







JVM能够跨计算机体系结构来执行Java字节码,主要是由于JVM屏蔽了与各个计算机平台相关的软件或者硬件之间的差异,使得
与平台相关的耦合统一由JVM提供者来实现。本章将主要介绍JVM的总体设计的体系结构,接着介绍JVM的执行引擎是如何工作
的,最后介绍执行引擎如何模拟执行JVM指令。
JVM体系结构
前面的章节在分析了 class文件的结构后,又接着分析了 class是如何被加载到JVM中的,下面看看JVM的体系结构是如何设计的,这里只能从宏观角度做分析,让大家了解一下最基本的JVM结构和工作模式。
何谓 JVM
JVM的全称是Java Virtual Machine (Java虚拟机),它通过模拟一个计算机来达到一计算机所具有的计算功能。我们先来看看一个真
实的计算机如何才能具备计算的功能。
〇以计算为中心来看计算机的体系结构可以分为如下几个部分。〇指令集,这个计算机所能识别的机器语言的命令集合。〇计算单元,即能够识别并且控制指令执行的功能模块。〇 寻址方式,地址的位数、最小地址和最大地址范围,以及地址的运行规则。〇 寄存器定义,包括操作数寄存器、变址寄存器、控制寄存器等的定义、数量和使 用方式。〇存储单元,能够存储操作数和保存操作结构的单元,如内核级缓存、内存和磁盘等。
在上面这几个部分中与我们所说的代码执行最密切的还是指令集部分,下面详细说明一下在计算机中指令集是如何定义的。
什么是指令集?有何作用?所谓指令集就是在CPU中用来计算和控制计算机系统的一套指令的集合,每一种新型的CPU在设计时都规定了一系列与其他硬件电路相配合的指令系统。而指令集的先进与否也关系到CPU的性能发挥,它是体现CPU性能的一个重要标志。
在当前计算机中有哪些指令集?从主流的体系结构上分为精简指令集(Reduced Istruction Set Computing,RISC)和复杂指令集(Complex Instruction Set Computing, CISC)。当前我们普遍使用的桌面操作系统中基本上使用的都是CISC,如x86架构的CPU都使用复杂指令集。除了这两种指令集之外Intel和AMD公司还在它们的基础上开发出了很多扩展指令集,如MMX(MultiMediaeXtension,多媒体扩展指令)使得在处理多媒体数据时性能更强,还有AMD公司为提高3D处理性能开发的3DNow!指令集等。
指令集与汇编语言有什么关系?指令集是可以直接被机器识别的机器码,也就是它必须以二进制格式存在于计算机中。而汇编语言是能够被人识别的指令,汇编语言在顺序和逻辑上是与机器指令一一对应的。换句话说,汇编语言是为了让人能够更容易地记住机器指令而使用的助记符。每一条汇编指令都可以直接翻译成一个机器指令,如MOV AX,1234H这条汇编语言对应的机器指令码为B83412。当然也不是所有的汇编语言都有对应的机器指令,如nop指令。
指令集与CPU架构有何联系?如Intel与AMD的CPU的指令集是否兼容?也就是CPU的架构是否会影响指令集?答案都是肯定的。学过汇编语言的人都知道在汇编语言中 都是对寄存器和段的直接操作的命令,这些寄存器和段等芯片都是架构的一部分,所以不 同的芯片架构设计一定会对应到不同的机器指令集合。但是现在不同的芯片厂商往往都会 采用兼容的方式来兼容其他不同架构的指令集。如AMD会兼容32位Intel的x86系统架 构的CPU,而当AMD开发出了支持64位指令的X86-64架构时,Intel又迫于压力不得不 兼容这种架构而起了另外一个名字EM64T。