







目录
题单题解都是我所写,不一定为最简单易懂的题解,但一定为正确且比较贴近基础的题解
由于题目较多,手机端进行阅读的话可以直接点击目录进行跳转
电脑端进行阅读的话既可以通过文章目录进行跳转,也可以通过文章左下角小目录点击跳转
本文章牵涉的算法在我的《ACM算法》专栏之中都有牵涉
若想查阅其余算法可前往我的《ACM算法》专栏
想获得更多测试样例和测试数据可以私聊找我要
货仓选址
在一条数轴上有 N 家商店,它们的坐标分别为 A1∼AN。
现在需要在数轴上建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。
为了提高效率,求把货仓建在何处,可以使得货仓到每家商店的距离之和最小。
输入格式
第一行输入整数 N。
第二行 N 个整数 A1∼AN。
输出格式
输出一个整数,表示距离之和的最小值。
数据范围
1≤N≤100000,
0≤Ai≤40000
输入样例:
4
6 2 9 1
输出样例:
12源代码
//这道题考察的知识点是快速选择算法和绝对值不等式
//注意陷阱点,数轴上的元素皆为货舱选址,也就是选址只能在商店建立
//这也就使货舱的地址在所有的商店地址进行排序之后的中位数位置
//那么对于偶数来说,假设下标1-n,即下标从1开始的话,那么我们发现 n / 2 必定为中位数的下标
//但是若是奇数个元素个数的话,根据c++向下取整的原则,我们(n + 1) / 2 才为中位数下标
//综合奇数和偶数个元素的不同情况,发现偶数的情况是奇数情况的一个子集
//因此我们可以推算出排序之后中位数即货舱选址的下标是(n + 1) / 2
#include <iostream>
using namespace std;
const int N = 1000000 + 10;
int a[N];
//首先,我们利用分治的思想手打一个快速排序的算法模板
//而后对于快速排序算法我们进行修改,使之成为快速选择算法
//即使算法能够在进行排序的同时还可以利用下标进行查找我们所需要的元素
//有点类似于利用下标所进行的二分查找
int quick_sort(int q[],int l,int r,int k)
{
if(l >= r) return q[l];
int x = q[l + r >> 1],i = l - 1,j = r + 1;
while(i < j)
{
do i ++ ;while(q[i] < x);
do j -- ;while(q[j] > x);
if(i < j)swap(q[i],q[j]);
}
int sl = j - l + 1;
if(k <= sl)return quick_sort(q,l,j,k);
else return quick_sort(q,j + 1,r,k - sl);
}
int main()
{
int n;
cin >> n;
for(int i = 1;i <= n;i ++ )cin >> a[i];
//调用自定义的快速选择算法
int idx = quick_sort(a,1,n,(n + 1) / 2);
int ans = 0;
//累计求和
for(int i = 1;i <= n;i ++ )ans += abs(a[i] - idx);
//答案输出
cout << ans << endl;
return 0;
}校门外的树
某校大门外长度为 L 的马路上有一排树,每两棵相邻的树之间的间隔都是 1 米。
我们可以把马路看成一个数轴,马路的一端在数轴 0 的位置,另一端在 L 的位置;数轴上的每个整数点,即 0,1,2,……,L,都种有一棵树。
由于马路上有一些区域要用来建地铁。
这些区域用它们在数轴上的起始点和终止点表示。
已知任一区域的起始点和终止点的坐标都是整数,区域之间可能有重合的部分。
现在要把这些区域中的树(包括区域端点处的两棵树)移走。
你的任务是计算将这些树都移走后,马路上还有多少棵树。
输入格式
输入文件的第一行有两个整数 L 和 M,L 代表马路的长度,M 代表区域的数目,L 和 M 之间用一个空格隔开。
接下来的 M 行每行包含两个不同的整数,用一个空格隔开,表示一个区域的起始点和终止点的坐标。
输出格式
输出文件包括一行,这一行只包含一个整数,表示马路上剩余的树的数目。
数据范围
1≤L≤10000,
1≤M≤100
输入样例:
500 3
150 300
100 200
470 471
输出样例:
298源代码
//本道题考察的算法为差分,注意树的位置是从0-n,也就是说
//在使用差分数组的时候,因为下标要从一开始
//因此我们所要处理的总区间就变成了1-(n+1)
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1000000 + 10;
int a[N],ans = 0;
//构造差分所需要的函数
void insert(int l,int r,int c)
{
a[l] += c;
a[r + 1] -= c;
}
int main()
{
//初始化数组a
memset(a,0,sizeof(a));
int n,m;
cin >> n >> m;
while(m -- )
{
int l,r;
cin >> l >> r;
//注意下标是从1 - (n + 1),因此将差分处理区间整体后移一位即可实现差分运算
insert(l + 1,r + 1,1);
}
//在差分数组进行自身前缀和还原的同时,计算剩余树的个数
for(int i = 1;i <= n + 1;i ++ )
{
a[i] += a[i - 1];
if(a[i] == 0)ans ++ ;
}
cout << ans << endl;
return 0;
}奖学金
某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前 5 名学生发奖学金。
期末,每个学生都有 3 门课的成绩:语文、数学、英语。
先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高到低排序,如果两个同学总分和语文成绩都相同,那么规定学号小的同学排在前面,这样,每个学生的排序是唯一确定的。
任务:先根据输入的 3 门课的成绩计算总分,然后按上述规则排序,最后按排名顺序输出前五名学生的学号和总分。
注意,在前 5 名同学中,每个人的奖学金都不相同,因此,你必须严格按上述规则排序。
例如,在某个正确答案中,如果前两行的输出数据(每行输出两个数:学号、总分) 是:
7 279
5 279
这两行数据的含义是:总分最高的两个同学的学号依次是 7 号、5 号。
这两名同学的总分都是 279 (总分等于输入的语文、数学、英语三科成绩之和),但学号为 7 的学生语文成绩更高一些。
如果你的前两名的输出数据是:
5 279
7 279
则按输出错误处理。
输入格式
输入文件包含 n+1 行:
第 1 行为一个正整数 n,表示该校参加评选的学生人数。
第 2 到 n+1 行,每行有 3 个用空格隔开的数字,每个数字都在 0 到 100 之间,第 j 行的 3 个数字依次表示学号为 j−1 的学生的语文、数学、英语的成绩。
每个学生的学号按照输入顺序编号为 1∼n (恰好是输入数据的行号减 1)。
所给的数据都是正确的,不必检验。
输出格式
输出文件共有 5 行,每行是两个用空格隔开的正整数,依次表示前 5 名学生的学号和总分。
数据范围
6≤n≤300
输入样例:
6
90 67 80
87 66 91
78 89 91
88 99 77
67 89 64
78 89 98
输出样例:
6 265
4 264
3 258
2 244
1 237源代码
//本题目考察的是非常简单的结构体排序算法
//也就是非常简单的利用算法库algorithm库当中的sort函数和自定义cmp函数结合
//而后实现sort排序的方式重定义的效果
//从而对于结构体所有的数据进行整体的排序
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 300 + 10;
struct Student
{
int Y;
int S;
int E;
int sum;
int num;
};
//自定义cmp函数
int cmp(const struct Student &A,const struct Student &B)
{
if(A.sum != B.sum)return A.sum > B.sum;//总分第一优先级比较
else if(A.Y != B.Y)return A.Y > B.Y;//语文第二优先级比较
else return A.num < B.num;//序号第三优先级比较
}
int main()
{
