







优化应用程序代码的内存使用并不是一个新主题,但是人们通常并没有很好地理解这个主题。本文将简要介绍 Java 进程的内存使用,随后深入探讨您编写的 Java 代码的内存使用。最后,本文将展示提高代码内存效率的方法,特别强调了 HashMap 和 ArrayList 等 Java 集合的使用。
背景信息:Java 进程的内存使用
架构提供的内存寻址能力依赖于处理器的位数,举例来说,32 位或者 64 位,对于大型机来说,还有 31 位。进程能够处理的位数决定了处理器能寻址的内存范围:32 位提供了 2^32 的可寻址范围,也就是 4,294,967,296 位,或者说 4GB。而 64 位处理器的可寻址范围明显增大:2^64,也就是 18,446,744,073,709,551,616,或者说 16 exabyte(百亿亿字节)。通过在命令行中执行 java 或者启动某种基于 Java 的中间件来运行 Java 应用程序时,Java 运行时会创建一个操作系统进程,就像您运行基于 C 的程序时那样。实际上,大多数 JVM 都是用 C 或者 C++ 语言编写的。作为操作系统进程,Java 运行时面临着与其他进程完全相同的内存限制:架构提供的寻址能力以及操作系统提供的用户空间。
处理器架构提供的部分可寻址范围由 OS 本身占用,提供给操作系统内核以及 C 运行时(对于使用 C 或者 C++ 编写的 JVM 而言)。OS 和 C 运行时占用的内存数量取决于所用的 OS,但通常数量较大:Windows 默认占用的内存是 2GB。剩余的可寻址空间(用术语来表示就是用户空间)就是可供运行的实际进程使用的内存。
对于 Java 应用程序,用户空间是 Java 进程占用的内存,实际上包含两个池:Java 堆和本机(非 Java)堆。Java 堆的大小由 JVM 的 Java 堆设置控制:-Xms 和 -Xmx 分别设置最小和最大 Java 堆。在按照最大的大小设置分配了 Java 堆之后,剩下的用户空间就是本机堆。图 1 展示了一个 32 位 Java 进程的内存布局:
图 1. 一个 32 位 Java 进程的内存布局示例

在 图 1 中,可寻址范围总共有 4GB,OS 和 C 运行时大约占用了其中的 1GB,Java 堆占用了将近 2GB,本机堆占用了其他部分。请注意,JVM 本身也要占用内存,就像 OS 内核和 C 运行时一样,而 JVM 占用的内存是本机堆的子集。
Java 对象详解
在您的 Java 代码使用 new 操作符创建一个 Java 对象的实例时,实际上分配的数据要比您想的多得多。例如,一个 int 值与一个 Integer 对象(能包含 int 值的最小对象)的大小比率是 1:4,这个比率可能会让您感到吃惊。额外的开销源于 JVM 用于描述 Java 对象的元数据,在本例中也就是 Integer。
根据 JVM 的版本和供应的不同,对象元数据的数量也各有不同,但其中通常包括:
- 类:一个指向类信息的指针,描述了对象类型。举例来说,对于
java.lang.Integer对象,这是java.lang.Integer类的一个指针。 - 标记:一组标记,描述了对象的状态,包括对象的散列码(如果有),以及对象的形状(也就是说,对象是否是数组)。
- 锁:对象的同步信息,也就是说,对象目前是否正在同步。
对象元数据后紧跟着对象数据本身,包括对象实例中存储的字段。对于 java.lang.Integer 对象,这就是一个 int。
如果您正在运行一个 32 位 JVM,那么在创建 java.lang.Integer 对象实例时,对象的布局可能如图 2 所示:
图 2. 一个 32 位 Java 进程的 java.lang.Integer 对象的布局示例

如 图 2 所示,有 128 位的数据被占用,其中用于存储 int 值的为 32 位,而对象元数据占用了其余的 96 位。
Java 数组对象详解
数组对象(例如一个 int 值数组)的形状和结构与标准 Java 对象相似。主要差别在于数组对象包含说明数组大小的额外元数据。因此,数据对象的元数据包括:
- 类:一个指向类信息的指针,描述了对象类型。举例来说,对于
int字段数组,这是int[]类的一个指针。 - 标记:一组标记,描述了对象的状态,包括对象的散列码(如果有),以及对象的形状(也就是说,对象是否是数组)。
- 锁:对象的同步信息,也就是说,对象目前是否正在同步。
- 大小:数组的大小。
图 3 展示了一个 int 数组对象的布局示例:
图 3. 一个 32 位 Java 进程的 int 数组对象的布局示例

