







 本文介绍了一种创新的文本匹配方法,灵感来源于图像识别中的卷积神经网络(CNN)。该方法通过构建文本相似度矩阵并应用卷积操作来提取特征,能够有效捕捉n-gram和n-term特征,并在MSRP数据集及自收集的论文引用匹配数据上进行了验证。
本文介绍了一种创新的文本匹配方法,灵感来源于图像识别中的卷积神经网络(CNN)。该方法通过构建文本相似度矩阵并应用卷积操作来提取特征,能够有效捕捉n-gram和n-term特征,并在MSRP数据集及自收集的论文引用匹配数据上进行了验证。
版权声明:本文为博主原创文章,未经博主允许不得转载。禁止抄袭。
由于作者资历尚浅,有理解错误的地方欢迎大家指正和交流。
论文简介
论文题目: Text Matching as Image Recognition
论文地址:http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/11895/12024
作者:Liang Pang, Shengxian Wan, Xueqi Cheng等
作者单位:中科院计算所(网络数据科学与技术重点实验室)
出版单位:the Association for the Advance of Artificial Intelligence(AAAI)
发表时间:2016.2
模型图
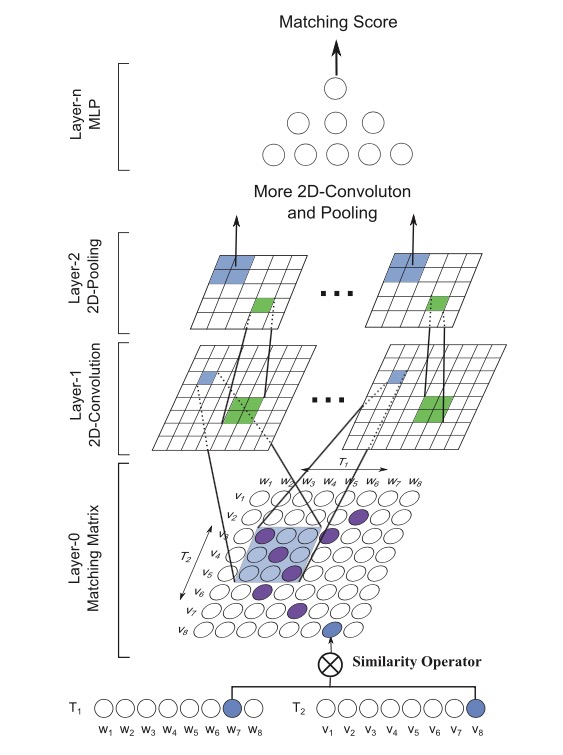
贡献点:
1.受CNN在图像识别中的启发(可以提取到边、角等特征),作者提出先将文本使用相似度计算构造相似度矩阵,然后卷积来提取特征。把文本匹配处理成图像识别。【想法很特别】
2.根据结果显示,在文本方面使用作者提出的方法可以提取n-gram、n-term特征。作者给了一个匹配的例子:
T1 : Down the ages noodles and dumplings were famous Chinese food.
T2 : Down the ages dumplings and noodles were popular in China.
PS:Down the ages是历代以来的意思。
模型可以学习到Down the ages(n-gram特征),noodles and dumplings与dumplings and noodles(打乱顺序的n-term特征)、were famous Chinese food和were popular in China(相似语义的n-term特征)。
作者基于此模型,在2017.3-2017.6 Kaggle的Quora Question Pairs 比赛上,取得了全球第四的好成绩。(YesOfCourse 团队)【效果很不错】
实验数据:
1.MSRP数据(判断两个短语是否有相同含义,4k训练,1.7k测试)
2.论文引用匹配(Paper Citation Matching)数据,约84w数据(28w正例,56w负例)。作者自己搜集,没有公开?