Student stu[N];
int n;
cin >> n;
//对于结构体的数据进行输入
for(int i = 1;i <= n;i ++ )
{
stu[i].num = i;
cin >> stu[i].Y >> stu[i].S >> stu[i].E;
stu[i].sum = stu[i].Y + stu[i].S + stu[i].E;
}
//sort与cmp结合排序
sort(stu + 1,stu + 1 + n,cmp);
//输出前五名
for(int i = 1;i <= 5;i ++ )cout << stu[i].num << ' ' << stu[i].sum << endl;
}蛇形矩阵
输入两个整数 n 和 m,输出一个 n 行 m 列的矩阵,将数字 1 到 n×m 按照回字蛇形填充至矩阵中。
具体矩阵形式可参考样例。
输入格式
输入共一行,包含两个整数 n 和 m。
输出格式
输出满足要求的矩阵。
矩阵占 n 行,每行包含 m 个空格隔开的整数。
数据范围
1≤n,m≤100
输入样例:
3 3
输出样例:
1 2 3
8 9 4
7 6 5源代码
//直接暴力的模拟
//原本想用dfs来填充数字,结果发现不好控制优先级
//即原本向上填充的数字变得会向右填充(偏移量数组右下左上的顺序)
//所以直接用一个while嵌套四个方向的while,一条路走到黑
//待走到填充数自增之后等于n * m时即走完了,跳出循环输出矩阵即可
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1000 + 10;
int a[N][N],idx = 1;
int n,m;
int main()
{
cin >> n >> m;
int x = 1,y = 1;
a[x][y] = idx;
while(idx < n * m)
{
//右能走向右走
while(y + 1 >= 1 && y + 1 <= m && a[x][y + 1] == 0)a[x][++ y] = ++ idx;
//下能走向下走
while(x + 1 >= 1 && x + 1 <= n && a[x + 1][y] == 0)a[++ x][y] = ++ idx;
//左能走向左走
while(y - 1 >= 1 && y - 1 <= m && a[x][y - 1] == 0)a[x][-- y] = ++ idx;
//上能走向上走
while(x - 1 >= 1 && x - 1 <= n && a[x - 1][y] == 0)a[-- x][y] = ++ idx;
}
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= m;j ++ )
{
cout << a[i][j] << ' ';
}
cout << endl;
}
return 0;
}找硬币
伊娃喜欢从整个宇宙中收集硬币。
有一天,她去了一家宇宙购物中心购物,结账时可以使用各种硬币付款。
但是,有一个特殊的付款要求:每张帐单,她只能使用恰好两个硬币来准确的支付消费金额。
给定她拥有的所有硬币的面额,请你帮她确定对于给定的金额,她是否可以找到两个硬币来支付。
输入格式
第一行包含两个整数 N 和 M,分别表示硬币数量以及需要支付的金额。
第二行包含 N 个整数,表示每个硬币的面额。
输出格式
输出一行,包含两个整数 V1,V2,表示所选的两个硬币的面额,使得 V1≤V2 并且 V1+V2=M
如果答案不唯一,则输出 V1 最小的解。
如果无解,则输出 No Solution。
数据范围
1≤N≤10^5
1≤M≤1000
输入样例1:
8 15
1 2 8 7 2 4 11 15
输出样例1:
4 11
输入样例2:
7 14
1 8 7 2 4 11 15
输出样例2:
No Solution源代码
//本题考察的为双指针算法,根据题意,选择的必为两枚硬币,且和的话要满足条件
//对于时间复杂度的优化的话,避免暴力超时就使用双指针算法
//根据题意,在使用排序之后,我们可以从头开始遍历,尾指针放置在末尾,也就是“小数”+“大数”的形式
//而后当“小数”+“大数”的和大于目标值,则证明大数过大,尾指针前移,当尾指针前移至小于目标值时,此时有两种情况
//一种是有解的情况即头尾指针元素之和正好是目标值,第二种是无解情况即头尾指针之和小于目标值
//若是查找到了元素的解则直接break进行输出,若是没有查找到则将小数递增来实现下次查找
//这样就可以将本题的时间复杂度进行巨大的优化
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1000000 + 10;
int a[N];
int main()
{
int n,m;
cin >> n >> m;
for(int i = 1;i <= n;i ++ )cin >> a[i];
//调用算法库函数进行排序
sort(a + 1,a + 1 + n);
for(int i = 1,j = n;i < j;i ++ )
{
//头尾指针元素之和大于目标值,尾指针前移
while(a[i] + a[j] > m && j > i + 1)j -- ;
//查找到了解,必定会进行输出
if(a[i] + a[j] == m)
{
cout << a[i]<< ' ' << a[j] << endl;
return 0;
}
else continue;
}
//未查找到解,则输出无解
cout << "No Solution" << endl;
return 0;
}回文平方
回文数是指数字从前往后读和从后往前读都相同的数字。
例如数字 12321 就是典型的回文数字。
现在给定你一个整数 B,请你判断 1∼300 之间的所有整数中,有哪些整数的平方转化为 B 进制后,其 B 进制表示是回文数字。
输入格式
一个整数 B。
输出格式
每行包含两个在 B 进制下表示的数字。
第一个表示满足平方值转化为 B 进制后是回文数字那个数,第二个数表示第一个数的平方。
所有满足条件的数字按从小到大顺序依次输出。
数据范围
2≤B≤20
对于大于 9 的数字,用 A 表示 10,用 B 表示 11,以此类推。
输入样例:
10
输出样例:
1 1
2 4
3 9
11 121
22 484
26 676
101 10201
111 12321
121 14641
202 40804
212 44944
264 69696源代码
//本题考察的算法为双指针算法和进制转换问题
//也就是一个2-20之间的进制转换小算法的设计,注意当取余所得数字大于9的时候要用A代替9,以此类推
//双指针算法的应用在与判断该数是否为回文数
//对于10以下的进制数不含字母,我们在判断回文数的时候能够按照数字处理
//但是对于大于10的进制数转换之后可能会含有字母位,所以根据计算量的处理和方式的简便性来看
//将某个数字的进制数转换为字符串无疑是很好的处理方法且利用头尾指针来判断是否回文
#include <iostream>
#include <algorithm>
using namespace std;
//双指针判断回文数算法
bool judge(string s)
{
//当字符串长度为偶数位时,若回文最后一次操作之后头尾指针必交叉
//当字符串长度为奇数位时,若回文最后一次操作之前头尾指针则会指向同一位置,而后操作之后交叉
int l = 0;
int r = s.size() - 1;
while(s[l] == s[r])
{
l ++ ;
r -- ;
}
//若头尾指针交叉则为回文数,或者在我们这种方法里来说,叫做回文串
if(l > r)return true;
//若二者未交叉,则证明头尾指针在相遇之前至少有一位不同
else return false;
}
//进制转换函数
string fun(int num,int n)
{
string s;
while(num > 0)
{
int t = num % n;
char c;
if(t >= 0 && t <= 9)c = t + '0';
else
{
t = t - 9;
c = 'A' + t - 1;
}
s += c;
num /= n;
}
reverse(s.begin(),s.end());
return s;
}
int main()
{
int n;
cin >> n;
for(int i = 1;i <= 300;i ++ )
{
string s;
s = fun(i * i,n);
if(judge(s))cout << fun(i,n) << ' ' << fun(i * i,n) << endl;
}
return 0;
}品种邻近
