







面试题
List快速去重
1、将list对象的hashcode和equals方法重写
2、放到hashSet里,然后取出来
HashSet如何去重的
1、HashSet去重是根据HashMap来实现的,因为HashSet实现原理是HashMap
2、HashMap去重是根据hashcode和eques方法实现的
如何解决 ArrayList 线程不安全问题(印象最深刻)
使用多线程来处理业务逻辑,但是没在意 ArrayList 是线程不安全的了,在多个线程同时使用同一个 ArrayList 后出现了 ConcurrentModificationException 异常。
线程不安全案例:
多线程情况下使用 ArrayList 会出现线程不安全问题。
List<String> list = new ArrayList<>();
for (int i = 1; i <= 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(Thread.currentThread().getName() + ":" + list);
}).start();
}
故障现象: 出现 java.util.ConcurrentModificationException 异常。(背下来)
导致原因: 一个线程正在写入数据,另一个线程来抢夺后写数据,导致数据不一致异常。并发修改异常。
解决方案:
- 使用
Vector,Vector将每个方法都加了synchronized修饰来达到线程安全的目的,性能太低,基本不使用。 - 通过
Collections.synchronizedList工具方法转换成一个线程安全的List。 - 使用
CopyOnWriteArrayList写时复制(读写分离思想)集合类。
Collection 和 Collections的区别
Collection:
是 java.uitl 下的接口,他是各种集合的父接口,继承于它的接口主要有set 和list。
Conllecitons:
是个java.util下的类,是针对集合的工具类,提供一系列静态方法对各种集合的搜索,排序,线程安全化等操作。
ArrayList集合加入1万条数据,应该怎么提高效率?
直接初始化ArrayList集合的初始化容量为1万,避免扩容带来的性能影响。
ArrayList 的扩容机制是什么
ArrayList底层是数组elementData,用于存放插入的数据。
初始大小是0,当有数据插入时,会初始化一个默认容量大小为10的数据。
当添加元素时,如果元素个数+1> 当前数组长度 【size + 1 > elementData.length】时,进行扩容,扩容后的数组大小时1.5倍。
通过 Arrays.copyOf(elementData, newCapacity); 方法进行扩容。
会创建一个1.5倍的新数组,然后通过 System.arraycopy 方法将旧数组中的值复制到新数组。
为什么放大因子是1.5?
扩容容量不能太小,防止频繁扩容,频繁申请内存空间 + 数组频繁复制;
扩容容量不能太大,需要充分利用空间,避免浪费过多空间。
集合体系
单列集合(Collection)
List:
ArrayList查询快,增删慢,底层维护了一个Object数组LinkedList查询慢,增删快,底层使用了链表数据结构Vector与ArrayList一样,是线程安全的,所有操作方法加上了Synchronize同步非法,效率低
Set:
HashSet存储速度快,底层使用Hash表支持TreeSet元素按照自然顺序进行排序存储
双列集合(Map)
Map:
HashMap底层基于数组+链表,下标使用Hash,允许一个null作为key,存在线程安全问题ConcurrentHashMap线程安全的HashMap,JDK8之前,对数组进行了分段,锁住部分数据实现线程安全;JDK8之后,使用的是Node+链表/树结构,使用CAS+Synchronize保证线程安全TreeMap基于二叉树,会对元素进行排序HashTable线程安全的HashMap,所有操作方法加上了Synchronize同步非法,效率低
JDK内置集合
Collection接口
集合结构的父接口,Collection继承了Iterable迭代器接口,所有实现了Collection集合的实现类都可以使用迭代器进行遍历。

iterator 迭代器方法遍历:
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
forEach 方法遍历:
list.forEach(forEachList->{
System.out.println(forEachList);
});
List
list数据有序存放、可重复;
ArrayList、LinkedList
Vector: 是ArrayList线程安全版本,所有方法都是用synchronized修饰的。
ArrayList: 数组结构,是一个Object[]数组,线程不安全,可以用下标访问,访问快,由于ArrayList涉及到扩容(初始值为0,执行第一个add默认初始化10,之后扩容会按照1.5倍增长),如果ArrayList触发扩容,代价较高,如果从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
**LinkedList:**链表结构,线程不安全,适合数据的动态插入和删除,随机访问和遍历速度比较慢。
Vector、Collections.SynchronizedList、CopyOnWriteArrayList
Vector: 使用同步方法实现线程安全,SynchronizedList使用同步代码块实现线程安全。
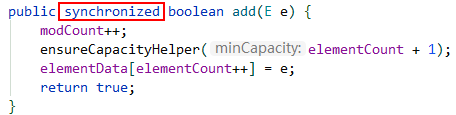
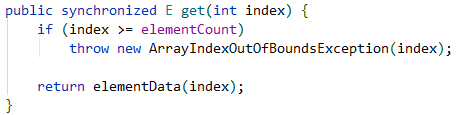
SynchronizedList: 是在方法块中第一行就使用同步锁了,所以两则的性能几乎一样,Collections.SynchronizedList专门用来将一个非线程安全的List转换成线程安全的List。


