是O(1)。
import sys
import collections
maxint = sys.maxsize
'''
超时!!!!!
'''
class LFUCache(object):
def __init__(self, capacity):
"""
:type capacity: int
"""
self.capacity = capacity
self.use = 0
self.dict = collections.OrderedDict()
self.times = dict()
def get(self, key):
"""
:type key: int
:rtype: int
"""
if key in self.dict:
self.times[key] += 1
value = self.dict.pop(key)
self.dict[key] = value
return value
else:
return -1
def put(self, key, value):
"""
:type key: int
:type value: int
:rtype: None
"""
if self.capacity != 0:
if key in self.dict:
self.dict[key] = value
self.times[key] += 1
else:
if self.use < self.capacity:
self.use += 1
else:
m = maxint
for k in self.dict: # 这里有一个遍历导致时间复杂度为O(N),要求为O(1)
if self.times[k] < m:
m = self.times[k]
kk = k
self.dict.pop(kk)
self.times.pop(kk)
self.dict[key] = value
self.times[key] = 1
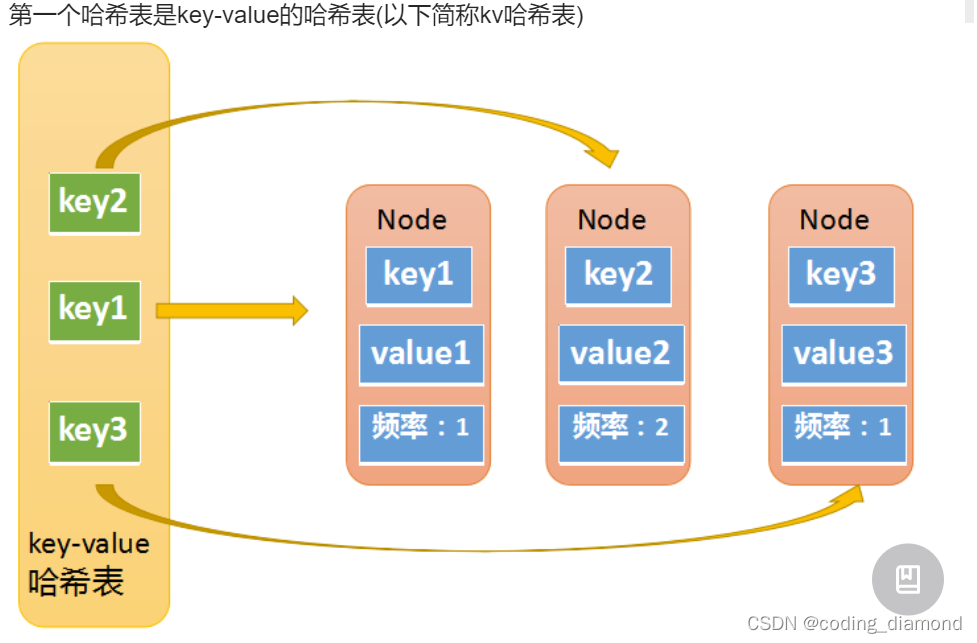
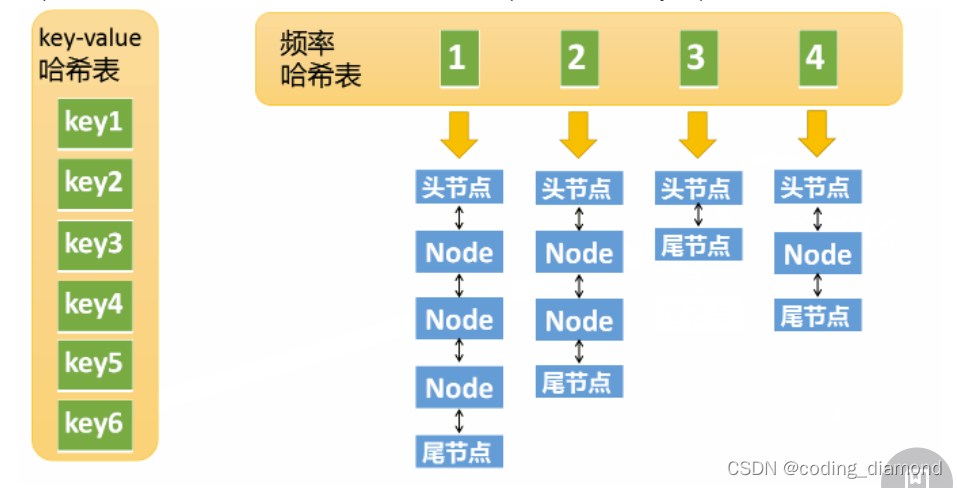
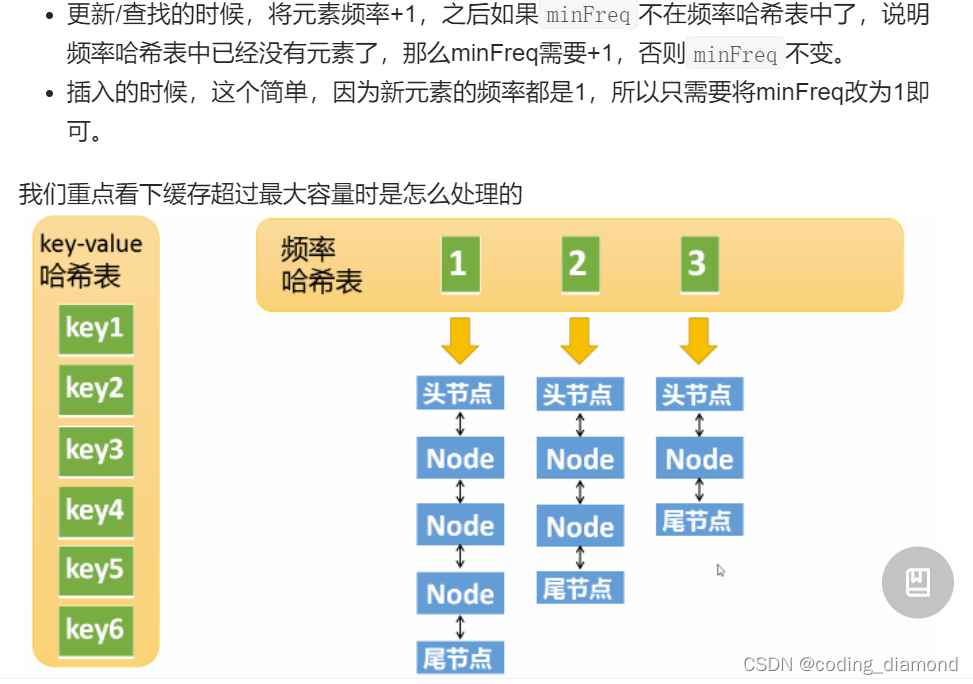
- 维护两个map, 具体的思路:
leetcode的一个题解




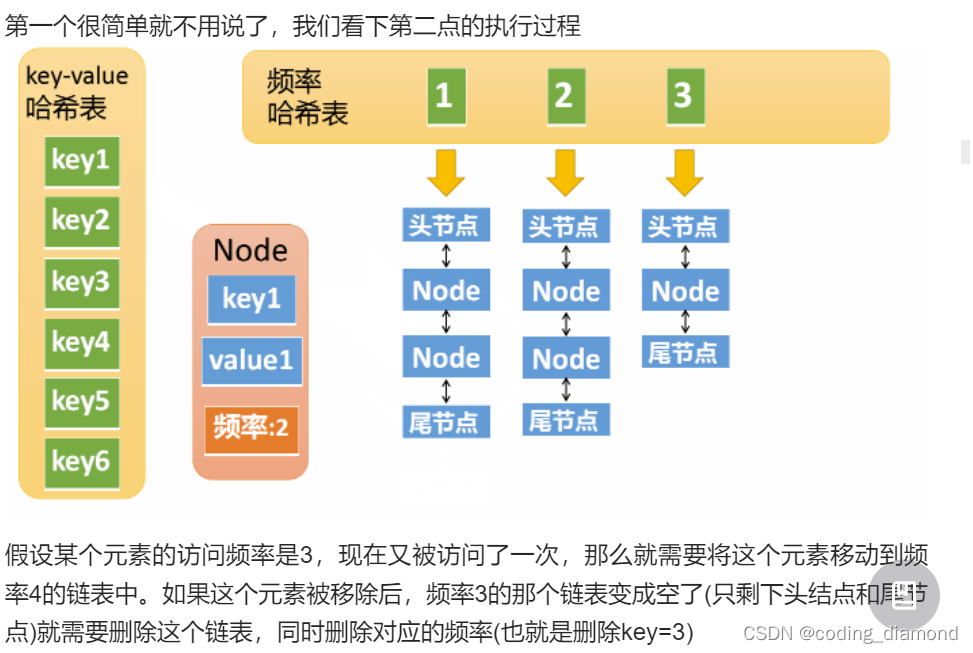

'''
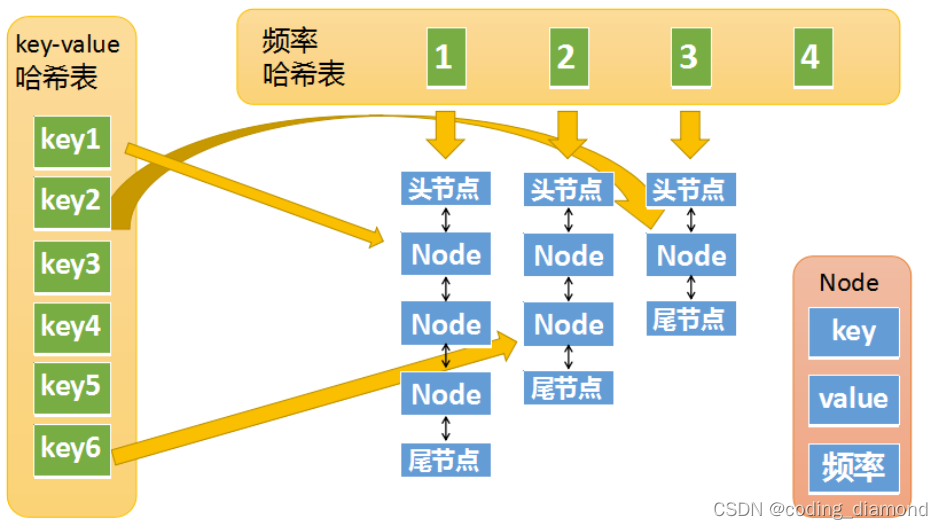
map1: <key, node> node需要保存value,fre