农夫约翰的 N 头奶牛排成一排,每头奶牛都用其品种 ID 进行描述。
如果两头相同品种的牛靠得太近,它们就会吵架。
具体的说,如果同一品种的两头奶牛在队列中的位置相差不超过 K,我们就称这是一对拥挤的牛。
请计算品种 ID 最大的拥挤奶牛对的品种 ID。
输入格式
第一行包含两个整数 N 和 K。
接下来 N 行,每行包含一个整数表示队列中一头奶牛的品种 ID。
输出格式
输出品种 ID 最大的拥挤奶牛对的品种 ID。
如果不存在拥挤奶牛对,则输出 −1。
数据范围
1≤N≤50000,
1≤K<N
品种 ID 范围 [0,10^6]。
输入样例:
6 3
7
3
4
2
3
4
输出样例:
4
样例解释
一对品种 ID 为 3 的奶牛以及一对品种 ID 为 4 的奶牛属于拥挤奶牛对。
所以,最大拥挤奶牛对的品种 ID 为 4。
源代码
//本题的标准解答算法滑动窗口即双端队列来处理,也就是单调队列
//但是由于我单调队列算法不太熟,我在想能不能换种思维,在不升高时间复杂度的条件下来解决本题
//由于我对于vector动态数组的使用比较得心应手,根据题意我设置了数对
//first存储出现的元素,second存储其出现时的下标
//然后利用sort进行排序,由于sort在对于PII类型进行排序时是按照first优先second其次来排的
//所以我们可以遍历排序后的动态数组若前后相同且属于拥挤条件就将其推入答案动态数组当中
//然后对于答案动态数组进行排序输出最后一位即可
//因为有特判0的存在,所以我们若是初始ans等于0而后在找寻符合条件的元素的同时不断求max的话
//就无法处理当符合条件的元素是0的情况,和答案无解输出-1会产生冲突
//也就是我们设计的算法出现了二义性,因此为了避免此种情况
//我们特制答案动态数组,并将其排序,当真正无解的时候,答案数组的大小一定为0,这样就避免了二义性
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int,int> PII;
vector<PII> A;
vector<int> B;
int main()
{
int n,k;
cin >> n >> k;
for(int i = 1;i <= n;i ++ )
{
int num;
cin >> num;
A.push_back({num,i});
}
sort(A.begin(),A.end());
for(int i = 0;i < A.size();i ++ )
{
if(A[i].first == A[i + 1].first && i + 1 < A.size() && A[i + 1].second - A[i].second <= k)B.push_back(A[i].first);
}
sort(B.begin(),B.end());
if(B.size() == 0)cout << -1 << endl;
else cout << B[B.size() - 1] << endl;
return 0;
}平方矩阵 II
输入整数 N,输出一个 N 阶的二维数组。
数组的形式参照样例。
输入格式
输入包含多行,每行包含一个整数 N。
当输入行为 N=0 时,表示输入结束,且该行无需作任何处理。
输出格式
对于每个输入整数 N,输出一个满足要求的 N 阶二维数组。
每个数组占 N 行,每行包含 N 个用空格隔开的整数。
每个数组输出完毕后,输出一个空行。
数据范围
0≤N≤100
输入样例:
1
2
3
4
5
0
输出样例:
1
1 2
2 1
1 2 3
2 1 2
3 2 1
1 2 3 4
2 1 2 3
3 2 1 2
4 3 2 1
1 2 3 4 5
2 1 2 3 4
3 2 1 2 3
4 3 2 1 2
5 4 3 2 1
源代码
//二维数组找规律题目,即以最上端和最左端为例,其元素皆为递增
//其余位置元素在赋值时,按照左上角原则与左上角元素赋值相同即可
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1000 + 10;
int a[N][N];
int main()
{
int n;
while(cin >> n,n != 0)
{
memset(a,0,sizeof(a));
//首先对于最上端和最左端赋值
for(int i = 1;i <= n;i ++ )
{
a[1][i] = i;
a[i][1] = i;
}
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= n;j ++ )
{
//跳过最上端和最左端元素
if(i == 1)continue;
if(j == 1)continue;
//复刻左上角元素的值
a[i][j] = a[i - 1][j - 1];
}
}
//输出整个矩阵
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= n;j ++ )
{
cout << a[i][j] << ' ';
}
cout << endl;
}
cout << endl;
}
}十三号星期五
十三号星期五真的很不常见吗?
每个月的十三号是星期五的频率是否比一周中的其他几天低?
请编写一个程序,计算 N 年内每个月的 13 号是星期日,星期一,星期二,星期三,星期四,星期五和星期六的频率。
测试的时间段将会开始于 1900 年 11 月 11 日,结束于 1900+N−1 年 12 月 31日。
一些有助于你解题的额外信息:
- 1900 年 1 月 1 日是星期一。
- 在一年中,4 月、6 月、9 月、11 月每个月 30 天,2 月平年 28 天,闰年 29 天,其他月份每个月31天。
- 公历年份是 4 的倍数且不是 100 的倍数的年份为闰年,例如 1992 年是闰年,1990 年不是闰年。
- 公历年份是整百数并且是 400 的倍数的也是闰年,例如1700年,1800年,1900年,2100年不是闰年,2000年是闰年。
输入格式
共一行,包含一个整数 N。
输出格式
共一行,包含七个整数,整数之间用一个空格隔开,依次表示星期六,星期日,星期一,星期二,星期三,星期四,星期五在十三号出现的次数。
数据范围
1≤N≤400
输入样例:
20
输出样例:
36 33 34 33 35 35 34//本题本意是打表,这种打表类的题容易出BUG且难以DEBUG,思路和代码需要高度一致
//但是此处我利用的是吉姆拉尔森计算公式,即W = (d + 1 + 2 * m + 3 * (m + 1) / 5 + y + y / 4 - y / 100 + y / 400) % 7
//当W为0时对应的是该天是星期日,当W为1-6时对应的该天是星期一到星期六
//由公式可得我们只需要输入某年某月某日即可自动得到答案,需要注意的是
//当月份为1时我们应将月份调至去年的13月,当月份为2时我们应将月份调至去年的14月来计算
#include <iostream>
using namespace std;
int ans[7];
//计算某年某月某日是周几的函数
int getidx(int y,int m,int d)
{
if(m == 1)
{
m = 13;
y -- ;
}
else if(m == 2)
{
m = 14;
y -- ;
}
int idx = (d + 1 + 2 * m + 3 * (m + 1) / 5 + y + y / 4 - y / 100 + y / 400) % 7;
return idx;
}
int main()
{
int n;
cin >> n;
int end = 1900 + n;
for(int year = 1900;year < end;year ++ )
{
for(int month = 1;month <= 12;month ++ )
{
int idx = getidx(year,month,13);
ans[idx] ++ ;
}
}
//注意输出的答案次序
for(int i = 6;i < 6 + 7;i ++ )cout << ans[i % 7] << ' ';
return 0;
}阶乘
N 的阶乘(记作 N!)是指从 1 到 N(包括 1 和 N)的所有整数的乘积。
阶乘运算的结果往往都非常的大。
现在,给定数字 N,请你求出 N! 的最右边的非零数字是多少。
例如 5!=1×2×3×4×5=120,所以 5! 的最右边的非零数字是 2。
输入格式
共一行,包含一个整数 N。
输出格式
输出一个整数,表示 N! 的最右边的非零数字。
数据范围
1≤N≤1000
输入样例:
7
输出样例:
4源代码
//注意数据范围,即使我们开longlong过不了n!