如 图 3 所示,有 160 位的数据用于存储 int 值内的 32 位数据,而数组元数据占用了其余 160 位。对于 byte、int 和 long 等原语,从内存的方面考虑,单项数组比对应的针对单一字段的包装器对象(Byte、Integer 或 Long)的成本更高。
更为复杂数据结构详解
良好的面向对象设计与编程鼓励使用封装(提供接口类来控制数据访问)和委托(使用 helper 对象来实施任务)。封装和委托会使大多数数据结构的表示形式中包含多个对象。一个简单的示例就是 java.lang.String 对象。java.lang.String 对象中的数据是一个字符数组,由管理和控制对字符数组的访问的 java.lang.String 对象封装。图 4 展示了一个 32 位 Java 进程的java.lang.String 对象的布局示例:
图 4. 一个 32 位 Java 进程的 java.lang.String 对象的布局示例
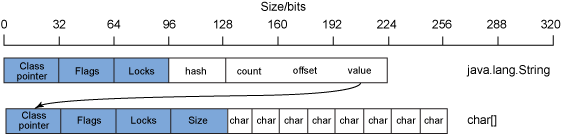
如 图 4 所示,除了标准对象元数据之外,java.lang.String 对象还包含一些用于管理字符串数据的字段。通常情况下,这些字段是散列值、字符串大小计数、字符串数据偏移量和对于字符数组本身的对象引用。
这也就意味着,对于一个 8 个字符的字符串(128 位的 char 数据),需要有 256 位的数据用于字符数组,224 位的数据用于管理该数组的java.lang.String 对象,因此为了表示 128 位(16 个字节)的数据,总共需要占用 480 位(60 字节)。开销比例为 3.75:1。
总体而言,数据结构越是复杂,开销就越高。下一节将具体讨论相关内容。
32 位和 64 位 Java 对象
之前的示例中的对象大小和开销适用于 32 位 Java 进程。在 背景信息:Java 进程的内存使用 一节中提到,64 位处理器的内存可寻址能力比 32 位处理器高得多。对于 64 位进程,Java 对象中的某些数据字段的大小(特别是对象元数据或者表示另一个对象的任何字段)也需要增加到 64 位。其他数据字段类型(例如 int、byte 和 long )的大小不会更改。图 5 展示了一个 64 位 Integer 对象和一个 int 数组的布局:
图 5. 一个 64 位进程的 java.lang.Integer 对象和 int 数组的布局示例

图 5 表明,对于一个 64 位 Integer 对象,现在有 224 位的数据用于存储 int 字段所用的 32 位,开销比例是 7:1。对于一个 64 位单元素 int数组,有 288 位的数据用于存储 32 位 int 条目,开销比例是 9:1。这在实际应用程序中产生的影响在于,之前在 32 位 Java 运行时中运行的应用程序若迁移到 64 位 Java 运行时,其 Java 堆内存使用量会显著增加。通常情况下,增加的数量是原始堆大小的 70% 左右。举例来说,一个在 32 位 Java 运行时中使用 1GB Java 堆的 Java 应用程序在迁移到 64 位 Java 运行时之后,通常需要使用 1.7GB 的 Java 堆。
请注意,这种内存增加并非仅限于 Java 堆。本机堆内存区使用量也会增加,有时甚至要增加 90% 之多。
表 1 展示了一个应用程序在 32 位和 64 位模式下运行时的对象和数组字段大小:
表 1. 32 位和 64 位 Java 运行时的对象中的字段大小
| 字段类型 | 字段大小(位) | |||
|---|---|---|---|---|
| 对象 | 数组 | |||
| 32 位 | 64 位 | 32 位 | 64 位 | |
boolean | 32 | 32 | 8 | 8 |
byte | 32 | 32 | 8 | 8 |
char | 32 | 32 | 16 | 16 |
short | 32 | 32 | 16 | 16 |
int | 32 | 32 | 32 | 32 |
float | 32 | 32 | 32 | 32 |
long | 32 | 32 | 64 | 64 |
double | 32 | 32 | 64 | 64 |
| 对象字段 | 32 | 64 (32*) | 32 | 64 (32*) |
| 对象元数据 | 32 | 64 (32*) | 32 | 64 (32*) |
* 对象字段的大小以及用于各对象元数据条目的数据的大小可通过 压缩引用或压缩 OOP 技术减小到 32 位。
压缩引用和压缩普通对象指针 (OOP)