这种压力来自什么地方?当然是垄断了操作 系统的微软,由于现在操作系统是管理计算机的真正入口,几乎所有的程序都要通过操作 系统来调用,所以如果操作系统不支持某种芯片的指令集,用户的程序是不可能执行的。 这种情况也存在于我们国家自己设计的龙芯CPU,龙芯CPU不得不使用基于MIPS架构 的指令集(是RISC指令集),因为目前有直接支持MIPS架构的操作系统(Linux操作系 统,目前Windows不支持)。如果没有操作系统和应用软件,再好的CPU也没有使用价值 当然在一些很少用到的大型机方面不存在这个问题。
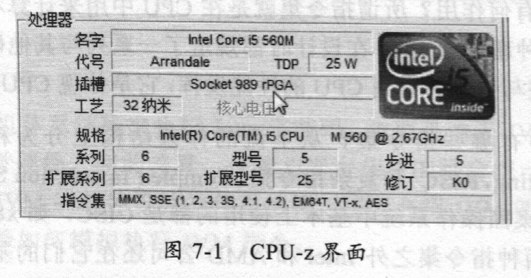
那么我们如何使得不同的CPU架构来支持不同的指令集呢?在Windows下可以通:二CPU-z软件来查看这个CPU都支持哪些指令集,如图7-1所示。
回到JVM的主题中来,JVM和实体机到底有何不同呢?大体有如下几点。
最下面一行就是这个CPU支持的指令集,可以看出该CPU支持6种指令集。
回到JVM的主题中来,JVM和实体机到底有何不同呢?大体有如下几点。
〇一个抽象规范,这个规范就约束了 JVM到底是什么,它有哪些组成部分,这些抽象的规范都在 The Java Virtiual Machine Specification 中详细描述了。
〇—个具体的实现,所谓具体的实现就是不同的厂商按照这个抽象的规范用软件或者软件和硬件结合的方式在相同或者不同的平台上的具体的实现。
〇一个运行中的实例,当用其运行一个Java程序时,它就是一个运行中的实例,每个运行中的Java程序都是一个JVM实例。
JVM和实体机一样也必须有一套合适的指令集,这个指令集能够被JVM解析执行。
这个指令集我们称为JVM字节码指令集,符合class文件规范的字节码都可以被JVM执行。
JVM体系结构详解
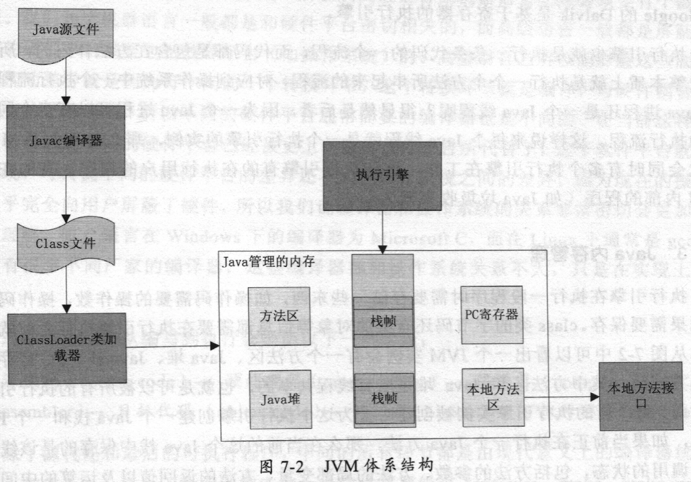
下面我们再看看除了指令集之外,JVM还需要哪些组成部分。如图7-2所示,JVM的结构基本上由4部分组成。
◎类加载器,在JVM启动时或者在类运行时将需要的class加载到JVM中。◎执行引擎,执行引擎的任务是负责执行class文件中包含的字节码指令,相当于 实际机器上的CPU。◎内存区,将内存划分成若干个区以模拟实际机器上的存储、记录和调度功能模块, 如实际机器上的各种功能的寄存器或者PC指针的记录器等。◎本地方法调用,调用C或C++实现的本地方法的代码返回结果。
1.类加载器
在深入分析ClassLoader时我们详细分析了 ClassLoader的工作机制,这里需要说明的是,每个被JVM装载的类型都有一个对应的java.lang.Class类的实例来表示该类型,该实例可以唯一表示被JVM装载的class类,要求这个实例和其他类的实例一样都存放在Java的堆中。
2.执行引擎
执行引擎是JVM的核心部分,执行引擎的作用就是解析JVM字节码指令,得到执行结果。在《Java虚拟机规范》中详细地定义了执行引擎遇到每条字节码指令时应该处理什么,并且应该得到什么结果。但是并没有规定执行引擎应该如何或采取什么方式处理而得到这个结果。因为执行引擎具体采取什么方式由JVM的实现厂家自己去实现,是直接解释执行还是采用JIT技术转成本地代码去执行,还是采用寄存器这个芯片模式去执行都可以。所以执行引擎的具体实现有很大的发挥空间,如SUN的hotspot是基于栈的执行引擎.