//那么观察题目,我们只需要求取n!的最后一位不为0的数字
//因此我们需要将末尾0去除,也就是当某个数对10取余余0的话证明其能够被10整除,以此除去末尾0
//而后为了减少处理的数据量和缩短数据长度,我们可以将答案对1000取余,因此最终的答案我们可以控制在3位
//即不会超出long long规定的数据范围,同时也减少了数据量的处理
#include <iostream>
using namespace std;
typedef long long ll;
int main()
{
ll n;
cin >> n;
ll ans = 1;
for(int i = 1;i <= n;i ++ )
{
ans = ans * i;
//对于末尾0的去除
while(ans % 10 == 0)ans /= 10;
//控制答案的位数
while(ans > 1000)ans %= 1000;
}
cout << ans % 10;
return 0;
}干草堆
贝茜对她最近在农场周围造成的一切恶作剧感到抱歉,她同意帮助农夫约翰把一批新到的干草捆堆起来。
开始时,共有 N 个空干草堆,编号 1∼N。
约翰给贝茜下达了 K 个指令,每条指令的格式为 A B,这意味着贝茜要在 A..B 范围内的每个干草堆的顶部添加一个新的干草捆。
例如,如果贝茜收到指令 10 13,则她应在干草堆 10,11,12,13 中各添加一个干草捆。
在贝茜完成了所有指令后,约翰想知道 N 个干草堆的中值高度——也就是说,如果干草堆按照高度从小到大排列,位于中间的干草堆的高度。
方便起见,N 一定是奇数,所以中间堆是唯一的。
请帮助贝茜确定约翰问题的答案。
输入格式
第一行包含 N 和 K。
接下来 K 行,每行包含两个整数 A,B,用来描述一个指令。
输出格式
输出完成所有指令后,N 个干草堆的中值高度。
数据范围
1≤N≤10^6
1≤K≤25000
1≤A≤B≤N
输入样例:
7 4
5 5
2 4
4 6
3 5
输出样例:
1
样例解释
贝茜完成所有指令后,各堆高度为 0,1,2,3,3,1,0。
将各高度从小到大排序后,得到 0,0,1,1,2,3,3,位于中间的是 1。
源代码
//这道题与昨天的货舱选址那道题有着异曲同工之妙,换汤不换药
//同样考察的为快速选择算法,选择的为中位数
//对于奇数个和偶数个元素的中位数我们选择(n + 1) / 2
//根据c ++ 向下取整的特点,此式得到的结果即为中位数的下标
//也因此知道总的元素个数,我们也就可以确定需要的是哪儿一个元素而后使用快速选择算法
//同样,为了节省数据的处理时间和减少数据量的处理
//在发现对于添加干草堆的操作是在一维的水平上对于某个区间进行处理时
//我们就可以结合差分算法,在进行差分处理之后,再自身前缀和运算进行还原为操作后的原数组
//对于原数组进行快速选择算法的运用即可快速的得到答案
#include <iostream>
using namespace std;
const int N = 1000000 + 10;
int q[N];
//快速选择算法
int quick_sort(int l,int r,int k)
{
if(l >= r)return q[l];
int x = q[l + r >> 1],i = l - 1,j = r + 1;
while(i < j)
{
do i ++ ;while(q[i] < x);
do j -- ;while(q[j] > x);
if(i < j)swap(q[i],q[j]);
}
int sl = j - l + 1;
if(k <= sl)return quick_sort(l,j,k);
else return quick_sort(j + 1,r,k - sl);
}
//差分数组函数
void insert(int l,int r,int c)
{
q[l] += c;
q[r + 1] -= c;
}
int main()
{
int n,m;
cin >> n >> m;
while(m -- )
{
int l,r;
cin >> l >> r;
insert(l,r,1);
}
//差分数组自身前缀和运算
for(int i = 1;i <= n;i ++ )q[i] += q[i - 1];
//快速选择排序后的中位数下标的元素
cout << quick_sort(1,n,(n + 1) / 2);
return 0;
}火星人
人类终于登上了火星的土地并且见到了神秘的火星人。
人类和火星人都无法理解对方的语言,但是我们的科学家发明了一种用数字交流的方法。
这种交流方法是这样的,首先,火星人把一个非常大的数字告诉人类科学家,科学家破解这个数字的含义后,再把一个很小的数字加到这个大数上面,把结果告诉火星人,作为人类的回答。
火星人用一种非常简单的方式来表示数字——掰手指。
火星人只有一只手,但这只手上有成千上万的手指,这些手指排成一列,分别编号为 1,2,3……。
火星人的任意两根手指都能随意交换位置,他们就是通过这方法计数的。
一个火星人用一个人类的手演示了如何用手指计数。
如果把五根手指——拇指、食指、中指、无名指和小指分别编号为 1,2,3,4 和 5,当它们按正常顺序排列时,形成了 5 位数 12345,当你交换无名指和小指的位置时,会形成 5 位数 12354,当你把五个手指的顺序完全颠倒时,会形成 54321,在所有能够形成的 120 个 5 位数中,12345 最小,它表示 1;12354 第二小,它表示 2;54321 最大,它表示 120。
下表展示了只有 3 根手指时能够形成的 6 个 3 位数和它们代表的数字:
三位数 123,132,213,231,312,321
代表的数字 1,2,3,4,5,6
现在你有幸成为了第一个和火星人交流的地球人。
一个火星人会让你看他的手指,科学家会告诉你要加上去的很小的数。
你的任务是,把火星人用手指表示的数与科学家告诉你的数相加,并根据相加的结果改变火星人手指的排列顺序。
输入数据保证这个结果不会超出火星人手指能表示的范围。
输入格式
输入包括三行,第一行有一个正整数 N,表示火星人手指的数目。
第二行是一个正整数 M,表示要加上去的小整数。
下一行是 1 到 N 这 N 个整数的一个排列,用空格隔开,表示火星人手指的排列顺序。
输出格式
输出只有一行,这一行含有 N 个整数,表示改变后的火星人手指的排列顺序。
每两个相邻的数中间用一个空格分开,不能有多余的空格。
数据范围
1≤N≤10000
1≤M≤100
输入样例:
5
3
1 2 3 4 5
输出样例:
1 2 4 5 3源代码
//刚开始使用DFS来全排列,虽然能够得到想要的答案,但是对于剪枝无从下手
//没办法还是使用的效率强大的next_permutation函数来得到下一个字典序
//从而快速高效的得到答案,有的时候库函数确实比无剪枝的DFS快得多
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1000000 + 10;
int a[N];
int n,m;
int main()
{
cin >> n >> m;
for(int i = 0;i < n;i ++ )cin >> a[i];
while(m -- )next_permutation(a,a + n);
for(int i = 0;i < n;i ++ )cout << a[i] << ' ';
cout << endl;
return 0;
}整数集合划分
给定一个包含 NN 个正整数的集合,请你将它划分为两个集合 A1 和 A2,其中 A1 包含 n1 个元素,A2 包含 n2 个元素。
集合中可以包含相同元素。
用 S1 表示集合 A1 内所有元素之和,S2 表示集合 A2 内所有元素之和。
请你妥善划分,使得 |n1−n2| 尽可能小,并在此基础上 |S1−S2| 尽可能大。
输入格式
第一行包含整数 N。
第二行包含 N 个正整数。
输出格式
在一行中输出 |n1−n2| 和 |S1−S2|,两数之间空格隔开。
数据范围
2≤N≤10^5
保证集合中各元素以及所有元素之和小于 231。
输入样例1:
10
23 8 10 99 46 2333 46 1 666 555
输出样例1:
0 3611
输入样例2:
13
110 79 218 69 3721 100 29 135 2 6 13 5188 85
输出样例2:
1 9359源代码
//根据集合划分的情况,大概可以分为两种,我们可以用贪心思维来想,用前缀和数组来辅助,排序算法为基础
//首先对于原数组当中的所有元素进行一个排序运算,也就是升序排序
//第一种情况为偶数个元素,那么此时A和B集合中的元素个数必定相同(为了保证|n1 - n2|尽可能小)
//同时,为了保证|S1 - S2|尽可能大,也就是两个集合当中的元素和差值尽可能大,那么区间可以分为两部分
//前半部分由升序序列前半部分[1,n / 2]来组成,后半部分[n / 2 + 1,n]由序列中的较大元素组成
//由于前缀和数组的特点,S[n] - S[n / 2]仅仅是求取的从a[n / 2 + 1]到a[n]之间的前缀和
//要取得真正的|S1 - S2|需要减去两个s[n / 2],即S[n] - S[n / 2] * 2
//那么对于奇数个元素的情况,则必定有一个集合多一个元素,为了保证|S1 - S2|尽可能大,我们将中位数下标的那个元素塞入B区间
//因此整个区间被分为[1,n / 2]和[(n + 1) / 2,n]两个区间,因此AB集合只差为s[n] - s[n / 2] * 2
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1000000 + 10;
int a[N],s[N];