IBM 和 Oracle JVM 分别通过压缩引用 (-Xcompressedrefs) 和压缩 OOP (-XX:+UseCompressedOops) 选项提供对象引用压缩功能。利用这些选项,即可在 32 位(而非 64 位)中存储对象字段和对象元数据值。在应用程序从 32 位 Java 运行时迁移到 64 位 Java 运行时的时候,这能消除 Java 堆内存使用量增加 70% 的负面影响。请注意,这些选项对于本机堆的内存使用无效,本机堆在 64 位 Java 运行时中的内存使用量仍然比 32 位 Java 运行时中的使用量高得多。
Java 集合的内存使用
在大多数应用程序中,大量数据都是使用核心 Java API 提供的标准 Java Collections 类来存储和管理的。如果内存占用对于您的应用程序极为重要,那么就非常有必要了解各集合提供的功能以及相关的内存开销。总体而言,集合功能的级别越高,内存开销就越高,因此使用提供的功能多于您需要的功能的集合类型会带来不必要的额外内存开销。
其中部分最常用的集合如下:
除了 HashSet 之外,此列表是按功能和内存开销进行降序排列的。(HashSet 是包围一个 HashMap 对象的包装器,它提供的功能比 HashMap少,同时容量稍微小一些。)
Java 集合:HashSet
HashSet 是 Set 接口的实现。Java Platform SE 6 API 文档对于 HashSet 的描述如下:
一个不包含重复元素的集合。更正式地来说,set(集)不包含元素 e1 和 e2 的配对 e1.equals(e2),而且至多包含一个空元素。正如其名称所表示的那样,这个接口将建模数学集抽象。
HashSet 包含的功能比 HashMap 要少,只能包含一个空条目,而且无法包含重复条目。该实现是包围 HashMap 的一个包装器,以及管理可在HashMap 对象中存放哪些内容的 HashSet 对象。限制 HashMap 功能的附加功能表示 HashSet 的内存开销略高。
图 6 展示了 32 位 Java 运行时中的一个 HashSet 的布局和内存使用:
图 6. 32 位 Java 运行时中的一个 HashSet 的内存使用和布局

图 6 展示了一个 java.util.HashSet 对象的 shallow 堆(独立对象的内存使用)以及保留堆(独立对象及其子对象的内存使用),以字节为单位。shallow 堆的大小是 16 字节,保留堆的大小是 144 字节。创建一个 HashSet 时,其默认容量(也就是该集中可以容纳的条目数量)将设置为 16 个条目。按照默认容量创建 HashSet,而且未在该集中输入任何条目时,它将占用 144 个字节。与 HashMap 的内存使用相比,超出了 16 个字节。表 2 显示了 HashSet 的属性:
表 2. 一个 HashSet 的属性
| 默认容量 | 16 个条目 |
|---|---|
| 空时的大小 | 144 个字节 |
| 开销 | 16 字节加 HashMap 开销 |
| 一个 10K 集合的开销 | 16 字节加 HashMap 开销 |
| 搜索/插入/删除性能 | O(1):所用时间是一个常量时间,无论要素数量如何都是如此(假设无散列冲突) |
Java 集合:HashMap
HashMap 是 Map 接口的实现。Java Platform SE 6 API 文档对于 HashMap 的描述如下:
一个将键映射到值的对象。一个映射中不能包含重复的键;每个键仅可映射到至多一个值。
HashMap 提供了一种存储键/值对的方法,使用散列函数将键转换为存储键/值对的集合中的索引。这允许快速访问数据位置。允许存在空条目和重复条目;因此,HashMap 是 HashSet 的简化版。
HashMap 将实现为一个 HashMap$Entry 对象数组。图 7 展示了 32 位 Java 运行时中的一个 HashMap 的内存使用和布局:
图 7. 32 位 Java 运行时中的一个 HashMap 的内存使用和布局

如 图 7 所示,创建一个 HashMap 时,结果是一个 HashMap 对象以及一个采用 16 个条目的默认容量的 HashMap$Entry 对象数组。这提供了一个 HashMap,在完全为空时,其大小是 128 字节。插入 HashMap 的任何键/值对都将包含于一个 HashMap$Entry 对象之中,该对象本身也有一定的开销。
大多数 HashMap$Entry 对象实现都包含以下字段:
-
int KeyHash -
Object next -
Object key -
Object value
一个 32 字节的 HashMap$Entry 对象用于管理插入集合的数据键/值对。这就意味着,一个 HashMap 的总开销包含 HashMap 对象、一个HashMap$Entry 数组条目和与各条目对应的 HashMap$Entry 对象的开销。可通过以下公式表示:
