







 本文介绍了朴素贝叶斯分类的基本概念,包括贝叶斯定理及其在分类问题中的应用。通过一个简单的文本分类例子,展示了如何使用Python实现朴素贝叶斯分类算法,涉及代码示例,并提及参考书籍。
本文介绍了朴素贝叶斯分类的基本概念,包括贝叶斯定理及其在分类问题中的应用。通过一个简单的文本分类例子,展示了如何使用Python实现朴素贝叶斯分类算法,涉及代码示例,并提及参考书籍。
贝叶斯定理:
这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率: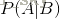
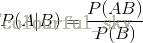
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理: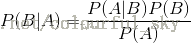
其实分类在我们的日常生活当中每时每刻都在用,当我们看见一个苹果,我们会判断它为一个苹果而不是一个梨异或是一头大象的依据是它的外观,颜色,重量等等这些特征。首先我们知道了它是一个待分类的物体A,然后判断它属于哪一类,苹果B1?梨B2?大象B3?狮子B4?姑且就判断它属于这四类中的哪一类。其中这四类都有的特征是[‘颜色’, ‘体重’],事先我们已经有了很多的已经训练好的样本,也就是P(B)已知。然后通过求P(A|B)P(B)的最大化来求待分类物体属于哪一类。可能表达得不太清楚,但实际就是这么个意思。具体流程参看下面分类流程以及文末的参考博客。

以下以Python语言实现简单文本的朴素贝叶斯分类:
Nbayes.py
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
from Nbayes_lib import *
dataSet,listClasses = loadDataSet() #导入外部数据集
nb = NBayes() #类的实例化
nb.train_set(dataSet,listClasses) #训练数据集
nb.map2vocab(dataSet[2]) #随机选择一个测试句,这里2表示文本中的第三句话,不是脏话,应输出0。
print (nb.predict(nb.testset)) #输出分类结果Nbayes_l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