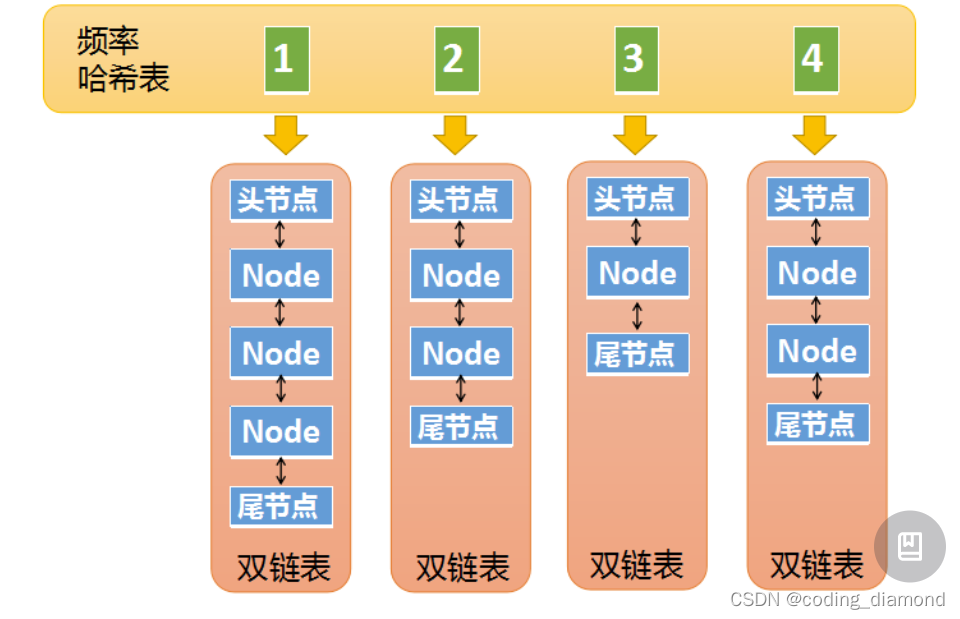
map2: <fre, node_list> node_list 是一个双向链表,时序的维护频次为fre的结点
还需要维护一个min_fre来记录最小的fre避免遍历得到最小的fre保证时间复杂度为O(1)
'''
class Node(object):
def __init__(self, key=0, value=0, fre=0):
self.key = key
self.value = value
self.fre = fre
self.pre = None
self.next = None
class LinkedList(object):
def __init__(self):
self.head = Node()
self.tail = Node()
self.head.next = self.tail
self.tail.pre = self.head
def remove_node(self, node):
node.pre.next = node.next
node.next.pre = node.pre
def addtohead(self, node):
self.head.next.pre = node
node.next = self.head.next
node.pre = self.head
self.head.next = node
def isEmpty(self):
return self.head.next == self.tail
class LFUCache(object):
def __init__(self, capacity):
"""
:type capacity: int
"""
self.use = 0
self.capacity = capacity
self.kvdict = dict()
self.fldict = dict()
self.min_fre = 0
def get(self, key): # 访问操作
"""
:type key: int
:rtype: int
"""
if key in self.kvdict:
node = self.kvdict[key]
list = self.fldict[node.fre]
list.remove_node(node)
if list.isEmpty():
self.fldict.pop(node.fre)
if self.min_fre not in self.fldict: # 一定要注意这里min_fre的设置
self.min_fre += 1