而Google的Dalvik是基于寄存器的执行引擎。
执行引擎也就是执行一条条代码的一个流程,而代码都是包含在方法体内的,所以执行引擎本质上就是执行一个个方法所串起来的流程,对应到操作系统中一个执行流程是一个Java进程还是一个Java线程呢?很显然是后者,因为一个Java进程可以有多个同时执
行的执行流程。这样说来每个Java线程就是一个执行引擎的实例,那么在一个JVM实例中就会同时有多个执行引擎在工作,这些执行引擎有的在执行用户的程序,有的在执行JVM内部的程序(如Java垃圾收集器)。
行的执行流程。这样说来每个Java线程就是一个执行引擎的实例,那么在一个JVM实例中就会同时有多个执行引擎在工作,这些执行引擎有的在执行用户的程序,有的在执行JVM内部的程序(如Java垃圾收集器)。
3 Java内存管理
例如引擎在执行一段程序时需要存储一些东西,如操作码需要的操作数,操作码的执行结果需要保存。class类的字节码还有类的对象等信息都需要在执行引擎之前就准备好。从图7-2中可以看出一个JVM实例会有一个方法区,Java堆,Java栈,PC寄存器和本地方法区。其中方法区和Java堆是所有线程共享的,也就是可以被所有的执行引擎实例访问。每个新的执行引擎实例被创建时会为这个执行引擎创建一个Java栈和一个PC寄存器,如果当前正在执行一个Java方法,那么在当前的这个Java栈中保存的是该线程中方法调用的状态,包括方法的参数,方法的局部变量,方法的返回值以及运算的中间结果等。而PC寄存器会指向即将执行的下一条指令。
如果是本地方法调用,则存储在本地方法调用栈中或者特定实现中的某个内存区域中。
通常一个程序从编写到执行会经历以下一些阶段:
除了源代码和最后的可执行程序,中间的所有环节都是由现代意义上的编译器统一完成的,如在Linux平台下我们通常安装一个软件需要经过configure、make、make install、make clean这4个步骤来完成。configure为这个程序在当前的操作系统环境下选择合适的
编译器来编译这个程序代码,也就是为这个程序代码选择合适的编译器和一些环境参数:make自然就是对程序代码进行编译操作了,它会将源码编译成可执行的目标文件。make install将已经编译好的可执行文件安装到操作系统指定或者默认的安装目录下。最后的
make clean用于删除编译时临时产生的目录或文件。
值得注意的是,我们通常所说的编译器都是将某种高级语言直接编译成可执行的目标机器语言(实际上在某种操作系统中是需要动态链接的目标二进制文件:在Windows下是dynamic link library, DLL;在 Linux 下是 Shared Library, SO 库)。但是实际上还有一些
编译器是将一种高级语言编译成另一种高级语言,或者将低级语言编译成高级语言(反编译),或者将高级语言编译成虚拟机目标语言,如Java编译器等。