int main()
{
int n;
cin >> n;
for(int i = 1;i <= n;i ++ )cin >> a[i];
sort(a + 1,a + 1 + n);
for(int i = 1;i <= n;i ++ )s[i] = s[i - 1] + a[i];
if(n&1)cout << 1 << ' ';
else cout << 0 << ' ';
cout << s[n] - s[n / 2] * 2;
return 0;
}最大的和
给定一个包含整数的二维矩阵,子矩形是位于整个阵列内的任何大小为 1×1 或更大的连续子阵列。
矩形的总和是该矩形中所有元素的总和。
在这个问题中,具有最大和的子矩形被称为最大子矩形。
例如,下列数组:
0 -2 -7 0
9 2 -6 2
-4 1 -4 1
-1 8 0 -2
其最大子矩形为:
9 2
-4 1
-1 8
它拥有最大和 15。
输入格式
输入中将包含一个 N×N 的整数数组。
第一行只输入一个整数 N,表示方形二维数组的大小。
从第二行开始,输入由空格和换行符隔开的 N2 个整数,它们即为二维数组中的 N2 个元素,输入顺序从二维数组的第一行开始向下逐行输入,同一行数据从左向右逐个输入。
数组中的数字会保持在 [−127,127] 的范围内。
输出格式
输出一个整数,代表最大子矩形的总和。
数据范围
1≤N≤100
输入样例:
4
0 -2 -7 0 9 2 -6 2
-4 1 -4 1 -1
8 0 -2
输出样例:
15源代码
//本题考察的是递推以及枚举,由于我太懒了我就没有使用这些方法
//在观察N的数据范围之后,将其转换为了一个二维前缀和问题
//也就是说,在对于子矩阵的枚举时,我们将四层枚举,外层枚举x1、y1,内层枚举x2、y2
//注意由于子矩阵的性质,x1满足严格大于等于x2,y1满足严格大于等于y2
//也就是说,我们枚举的是两个点,终点在枚举最小的情况下是和起点重合,也就是单独一个(也属于一个子矩阵)
//其次情况下。终点可以在起点的左边或者下边或者左下边,即起点终点二者有着严格的限制,以免TLE
#include <iostream>
using namespace std;
const int N = 1000 + 10;
int a[N][N],s[N][N];
int main()
{
int n;
cin >> n;
int ans = -99999999;
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= n;j ++ )
{
cin >> a[i][j];
//前缀和矩阵的构建
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j];
}
}
//进行子矩阵的枚举
//枚举起点
for(int x1 = 1;x1 <= n;x1 ++ )
{
for(int y1 = 1;y1 <= n;y1 ++ )
{
//枚举终点
for(int x2 = x1;x2 <= n;x2 ++ )
{
for(int y2 = y1;y2 <= n;y2 ++ )
{
//求取最大值
ans = max(ans,s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1]);
}
}
}
}
cout << ans << endl;
return 0;
}剪绳子
有 N 根绳子,第 i 根绳子长度为 Li,现在需要 M 根等长的绳子,你可以对 N 根绳子进行任意裁剪(不能拼接),请你帮忙计算出这 M 根绳子最长的长度是多少。
输入格式
第一行包含 2 个正整数 N、M,表示原始绳子的数量和需求绳子的数量。
第二行包含 N 个整数,其中第 i 个整数 Li 表示第 i 根绳子的长度。
输出格式
输出一个数字,表示裁剪后最长的长度,保留两位小数。
数据范围
1≤N,M≤100000
0<Li<10^9
输入样例:
3 4
3 5 4
输出样例:
2.50
样例解释
第一根和第三根分别裁剪出一根 2.50 长度的绳子,第二根剪成 2 根 2.50 长度的绳子,刚好 4 根。
源代码
//库函数iomanip保证输出答案的精度以及位数限制
//本题考察的是经典浮点二分法,对于给定的m条绳子,我们可以不断进行二分求取答案来确定最终的l
//在二分之某个值的时候,我们可以进行检查,即假设二分此值的话,我们能够分得的绳子条数是否大于等于m
//若是大于等于m的话,证明绳子有盈余,可以试着在区间右侧再找值,反之,若小于m的话,则绳子缺少,转向左区间查找
//利用自定义的check函数来判断并不断的缩小区间,直至搜寻至答案
//注意浮点二分的while内部精度往往是取1e-(2 + 保留小数位数),当然取大点也行
//在使用c ++ 进行输出的时候注意l要在setiosflags(ios::fixed)和setprecision(2)之前,否则函数库无法起到作用
#include <iostream>
#include <iomanip>
using namespace std;
const int N = 1000000 + 10;
int a[N],n,m;
//判断某点是否满足条件,并以此调整区间
bool check(double mid)
{
int num = 0;
for(int i = 1;i <= n;i ++ )num += a[i] / mid;
if(num >= m)return true;
else return false;
}
int main()
{
cin >> n >> m;
for(int i = 1;i <= n;i ++ )cin >> a[i];
double l = 0,r = 1e9;//设定左右界
while(r - l > 1e-4)//注意精度限制
{
double mid = (l + r) / 2;
if(check(mid))l = mid;//如果有盈余,查右区间
else r = mid;//有缺欠,查左区间
}
//iomanip库函数对于输出数据进行格式限定
cout << setiosflags(ios::fixed) << setprecision(2) << l << endl;
return 0;
}分巧克力
儿童节那天有 K 位小朋友到小明家做客。
小明拿出了珍藏的巧克力招待小朋友们。
小明一共有 N 块巧克力,其中第 ii 块是 Hi×Wi 的方格组成的长方形。
为了公平起见,小明需要从这 N 块巧克力中切出 K 块巧克力分给小朋友们。
切出的巧克力需要满足:
- 形状是正方形,边长是整数
- 大小相同
例如一块 6×5 的巧克力可以切出 6 块 2×2 的巧克力或者 2 块 3×3 的巧克力。
当然小朋友们都希望得到的巧克力尽可能大,你能帮小明计算出最大的边长是多少么?
输入格式
第一行包含两个整数 N 和 K。
以下 N 行每行包含两个整数 Hi 和 Wi。
输入保证每位小朋友至少能获得一块 1×1 的巧克力。
输出格式
输出切出的正方形巧克力最大可能的边长。
数据范围
1≤N,K≤10^5
1≤Hi,Wi≤10^5
输入样例:
2 10
6 5
5 6
输出样例:
2源代码
//此题目考察的整数二分法,与剪绳子有着异曲同工之处,剪绳子是一个变量,分巧克力是两个变量
//对于能够分的块数,我们与剪绳子的处理方法相同,若块数大于等于k则是有盈余,查右区间,反之缺少查左区间
//在累计巧克力块数的时候,我们可以发现规律,截取边长为mid的巧克力的话,块数等于(长 / mid) * (宽 / mid)
//借此我们可以设置check函数,对于具有长和宽的巧克力来说,我们可以为之设置一个结构体类型来存储和使用
#include <iostream>
#include <iomanip>
using namespace std;
const int N = 1000000 + 10;
int n,k;
struct Chocolate
{
int x;
int y;
};
Chocolate A[N];
bool check(int x)
{
int num = 0;
for(int i = 1;i <= n;i ++ )num += (A[i].x / x) * (A[i].y / x);
if(num >= k)return true;
else return false;
}
int main()
{
cin >> n >> k;
for(int i = 1;i <= n;i ++ )cin >> A[i].x >> A[i].y;
int l = 0,r = 1e6;
while(l < r)
{
int mid = l + r + 1>> 1;//注意加一防止死循环
if(check(mid))l = mid;
else r = mid - 1;
}
cout << setiosflags(ios::fixed) << setprecision(2) << l << endl;
return 0;
}a^b
求 a 的 b 次方对 p 取模的值。
输入格式
三个整数 a,b,p ,在同一行用空格隔开。
输出格式
输出一个整数,表示a^b mod p的值。
数据范围
0≤a,b≤10^9
1≤p≤10^9
输入样例:
3 2 7
输出样例:
2源代码
//本题考察的为快速幂算法,也是一个快速幂算法的模板
//对于快速幂算法,简单解释来说就是对于幂次进行不断的除2运算,从而降低运算量
//当幂次为奇数时,我们需要将他变为偶数次幂,也就意味这,我们的答案要乘一个底数来将其幂次减一
//当幂次为偶数时且幂次大于0时,我们不断的将幂次除二运算,同时也将底数平方运算同时注意对p取模放置溢出
//当幂次由2降至1时就会发现ans会乘以最后的底数,也就是最终的答案,而后幂次降为0跳出循环