node.fre += 1
if node.fre not in self.fldict:
self.fldict[node.fre] = LinkedList()
self.fldict[node.fre].addtohead(node)
return node.value
else:
return -1
def put(self, key, value):
"""
:type key: int
:type value: int
:rtype: None
"""
if key in self.kvdict: # 值更新操作
node = self.kvdict[key]
list = self.fldict[node.fre]
list.remove_node(node)
if list.isEmpty():
self.fldict.pop(node.fre)
if self.min_fre not in self.fldict:
self.min_fre += 1
node.fre += 1
node.value = value
if node.fre not in self.fldict:
self.fldict[node.fre] = LinkedList()
self.fldict[node.fre].addtohead(node)
else:
if self.capacity != 0:
if self.use >= self.capacity:
# 删除访问次数最少的key
# print("self.min_fre:", self.min_fre)
list = self.fldict[self.min_fre]
node_d = list.tail.pre
list.remove_node(node_d)
if list.isEmpty():
self.fldict.pop(node_d.fre)
self.use -= 1
self.kvdict.pop(node_d.key)
node_new = Node(key, value, 1)
self.use += 1
if 1 not in self.fldict:
self.fldict[1] = LinkedList()
self.fldict[1].addtohead(node_new)
self.kvdict[key] = node_new
self.min_fre = 1














 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