再回到如何让机器(不管是实体机还是虚拟机)执行代码的主题,不管是何种指令集都只有几种最基本的元素:加、减、乘、求余、求模等。这些运算又可以进一步分解成二进制位运算:与、或、异或等。这些运算又通过指令来完成,而指令的核心目的就是确定需要运算的种类(操作码)和运算需要的数据(操作数),以及从哪里(寄存器或栈)获取操作数、将运算结果存放到什么地方(寄存器或是栈)等。这种不同的操作方式又将指令划分成:一地址指令、二地址指令、三地址指令和零地址指令等ai地址指令。相应的指令集会有对应的架构实现,如基于寄存器的架构实现或者基于栈的架构实现,这里的基于寄存器或者栈都是指在一个指令中的操作数是如何存取的。
JVM为何要基于栈来设计有几个理由。一个是JVM要设计成与平台无关的,而平台无关性就是要保证在没有或者有很少的寄存器的机器上也要同样能正确地执行Java代码。例如,在80x86的机器上寄存器就是没有规律的,很难针对某一款机器设计通用的基于寄
存器的指令,所以基于寄存器的架构很难做到通用。在手机操作系统方面,Google的Android平台上的DalvikVM就是基于特定芯片(ARM)设计的基于寄存器的架构,这样在特定芯片上实现基于寄存器的架构可能更多考虑性能,但是也牺牲了跨平台的移植性,
当然在当前的手机上这个需求还不是最迫切的。
还有一个理由是为了指令的紧凑性,因为Java的字节码可能在网络上传输,所以class文件的大小也是设计JVM字节码指令的一个重要因素,如在class文件中字节码除了处理两个表跳转的指令外,其他都是字节对齐的,操作码可以只占一个字节大小,这都是为了
尽量让编译后的class文件更加紧凑。为了提高字节码在网络上的传输效率,Sim设计了一个Jar包的压缩工具Pack200,它可以将多个class文件中的重复的常量池的信息进行合并,如一般在每个class文件中都含有“Ljava/lang/String;”,那么多个class文件中的常量就可
以共用,从而起到减少数据量的作用。
每当创建一个新的线程时,JVM会为这个线程创建一个Java栈,同时会为这个线程分配一个PC寄存器,并且这个PC寄存器会指向这个线程的第一行可执行代码。每当调用一个新方法时会在这个栈上创建一个新的栈帧数据结构,这个栈帧会保留这个方法的一些元信息,如在这个方法中定义的局部变量、一些用来支持常量池的解析、正常方法返回及异常处理机制等。
下面以一个具体的例子来看一下执行引擎是如何将一段代码在执行部件上执行的,代码如下:
JVM工作机制
前面简单分析了 JVM的基本结构,下面再简单分析一下JVM是如何执行字节码命令的,也就是前面介绍的执行引擎是如何工作的。
机器如何执行代码
在分析JVM的执行引擎如何工作之前,我们不妨先看看在普通的实体机上程序是如何执行的。前面已经分析了计算机只接受机器指令,其他高级语言首先必须经过编译器编译成机器指令才能被计算机正确执行,所以从高级语言到机器.语言之间必须要有个翻译的
过程。我们知道机器语言一般都是和硬件平台密切相关的,而高级语言一般都是屏蔽所有底层的硬件平台甚至包括软件平台(如操作系统)的。高级语言之所以能屏蔽这些底层硬件架构的差异就是因为有中间的一个转换环节,这个转换环节就是编译,与硬件耦合的麻烦就交给了编译器,所以不同的硬件平台通常需要的编译器也是不同的。在当前这种环境下我们所说的不同的硬件平台已经被更上一层的软件平台所代替了,这个软件平台就是操作系统,与其说不同的硬件平台的差异还不如说操作系统之间的差异,因为现在的操作系统几乎完全向用户屏蔽了硬件,所以我们说编译器和操作系统的关系非常密切会更加容易让人理解。如C语言在Windows下的编译器为Microsoft C,而在Linux下通常是gcc,当然还有很多不同厂家的编译器,这些编译器都和操作系统关系不大,只是在实现上有些
