






主要介绍了一种仿真图像真实化的方法。(synthetic to real)

1.问题:如果针对每个仿真-真实图像对进行训练,需要耗费很大的经历进行图像对的匹配,费时费力。因此,作者提出了一种方案,以集合为单位,将真实图像集的整体风格迁移到仿真图像集。
2.改进tricks:cycle-consistency, custom attention module, temporal regularization, modeling sensor noise, geometric constrains in the image plane, constraints derived from depth maps, contrastive losses.
3.对抗网络:关于图像合成以及风格迁移大多使用了生成的图像,因此需要有一个鉴别器来鉴定生成图像的真实性。这里就需要一个对抗网络。对抗网络往往和生成网络一起训练。这样设置的一个目的就是让鉴别器学习到高层级的语义概念,以此来提供高质量的监督。然而,简单的二分类很难达到这样的效果。因此,作者提出了一些改进的技巧:
(1):在二分类的基础上可以加上一个classification objective.
(2):在输入图像上串接语义分割的图像,达到一个高维的特征空间,并通过单独的网络流进行处理,或者引导一个辅助分类器。
虽然这提供了真实的语义信息(需要annotation),但它将可用于训练的图像集合限制为与手头的合成标签地图兼容的密集注释数据集。于是,在作者的工作中,其使用了一个鲁棒的语义分割网络,用来获得label map,以保证仿真与真实图像风格的一致性。然而,作者并没有使用自己的数据集来训练分割网络,文中给出了原因。
作者从神经补丁鉴别器中获得灵感,在预训练的VGG上训练鉴别器,从VGG的不同层来提取多个特征映射,在每一个特征映射上训练一个鉴别器。
作者使用语义感知采样来解决布局不匹配的问题,并设计了一种简洁的采样策略,不需要训练,直接在patch级别操作,可以保留训练样本的多样性。
4.Methods:
(1)概览
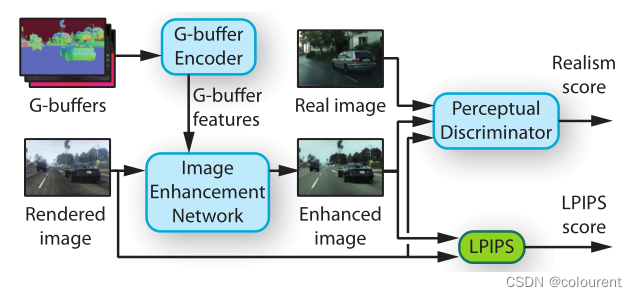
图1 工作流程
作者的方法由一个图像增强网络组成,该网络将渲染图像作为输入并输出增强图像。为了便于加强,向网络提供了额外的输入。具体来说,是从图形渲染pipeline中提取中间渲染缓冲区(G-buffers)。这些gbuffer提供了场景中几何体、材质和光照的信息。它们由G-buffer编码器网络处理,该编码器网络在多个尺度上输出G-buffer特征。然后将g缓冲特征作为输入提供给图像增强网络,在那里它们调制图像特征。
图像增强网络基于HRNetV2,它在各种密集预测任务中表现出很强的性能[87](见图4)。HRNet在不同分辨率下通过多个分支处理图像。重要的是,一个特征流保持在相对较高的分辨率(输入分辨率的1 / 4),以保持良好的图像结构。我们对HRNet架构进行如下修改。首先,我们用正则卷积替换初始的跨行卷积,使网络在全分辨率下运行,并保留更精细的细节。其次,在每个分支的剩余块中,我们通过渲染感知反规范化(RAD)模块替换批规范化层,如第3.2节所述。修改后的块根据从g缓冲区中提取的信息调制特征流。
图像增强网络的训练有两个目标。首先,LPIPS损失[88]会惩罚输入和输出图像之间的巨大结构差异。其次,感知鉴别器评估输出图像的真实感。第3.3节描述的鉴别器是经过训练的。
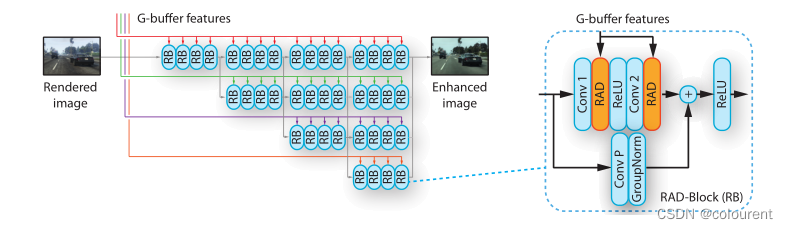
图2 整体网络结构
(2)利用卷积渲染pipeline
tricks:延迟着色、延迟照明、提取Gbuffer、Gbuffer-encoder、RAD modules(Rendering-Aware Denormalization )

