






这两天做性能测试碰见一个问题,比较有意思。
一条SQL,使用了绑定变量,查看V$SQLAREA发现version_count是2,

查看V$SQL,发现有两条记录,分别对应了0和1两个child cursor:

再查看这两个child cursor对应的执行计划:
child cursor:0
----------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | | 1 | SORT ORDER BY | | 1 | 196 | 2 (50)| 00:00:01 | |* 2 | TABLE ACCESS BY INDEX ROWID| T | 1 | 196 | 1 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | IDX_T_01 | 1 | | 1 (0)| 00:00:01 | -----------------------------------------------------------------------------------------------------
child cursor:1
----------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 3 (100)| | | 1 | SORT ORDER BY | | 1 | 75 | 3 (34)| 00:00:01 | |* 2 | TABLE ACCESS BY INDEX ROWID| T | 1 | 75 | 2 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | IDX_T_01 | 1 | | 1 (0)| 00:00:01 | -----------------------------------------------------------------------------------------------------
发现除了成本代价略有不同,其他访问路径完全一致。应用保证使用的相同用户执行这条SQL语句,绑定变量窥探关闭。问题就来了,为何同一条SQL有两个child cursor,且执行计划一致?
再抛一下,通过V$SQL_SHARED_CURSOR视图可以查看游标失效的原因,对比这两个cursor,不同之一就是这个ROLL_INVALID_MISMATCH字段的值,0号cursor值为N,1号cursor值为Y,

另外,REASON字段,0号cursor显示了内容,1号cursor该字段值为空。
Rolling Invalidate Window Exceeded(3)
- 1
- 1
这个问题通过Rolling Cursor Invalidations with DBMS_STATS.AUTO_INVALIDATE (文档 ID 557661.1)这篇文章能够很好地解释。
大体意思是在10g之前,使用dbms_stats采集对象统计信息,除非no_invalidate设为TRUE,否则所有缓存在Library Cache中的游标都会失效,下次执行时需要做硬解析。隐患就是对于一个OLTP系统,会产生一次硬解析风暴,消耗大量的CPU、库缓存以及共享池latch的争用,进而影响应用系统的响应时间。如果设置no_invalidate为FALSE,则现有存储的游标不会使用更新的对象统计信息,仍使用旧有执行计划,直到下次硬解析,要么因为时间太久,导致cursor被刷出,要么手工执行flush刷新了共享池,这两种情况下会重新执行硬解析,根据更新的对象统计信息,生成更新的执行计划。这么做其实还是有可能出现硬解析风暴,特别是OLTP系统,高并发时候,有SQL语句频繁访问。
使用dbms_stats.gather_XXX_stats的时候,有个参数no_invalidate,
TRUE: does not invalidate the dependent cursors
FALSE: invalidates the dependent cursors immediately
AUTO_INVALIDATE (default): have Oracle decide when to invalidate dependent cursors
默认是AUTO_INVALIDATE,这表示是由Oracle来决定什么时候让依赖的游标失效。
10g之后,如果采集对象统计信息使用的no_invalidate参数是auto_invalidate,则Oracle会采用如下操作,来缓解可能的硬解析风暴。
1.执行dbms_stats,所有依赖于这个已分析对象的缓存cursor游标会被标记为rolling invalidation,并且记录此时刻是T0。
2.下次某个session需要解析这个标记为rolling invalidation的cursor游标时,会设置一个时间戳,其取值为_optimizer_invalidation_period定义的最大值范围内的一个随机数。之所以是随机数,就是为了分散这些 invalidation的游标,防止出现硬解析风暴。参数_optimizer_invalidation_period默认值是18000秒,5小时。记录这次解析时间为T1,时间戳值为Tmax。但此时,仍是重用了已有游标,不会做硬解析,不会使用更新的统计信息来生成一个新的执行计划。
3.接下来这个游标(标记了rolling invalidation和时间戳)的每次使用时,都会判断当前时刻T2是否超过了时间戳Tmax。如果未超过,则仍使用已存在的cursor。如果Tmax已经超过了,则会让此游标失效,创建一个新的版本(一个新的child cursor子游标),使用更新的执行计划,并且新的子游标会标记V$SQL_SHARED_CURSOR中ROLL_INVALID_MISMATCH的值。
这些和我上面碰见的情况基本一致。
MOS是附带了一个实验,可以根据实验来体会下这种情况。
1.为了容易观察,设置_optimizer_invalidation_period为1分钟,
alter system set "_optimizer_invalidation_period"=60;
- 1
- 1
2.创建测试表,并采集统计信息,
create table X as select * from dba_tables;
exec dbms_stats.gather_table_stats(null,'X');
- 1
- 2
- 2
3.执行一次目标SQL,并查看V$SQL_SHARED_CURSOR信息,
select count(*) from X;
select sql_id from v$sql where sql_text='select count(*) from X';
select * from v$sql_shared_cursor where sql_id='95rckg79jgshh';
select * from v$sql_shared_cursor where sql_id='95rckg79jgshh';
SQL_ID ADDRESS CHILD_AD CHILD_NUMBER U S O O S L F E B P I S T A B D L T
------------- -------- -------- ------------ - - - - - - - - - - - - - - - - - -
B I I R L I O E M U T N F A P T D L D B P C S C P T M B M R O P M F L P L A F L
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
R L H P B U
- - - - - -
REASON
--------------------------------------------------------------------------------
95rckg79jgshh 524A2434 524A216C 0 N N N N N N N N N N N N N N N N N N
N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N
N N N N N N
此时查看这条SQL的解析和执行次数都是1,

