







目录
前言
在现代互联网架构中,缓存已成为高并发、高可用系统不可或缺的一部分。它通过将热点数据存储于内存中,显著提升了系统的响应速度并减轻了后端数据库的压力。然而,在某些极端情况下,缓存可能会成为系统的不稳定因素。缓存雪崩正是其中一种极具破坏力的现象。
所谓“缓存雪崩”,并不是一种突发的程序错误,而是一种由于缓存机制设计不当所引发的系统性性能灾难。其破坏性类似雪山上的雪崩:原本静态的冰雪,在特定条件下突然崩塌,席卷一切。本文将全面剖析缓存雪崩的成因、影响及其应对策略,帮助开发者更好地构建稳定可靠的分布式系统。
1. 什么是缓存雪崩
缓存雪崩是指在某一时间段,大量缓存数据集中失效,导致请求无法命中缓存,大量并发请求直接打到数据库或后端服务,瞬间造成数据库压力飙升,系统性能下降,甚至可能导致整个系统崩溃。
缓存雪崩的根源并非某一条缓存数据失效,而在于**“集中”失效**。如果系统中存在成百上千条关键业务的缓存数据,它们的过期时间设置得非常一致,例如统一设置为1小时。当这1小时到达后,所有缓存同时过期,便会形成一次“缓存雪崩”事件。
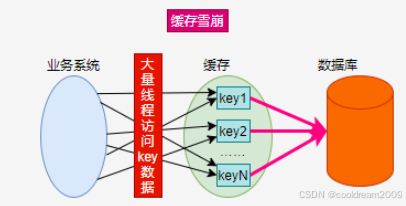
1.1 缓存雪崩与缓存击穿、缓存穿透的区别
在进一步展开之前,我们有必要简要区分缓存雪崩与另外两种常见的缓存问题:
- 缓存击穿:指某个热点数据突然失效,大量请求集中访问数据库,导致数据库短时间内过载。
- 缓存穿透:指客户端请求的数据根本不存在于缓存和数据库中,例如请求的是非法参数,攻击者可利用这一漏洞反复发起请求,绕过缓存层直接打数据库。
- 缓存雪崩:则是多个缓存集中同时失效,造成大面积缓存失效和系统访问压力骤增。
虽然三者概念不同,但缓存雪崩往往是最严重、波及范围最广的问题。

2. 缓存雪崩产生的根本原因
缓存雪崩的发生往往与缓存系统的设计策略不当密切相关,下面从多个角度解析其常见诱因。
2.1 缓存集中过期时间设置不合理
这是导致缓存雪崩最典型的原因之一。很多系统为了简化实现,统一设置缓存的过期时间,比如将所有缓存统一设置为3600秒。这样的设计虽然方便维护,但却极易导致缓存同时失效,从而引发雪崩。
2.2 缓存服务宕机或大面积失效
如果缓存中间件(如Redis或Memcached)服务宕机、网络出现故障,或集群节点同时崩溃,所有缓存将瞬间失效。这类“不可预知”的系统性故障,也会导致雪崩效应。
2.3 高并发访问下缓存未能及时恢复
在缓存过期后,系统需要重新从数据库加载数据并写入缓存。如果系统并没有对更新缓存进行并发控制,例如加锁或去重机制,可能造成大量请求同时访问数据库,进而拖垮数据库,导致缓存无法及时恢复,形成恶性循环。
3. 缓存雪崩的影响
缓存雪崩对系统的影响远超一般的性能问题。在高并发场景下,缓存雪崩可能会引发以下连锁反应:
- 数据库连接数耗尽,造成请求阻塞甚至崩溃;
- 上游应用等待数据库响应时间过长,线程池耗尽,最终服务不可用;
- 用户体验极差,响应延迟,业务中断;
- 在分布式系统中,一台服务崩溃可能会引发其他节点连锁宕机。
因此,缓存雪崩不仅是一个技术问题,更是系统稳定性与可靠性的重大威胁。
4. 应对缓存雪崩的策略
面对缓存雪崩,我们并非无计可施。通过合理的系统设计和多层防护机制,可以有效规避这一风险。
4.1 为缓存设置随机化过期时间
最直接的防御手段是避免缓存同时过期。在设置缓存时,可通过在原有过期时间基础上添加一个随机范围,比如:
expire_time = 3600 + random.randint(0, 300) 1小时 ±5分钟
这种策略能够显著降低缓存集中失效的风险,从而减少对后端系统的冲击。
4.2 提前刷新即将过期的缓存(预热机制)
引入“主动刷新”机制,在缓存即将过期前的一个合理窗口内(比如提前5分钟),系统可以通过异步任务或后台定时器提前加载新数据并更新缓存。这种方式能够让缓存始终处于“有效”状态,避免瞬间的空档期。
例如,可结合消息队列或定时任务框架(如Quartz、ScheduledExecutor)实现批量刷新策略。
4.3 利用分布式锁控制并发回源
为防止大量请求在缓存失效时同时访问数据库,可引入分布式锁机制。在发现缓存失效后,仅允许一个线程访问数据库并更新缓存,其他线程等待或返回默认值,避免数据库被压垮。
可以使用Redis的SETNX命令配合过期时间实现轻量级分布式锁。
4.4 设置热点数据永不过期,依赖主动更新
对于访问量极高的热点数据,例如首页推荐、商品详情,可以考虑不设置过期时间,而是依赖后台业务逻辑主动更新缓存。这样可从根源上避免过期引发的高并发数据库访问。
当然,此策略需结合业务特性谨慎使用,避免缓存长期不更新导致数据陈旧。
4.5 限流与降级机制
当系统面临缓存雪崩引发的高并发访问压力时,可通过限流器(如令牌桶、漏桶算法)进行流量控制,确保数据库不会超载。同时,可以设置服务降级策略,在缓存和数据库都不可用时,返回静态数据、默认值或友好提示,保证服务不中断。
如使用Hystrix、Sentinel等熔断降级组件,可以自动识别异常并进行快速故障处理。
5. 综合实战:构建抗雪崩的缓存体系
一个稳定的缓存体系应具备以下几个特征:
- 缓存设置合理,过期时间具备随机性;
- 数据访问具有一定的预取和预热能力;
- 缓存更新具备并发控制能力,防止击穿;
- 核心路径具备降级兜底能力,避免系统雪崩;
- 缓存服务本身具备容灾备份能力,如使用Redis Sentinel或Cluster架构。
通过引入缓存中间层(如本地缓存+分布式缓存)、读写分离、异步处理等技术手段,也可以进一步增强系统在雪崩情形下的韧性。
结语
缓存雪崩并不是一种容易被察觉的问题,往往在系统上线初期运行良好,却在某一特定时间点突然爆发,造成灾难性后果。它的发生,往往是架构设计者对缓存机制理解不足、对系统高并发行为预判不准确所致。构建高可用、高并发系统是一项系统性工程。防止缓存雪崩,不能依赖某一个“补丁”,而需要从缓存策略、业务逻辑、并发控制到异常处理等多个维度着手。希望通过本文的分析与实践策略,能够为开发者在实际项目中提供有益的参考,助力打造一个稳定、可靠的系统架构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