//注意ans在累乘和底数a进行自增的同时要对p取模注意数据范围
#include <iostream>
using namespace std;
typedef long long ll;
ll fast(ll a,ll b,ll p)
{
//当幂次为0时,任何书的0次幂都是1,返回1%p即可
if(b == 0)return 1%p;
ll ans = 1;
while(b > 0)
{
if(b&1)ans = ans * a % p;
b >>= 1;
a = (a * a) % p;
}
return ans;
}
int main()
{
ll a,b,p;
cin >> a >> b >> p;
cout << fast(a,b,p);
return 0;
}数独检查
数独是一种流行的单人游戏。
目标是用数字填充 9×9 矩阵,使每列,每行和所有 9 个非重叠的 3×3 子矩阵包含从 1 到 9 的所有数字。
每个 9×9 矩阵在游戏开始时都会有部分数字已经给出,通常有一个独特的解决方案。


给定完成的 N^2×N^2 数独矩阵,你的任务是确定它是否是有效的解决方案。
有效的解决方案必须满足以下条件:
- 每行包含从 1 到 N^2 的每个数字,每个数字一次。
- 每列包含从 1 到 N^2 的每个数字,每个数字一次。
- 将 N^2×N^2 矩阵划分为 N^2 个非重叠 N×N 子矩阵。 每个子矩阵包含从 1 到 N^2 的每个数字,每个数字一次。
你无需担心问题的唯一性,只需检查给定矩阵是否是有效的解决方案即可。
输入格式
第一行包含整数 T,表示共有 T 组测试数据。
每组数据第一行包含整数 N。
接下来 N^2 行,每行包含 N^2 个数字(均不超过 1000),用来描述完整的数独矩阵。
输出格式
每组数据输出一个结果,每个结果占一行。
结果表示为 Case #x: y,其中 x 是组别编号(从 1 开始),如果给定矩阵是有效方案则 y 是 Yes,否则 y 是 No。
数据范围
1≤T≤100
3≤N≤6
输入样例:
3
3
5 3 4 6 7 8 9 1 2
6 7 2 1 9 5 3 4 8
1 9 8 3 4 2 5 6 7
8 5 9 7 6 1 4 2 3
4 2 6 8 5 3 7 9 1
7 1 3 9 2 4 8 5 6
9 6 1 5 3 7 2 8 4
2 8 7 4 1 9 6 3 5
3 4 5 2 8 6 1 7 9
3
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
1 2 3 4 5 6 7 8 9
3
5 3 4 6 7 8 9 1 2
6 7 2 1 9 5 3 4 8
1 9 8 3 4 2 5 6 7
8 5 9 7 6 1 4 2 3
4 2 6 8 999 3 7 9 1
7 1 3 9 2 4 8 5 6
9 6 1 5 3 7 2 8 4
2 8 7 4 1 9 6 3 5
3 4 5 2 8 6 1 7 9
输出样例:
Case #1: Yes
Case #2: No
Case #3: No源代码
//本题为模拟题,也就是在二维矩阵当中对于组成其的小矩阵进行逐个遍历
//刚开始错的几次是因为没看清题给的条件,注意满足数独矩阵的条件有三条
//第一条:每行的数据组成由1-n*n且无重复
//第二条:每列的数据组成由1-n*n且无重复
//第三条:每个子矩阵的数据组成由1-n*n且无重复
//注意三个条件同时满足才为数独矩阵,反之则不为
//对于数独矩阵的检查我没有使用布尔数组而是使用了哈希表进行处理
//因为unordered_set有自动去重功能,因此我们只需要规定哪儿些数字能够插入其中,并对最后该容器的大小进行检查即可完成对于矩阵的检查
//后来又Wa了一次因为容器忘记清空了
//注释的内容为子矩阵的枚举,去掉注释内容即可查看每个样例的详细输出
//对于子矩阵的枚举,我们采用四重循环的方式进行,内两层循环以偏移量循环的方式给出,范围为0-(n - 1)
//从提交记录来看使用哈希表(100ms)检验的方式比使用布尔数组(11ms)大概慢了10倍左右,所以还是推荐使用布尔数组进行检验
#include <iostream>
#include <unordered_set>
#include <cstring>
using namespace std;
const int N = 1000 + 10;
int a[N][N];//存储待检查的数独矩阵
unordered_set<int> A;//用于检查子矩阵的容器
unordered_set<int> B;//用于检查行的容器
unordered_set<int> C;//用于检查列的容器
int main()
{
int t;
cin >> t;
//我们用for循环来使每次的输出样例次序得以保证
for(int idx = 1;idx <= t;idx ++ )
{
int flag = 1;//置标志flag来判断是否为数独矩阵
memset(a,0,sizeof(a));//重设数独矩阵
int n;
cin >> n;
//读入数独矩阵
for(int i = 1;i <= n * n;i ++ )
{
for(int j = 1;j <= n * n;j ++ )
{
cin >> a[i][j];
}
}
//进行每行是否满足条件的检查,检查前先清空B容器
B.clear();
for(int i = 1;i <= n * n;i ++ )
{
for(int j = 1;j <= n * n;j ++ )
{
if(a[i][j] >= 1 && a[i][j] <= n * n)B.insert(a[i][j]);//符合条件则插入
}
//若元素个数不满足条件则置flag = 0,跳出循环
if(B.size() != n * n)
{
flag = 0;
break;
}
}
//进行每列是否满足条件的检查,检查前先清空C容器
C.clear();
for(int j = 1;j <= n * n;j ++ )
{
for(int i = 1;i <= n * n;i ++ )
{
if(a[i][j] >= 1 && a[i][j] <= n * n)C.insert(a[i][j]);//符合条件则插入
}
//若元素个数不满足条件则置flag = 0,跳出循环
if(C.size() != n * n)
{
flag = 0;
break;
}
}
//进行子矩阵的检查
for(int i = 1;i <= n * n;i += n)
{
if(flag == 0)break;//若前两次flag已为0则直接跳出和内层flag为0时跳出循环
for(int j = 1;j <= n * n;j += n)
{
//首先对于A容器进行清空
A.clear();
for(int x = 0;x < n;x ++ )
{
for(int y = 0;y < n;y ++ )
{
if(a[i + x][j + y] >= 1 && a[i + x][j + y] <= n * n)A.insert(a[i + x][j + y]);//满足条件则插入
// cout << a[i + x][j + y] << ' ';
}
// cout << endl;
}
// for(auto i : A)cout << i << ' ';
// cout << endl << endl;
if(A.size() != n * n)
{
flag = 0;
break;
}
}
}
//根据flag进行输出
if(flag == 1)cout << "Case #" << idx << ": Yes" << endl;
else if(flag == 0)cout << "Case #" << idx << ": No" << endl;
// cout << "---------------------" << endl;
}
}ISBN号码
每一本正式出版的图书都有一个 ISBN 号码与之对应。
ISBN 码包括 9 位数字、1 位识别码和 3 位分隔符,其规定格式如 x-xxx-xxxxx-x,其中符号 - 是分隔符(键盘上的减号),最后一位是识别码,例如 0-670-82162-4 就是一个标准的ISBN码。
ISBN 码的首位数字表示书籍的出版语言,例如 0 代表英语;第一个分隔符 - 之后的三位数字代表出版社,例如 670 代表维京出版社;第二个分隔之后的五位数字代表该书在出版社的编号;最后一位为识别码。
识别码的计算方法如下:
首位数字乘以 1 加上次位数字乘以 2……以此类推,用所得的结果 mod11,所得的余数即为识别码,如果余数为 10,则识别码为大写字母 X。
例如 ISBN 号码 0-670-82162-4 中的识别码 44 是这样得到的:对 067082162 这 9 个数字,从左至右,分别乘以 1,2,…,9,再求和,即 0×1+6×2+……+2×9=158,然后取 158mod11 的结果 4 作为识别码。
编写程序判断输入的 ISBN 号码中识别码是否正确,如果正确,则仅输出 Right;如果错误,则输出是正确的 ISBN 号码。
输入格式
输入只有一行,是一个字符序列,表示一本书的 ISBN 号码(保证输入符合 ISBN 号码的格式要求)。
输出格式
输出一行,假如输入的 ISBN 号码的识别码正确,那么输出 Right,否则,按照规定的格式,输出正确的 ISBN 号码(包括分隔符 -)。
输入样例1:
0-670-82162-4
输出样例1:
Right
输入样例2:
0-670-82162-0
输出样例2:
0-670-82162-4源代码
//本题为字符串处理的模拟问题,也就是字符串最后一位是检验位检验的问题
