






实验:
创建表
create table t as select * from dba_objects ;
查看段,以及块的数目
select extents,blocks from user_segments where segment_name = 'T' ;
查看表,以及表的数目
select num_rows , blocks from user_tables where table_name='T' ;
创建直方图:
SQL>exec dbms_stats.gather_table_stats(user,'t',method_opt=>'for all columns size 254');
创建直方图后,统计信息就会比较准
set autotrace trace exp ;
select * from t where object_id=1 ;
DBMS_STATS包和analyze命令:
analyze : 已经过时
1. 无法提供灵活的分析选项
2. 无法提供并行分析
3. 无法对分析数据进行管理
DBMS_STATS:
1. 专门为CBO提供信息来源
2. 可以进行数据分析的多种组合
3. 可以对分区进行分析
4. 可以进行分析数据管理
-- 备份,恢复,删除,设置
oracle自动信息收集
user_tab_modification跟踪表:这个表记录了表的修改,当分析对象的数据修改超过10%,oracle会重新分析。
定时任务:GATHER_STATS_JOB负责重新定时
当插入到表数据以后, user_tab_modification并不会马上记录,会有延迟的。
如果要马上生效,可以用SQL>exec DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO ;
查看视图DBA_SCHEDULER_JOB_RUN_DETAILS 来显示JOB的运行情况。
eg: select log_id,job_name,status from dba_scheduler_job_run_details where job_name='GATHER_STATS_JOB';
表分析:
DBMS_STATS.GATHER_TABLE_STATS
eg: SQL>exec dbms_stats.gather_table_stats(user,'t');
但如果表很大,采样比例尽量小一些,否则会消耗很多时间的。
SQL>exec dbms_stats.gather_table_stats(user,'t',cascade=>true);
这个语句表示分析表的同时,也分析索引。
索引分析:
DBMS_STATS.GATHER_INDEX_STATS
对于小表来说,可以全表扫描,而大表,尽量要小些。
granularity数据分析的力度:
这个参数用于分区表的采样,它的值包含:global , partition , subpartition
global:针对整个表的数据分析
partition:针对分区的数据分析
subpartition: 针对分区表的子分区的分析
查看分区表的块情况
select * from user_tab_partitions where table_name='T' ;
select * from user_tables where table_name='T' ;
SQL>exec dbms_stats.gather_table_statis(user,'TG',granularity=>'partition');
表上已经有全局统计信息时,单独对分区分析,不会更新全局信息。
当表上没有全局信息的时候,单独对分区分析,会更新全局信息。
删除全局分区的统计信息命令:
SQL>exec dbms_stats.delete_table_stats(user,'t',cascade_parts=false ) ;
11g以后增量全局分析来更新全局信息:
SQL>exec dbms_stats.set_table_preps(user,'t','incremental','true');
SQL>exec dbms_stats.gather_table_stats(user,'t');
select num_rows,blocks,global_stats from user_tables
where table_name='T' ;
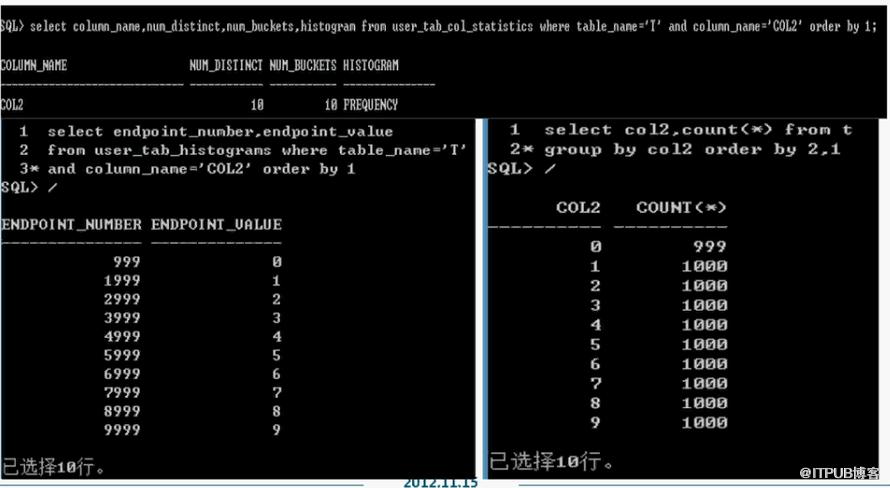
直方图:只有在收集了直方图以后,oracle才知道哪个值有多少条记录。