差异。
过程。我们知道机器语言一般都是和硬件平台密切相关的,而高级语言一般都是屏蔽所有底层的硬件平台甚至包括软件平台(如操作系统)的。高级语言之所以能屏蔽这些底层硬件架构的差异就是因为有中间的一个转换环节,这个转换环节就是编译,与硬件耦合的麻烦就交给了编译器,所以不同的硬件平台通常需要的编译器也是不同的。在当前这种环境下我们所说的不同的硬件平台已经被更上一层的软件平台所代替了,这个软件平台就是操作系统,与其说不同的硬件平台的差异还不如说操作系统之间的差异,因为现在的操作系统几乎完全向用户屏蔽了硬件,所以我们说编译器和操作系统的关系非常密切会更加容易让人理解。如C语言在Windows下的编译器为Microsoft C,而在Linux下通常是gcc,当然还有很多不同厂家的编译器,这些编译器都和操作系统关系不大,只是在实现上有些
差异。
通常一个程序从编写到执行会经历以下一些阶段:
源代码(source code)—>预处理器(preprocessor)—>编译器(compiler)—>汇编程序(assembler)—>目标代码(object code )—> 链接器(Linker)—>可执行程序(executables )
除了源代码和最后的可执行程序,中间的所有环节都是由现代意义上的编译器统一完成的,如在Linux平台下我们通常安装一个软件需要经过configure、make、make install、make clean这4个步骤来完成。configure为这个程序在当前的操作系统环境下选择合适的
编译器来编译这个程序代码,也就是为这个程序代码选择合适的编译器和一些环境参数:make自然就是对程序代码进行编译操作了,它会将源码编译成可执行的目标文件。make install将已经编译好的可执行文件安装到操作系统指定或者默认的安装目录下。最后的
make clean用于删除编译时临时产生的目录或文件。
值得注意的是,我们通常所说的编译器都是将某种高级语言直接编译成可执行的目标机器语言(实际上在某种操作系统中是需要动态链接的目标二进制文件:在Windows下是dynamic link library, DLL;在 Linux 下是 Shared Library, SO 库)。但是实际上还有一些
编译器是将一种高级语言编译成另一种高级语言,或者将低级语言编译成高级语言(反编译),或者将高级语言编译成虚拟机目标语言,如Java编译器等。
再回到如何让机器(不管是实体机还是虚拟机)执行代码的主题,不管是何种指令集都只有几种最基本的元素:加、减、乘、求余、求模等。这些运算又可以进一步分解成二进制位运算:与、或、异或等。这些运算又通过指令来完成,而指令的核心目的就是确定需要运算的种类(操作码)和运算需要的数据(操作数),以及从哪里(寄存器或栈)获取操作数、将运算结果存放到什么地方(寄存器或是栈)等。这种不同的操作方式又将指令划分成:一地址指令、二地址指令、三地址指令和零地址指令等ai地址指令。相应的指令集会有对应的架构实现,如基于寄存器的架构实现或者基于栈的架构实现,这里的基于寄存器或者栈都是指在一个指令中的操作数是如何存取的。