CopyOnWriteArrayList: java.util.concurrent.CopyOnWriteArrayList前两者使用Java内置锁Synchronized实现线程安全,CopyOnWriteArrayList使用了可重入锁ReentrantLock 实现线程安全的。

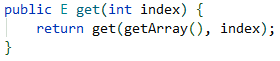
CopyOnWriteArrayList 原理解析
CopyOnWriteArrayList 其中所有可变操作(add、set等)都是通过生成底层数组的新副本来实现的。
CopyOnWriteArrayList只有写操作才会被加锁,并且在写的时候复制出一个新的容器Object[],将旧容器的元素复制到新容器,然后在新的容器Object[] newElements 里添加元素,添加完成之后,将原容器的引用指向新容器;这样做的好处是可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。
所以 CopyOnWrite 容器也是一种读写分离的思想,读和写是不同的容器。
源代码如下:
List<String> list = Arrays.asList("Tom", "James");
CopyOnWriteArrayList<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>(list);
// CopyOnWriteArrayList 写源码
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 复制出一个新容器,并扩容一个元素的空间
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 添加元素到新容器的末尾
newElements[len] = e;
// 将容器的引用指向新容器
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
Set
set中数据无序存放,不可重复;
HashSet、LinkedHashSet
HashSet: 内部使用的是HashMap,value是同一个值(new Object())。
LinkedHashSet: 继承HashSet,唯一的区别是内部使用的是LinkedHashMap。
HashSet其实就是一个简化版的HashMap,HashSet的值是HashMap的key,HashSet里面的HashMap所有的value都是同一个Object。
Collections.SynchronizedSet、CopyOnWriteArraySet区别
Collections.SynchronizedSet: 和 Collections.SynchronizedList 原理一样。
CopyOnWriteArraySet: 组合了CopyOnWriteArrayList,调用了CopyOnWriteArrayList中的方法进行线程安全的处理。
Map接口
key-value结构的父接口。

Map遍历:
Map<String,String> map = new HashMap<>();
for (Map.Entry<String, String> entry : map.entrySet()){
String key = entry.getKey();
String value = entry.getValue();
}
for (String key : map.keySet()){
String value = map.get(key);
}
for (String value : map.values()){
}
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, String> entry = iterator.next();
String key = entry.getKey();
String value = entry.getValue();
}
map.forEach((key, value)->{
});
map.entrySet().stream().forEach(entry->{
String key = entry.getKey();
String value = entry.getValue();
});
HashMap、LinkedHashMap、TreeMap
HashMap: 数组加链表结构存储元素,数组用来存储key-value构成的Map.Entry<K,V>对象,无容量限制;链表用来解决hash冲突的情况; 基于key的hash值查找Entry对象存放到数组的位置,所以不保证数据的有序性,对于hash冲突采用链表的方式去解决。(table数组存放元素,链表解决hash冲突问题),数组的初始容量为16,扩容因子为0.75。
在JDK1.8之后由原来单纯的的数组+链表,更改为链表长度为8时,开始由链表转换为红黑树。
LinkedHashMap: 可以保证数据的插入序和访问序,使用双向链表来实现的。
TreeMap: 存储的数据按照键值来升序排序,也可以指定比较器进行排序;使用二叉树数据结构实现的。
Hashtable、Collections.synchronizedMap、ConcurrentHashMap区别
Hashtable: 原理和 Vector 一样。
Collections.synchronizedMap: 和 Collections.SynchronizedList 原理一样。
ConcurrentHashMap: 在并发包中java.util.concurrent.ConcurrentHashMap,锁的粒度更细,使用了分段锁和ReentrantLock,所以性能好。
ConcurrentHashMap 线程安全解析
Java8 中 ConcurrentHashMap工作原理的要点分析
JDK1.7: ConcurrentHashMap 线程安全使用分段锁对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
JDK1.8: 取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构:数组+链表/红黑二叉树。在链表长度超过一定阈值(8)时,并且Map容量大于64时,将链表转换为红黑树。
如果没有hash冲突就尝试CAS方式插入。
如果存在hash冲突,就使用synchronized加锁来保证put操作的线程安全。
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
数组称之为表,将数组中每个链表或红黑树称之为桶,将数组中的每个节点称之为槽,也就是说槽存储了链表的头结点或者红黑树的根节点。源代码中用内部类Node表示链表中的每个节点。



