






KMP算法
一. 介绍
KMP算法是一种高效的字符串匹配算法,其时间复杂度为O(n+m),其主要原因是目标串指针不回溯。
1.1 为什么目标串指针不用回溯?
1.1.1 什么是前后缀?
前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
1.1.2 理由 :
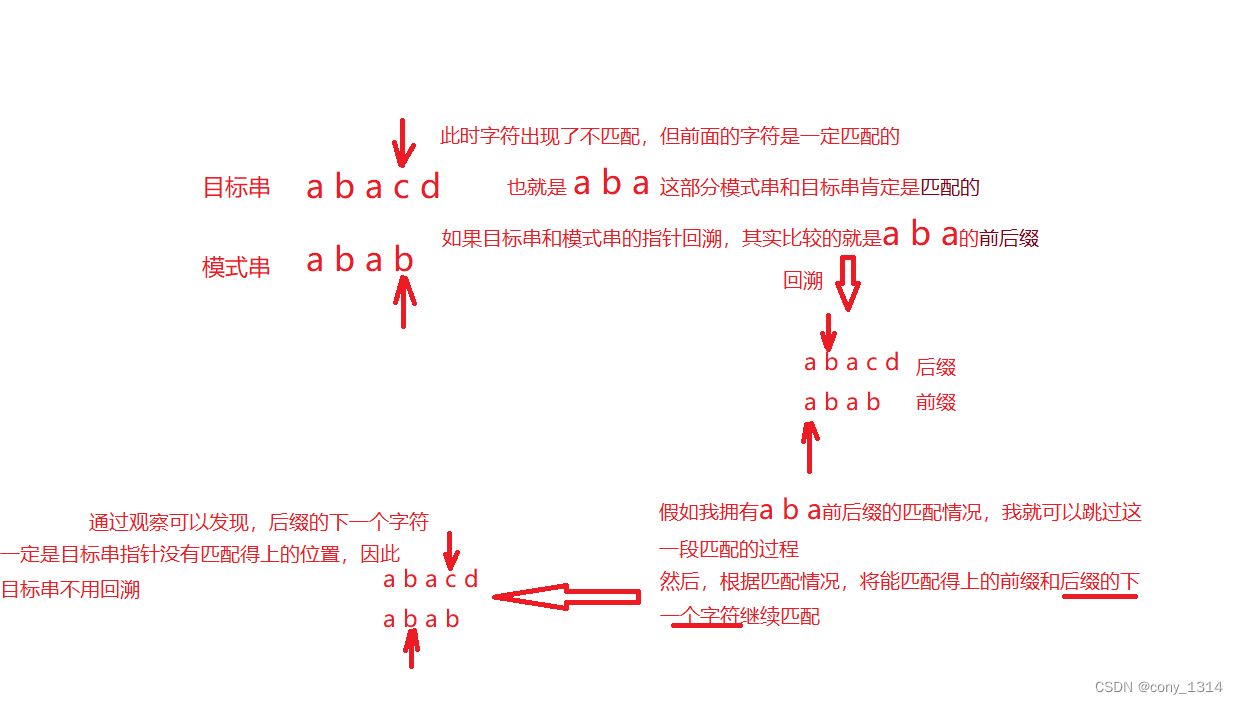
在回溯的过程中,也将 **已经匹配好的字符串** 前后缀,进行了匹配比较。
如果我拥有这个字符串前后缀匹配情况,我就可以跳过这段比较过程,直接将前后缀的下一个字符继续进行比较。
然而,
**目标串指针回溯** 时记录的就是,这个字符串的 **后缀**。
**模式串指针回溯** 时记录的就是,这个字符的 **前缀** 。
**因此这个字符串后缀的下一个字符,就是当前目标串指针的位置,所以不用回溯**。
所以只用根据这个字符串前后缀匹配情况,去计算匹配好后,**前缀的下一个位置** 就行了。
也就是 **模式串需要回溯的位置**。
1.2 那么模式串到底需要回溯到哪呢?
===>>> 这就涉及到了next数组
1.2.1 什么是next数组?