JVM为何选择基于栈的架构
JVM执行字节码指令是基于栈的架构,也就是所有的操作系统必须先入栈,然后根据指令中的操作码选择从栈顶弹出若干个元素进行计算后再将结果压入栈。在JVM中操作数可以存放在每一个栈帧中的一个本地变量集中,即在每个方法调用时就会给这个方法分配一个本地变量集,这个本地变量集在编译时就已经确定,所有操作数入栈可以直接是常量入栈或者从本地变量集中取一个变量压入栈中。这和一般的基于寄存器的操作有所不同,一个操作需要频繁地入栈和出栈,如进行一个加法运算,如果两个操作数都在本地变量中,那么一个加法操作就要有5次栈操作,分别是将两个操作数从本地变量入栈(2次入栈操作),再将两个操作数出栈用于加法运算(2次出栈),再将加法结果压入栈顶(1次入栈)。如果是基于寄存器的话,一般只需要将两个操作数存入寄存器进行加法运算后
再将结果存入其中一个寄存器即可,不需要这么多的数据移动的操作。那么为什么JVM还要基于栈来设计呢?
再将结果存入其中一个寄存器即可,不需要这么多的数据移动的操作。那么为什么JVM还要基于栈来设计呢?
JVM为何要基于栈来设计有几个理由。一个是JVM要设计成与平台无关的,而平台无关性就是要保证在没有或者有很少的寄存器的机器上也要同样能正确地执行Java代码。例如,在80x86的机器上寄存器就是没有规律的,很难针对某一款机器设计通用的基于寄
存器的指令,所以基于寄存器的架构很难做到通用。在手机操作系统方面,Google的Android平台上的DalvikVM就是基于特定芯片(ARM)设计的基于寄存器的架构,这样在特定芯片上实现基于寄存器的架构可能更多考虑性能,但是也牺牲了跨平台的移植性,
当然在当前的手机上这个需求还不是最迫切的。
还有一个理由是为了指令的紧凑性,因为Java的字节码可能在网络上传输,所以class文件的大小也是设计JVM字节码指令的一个重要因素,如在class文件中字节码除了处理两个表跳转的指令外,其他都是字节对齐的,操作码可以只占一个字节大小,这都是为了
尽量让编译后的class文件更加紧凑。为了提高字节码在网络上的传输效率,Sim设计了一个Jar包的压缩工具Pack200,它可以将多个class文件中的重复的常量池的信息进行合并,如一般在每个class文件中都含有“Ljava/lang/String;”,那么多个class文件中的常量就可
以共用,从而起到减少数据量的作用。
执行引擎的架构设计
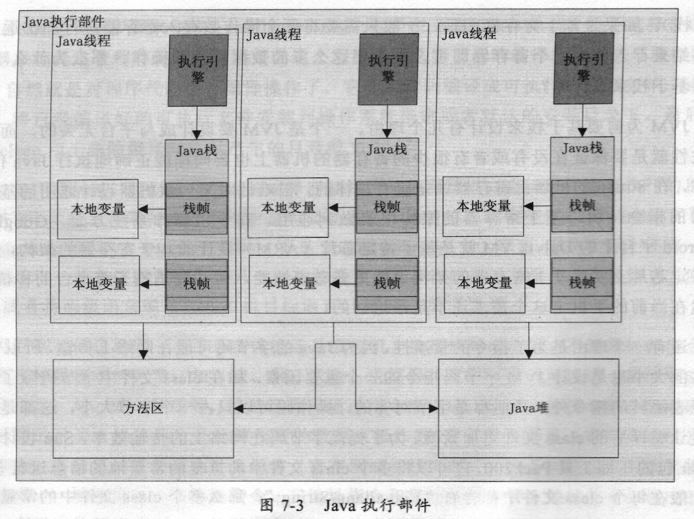
了解了 Java以栈为架构的原因后,再详细看一下JVM是如何设计Java的执行部件的,如图7-3所示。
每当创建一个新的线程时,JVM会为这个线程创建一个Java栈,同时会为这个线程分配一个PC寄存器,并且这个PC寄存器会指向这个线程的第一行可执行代码。每当调用一个新方法时会在这个栈上创建一个新的栈帧数据结构,这个栈帧会保留这个方法的一些元信息,如在这个方法中定义的局部变量、一些用来支持常量池的解析、正常方法返回及异常处理机制等。
JVM在调用某些指令时可能需要使用到常量池中的一些常量,或者是获取常量代表的数据或者这个数据指向的实例化的对象,而这些信息都存储在所有线程共享的方法区和Java堆中。