细节:
1.Ai和Bj距离度量方式:完全一样 (Indicator),余弦相似度 (Cosine),点乘 (Dot Product)。
2.卷积,RELU激活,动态pooling(pooling size等于内容大小除以kernel大小)。
3.卷积核第一层分别算,第二层求和算。可以见下图3*3的kernel分别算,2*4*4求和算。
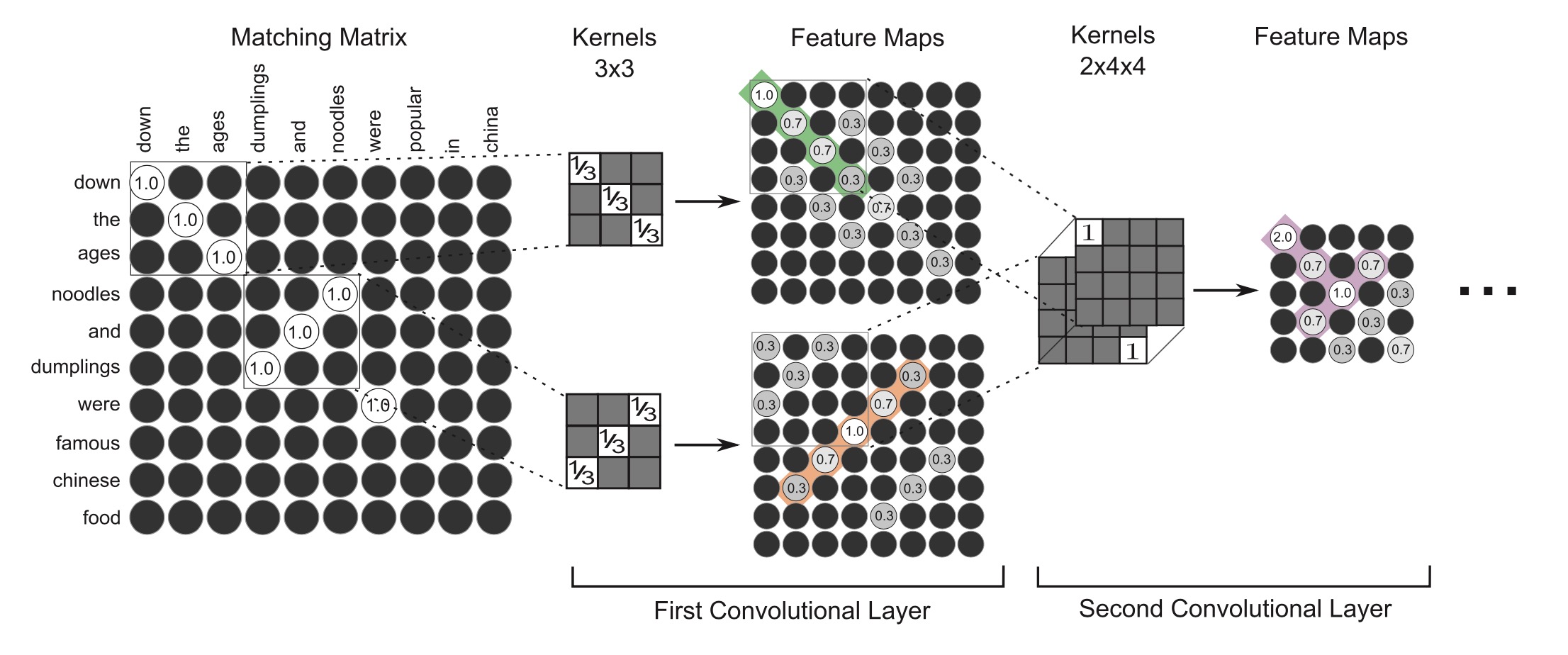
4.MLP拟合相似度,两层,使用sigmoid激活,最后使用softmax,交叉熵损失函数。
5. Embedding长度较小的比较没用,用DOT比COS好。
不足:
1.MSRP上效果不如uRAE。(怎样把外部数据加入)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









