







业务流测试(各种功能) 对应的是单接口测试
-业务流本质上还是接口关联
技术1:
-动态数据替换
用if可以实现 但是如果要替换的数据很多的话,就要写很多的if
-正则表达式
正则表达式是通用的编程语言,是一种字符串的模糊匹配技术(基于一个规则去匹配字符串当中的内容),匹配的需要是连在一起的子字符串,只要想在字符串中符合规律的子字符串,基本上都可以使用正则表达式
正则表达式在python中应用,re模块
-基本语法
参数:pattern 表达式(字符串类型) string 需要匹配的字符串
import re
#需要匹配的字符串,需要连在一起的子字符串
string = "@12abc45"
#基本用法,直接匹配想要的字符串
result = re.search(pattern="abc",string=string)
print(result)每次匹配到的结果是一个对象![]()
需要用group方法提取匹配的子字符串![]()
re.match:从字符串开头开始匹配,返回的是一个对象
re.search:在字符串中匹配一个符合规则的子字符串,返回的是一个对象
re.findall:在字符串中匹配所有符合规则的子字符串,返回列表
re.finditer:在字符串中匹配所有符合规则的子字符串,返回一个对象,对象里有多个匹配的结果
![]()
需要遍历对象获得每次匹配到的结果
规则:是一个字符串,由一个或者多个(表示字符+表示次数/数量)组成(可用+隔开).表示原字符串里的子字符串需要跟这个规则匹配
如:表示符合规则的11位手机号,第一个数字要匹配1 第二个数字要匹配[]里面的任意一个,之后的是数字,出现次数为9
string = '15301017834'
#匹配手机号
import re
result = re.search(r"1+[35678]+\d{9}",string)
print(result)
表示字符
. :表示任意字符(\n除外)
在没有边界的情况下,默认匹配第一个
string = "@12abc45"
result = re.search(pattern=".",string=string)
print(result)![]()
在有特定边界的情况下,匹配边界之间(包括边界字符)的字符(匹配需要是连起来的字符)
string = "@12abc45"
#匹配指定子字符串与它后一个字字符串
result = re.search(pattern="c.",string=string)
print(result)![]()
[abc] : 匹配a或者b或者c中的一个
string = "@12abc45"
#[abc] 匹配a或者b或者c,只取其中一个
result = re.search(pattern="[abc]",string=string)
print(result)![]()
\d :只匹配数字
string = "@12abc45"
result = re.search(pattern="\d",string=string)
print(result)![]()
表示数量/次数
{n} :表示匹配某种字符n次
匹配数字n次

{n,} :表示匹配某种字符至少n次,到无限次
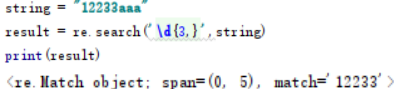
{m,n} : 表示匹配某种字符串m次或者n次之间(包含m,n)

* : 表示匹配某个字符尽可能少(0次)或者尽可能多(无限次)
string = "aaaa7bc45"
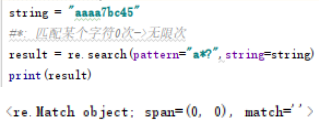
#*: 匹配某个字符0次->无限次
result = re.search(pattern="a*?",string=string)
print(result)![]()
拓展:python中,*默认开启的是贪婪模式,就是获取尽可能多的次数
非贪婪模式: 获取尽可能少(0次)的次数
匹配任意字符串尽可能多(无限次)的次数
string = "aaaa7bc45"
#python使用正则表达式,默认启用贪婪模式,优先尽可能多的次数
result = re.search(pattern=".*",string=string)
print(result)#结果是整个字符串![]()
匹配任意字符串尽可能少(0次)的次数
string = "aaaa7bc45"
#开启非贪婪模式(自动化测试需要)
result = re.search(pattern=".*?",string=string)
print(result)#结果为空字符![]()
边界
存在边界,匹配的字符要在边界范围内
-贪婪模式下,要尽可能多地获取两个#号之间的字符
string = '{"member_id":"#pwd#","amount":#money#}'
import re
#存在边界# #,所以要尽可能拿去两个#之间的字符
result = re.search('#.*#',string)
print(result)![]()
这里有4个#号,贪婪模式下尽可能多获取字符,存在边界就是只能匹配边界范围内的,不能超过边界
也就是第一和第四个#号之间
-非贪婪模式下,尽可能少获取两个#号之间的字符(自动化测试)
string = '{"member_id":"#pwd#","amount":#money#}'
import re
#存在边界# #,所以要尽可能拿去两个#之间的字符
result = re.search('#.*?#',string)
print(result)![]()
非贪婪模式下,只会尽可能少地获取最近的两个#号里面的值,尽可能少也包括0次,但是存在边界值,必须要拿到包括前后#号夹着的字符,就是说最少也要获取最前面两个之间里的字符
分组
在规则字符串中间加( ),表示分组
string = '{"member_id":"#pwd#","amount":#money#}'
result = re.search('#(.*?)#',string)
#.group 正则表达式匹配到的整个结果
print(result.group())
#参数为1,表示第一个括号里的字符
print(result.group(1))group()默认参数是0,表示匹配到整个相匹配的子字符串![]()
group(1),表示匹配到的整个子字符串中第一个括号里的子字符串![]()
自动化测试中使用:为了动态提取类/对象的属性
实战演示
把字符串里带有#标记的提取出来,并且动态替换类的属性
string = '{"member_id":"#pwd#","amount":#money#}'
class Data:
pwd = "123456"
money = 100方法1: if判断
#if
if "#pwd#" in string:
string = string.replace("#pwd#",Data.pwd)
if "#money#" in string:
string = string.replace("#money#",str(Data.money))
print(string)方法2: 正则表达式
#正则表达式
import re
result = re.finditer("#(.*?)#",string)
print(result)用finditer方法表示找到所有符合规则的子字符串,获取到的结果是一个对象,需要用for循环得到每次匹配的子字符串
![]()
-替换字符串
需要准备好替换的数据:类/实例属性,要跟原字符串的标记名称相同
for el in result:
old = el.group()#获取匹配字符串 #pwd#
prop_name = el.group(1) # pwd
string = string.replace(old,str(getattr(Data,prop_name)))
#标记的字符串,要跟类/对象的属性名称相同,才能被获取到思路:
通过断点可以看出,循环第一次,old匹配到的是#pwd#, prop_name的结果是pwd,然后通过动态获取类的属性getarrt(类名,属性名)获取需要替换的属性值,最后通过replace把字符串相应的子字符串替换成属性值
注意:因为是循环,每次的获取的属性名称要不一样,所以需要动态获取,而标记的字符串,要跟类/对象的属性名称相同,才能被获取















 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









