










mahout 实用教程 (一)
—by comaple.zhang
本文力求把mahout从使用的角度为读者建立一个框架,为后续的使用打下基础。本文为原创文章转载请注明原网址http://blog.csdn.net/comaple,谢谢。下面首先给出源代码svn地址以及用于测试的公共数据集,大家可以下载并测试。
mahout svn仓库地址:http://svn.apache.org/repos/asf/mahout/trunk
movie length 数据地址:http://www.grouplens.org/system/files/ml-100k.zip
1. mahout简介
The Apache Mahout™ machine learning library's goal is to build scalable machine learning libraries.
Classification
Logistic Regression (SGD)
Support Vector Machines (SVM)
Clustering
Pattern Mining
Dimension reduction
Singular Value Decomposition and other Dimension Reduction Techniques
Stochastic Singular Value Decomposition with PCA workflow
Independent Component Analysis
Gaussian Discriminative Analysis
Recommenders / Collaborative Filtering
Non-distributed recommenders ("Taste")
Distributed Item-Based Collaborative Filtering
Collaborative Filtering using a parallel matrix factorization
2. 应用于推荐系统(item-based/user-based/slopone)
2.1小型网站直接集成即可使用(user-based/item-based)
协同过滤主要分为:计算相似度è预测评分è产生推荐
Preferenceinferre 0.8版本变为capper,他的作用是:评估用户的缺失评分值:
2.1.1 User-based的实现
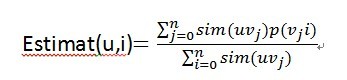
用户u对第i个商品的评分预测:u为当前用户,vi为第i个用户,p(vi)为第i个用户对当前item的评分。
protected float doEstimatePreference(long theUserID, long[] theNeighborhood, long itemID) throws TasteException {
if (theNeighborhood.length == 0) {
return Float.NaN;
}
DataModel dataModel = getDataModel();
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
for (long userID : theNeighborhood) {
if (userID != theUserID) {
// See GenericItemBasedRecommender.doEstimatePreference() too
Float pref = dataModel.getPreferenceValue(userID, itemID);
if (pref != null) {
double theSimilarity = similarity.userSimilarity(theUserID, userID);
if (!Double.isNaN(theSimilarity)) {
preference += theSimilarity * pref;
totalSimilarity += theSimilarity;
count++;
}
}
}
}
2.1.2 Item-based的实现

第i个item被用户u评分预测,sim(i,j)第i个商品与第j个商品的相似度,p(vj,u)表示用户u对第j个商品的评分。
protected float doEstimatePreference(long userID, PreferenceArray preferencesFromUser, long itemID)
throws TasteException {
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
double[] similarities = similarity.itemSimilarities(itemID, preferencesFromUser.getIDs());
for (int i = 0; i < similarities.length; i++) {
double theSimilarity = similarities[i];
if (!Double.isNaN(theSimilarity)) {
// Weights can be negative!
preference += theSimilarity * preferencesFromUser.getValue(i);
totalSimilarity += theSimilarity;
count++;
}
}
Mathout中实现的相似度度量
PearsonCorrelationSimilarity皮尔逊距离
皮尔森相关系数等于两个变量的协方差除于两个变量的标准差。

缺点:没有考虑(take into account)用户间重叠的评分项数量对相似度的影响;
EuclideanDistanceSimilarity 欧几里德距离

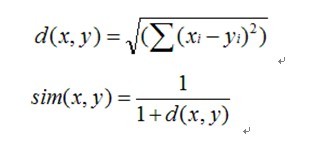
缺点:
CosineMeasureSimilarity 余弦距离(0.7变成了UncenteredCosineSimilarity)
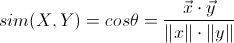
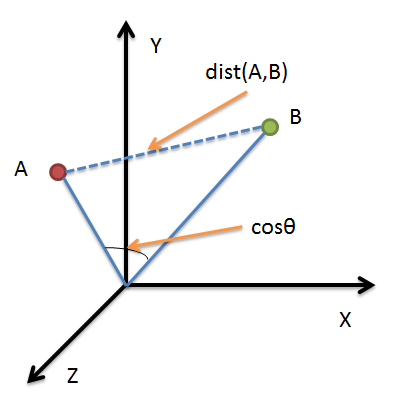
标准余弦相似度对方向敏感但对数值不敏感,比如用户对内容评分,5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得出的结果是0.98,两者极为相似,但从评分上看X似乎不喜欢这2个内容,而Y比较喜欢,为了修正这种不合理性,就出现了调整余弦相似度,Mahout给出了调整余弦相似度的实现。即所有维度上的数值都减去一个均值。
SpearmanCorrelationSimilarity斯皮尔曼等级相关
TanimotoCoefficientSimilarity谷本相关系数
LogLikelihoodSimilarity 对数似然相似度
CityBlockSimilarity基于曼哈顿距离
2.2离线计算,基于中间数据再开发(item-based/slopone)
2.2.1 mahout的源代码结构

Item-based和slopone都有hadoop实现和单机版实现。User-based没有。
Item-based recommender使用命令:
mahout org.apache.mahout.cf.taste.hadoop.item.RecommenderJob -i input -o output --maxPrefsPerUser 100 -- numRecommendations 20
-s SIMILARITY_COSINE
Item-item 相似商品:
mahout org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob --input user-item --output similarity --similarityClassname SIMILARITY_PEARSON_CORRELATION --maxSimilaritiesPerItem 120 --maxPrefsPerUser 1200 --minPrefsPerUser 2
3应用于机器学(贝叶斯/模式挖掘/聚类等…)
3.1快速建模/模型评估

$MAHOUT_HOME/bin/mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
将该数据放到testdata目录下,算法的输出放到output目录下:、
可以采用 mahout clusterdump来查看结果数据也可以输出到本地文件。
Recommender的评估
RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();

Cluster的模型评估可以参考:
http://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html
创建seqdirectory
./bin/mahout seqdirectory \
-i ${WORK_DIR}/20news-all \
-o ${WORK_DIR}/20news-seq
将seqdirectory转换为向量
./bin/mahout seq2sparse \
-i ${WORK_DIR}/20news-seq \
-o ${WORK_DIR}/20news-vectors -lnorm -nv -wt tfidf
3.2例如PFPGrowth
mahout fpg -i pfp/order_01.txt -o pfp/patterns/output.txt -k 50 -method mapreduce -regex '[\ ]' -s 2
pfpgrowth论文参照:http://infolab.stanford.edu/~echang/recsys08-69.pdf
结果示例:
Key: 0: Value: ([0],14), ([368, 0],7), ([0, 53],5), ([368, 0, 53],4), ([950, 0],4), ([682, 826, 523, 950, 277, 475, 0],3), ([682, 826, 523, 950, 475, 0],3), ([183, 0],3), ([168, 0],3), ([682, 826, 523, 168, 950, 277, 475, 0],2), ([368, 684, 401, 428, 0, 53],2), ([368, 871, 239, 0, 257],2), ([368, 766, 183, 0, 831],2), ([368, 684, 401, 428, 0],2), ([937, 57, 450, 0],2), ([710, 173, 0, 731],2), ([368, 871, 239, 0],2), ([368, 766, 183, 0],2), ([710, 173, 0],2), ([419, 581, 0],2), ([368, 4, 0],2), ([368, 242, 0],2), ([183, 366, 0],2), ([676, 0],2), ([460, 0],2), ([35, 0],2), ([298, 0],2), ([171, 0],2), ([10, 0],2)














 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









