








1、行转列
例题数据如下:
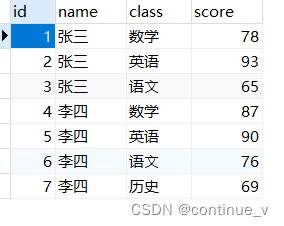
解题核心思路:将一维数据转化为二位数据,根据姓名分组;提供四种解法
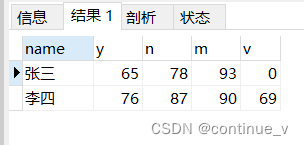
方法一:case when ……then ……end
# 方法一:case when
select `name`,
max(case when class='语文' then score else 0 end) as y,
max(case when class='数学' then score else 0 end) as n,
max(case when class='英语' then score else 0 end) as m,
max(case when class='历史' then score else 0 end) as v
from student_x
group by `name`;
输出结果:
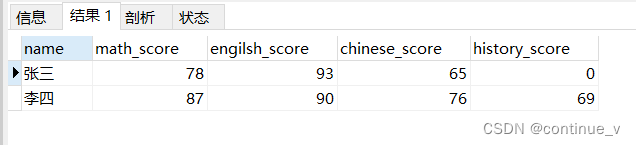
方法二:if 函数,结果和方法一致
# 方法二:if函数
select name,
max(if(class = '数学', score, 0)) as math_score,
max(if(class = '英语', score, 0)) as engilsh_score,
max(if(class = '语文', score, 0)) as chinese_score,
max(if(class = '历史', score, 0)) as history_score
from student_x
group by name;输出结果:
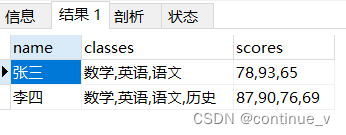
方法三:group_concat( sparator ) 拼接函数
-- 方法三:group_concat函数
select name,
group_concat(class separator ',') as classes,
group_concat(score separator ',') as scores
from student_x
group by name;输出结果:
方法四:对方法三的优化
-- 方法四:
select name,
group_concat(class,':',score separator ',') as 'class:score'
from student_x
group by name;输出结果:
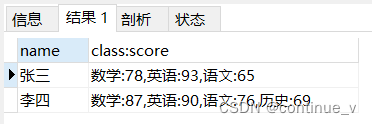
注意:以上四种方法中前两种会对没有成绩的科目自动补0,后两种方法不会补0。
2、列转行
核心思想:每一个字段单独查询作为一个临时表,然后将各个子表联合拼接起来。
例题:
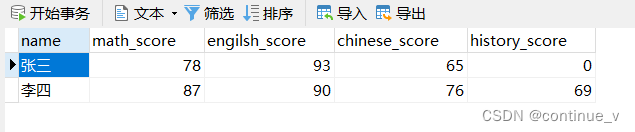
题解:
select * from (
select name, '数学' as class, math_score as score from student_y
union all
select name, '英语' as class, engilsh_score as score from student_y
union all
select name, '语文' as class, chinese_score as score from student_y
union all
select name, '历史' as class, history_score as score from student_y
) as x order by name,class;输出结果:
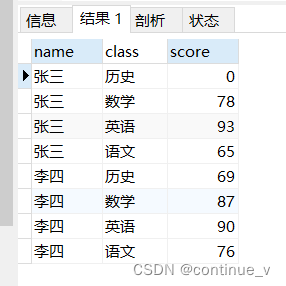
3、字符拼接函数的使用
例题:将表中的id和chang 字段用“—”连接,例如:1-1001-1002,只拼接前两个
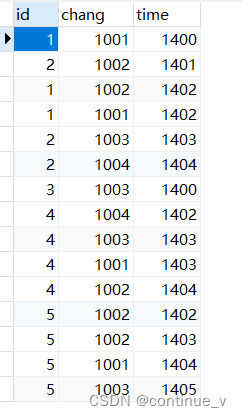
解题思路:根据id和chang字段分组,使用窗口函数添加一个辅助列;使用group_concat()函数将chang字段1001和1002拼接,最后使用concat()函数将id 和chang 字段拼接
步骤一:
# 窗口函数添加辅助列
select *,row_number() over(partition by id order by chang) as n from cj group by id,chang;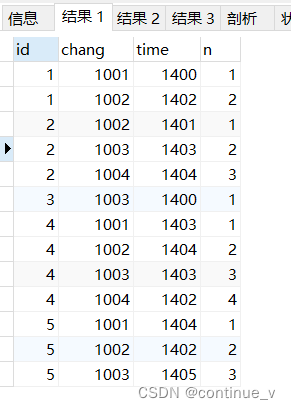
步骤二:
# 将上面的查询作为子表,使用group_concat()拼接chang 字段
select group_concat(distinct b.chang order by b.time separator '-' ) 结果1
from (select *,row_number() over(partition by id order by time) n from cj group by id,chang)b
where b.n<3 group by id;输出结果:
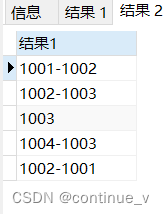
步骤三:
# 通过group_concat()函数和concat()函数实现字段拼接
select concat(b.id,'-',group_concat(distinct b.chang order by b.time separator '-' )) 结果
from (select *,row_number() over(partition by id order by time) n from cj group by id,chang)b
where b.n<3 group by id;
输出结果:
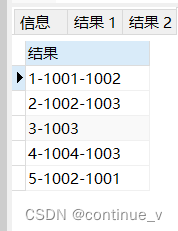















 5539
5539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