4.再执行一次目标SQL,
select count(*) from X;
- 1
- 1
查看这条SQL的解析和执行次数是2,

有人曾说过,11g中未必会按照_optimizer_invalidation_period参数定义的时间产生新的子游标,我上面用的环境是11g,确实如此,等了2分钟,执行目标SQL,仍只有一个子游标。这样的好处有人也说了,就是更加的随机,因为如果严格按照参数设置的时间失效,则有可能频繁使用的游标会在超时后某一时刻集中做硬解析,还是会有资源的影响,只是时间推迟了,因此如果是在超时值基础上又有随机分布,则可能会将硬解析的影响降到最低。
又等了一段时间,再查询V$SQL,
确实产生了两个子游标,这里需要注意FIRST_LOAD_TIME的时间是一样的,因为他是parent父游标的创建时间,显然这两个子游标肯定是对应同一个父游标,不同的就是LAST_LOAD_TIME,这是子游标的使用时间。
再看看V$SQL_SHARED_CURSOR,
两个子游标信息,只有一个R项值有差别,R是ROLL_INVALID_MISMATCH,0号子游标是N,1号子游标是Y,看看官方文档对这个字段的说明,
表示的就是标记为rolling invalidation的游标,已经是超过了时间窗口,此时0号子游标已经过期,1号子游标使用最新的统计信息,来生成最新的执行计划。



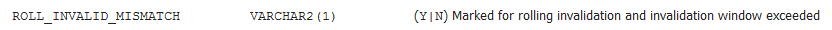
这就解释了为何同一条SQL,执行计划一致,但却有两个子游标的情况。
MOS中还描述了一些游标使用的场景:
1.如果一个游标被标记为rolling invalidation,但是再不会做解析,则这个游标不会失效,最终还是可能根据LRU被刷出共享池。
2.如果一个游标被标记为rolling invalidation,后面只会解析一次,那么这个游标依然不会失效(仅仅使用时间戳标记),最终还是可能根据LRU被刷出共享池。
3.频繁使用的游标,在超过时间戳Tmax值后,下次解析时就会被置为失效。
很明显,上面的这些方法是有效的,因为失效标记仅仅适用于这些频繁重用的游标,对于其他场景的游标可以忽略,未有影响。
总结:
1.凡事有因果,同一条SQL,执行计划相同,但产生了两个子游标,总会有其的原因,上面游标失效标记可能是一个原因,当然还有可能是其他原因。
2.对于FIRST_LOAD_TIME这些字段的理解,还是要准确些,不能断章取义。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/7192724/viewspace-2123971/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/7192724/viewspace-2123971/















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