//非检验为有着属于自己的权重,求和之后对某个数取模得到检验位,若取模得到的与所给的不一致
//则更正并输出真正的编码,若正确则输出Right
//注意对于检验位的特判,即检验位为10的时候相当于X
//当求得的检验位为10,所给的检验位不为X则错误
//且若检验位错误,编码在更正之后的最后一位检验位不能够是10,若是10的话应替换为X
#include <iostream>
#include <vector>
using namespace std;
const int N = 1000000 + 10;
vector<int> A;
int main()
{
string s;
cin >> s;
//读取非检验位
for(int i = 0;i < s.size() - 1;i ++ )
{
if(s[i] >= '0' && s[i] <= '9')A.push_back(s[i] - '0');
}
int flag = 0;
//累加各位的非检验位与其权重的乘积
for(int i = 0;i < A.size();i ++ )flag += A[i] * (i + 1);
//计算检验位
flag %= 11;
if(flag == (s[s.size() - 1] - '0')||flag == 10 && s[s.size() - 1] == 'X')cout << "Right" << endl;
else
{
for(int i = 0;i < s.size() - 1;i ++ )cout << s[i];
if(flag == 10)cout << 'X' << endl;
else cout << flag % 11 << endl;
}
return 0;
}COW
奶牛贝茜在她最喜欢的牧场中发现了一块石碑,上面刻有神秘的碑文。
碑文的文字似乎来自一种神秘的古代语言,可看作一个只包含 C,O,W 三种字符的字符串。
尽管贝茜无法解密该文字,但是她很欣赏 C,O,W 按顺序构成她最喜欢的单词 COW。
她想知道 COW 在碑文中一共出现了多少次。
她不介意 C,O,W 之间是否存在其他字符,只要这三个字符按正确的顺序出现即可。
她也不介意多个不同的 COW 是否共享了一些字符。
例如,COW 在 CWOW 中只出现一次,在 CCOW 中出现两次,在 CCOOWW 中出现八次。
给定碑文中的文字,请帮助贝茜计算 COW 出现的次数。
输入格式
第一行包含 N。
第二行包含一个长度为 N 的字符串,其中只包含字符 C,O,W。
输出格式
输出给定字符串中 COW 作为子序列(不一定连续)的出现次数。
数据范围
1≤N≤10^5
输入样例:
6
COOWWW
输出样例:
6源代码
//不管中间条件如何,我们只计算合法的数据,也就是a、b、c分别计算合法C、CO、COW的个数
//在这块我们选择读入字符串,n可以进行忽略不计,输入无用即可,遍历字符串找寻合法数据
//注意合法C、CO、COW的计算方式,最后输出COW的个数即可,数据要开大
#include <iostream>
using namespace std;
typedef long long ll;
int main()
{
int n;
cin >> n;
string s;
cin >> s;
ll a = 0,b = 0,c = 0;
for(int i = 0;i < s.size();i ++ )
{
if(s[i] == 'C')a ++ ;
else if(s[i] == 'O')b += a;
else if(s[i] == 'W')c += b;
}
cout << c << endl;
return 0;
}红与黑
有一间长方形的房子,地上铺了红色、黑色两种颜色的正方形瓷砖。
你站在其中一块黑色的瓷砖上,只能向相邻(上下左右四个方向)的黑色瓷砖移动。
请写一个程序,计算你总共能够到达多少块黑色的瓷砖。
输入格式
输入包括多个数据集合。
每个数据集合的第一行是两个整数 W 和 H,分别表示 x 方向和 y 方向瓷砖的数量。
在接下来的 H 行中,每行包括 W 个字符。每个字符表示一块瓷砖的颜色,规则如下
1)‘.’:黑色的瓷砖;
2)‘#’:红色的瓷砖;
3)‘@’:黑色的瓷砖,并且你站在这块瓷砖上。该字符在每个数据集合中唯一出现一次。
当在一行中读入的是两个零时,表示输入结束。
输出格式
对每个数据集合,分别输出一行,显示你从初始位置出发能到达的瓷砖数(记数时包括初始位置的瓷砖)。
数据范围
1≤W,H≤20
输入样例:
6 9
....#.
.....#
......
......
......
......
......
#@...#
.#..#.
0 0
输出样例:
45源代码
//本题考察的算法为DFS中的FLOODFILL算法,即洪水灌溉算法
//根据此题目的特点,布尔数组只用来打标记,不用于恢复,也就是说此DFS无回溯
//本着只要能走就一直走的原则,将所有的未标记的、属于区间内的、是'.'的元素格子遍历完毕并计数
//洪水灌溉法则无结束标志,即不能走了就不走了,不用手动结束
//本题为多实例输入输出,要使用cstring库当中的函数进行memset数组初始化即可
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1000 + 10;
char map[N][N];
bool vis[N][N];
//设置偏移量数组
int dx[4] = {-1,0,1,0};
int dy[4] = {0,-1,0,1};
int n,m,ans = 0,sx = 0,sy = 0;
void dfs(int x,int y)
{
ans ++ ;
for(int i = 0;i < 4;i ++ )
{
int X = x + dx[i];
int Y = y + dy[i];
if(X >= 1 && X <= n && Y >= 1 && Y <= m && !vis[X][Y] && map[X][Y] == '.' && map[X][Y] != '#')
{
vis[X][Y] = true;
dfs(X,Y);
}
}
}
int main()
{
while(cin >> m >> n)
{
if(m == 0 && n == 0)break;
//面对每次的输入重置数组元素
memset(vis,false,sizeof(vis));
memset(map,'.',sizeof(map));
ans = 0;
sx = 0;
sy = 0;
//对于图进行输入
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= m;j ++ )
{
cin >> map[i][j];
//记录起点位置
if(map[i][j] == '@')
{
sx = i;
sy = j;
}
}
}
dfs(sx,sy);
cout << ans << endl;
}
return 0;
}棋盘挑战
给定一个 N×N 的棋盘,请你在上面放置 N 个棋子,要求满足:
- 每行每列都恰好有一个棋子
- 每条对角线上都最多只能有一个棋子
1 2 3 4 5 6
-------------------------
1 | | O | | | | |
-------------------------
2 | | | | O | | |
-------------------------
3 | | | | | | O |
-------------------------
4 | O | | | | | |
-------------------------
5 | | | O | | | |
-------------------------
6 | | | | | O | |
-------------------------
上图给出了当 N=6 时的一种解决方案,该方案可用序列 2 4 6 1 3 5 来描述,该序列按顺序给出了从第一行到第六行,每一行摆放的棋子所在的列的位置。
请你编写一个程序,给定一个 N×N 的棋盘以及 N 个棋子,请你找出所有满足上述条件的棋子放置方案。
输入格式
共一行,一个整数 N。
输出格式
共四行,前三行每行输出一个整数序列,用来描述一种可行放置方案,序列中的第 i 个数表示第 i 行的棋子应该摆放的列的位置。
这三行描述的方案应该是整数序列字典序排在第一、第二、第三的方案。
第四行输出一个整数,表示可行放置方案的总数。
数据范围
6≤N≤13
输入样例:
6
输出样例:
2 4 6 1 3 5
3 6 2 5 1 4
4 1 5 2 6 3
4
源代码
//此题考察的是DFS的n皇后问题变式,与n皇后问题不同的是存储答案的方式不同,且只输出前三种,接着输出答案总数
//皇后放置的位置下标从1-n来计算,因此我们需要一个path数组来记录每行皇后所放置的下标
//为了优化算法节约运算时间,我们采用逐列遍历的方式,也因此可以得到满足题目要求的升序答案格式
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1000 + 10;
char map[N][N];
bool col[N],dg[N],udg[N];
int n,path[N],ans = 0;
void dfs(int u)
{
if(u == n)
{
ans ++ ;//答案累加
if(ans <= 3)//前三种输出
{
for(int i = 0;i < n;i ++ )cout << path[i] << ' ';
cout << endl;
}
return;
}
for(int i = 0;i < n;i ++ )
{
if(!col[i] && !dg[u + i] && !udg[n - u + i])