HashMap对象 + 数组对象开销 + (条目数量 * (HashMap$Entry数组条目 +HashMap$Entry对象))
对于一个包含 10,000 个条目的 HashMap 来说,仅仅 HashMap、HashMap$Entry 数组和 HashMap$Entry 对象的开销就在 360K 左右。这还没有考虑所存储的键和值的大小。
表 3 展示了 HashMap 的属性:
表 3. 一个 HashMap 的属性
| 默认容量 | 16 个条目 |
|---|---|
| 空时的大小 | 128 个字节 |
| 开销 | 64 字节加上每个条目 36 字节 |
| 一个 10K 集合的开销 | ~360K |
| 搜索/插入/删除性能 | O(1):所用时间是一个常量时间,无论要素数量如何都是如此(假设无散列冲突) |
Java 集合:Hashtable
Hashtable 与 HashMap 相似,也是 Map 接口的实现。Java Platform SE 6 API 文档对于 Hashtable 的描述如下:
这个类实现了一个散列表,用于将键映射到值。对于非空对象,可以将它用作键,也可以将它用作值。
Hashtable 与 HashMap 极其相似,但有两项限制。无论是键还是值条目,它均不接受空值,而且它是一个同步集合。相比之下,HashMap 可以接受空值,且不是同步的,但可以利用 Collections.synchronizedMap() 方法来实现同步。
Hashtable 的实现同样类似于 HashMap,也是条目对象的数组,在本例中即 Hashtable$Entry 对象。图 8 展示了 32 位 Java 运行时中的一个 Hashtable 的内存使用和布局:
图 8. 32 位 Java 运行时中的一个 Hashtable 的内存使用和布局

图 8 显示,创建一个 Hashtable 时,结果会是一个占用了 40 字节的内存的 Hashtable 对象,另有一个默认容量为 11 个条目的Hashtable$entry 数组,在 Hashtable 为空时,总大小为 104 字节。
Hashtable$Entry 存储的数据实际上与 HashMap 相同:
-
int KeyHash -
Object next -
Object key -
Object value
这意味着,对于 Hashtable 中的键/值条目,Hashtable$Entry 对象也是 32 字节,而 Hashtable 开销的计算和 10K 个条目的集合的大小(约为 360K)与 HashMap 类似。
表 4 显示了 Hashtable 的属性:
表 4. 一个 Hashtable 的属性
| 默认容量 | 11 个条目 |
|---|---|
| 空时的大小 | 104 个字节 |
| 开销 | 56 字节加上每个条目 36 字节 |
| 一个 10K 集合的开销 | ~360K |
| 搜索/插入/删除性能 | O(1):所用时间是一个常量时间,无论要素数量如何都是如此(假设无散列冲突) |
如您所见,Hashtable 的默认容量比 HashMap 要稍微小一些(分别是 11 与 16)。除此之外,两者之间的主要差别在于 Hashtable 无法接受空键和空值,而且是默认同步的,但这可能是不必要的,还有可能降低集合的性能。
Java 集合:LinkedList
LinkedList 是 List 接口的链表实现。Java Platform SE 6 API 文档对于 LinkedList 的描述如下:
一种有序集合(也称为序列)。此接口的用户可以精确控制将各元素插入列表时的位置。用户可以按照整数索引(代表在列表中的位置)来访问元素,也可以搜索列表中的元素。与其他集合 (set) 不同,该集合 (collection) 通常允许存在重复的元素。
实现是 LinkedList$Entry 对象链表。图 9 展示了 32 位 Java 运行时中的 LinkedList 的内存使用和布局:
图 9. 32 位 Java 运行时中的一个 LinkedList 的内存使用和布局

图 9 表明,创建一个 LinkedList 时,结果将得到一个占用 24 字节内存的 LinkedList 对象以及一个 LinkedList$Entry 对象,在LinkedList 为空时,总共占用的内存是 48 个字节。
链表的优势之一就是能够准确调整其大小,且无需重新调整。默认容量实际上就是一个条目,能够在添加或删除条目时动态扩大或缩小。每个LinkedList$Entry 对象仍然有自己的开销,其数据字段如下:
-
Object previous -