图3 输入图像以及在render pipeline中需要的图像信息(Gbuffer)以及语义分割图像
(3)感知鉴别器
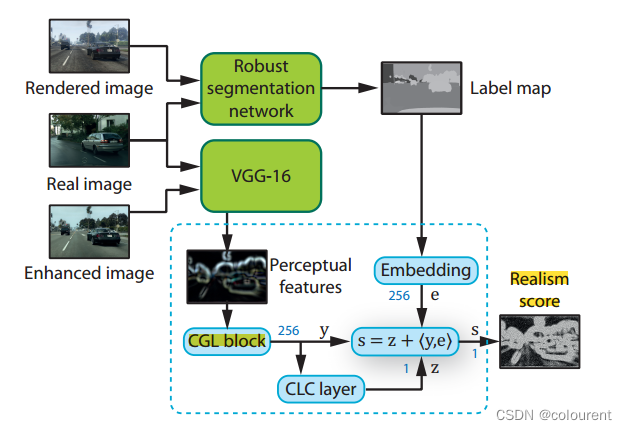
图4 Perceptual Discriminator
使用Mseg进行分割,VGG-16用来提取特征。在分割时,有一些需要注意的点,见原文。
关于分割:将VGG特征提取网络应用于真实图像和增强图像提供了几个抽象级别的感知特征。我们从VGG的relu层中提取特征张量,并为每个级别训练鉴别器网络。通过这种方式,每个网络都在不同的感知水平上进行专门化。鉴别器网络(图4)每个由五个Convolutional GroupNorm LeakyReLU(CGL)层的堆栈组成,其产生256维特征张量y,以及Concolution-LeakyReLU-Convolution(CLC)层,其将特征张量向下投影到单个通道映射z。特征张量y通过内积与嵌入张量e进一步融合。嵌入张量包含了每像素256维,从label maps中学来。
(4)布局差异问题
在作者使用的对抗性设置中,鉴别器被训练来对图像进行分类,为每个图像或像素分配真实或虚假标签。在训练过程中,鉴别器会拾取任何可以轻松区分真实图像和伪造图像的特征。例如,如果传感器噪声存在于真实图像中,但不存在于合成图像中,则鉴别器将很快学会将有噪声的补丁正确地标记为真实的。将梯度从鉴别器反向传播到生成器鼓励生成器向合成图像添加噪声,使其看起来更逼真。
当可以通过依赖于伪特征来区分伪图像和真实图像时,就会出现问题。例如,从图5中的概率密度图中可以看出,在GTA V的图像顶部看到天空的概率远高于城市景观。相反,在相同的位置,在城市景观中比在GTAV中更容易找到树木。因此,在来自两个数据集的均匀采样图像上训练的分类器可以通过检查图像的顶部来容易地识别来自城市景观的(真实)图像。如果顶部包含一些类似树木的纹理,则更有可能是真实的。让这个鉴别器在对抗性训练设置中工作,将推动生成器在天空中放置树木。

图6 场景布局的概率分布
(5)采样匹配补丁
作者的分析表明,GTA和Cityscapes的随机采样图像在预期布局上有所不同,尽管它们可能包含相同类型和数量的物体。基于此,作者提出了一种新的采样策略:
a). 将裁剪尺寸缩小到仅占完整图像的7%左右。
b).在数据集之间匹配采样的补丁,以平衡鉴别器对象的分布。
具体而言,b).使用VGG网络处理合成图像中的补丁,在ImageNet上进行预训练,并提取最后一个relu层的特征张量。以196像素的宽度裁剪贴片,这对应于VGG在该层的感受野。因此,获得了每个补丁1×1×512维的特征向量。设φ(pi)表示根据面片pi计算的特征向量。如果两个补丁的余弦相似性大于0.5,则认为它们是匹配的。
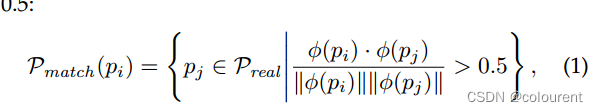
为了提高效率,对φ(pi)进行单位归一化,并通过FAISS计算L2距离。每个数据集的图像,我们采样75个补丁。对于合成数据集的每个补丁,我们保留目标数据集的10个最近的补丁,从而产生1300万对。在训练过程中,我们从这些对中进行采样,以使合成数据集中的所有像素都以相同的频率出现。GTA和城市景观的匹配补丁示例如图7所示。

图7 匹配补丁示意图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