HashMap为什么是线程不安全的
扩容引发的线程不安全。
HashMap的线程不安全体现在会造成死循环、数据丢失、数据覆盖这些问题。
其中死循环和数据丢失是在JDK1.7中出现的问题,在JDK1.8中已经得到解决,然而1.8中仍会有数据覆盖这样的问题。
Collections、Arrays工具类
Collections: 是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
Arrays: 数组操作工具类。
Collections常用方法:
sort排序:
List<String> list = Arrays.asList("Tom", "James");
Collections.sort(list, (x, y) -> {
return x.compareTo(y);
});
binarySearch查找元素:
List<String> list = Arrays.asList("Tom", "James");
int index = Collections.binarySearch(list, "Tom");
Guava扩展集合
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>
Guava提供了Lists、Sets、Maps集合工具类,封装了更多的对集合操作的功能。
List<String> list = Lists.newArrayList();
Set<String> set = Sets.newHashSet();
Map<String, String> map = Maps.newHashMap();
Multimap
扩展map接口,一个key可以映射到多个值。
当我们需要一个map中包含key为String类型,value为List类型的时候,以前我们是这样写的:
Map<String,List<String>> map = Maps.newHashMap();
List<String> list = Lists.newArrayList();
list.add("Hbase");
list.add("Hadoop");
map.put("bookNames", list);
System.out.println(map.get("bookNames")); // [Hbase, Hadoop]
而现在:
Multimap<String, String> multimap = ArrayListMultimap.create();
multimap.put("bookNames", "Hadoop");
multimap.put("bookNames", "Hbase");
System.out.println(multimap.get("bookNames")); // [Hbase, Hadoop]
Multimap的实现类有:ArrayListMultimap/HashMultimap/LinkedHashMultimap/TreeMultimap/ImmutableMultimap/......
get()/keys()/keySet()/values()/entries()/asMap()都是非常有用的返回view collection的方法。
Multiset
JDK的集合,提供了有序且可以重复的List,无序且不可以重复的Set。那么需要一个无序且可以重复的集合该怎么办呢?
Guava新增了一个集合Multiset。
Multiset就是无序的,但是可以重复的集合,它就是游离在List/Set之间的“灰色地带”!
示例:
Multiset<String> multiset = HashMultiset.create();
multiset.add("a");
multiset.add("b");
multiset.add("a");
multiset.add("d");
multiset.add("c");
System.out.println(multiset.size());
System.out.println(multiset.count("a"));
Multiset自带一个有用的功能,就是可以跟踪每个对象的数量。
Immutable
ImmutableList<String> iList = ImmutableList.of("a", "b", "c");
ImmutableSet<String> iSet = ImmutableSet.of("e1", "e2");
ImmutableMap<String, String> iMap = ImmutableMap.of("k1", "v1", "k2", "v2");
Immutable是不可变的意思。
guava提供了很多Immutable集合,比如ImmutableList/ImmutableSet/ImmutableSortedSet/ImmutableMap/…
什么是Immutable(不可变)对象?
- 在多线程操作下,是线程安全的。
- 所有不可变集合会比可变集合更有效的利用资源。
- 中途不可改变。
ImmutableList<String> immutableList = ImmutableList.of("1","2","3","4");
上面声明了一个不可变的List集合,List中有数据1,2,3,4。类中的操作集合的方法(譬如add, set, sort, replace等)都被声明过期,并且抛出异常。
// add 方法
@Deprecated @Override
public final void add(int index, E element) {
throw new UnsupportedOperationException();
}
ImmutableMap
BiMap
双向Map(Bidirectional Map) 键与值都不能重复。
创建方式: BiMap<String, String> biMap = HashBiMap.create();
Google的Guava提供了BiMap这样一个双向Map,调用inverse()方法会返回一个反向的关联的BiMap,然后便可以通过get()方法获取key值了。
BiMap<String, Integer> biMap = HashBiMap.create();
biMap.put("A", 1);
biMap.put("B", 2);
biMap.put("C", null);
biMap.put("D", 4);
assertEquals("D", biMap.inverse().get(4));
需要注意的是,BiMap作为一个双向的Map,它不能存储多对一的关系;而HashMap是可以的。其实很好理解,因为是双向的,所以即要满足Key值的唯一性,也要满足Value值的唯一性。如果往里存放同样的Value,会抛异常: java.lang.IllegalArgumentException: value already present。
Table
双键的Map Map–> Table–>rowKey+columnKey+value //和sql中的联合主键有点像
创建方式: Table<String, String, Integer> tables = HashBasedTable.create();
Apache扩展集合
BidiMap
类似地,Apache Commons Collections也提供了双向Map的类BidiMap,它也是维持一对一的关系,不能多对一。它提供了getKey(value)方法返回Key值。代码如下:
BidiMap bidiMap = new DualHashBidiMap(new HashMap<>());
bidiMap.put("A", 1);
bidiMap.put("B", 2);
bidiMap.put("C", null);
bidiMap.put("D", 4);
assertEquals("D", bidiMap.getKey(4));
与Guava的BiMap不同的是,当存放同样的Value时,它不会抛异常,而是覆盖原有的数据















 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