平衡直方图:

frequent直方图:
gather_table_stats.method_opt参数 :
for all columns 统计所有列
for all indexed columns 统计所有索引
for columns list size
N的取值为1-254
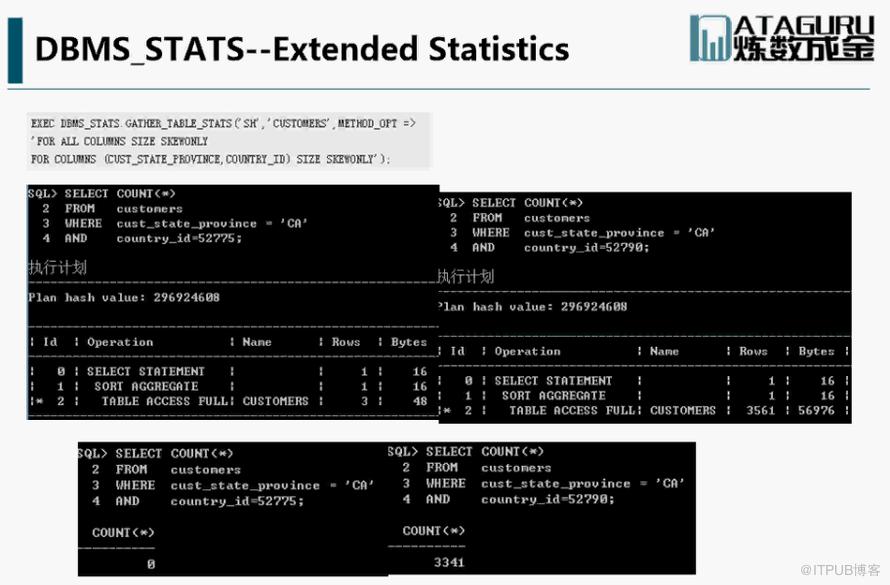
扩展分析 ,相关性查询:
动态采样:
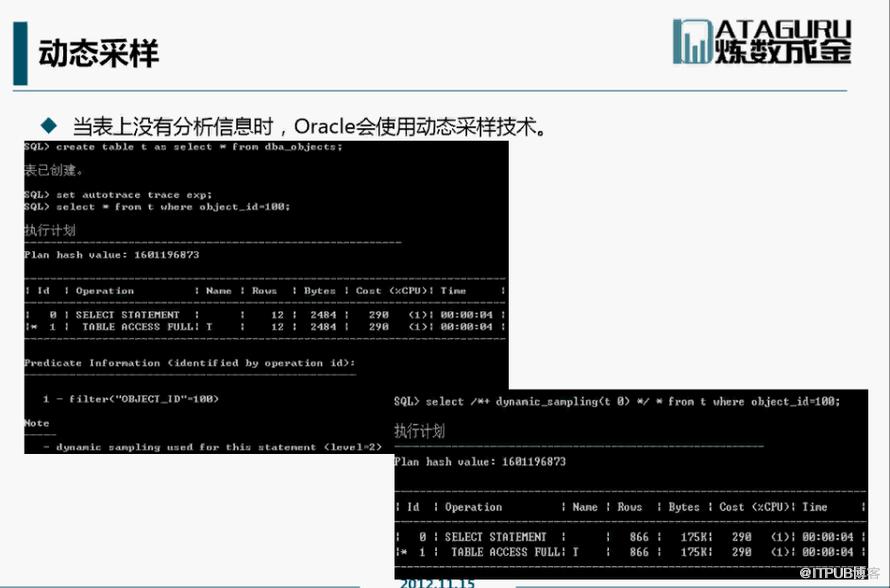
动态采样是有级别的,1-10,级别越高,采样 时间越长。
对于OLAP系统,没有多少用户去连接,反而执行计划的结果更重要,因此OLAP系统可以将动态采样的级别设置高一些。