执行引擎的执行过程
public class Math {
public static void main(String[] args) {
int a=l;
int b=2;
int c = {a+b}*10;
}
}
其中main的字节码指令如下:
偏移量指令 说明
0: iconst一 1常数1入浅
1: istore—1将栈顶元雜M地魏1存储
2: iconstj常数2人找
3 : istorei将栈顶元素移人本地变量2存储
4: iload—1 本地变量1入钱
5: iload_2 2
6: iadd弹出栈顶两个元素相加
7: bipush 10 将 10 入栈
9: imul栈顶两个元素相乘
10: istore一3栈顶元素移入本地变量3存储
11: return 返回
对应到执行引擎的各执行部件如图74所示。
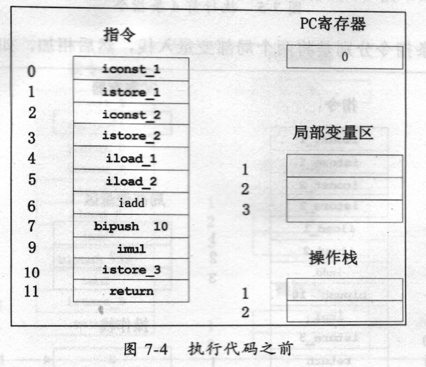
前4条指令执行完后,PC寄存器当前指向的是下一条指令地址,也就是第5条指令,这时局部变量区已经保存了两个局部变量(也就是变量a和b的值),而操作栈里仍然没有值,因为两次常数入栈后又分别出桟了。
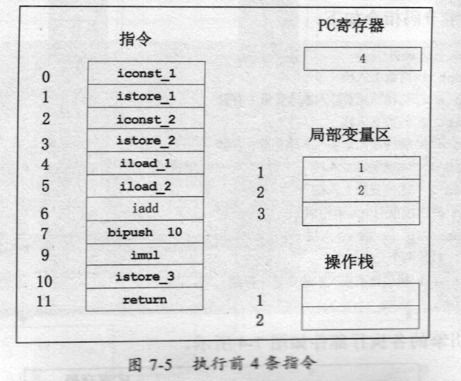
第5条和第6条指令分别是将两个局部变量入栈,然后相加,如图7-6所示。

1先入栈2后入栈,栈顶元素是2,第7条指令是将栈顶的两个元素弹出后相加,将结果再入栈,这时整个部件状态如图7-7所示。

可以看出,变量a和b相加的结果3存在当前栈的栈顶中,接下来是第8条指令将10入栈,如图7-8所示。

当前PC寄存器执行的地址是9,下一个操作是将当前栈的两个操作数弹出进行相乘并把结果压入栈中,如图7-9所示。
第10条指令是将当前的栈顶元素存入局部变量3中,这时状态如图7-10所示。


第10条指令执行完后栈中元素出栈,出栈的元素存储在局部变量区3中,对应的是
变量c的值。最后一条指令是return,这条指令执行完后当前的这个方法对应的这些部件
会被JVM回收,局部变量区的所有值将全部释放,PC寄存器会被销毁,在Java栈中与这
个方法对应的栈帧将消失。
JVM方法调用栈
JVM的方法调用分为两种:一种是Java方法调用,另一种是本地方法调用。本地方法调用由于各个虚拟机的实现不太相同,所以这里主要介绍Java的方法调用情况。
如下面一段方法调用的代码:
public class Math {
public statie void main(String[] args) {
int a=l;
int b-2;
int c - math(a#b)/10;
}
public static int math(int a,int b){
return (a+b)*10;
}
}
其中两个方法对应的字节码分别如下:
public static void main(java.lang.String[]};
Code:
0: iconst一1
1: istore 1
2: i const」
3: istore 2
4: iload_l
5: iload一2
6: invokestatic #2; //Method math:(II)
9: bipush 10
11: idiv