用于记录模式串在当前位置不匹配的时候,需要回溯到的位置。
1.2.2 如何求next数组
===>>> 代码 :
int *getNext(char *ch) {
int length = strlen(ch);
int *next = (int *) malloc(sizeof(char) * (length + 1));
int i = 0, j = -1;
next[0] = -1;
while (i < length) {
if (j == -1 || ch[i] == ch[j]) {
next[++i] = ++j;
// if (ch[i] == ch[next[i]])
// next[i] = next[next[i]];
} else j = next[j];
}
return next;
}
===>>> 分析 :
手算 :
next数组是指导模式串指针如何回溯的工具。
系统默认字符串是从0的位置开始,一般规定next[0]=-1。
但大部分教材的字符串是从位置1开始,也就是第二个位置,所以next数组从1开始,规定next[1]=0。
我使用的是系统默认字符串,第一个位置从0开始。
为什么要事先规定好next数组的第一个位置的值呢?
因为第一个位置是一个特殊情况。之后的位置的值就跟前后缀相关了。
当模式串不存在前后缀/前后缀没有匹配项,说明目标串指针之前的位置不存在匹配的情况。此时,模式串需要重新与目标串开始匹配,也就是回溯到第一个位置。
当模式串前后缀存在n个匹配项,说明目标串指针之前的位置存在n个字符匹配的情况。此时,模式串可以回溯到第n+1的位置上。

代码思想 :
第一个位置人为规定为-1。
第二个位置的情况是不存在前后缀,也就是值肯定为0,这个情况可以和else j指针回溯并用一个条件(j==-1)。
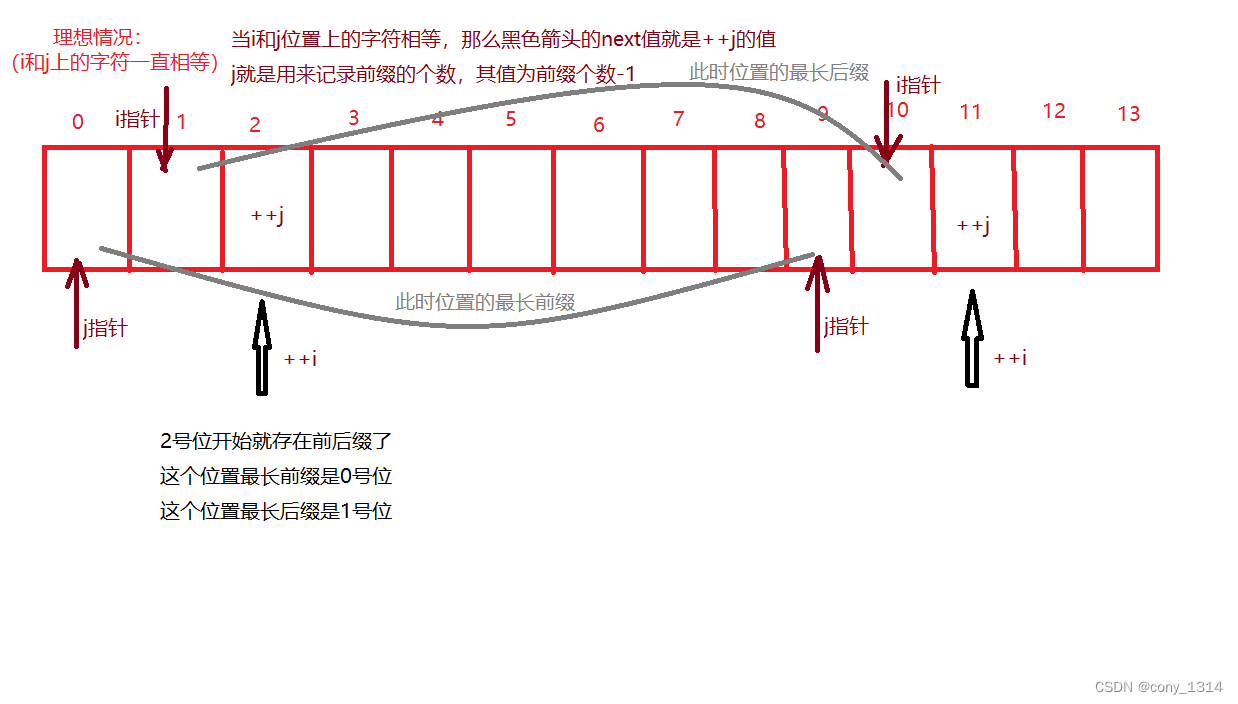
从第三个位置开始,就存在前后缀了。
理想情况下(i和j位置上的字符一直相等),i和j相差一个位置。
i为已经匹配的字符的倒数第二个位置,j为已经匹配的字符的倒数第一个位置,此时是最长的前后缀。
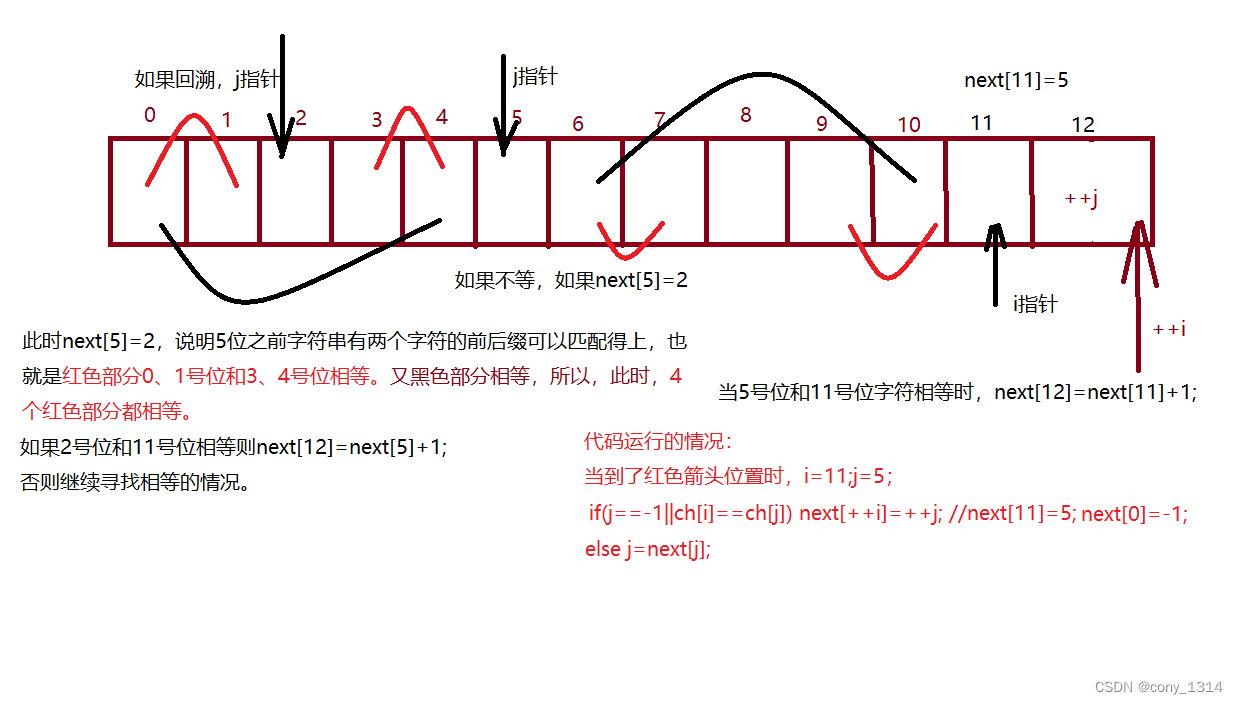
一旦i和j上的字符不满足条件,j就要回溯,那么j为什么要回溯且回溯到next[j]呢?