创建表
create table t as select * from dba_objects ;
查看段,以及块的数目
select extents,blocks from user_segments where segment_name = 'T' ;
查看表,以及表的数目
select num_rows , blocks from user_tables where table_name='T' ;
创建直方图:
SQL>exec dbms_stats.gather_table_stats(user,'t',method_opt=>'for all columns size 254');
创建直方图后,统计信息就会比较准
set autotrace trace exp ;
select * from t where object_id=1 ;
DBMS_STATS包和analyze命令:
analyze : 已经过时
1. 无法提供灵活的分析选项
2. 无法提供并行分析
3. 无法对分析数据进行管理
DBMS_STATS:
1. 专门为CBO提供信息来源
2. 可以进行数据分析的多种组合
3. 可以对分区进行分析
4. 可以进行分析数据管理
-- 备份,恢复,删除,设置
oracle自动信息收集
user_tab_modification跟踪表:这个表记录了表的修改,当分析对象的数据修改超过10%,oracle会重新分析。
定时任务:GATHER_STATS_JOB负责重新定时
当插入到表数据以后, user_tab_modification并不会马上记录,会有延迟的。
如果要马上生效,可以用SQL>exec DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO ;
查看视图DBA_SCHEDULER_JOB_RUN_DETAILS 来显示JOB的运行情况。
eg: select log_id,job_name,status from dba_scheduler_job_run_details where job_name='GATHER_STATS_JOB';
表分析:
DBMS_STATS.GATHER_TABLE_STATS
eg: SQL>exec dbms_stats.gather_table_stats(user,'t');
但如果表很大,采样比例尽量小一些,否则会消耗很多时间的。
SQL>exec dbms_stats.gather_table_stats(user,'t',cascade=>true);
这个语句表示分析表的同时,也分析索引。
索引分析:
DBMS_STATS.GATHER_INDEX_STATS
对于小表来说,可以全表扫描,而大表,尽量要小些。
granularity数据分析的力度:
这个参数用于分区表的采样,它的值包含:global , partition , subpartition
global:针对整个表的数据分析
partition:针对分区的数据分析
subpartition: 针对分区表的子分区的分析
查看分区表的块情况
select * from user_tab_partitions where table_name='T' ;
select * from user_tables where table_name='T' ;
SQL>exec dbms_stats.gather_table_statis(user,'TG',granularity=>'partition');
表上已经有全局统计信息时,单独对分区分析,不会更新全局信息。
当表上没有全局信息的时候,单独对分区分析,会更新全局信息。
删除全局分区的统计信息命令:
SQL>exec dbms_stats.delete_table_stats(user,'t',cascade_parts=false ) ;
11g以后增量全局分析来更新全局信息:
SQL>exec dbms_stats.set_table_preps(user,'t','incremental','true');
SQL>exec dbms_stats.gather_table_stats(user,'t');
select num_rows,blocks,global_stats from user_tables
where table_name='T' ;
直方图:只有在收集了直方图以后,oracle才知道哪个值有多少条记录。

平衡直方图:

frequent直方图:

gather_table_stats.method_opt参数 :
for all columns 统计所有列
for all indexed columns 统计所有索引
for columns list size
N的取值为1-254
扩展分析 ,相关性查询:

动态采样:

动态采样是有级别的,1-10,级别越高,采样 时间越长。
对于OLAP系统,没有多少用户去连接,反而执行计划的结果更重要,因此OLAP系统可以将动态采样的级别设置高一些。

来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/29196873/viewspace-1137314/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/29196873/viewspace-1137314/















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