12: istore一3
13: return
public static int math{intf int);
Code:
0: iload-0
1: iload 一1
2: iadd
3: bipush 10
5: imul
6: ireturn
当JVM执行main方法时,首先将两个常数1和2分别存锗到局部变量区1和2中,然后调用静态math方法。从math的字节码指令可以看出,math方沄?:污个参数也存储在其对应的方法栈帧中的局部变量区0和1中,先将这两个局部变量分今\栈,然后进行相
加操作再和常数10相乘,最后将结果返回。
下面看一下实际的执行部件中是如何操作的,如图7-11所示。
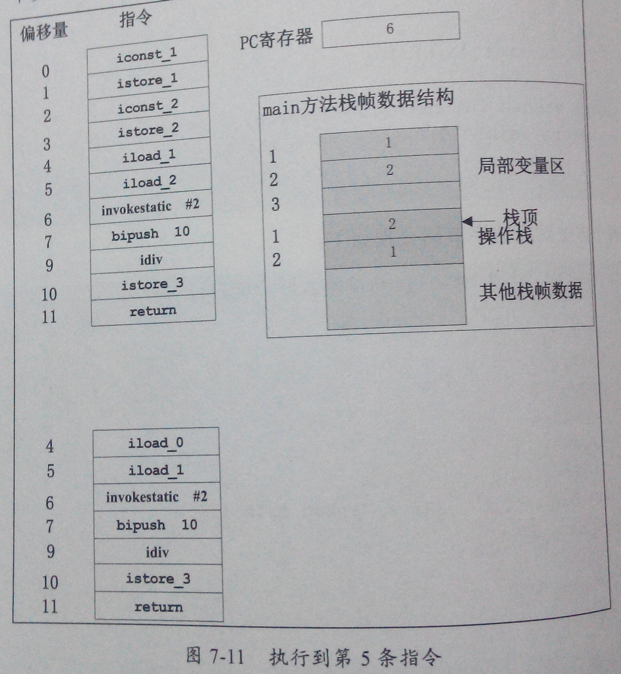
上图7-11是JVM执行到第I‘指令时,执行引擎各部件的状态图,PC寄存器指间的是下一条执行math方法的地址。当执行invokestatic指令时JVM会为math方法创建一个新的栈帧,并且将两个参数存在math方法对应的栈帧的前两个局部变量区中,这时PC寄存器会清零,并且会指向math方法对应栈帧地第一条指令地址,这时的状态图如图7-12所示。
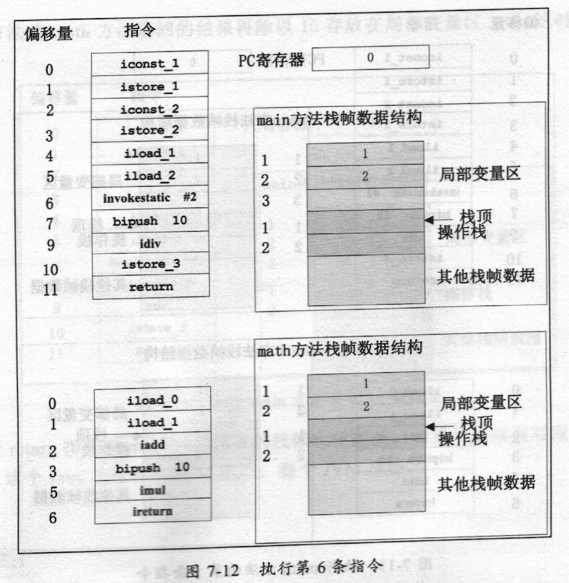
执行invokestatic指令时,S建了一个新的栈帧,这时栈帧中的局部变量区中已经有两个变量了,这两个变量是从mam方法的栈帧中的操作栈中传过来的。当执行math方法时,math方法对应的栈帧成为当It的活动栈帧,PC寄存器保存的是当前这个栈帧中的下
一条指令地址,所以是0。
一条指令地址,所以是0。
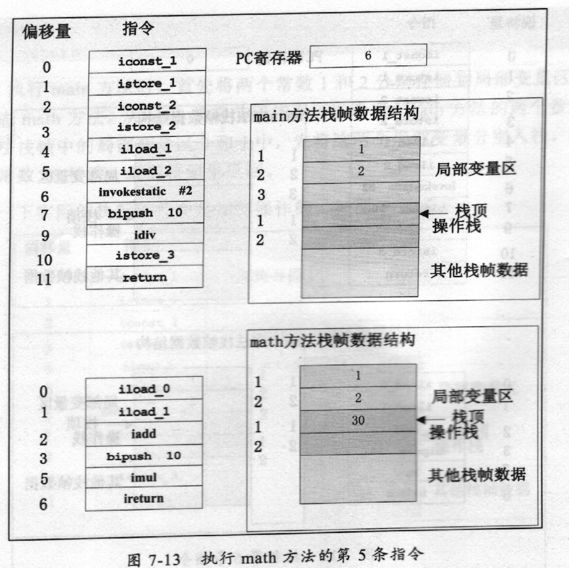
math方法先将a、b两个变量相fc,再乘以10,最后返回这个结果执行到第5条指令的状态,如图7-13所示。
math的操作栈中的栈顶元素相乘的结果是30,最后一条指令是iretura,这条指令是将当前栈帧中的栈顶元素返回到调用这个方法的栈中,而这个栈帧也将撤销,PC寄存器的值恢复调用桟的下一条指令地址,如图7-14所示。

main方法将math方法返回的结果再除以10存放在局部变量区3中,这时的状态如图7-15所示。
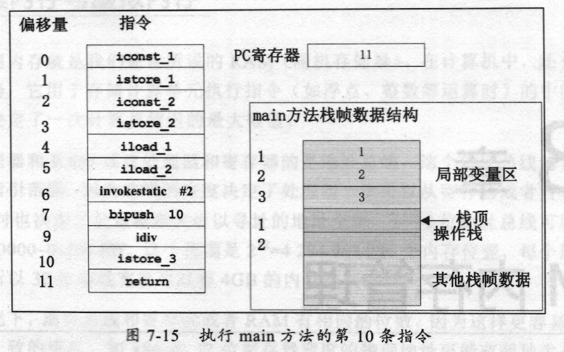
当执行return指令时main方法对应的栈帧也将撤销,如果当前线程对应的Java栈中没有栈帧,这个Java栈也将被JVM撤销,整个JVM退出。
总结
本章主要介绍了 JVM的体系结构,以及JVM的执行引擎执行JVM指令的过程,实际上JVM的设计非常复杂,包括JVM在执行字节码时如何来自动优化这些字节码,并将它们再编译成本地代码,也就是JIT技术,这个技术在我们执行测试时可能会有影响,如果你的程序没有经过充分的“预热”,那么得出的结果可能会不准确。例如,JVM在执行程序时会记录某个方法的执行次数,如果执行的次数到一个阈值(客户端一般是1500次,服务器一般是10000次)时JIT就会编译这个方法为本地代码。















 141
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