回溯到next[j]的原因 :
由于next[j]是记录了当前位置之前的前后缀相等情况,所以可以借用已经拥有的next值去定位到前缀的下一位。
即j=next[j],而i指针就是后缀的下一位。
如果前缀的下一位字符等于后缀的下一位字符,即ch[i]==ch[j],则next[++i]=++j即可。
否则继续回溯,即j=next[j]。
二. 根据next数组进行字符串匹配
2.1 代码 :
int index_KMP(char ch1[], char ch2[], int pos) {//pos是值从哪里开始匹配,从数字1开始
int length1 = strlen(ch1);
int length2 = strlen(ch2);
if (length1 < length2) {
printf("NOT FOUND!\n");
return -1;
}
int *next = getNext(ch2);
int i = pos - 1, j = 0;
while (i < length1 && j < length2) {
if (j == -1 || ch1[i] == ch2[j]) {
i++;
j++;
} else j = next[j];
}
if (j >= length2) {
printf("index = %d\n", i - j + 1);
return i - j + 1;
}
printf("NOT FOUND!\n");
return -1;
}
既然理解了next数组的作用,也就是指导模式串指针如何回溯。
代码就是开头所讲的实现,即目标指针不回溯,模式串指针回溯。
当j==-1时,也就是特殊情况,模式串指针不移动,目标指针向后移动一位。
这就解释了为什么要将next[0]设置为-1(可以理解为将模式串指针向前移动一位),
接着再将模式串指针和目标指针同时向后移动一位,即模式串指针不移动,目标指针向后移动一位。
三. nextval数组优化KMP算法
/*例如:aaaab
next数组的值分别为:
-1 0 1 2 3
如果模式串指针在4号位不匹配,则将回溯到3号位置,而3号位和4号位上的字符是相等的,且都为a,那么即使回溯到3号位也一定匹配不了,然后3号位会回溯到2号位,然而2号和3号位是同样的情况,那么2号位会回溯到1号位。这个过程本质上就是BF算法的过程。
那么如何优化呢?
既然,当前不匹配的位置和回溯的位置上的字符相等,且一定会继续回溯,那么我直接将回溯位置更新至最后一次回溯位置即可。
在代码中加上下面这一句代码即可*/
if(ch[i]==ch[next[i]])
next[i]=next[next[i]];
3.1 完整代码
#include<stdio.h>
#include<string.h>
#include<malloc.h>
int *getNext(char *ch) {
int length = strlen(ch);
int *next = (int *) malloc(sizeof(char) * (length + 1));
int i = 0, j = -1;
next[0] = -1;
while (i < length) {
if (j == -1 || ch[i] == ch[j]) {
next[++i] = ++j;
if (ch[i] == ch[next[i]])
next[i] = next[next[i]];
} else j = next[j];
}
return next;
}
int index_KMP(char ch1[], char ch2[], int pos) {//pos是值从哪里开始匹配,从数字1开始
int length1 = strlen(ch1);
int length2 = strlen(ch2);
if (length1 < length2) {
printf("NOT FOUND!\n");
return -1;
}
int *next = getNext(ch2);
int i = pos - 1, j = 0;
while (i < length1 && j < length2) {
if (j == -1 || ch1[i] == ch2[j]) {
i++;
j++;
} else j = next[j];
}
if (j >= length2) {
printf("index = %d\n", i - j + 1);
return i - j + 1;
}
printf("NOT FOUND!\n");
return -1;
}
int main() {
int *next = getNext("aaab");
for (int i = 0; i < strlen("aaab"); i++)
printf("%d ", next[i]);
printf("\n");
index_KMP("aaaabca", "aaab", 1);
return 0;
}
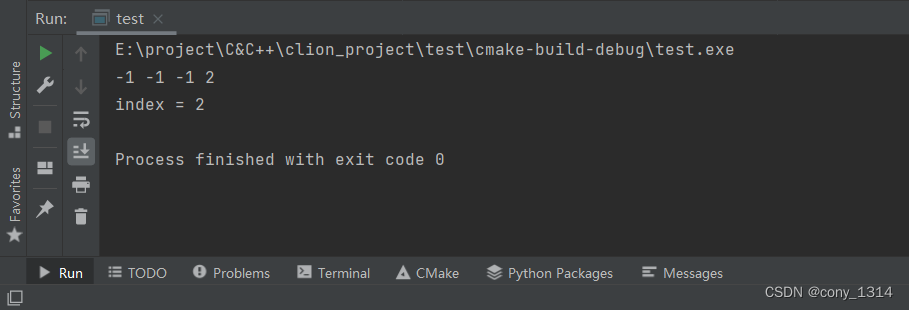
3.2 结果演示
四. 总结
KMP算法是利用已经匹配好的字符串的信息,去指导下一次匹配,从而达到高效结果的算法。
next数组存在不完全回溯的问题,因为不能保证当前不匹配位和回溯位上的字符不相等。
所以只需在赋值完next数组之后,判断回溯位和当前不匹配位是否相等,如果不相等则将回溯位更新至回溯位回溯的位置。















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