Object next -
Object value
但这比 HashMap 和 Hashtable 的开销低,因为链表仅存储单独一个条目,而非键/值对,由于不会使用基于数组的查找,因此不需要存储散列值。从负面角度来看,在链表中查找的速度要慢得多,因为链表必须依次遍历才能找到需要查找的正确条目。对于较大的链表,结果可能导致漫长的查找时间。
表 5 显示了 LinkedList 的属性:
表 5. 一个 LinkedList 的属性
| 默认容量 | 1 个条目 |
|---|---|
| 空时的大小 | 48 个字节 |
| 开销 | 24 字节加上每个条目 24 字节 |
| 一个 10K 集合的开销 | ~240K |
| 搜索/插入/删除性能 | O(n):所用时间与元素数量线性相关。 |
Java 集合:ArrayList
ArrayList 是 List 接口的可变长数组实现。Java Platform SE 6 API 文档对于 ArrayList 的描述如下:
一种有序集合(也称为序列)。此接口的用户可以精确控制将各元素插入列表时的位置。用户可以按照整数索引(代表在列表中的位置)来访问元素,也可以搜索列表中的元素。与其他集合 (set) 不同,该集合 (collection) 通常允许存在重复的元素。
不同于 LinkedList,ArrayList 是使用一个 Object 数组实现的。图 10 展示了一个 32 位 Java 运行时中的 ArrayList 的内存使用和布局:
图 10. 32 位 Java 运行时中的一个 ArrayList 的内存使用和布局

图 10 表明,在创建 ArrayList 时,结果将得到一个占用 32 字节内存的 ArrayList 对象,以及一个默认大小为 10 的 Object 数组,在ArrayList 为空时,总计占用的内存是 88 字节。这意味着 ArrayList 无法准确调整大小,因此拥有一个默认容量,恰好是 10 个条目。
表 6 展示了一个 ArrayList 的属性:
表 6. 一个 ArrayList 的属性
| 默认容量 | 10 |
|---|---|
| 空时的大小 | 88 个字节 |
| 开销 | 48 字节加上每个条目 4 字节 |
| 一个 10K 集合的开销 | ~40K |
| 搜索/插入/删除性能 | O(n):所用时间与元素数量线性相关 |
其他类型的 “集合”
除了标准集合之外,StringBuffer 也可以视为集合,因为它管理字符数据,而且在结构和功能上与其他集合相似。Java Platform SE 6 API 文档对于 StringBuffer 的描述如下:
线程安全、可变的字符序列……每个字符串缓冲区都有相应的容量。只要字符串缓冲区内包含的字符序列的长度不超过容量,就不必分配新的内部缓冲区数组。如果内部缓冲区溢出,则会自动为其扩大容量。
StringBuffer 是作为一个 char 数组来实现的。图 11 展示了一个 32 位 Java 运行时中的 StringBuffer 的内存使用和布局:
图 11. 32 位 Java 运行时中的一个 StringBuffer 的内存使用和布局

图 11 展示,创建一个 StringBuffer 时,结果将得到一个占用 24 字节内存的 StringBuffer 对象,以及一个默认大小为 16 的字符数组,在StringBuffer 为空时,数据总大小为 72 字节。
与集合相似,StringBuffer 拥有默认容量和重新调整大小的机制。表 7 显示了 StringBuffer 的属性:
表 7. 一个 StringBuffer 的属性
| 默认容量 | 16 |
|---|---|
| 空时的大小 | 72 个字节 |
| 开销 | 24 个字节 |
| 一个 10K 集合的开销 | 24 个字节 |
| 搜索/插入/删除性能 | 不适用 |
集合中的空白空间
拥有给定数量对象的各种集合的开销并不是内存开销的全部。前文的示例中的度量假设集合已经得到了准确的大小调整。然而,对于大多数集合来说,这种假设都是不成立的。大多数集合在创建时都指定给定的初始容量,数据将置入集合之中。这也就是说,集合拥有的容量往往大于集合中存储的数据容量,这造成了额外的开销。
考虑一个 StringBuffer 的示例。其默认容量是 16 个字符条目,大小为 72 字节。初始情况下,72 个字节中未存储任何数据。如果您在字符数组中存储了一些字符,例如 "MY STRING" ,那么也就是在 16 个字符的数组中存储了 9 个字符。图 12 展示了 32 位 Java 运行时中的一个包含 "MY STRING" 的 StringBuffer 的内存使用和布局:
图 12. 32 位 Java 运行时中的一个包含 "MY STRING" 的 StringBuffer 的内存使用
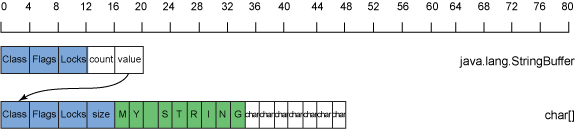
如 图 12 所示,数组中有 7 个可用的字符条目未被使用,但占用了内存,在本例中,这造成了 112 字节的额外开销。对于这个集合,您在 16 的容量中存储了 9 个条目,因而填充率 为 0.56。集合的填充率越低,因多余容量而造成的开销就越高。
集合的扩展和重新调整
在集合达到容量限制时,如果出现了在集合中存储额外条目的请求,那么会重新调整集合,并扩展它以容纳新条目。这将增加容量,但往往会降低填充比,造成更高的内存开销。
各集合所用的扩展算法各有不同,但一种通用的做法就是将集合的容量加倍。这也是 StringBuffer 采用的方法。对于前文示例中的StringBuffer,如果您希望将 " OF TEXT" 添加到缓冲区中,生成 "MY STRING OF TEXT",则需要扩展集合,因为新的字符集合拥有 17 个条目,当前容量 16 无法满足其要求。图 13 展示了所得到的内存使用:
图 13. 32 位 Java 运行时中的一个包含 "MY STRING OF TEXT" 的 StringBuffer 的内存使用
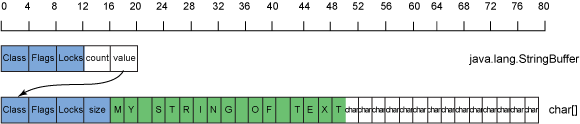
现在,如 图 13 所示,您得到了一个 32 个条目的字符数组,但仅仅使用了 17 个条目,填充率为 0.53。填充率并未显著下滑,但您现在需要为多余的容量付出 240 字节的开销。
对于小字符串和集合,低填充率和多余容量的开销可能并不会被视为严重问题,而在大小增加时,这样的问题就会愈加明显,代价也就愈加高昂。例如,如果您创建了一个 StringBuffer,其中仅包含 16MB 的数据,那么(在默认情况下)它将使用大小设置为可容纳 32MB 数据的字符数组,这造成了以多余容量形式存在的 16MB 的额外开销。
Java 集合:汇总
表 8 汇总了集合的属性:
表 8. 集合属性汇总
| 集合 | 性能 | 默认容量 | 空时的大小 | 10K 条目的开销 | 准确设置大小? | 扩展算法 |
|---|---|---|---|---|---|---|
HashSet | O(1) | 16 | 144 | 360K | 否 | x2 |
HashMap | O(1) | 16 | 128 | 360K | 否 | x2 |
Hashtable | O(1) | 11 | 104 | 360K | 否 | x2+1 |
LinkedList | O(n) | 1 | 48 | 240K | 是 | +1 |
ArrayList | O(n) | 10 | 88 | 40K | 否 | x1.5 |
StringBuffer | O(1) | 16 | 72 | 24 | 否 | x2 |
Hash 集合的性能比任何 List 的性能都要高,但每条目的成本也要更高。由于访问性能方面的原因,如果您正在创建大集合(例如,用于实现缓存),那么最好使用基于 Hash 的集合,而不必考虑额外的开销。
对于并不那么注重访问性能的较小集合而言,List 则是合理的选择。ArrayList 和 LinkedList 集合的性能大体相同,但其内存占用完全不同:ArrayList 的每条目大小要比 LinkedList 小得多,但它不是准确设置大小的。List 要使用的正确实现是 ArrayList 还是 LinkedList取决于 List 长度的可预测性。如果长度未知,那么正确的选择可能是 LinkedList,因为集合包含的空白空间更少。如果大小已知,那么ArrayList 的内存开销会更低一些。
选择正确的集合类型使您能够在集合性能与内存占用之间达到合理的平衡。除此之外,您可以通过正确调整集合大小来最大化填充率、最小化未得到利用的空间,从而最大限度地减少内存占用。
集合的实际应用:PlantsByWebSphere 和 WebSphere Application Server Version 7
在 表 8 中,创建一个包含 10,000 个条目、基于 Hash 的集合的开销是 360K。考虑到,复杂的 Java 应用程序常常使用大小为数 GB 的 Java 堆运行,因此这样的开销看起来并不是非常高,当然,除非使用了大量集合。
表 9 展示了在包含五个用户的负载测试中运行 WebSphere® Application Server Version 7 提供的 PlantsByWebSphere 样例应用程序时,Java 堆使用的 206MB 中的集合对象使用量:
表 9. WebSphere Application Server v7 中的 PlantsByWebSphere 的集合使用量
| 集合类型 | 实例数量 | 集合总开销 (MB) |
|---|---|---|
Hashtable | 262,234 | 26.5 |
WeakHashMap | 19,562 | 12.6 |
HashMap | 10,600 | 2.3 |
ArrayList | 9,530 | 0.3 |
HashSet | 1,551 | 1.0 |
Vector | 1,271 | 0.04 |
LinkedList | 1,148 | 0.1 |
TreeMap | 299 | 0.03 |
| 总计 | 306,195 | 42.9 |
通过 表 9 可以看到,这里使用了超过 30 万个不同的集合,而且仅集合本身(不考虑其中包含的数据)就占用了 206MB 的 Java 堆用量中的 42.9MB(21%)。这就意味着,如果您能更改集合类型,或者确保集合的大小更加准确,那么就有可能实现可观的内存节约。
通过 Memory Analyzer 查找低填充率
IBM Java 监控和诊断工具(Memory Analyzer 工具是在 IBM Support Assistant 中提供的)可以分析 Java 集合的内存使用情况(请参阅 参考资料 部分)。其功能包括分析集合的填充率和大小。您可以使用这样的分析来识别需要优化的集合。
Memory Analyzer 中的集合分析位于 Open Query Browser -> Java Collections 菜单中,如图 14 所示:
图 14. 在 Memory Analyzer 中分析 Java 集合的填充率
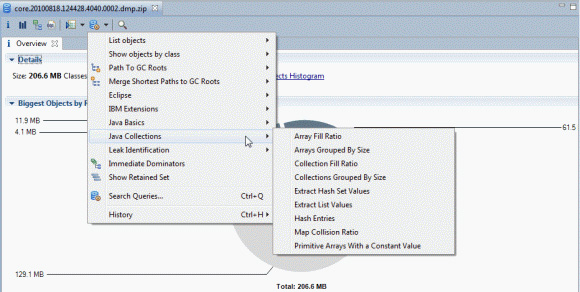
在判断当前大小超出需要的大小的集合时,图 14 中选择的 Collection Fill Ratio 查询是最有用的。您可以为该查询指定多种选项,这些选项包括:
- 对象:您关注的对象类型(集合)
- 分段:用于分组对象的填充率范围
将对象选项设置为 "java.util.Hashtable"、将分段选项设置为 "10",之后运行查询将得到如图 15 所示的输出结果:
图 15. 在 Memory Analyzer 中对 Hashtable 的填充率分析
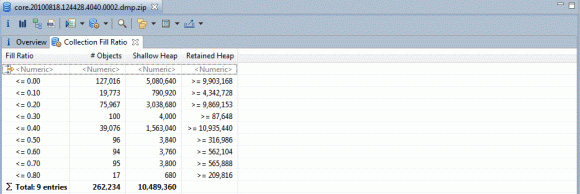
图 15 表明,在 java.util.Hashtable 的 262,234 个实例中,有 127,016 (48.4%) 的实例完全未空,几乎所有实例都仅包含少量条目。
随后便可识别这些集合,方法是选择结果表中的一行,右键单击并选择 list objects -> with incoming references,查看哪些对象拥有这些集合,或者选择 list objects -> with outgoing references,查看这些集合中包含哪些条目。图 16 展示了查看对于空 Hashtable 的传入引用的结果,图中展开了一些条目:
图 16. 在 Memory Analyzer 中对于空 Hashtable 的传入引用的分析
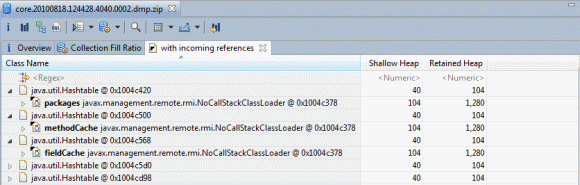
图 16 表明,某些空 Hashtable 归 javax.management.remote.rmi.NoCallStackClassLoader 代码所有。
通过查看 Memory Analyzer 左侧面板中的 Attributes 视图,您就可以看到有关 Hashtable 本身的具体细节,如图 17 所示:
图 17. 在 Memory Analyzer 中检查空 Hashtable
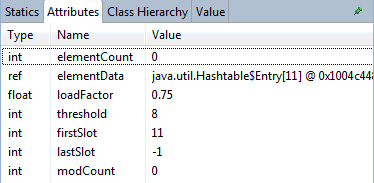
图 17 表明,Hashtable 的大小为 11(默认大小),而且完全是空的。
对于 javax.management.remote.rmi.NoCallStackClassLoader 代码,可以通过以下方法来优化集合使用:
- 延迟分配
Hashtable:如果Hashtable为空是经常发生的普遍现象,那么仅在存在需要存储的数据时分配Hashtable应该是一种合理的做法。 - 将
Hashtable分配为准确的大小:由于使用默认大小,因此完全可以使用更为准确的初始大小。
这些优化是否适用取决于代码的常用方式以及通常存储的是哪些数据。
PlantsByWebSphere 示例中的空集合
表 10 展示了分析 PlantsByWebSphere 示例中的集合来确定哪些集合为空时的分析结果:
表 10. WebSphere Application Server v7 中 PlantsByWebSphere 的空集合使用量
| 集合类型 | 实例数量 | 空实例 | 空实例百分比 |
|---|---|---|---|
Hashtable | 262,234 | 127,016 | 48.4 |
WeakHashMap | 19,562 | 19,465 | 99.5 |
HashMap | 10,600 | 7,599 | 71.7 |
ArrayList | 9,530 | 4,588 | 48.1 |
HashSet | 1,551 | 866 | 55.8 |
Vector | 1,271 | 622 | 48.9 |
| 总计 | 304,748 | 160,156 | 52.6 |
表 10 表明,平均而言,超过 50% 的集合为空,也就是说通过优化集合使用能够实现可观的内存占用节约。这种优化可以应用于应用程序的各个级别:应用于 PlantsByWebSphere 示例代码中、应用于 WebSphere Application Server 中,以及应用于 Java 集合类本身。
在 WebSphere Application Server 版本 7 与版本 8 之间,我们做出了一些努力来改进 Java 集合和中间件层的内存效率。举例来说,java.util.WeahHashMap 实例的开销中,有很大一部分比例源于其中包含用来处理弱引用的 java.lang.ref.ReferenceQueue 实例。图 18 展示了 32 位 Java 运行时中的一个 WeakHashMap 的内存布局:
图 18. 32 位 Java 运行时中的一个 WeakHashMap 的内存布局
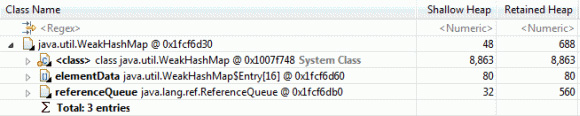
图 18 表明,ReferenceQueue 对象负责保留占用 560 字节的数据,即便在 WeakHashMap 为空、不需要 ReferenceQueue 的情况下也是如此。对于 PlantsByWebSphere 示例来说,在空 WeakHashMap 的数量为 19,465 的情况下,ReferenceQueue 对象将额外增加 10.9MB 的非必要数据。在 WebSphere Application Server 版本 8 和 IBM Java 运行时的 Java 7 发布版中,WeakHashMap 得到了一定的优化:它包含一个ReferenceQueue,这又包含一个 Reference 对象数组。该数组已经更改为延迟分配,也就是说,仅在向 ReferenceQueue 添加了对象的情况下执行分配。
结束语
在任何给定应用程序中,都存在着数量庞大(或许达到惊人的程度)的集合,复杂应用程序中的集合数量可能会更多。使用大量集合往往能够提供通过选择正确的集合、正确地调整其大小(或许还能通过延迟分配集合)来实现有时极其可观的内存占用节约的范围。这些决策最好在设计和开发的过程中制定,但您也可以利用 Memory Analyzer 工具来分析现有应用程序中存在内存占用优化潜力的部分。
参考资料
学习
- "从转储(Dump)文件中调试并除错"(Chris Bailey、Andrew Johnson 及 Kevin Grigorenko,developerWorks,2011 年 3 月):了解如何利用 Memory Analyzer 生成转储文件,并利用转储文件来检查应用程序的状态。
- "权威支持:Memory Analyzer(及其 IBM Extensions 插件)为何不再只用于内存泄露"(Chris Bailey、Kevin Grigorenko 和 Mahesh Rathi 博士,developerWorks,2011 年 3 月):这篇文章展示了如何将 Memory Analyzer 与 IBM Extensions for Memory Analyzer 插件结合使用,检查 WebSphere Application Server 和您的应用程序的状态。
- "关于 Java Collections API 您不知道的五件事,第 1 部分"(Ted Neward,developerWorks,2010 年 4 月):阅读利用 Collections 完成更多任务的五个提示。第 2 部分 中又提供了五个提示。
- 浏览 技术书店,阅读有关这些主题和其他技术主题的图书。
- developerWorks 中国网站 Java 技术专区:查看数百篇关于 Java 编程各个方面的文章。















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