{
path[u] = i + 1;//记录皇后放置的横坐标
col[i] = dg[u + i] = udg[n - u + i] = true;//标记
dfs(u + 1);
col[i] = dg[u + i] = udg[n - u + i] = false;//恢复
}
}
}
int main()
{
cin >> n;
dfs(0);
cout << ans << endl;
return 0;
}不高兴的津津
津津上初中了。
妈妈认为津津应该更加用功学习,所以津津除了上学之外,还要参加妈妈为她报名的各科复习班。
另外每周妈妈还会送她去学习朗诵、舞蹈和钢琴。
但是津津如果一天上课超过八个小时就会不高兴,而且上得越久就会越不高兴。
假设津津不会因为其它事不高兴,并且她的不高兴不会持续到第二天。
请你帮忙检查一下津津下周的日程安排,看看下周她会不会不高兴;如果会的话,哪天最不高兴。
输入格式
输入文件包括七行数据,分别表示周一到周日的日程安排。
每行包括两个小于 10 的非负整数,用空格隔开,分别表示津津在学校上课的时间和妈妈安排她上课的时间。
输出格式
输出文件包括一行,这一行只包含一个数字。
如果不会不高兴则输出 0,如果会则输出最不高兴的是周几(用 1, 2, 3, 4, 5, 6, 7 分别表示周一,周二,周三,周四,周五,周六,周日)。
如果有两天或两天以上不高兴的程度相当,则输出时间最靠前的一天。
输入样例:
5 3
6 2
7 2
5 3
5 4
0 4
0 6
输出样例:
3源代码
//本题考察的使用数组进行情况模拟
//数据量很小仅仅有七组数据,在这里我们使用数对类型开一个动态数组进行存储
//first为该天上课的总时长,second为该天是周几
//利用cmp函数对于该动态数组进行排序,本着first(上课总时长)优先降序排列,second(周几)其次升序排序
//这样对于我们最终得到的动态数组的头first就是最大的上课总时长,second就是最大总时长当中最小的周天数
//若最大总时长大于8则津津不开心,输出周天数,反之则无解输出0
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 1000000 + 10;
typedef pair<int,int> PII;
vector<PII> A;
//重定义sort函数的排序方式
int cmp(const PII &A,const PII &B)
{
if(A.first != B.first)return A.first > B.first;
else return A.second < B.second;
}
int main()
{
for(int i = 1;i <= 7;i ++ )
{
int a,b;
cin >> a >> b;
A.push_back({a + b,i});
}
sort(A.begin(),A.end(),cmp);
if(A[0].first > 8)cout << A[0].second << endl;
else cout << 0 << endl;
return 0;
}马蹄铁
尽管奶牛贝茜发现每个平衡括号字符串都很美观,但她特别喜欢被她称为“完全”平衡的括号字符串----一个由 ( 构成的字符串后接一个长度相同的 ) 构成的字符串。
例如:
(((())))
有一天,当贝茜穿过牛棚时,她发现地面上有一个 N×N 的马蹄铁矩阵。每个马蹄铁的方向都看上去像 ( 或 )。
从矩阵的左上角开始,贝茜希望四处走动以拾起马蹄铁,使得她捡起的马蹄铁按顺序构成的括号字符串是完全平衡的。
请计算她能得到的最长完全平衡括号字符串的长度。
每一步中,贝茜可以沿上下左右四个方向移动。
她只能移动到包含马蹄铁的方格区域内,当她进入该区域时就会拿起那里的马蹄铁,并无法再次回到该位置(因为该位置没有马蹄铁了)。
她首先拿起的是左上角的马蹄铁。
由于她拿起的马蹄铁要形成一个完全平衡的字符串,因此她可能无法将所有马蹄铁都拿起来。
输入格式
第一行包含整数 N。
接下来 N 行,每行包含一个长度为 N 的括号字符串,用来表示括号矩阵。
输出格式
输出她能得到的最长完全平衡括号字符串的长度。
如果无法得到完全平衡括号字符串(例如,左上角马蹄铁形如 )),则输出 0。
数据范围
2≤N≤5
输入样例:
4
(())
()((
(()(
))))
输出样例:
8
样例解释
贝茜的移动步骤如下:
1())
2)((
345(
876)源代码
//此题考察的算法是DFS,并给定了起点也就是左马蹄铁
//当我们求取的是最长的左右对称的字符串,注意特判当起点为右马蹄铁时无解
//根据拾取马蹄铁我们可以找到一些规律,比如(之后可以)也可以(,但是)之后只能跟)不可以(
//因此我们得到了能够深层搜索的条件,即除)下一个不可以是(之外,其余情况都可以深搜
//那么回归的条件我们也可以得到,即左半边个数等于右半边个数的时候能够回归
#include <iostream>
using namespace std;
const int N = 1000 + 10;
char map[N][N];
bool vis[N][N];
//偏移量数组
int dx[4] = {-1,0,1,0};
int dy[4] = {0,-1,0,1};
int n,ans = 0;
void dfs(int x,int y,int l,int r)
{
vis[x][y] = true;//深搜之后的第一件事就是打标记
if(l == r)
{
ans = max(ans,l + r);
vis[x][y] = false;//有解的话求取最大值之后也要恢复标记
return;
}
for(int i = 0;i < 4;i ++ )
{
int X = x + dx[i];
int Y = y + dy[i];
if(X >= 1 && X <= n && Y >= 1 && Y <= n && !vis[X][Y])
{
if(!(map[x][y] == ')' && map[X][Y] == '('))
{
if(map[X][Y] == '(')dfs(X,Y,l + 1,r);//下一步拾取左蹄铁
else if(map[X][Y] == ')')dfs(X,Y,l,r + 1);//下一步拾取右蹄铁
}
}
}
vis[x][y] = false;//恢复标记
}
int main()
{
cin >> n;
//输入图
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= n;j ++ )
{
cin >> map[i][j];
}
}
//无解特判
if(map[1][1] == ')')cout << 0 << endl;
//有解深搜,输出答案
else if(map[1][1] == '(')
{
dfs(1,1,1,0);
cout << ans << endl;
}
return 0;
}跳一跳
近来,跳一跳这款小游戏风靡全国,受到不少玩家的喜爱。
简化后的跳一跳规则如下:玩家每次从当前方块跳到下一个方块,如果没有跳到下一个方块上则游戏结束。
如果跳到了方块上,但没有跳到方块的中心则获得 1 分;跳到方块中心时,若上一次的得分为 1 分或这是本局游戏的第一次跳跃则此次得分为 2 分,否则此次得分比上一次得分多两分(即连续跳到方块中心时,总得分将 +2,+4,+6,+8…)。
现在给出一个人跳一跳的全过程,请你求出他本局游戏的得分(按照题目描述的规则)。
输入格式
输入包含多个数字,用空格分隔,每个数字都是 1,2,0 之一,1 表示此次跳跃跳到了方块上但是没有跳到中心,2 表示此次跳跃跳到了方块上并且跳到了方块中心,0 表示此次跳跃没有跳到方块上(此时游戏结束)。
输出格式
输出一个整数,为本局游戏的得分(在本题的规则下)。
数据范围
对于所有评测用例,输入的数字不超过 30 个,保证 0 正好出现一次且为最后一个数字。
输入样例:
1 1 2 2 2 1 1 2 2 0
输出样例:
22源代码
//本题为数组模拟,ans数组储存的为每次的得分,根据题意设置得分规则,最后遍历ans数组进行累加即可
#include <iostream>
using namespace std;
const int N = 1000000 + 10;
int ans[N],res = 0;
int main()
{
//初始化idx即ans数组的下标
int idx = 0;
int n;
//随着每次循环的进行,ans数组下标后移
while(cin >> n,n != 0)
{
//当此次跳跃为本次第一次跳跃且跳至方块中心或者之前跳跃在了方格上,则本次得分为2
if((idx == 0 && n == 2)||(ans[idx - 1] == 1 && n == 2))ans[idx] = 2;
//若此次跳跃在了方格上,则得分为一
else if(n == 1)ans[idx] = 1;
//其余情况得分按照每次2的公差来累加
else ans[idx] = ans[idx - 1] + 2;
idx ++ ;
}
//遍历ans数组计算总的得分
for(int i = 0;i < idx;i ++ )res += ans[i];
cout << res << endl;
return 0;
}折点计数
给定 n 个整数表示一个商店连续 n 天的销售量。
如果某天之前销售量在增长,而后一天销售量减少,则称这一天为折点,反过来如果之前销售量减少而后一天销售量增长,也称这一天为折点。
其他的天都不是折点。
如下图中,第 3 天和第 6 天是折点。

给定 n 个整数 a1,a2,…,an 表示销售量,请计算出这些天总共有多少个折点。
为了减少歧义,我们给定的数据保证:在这 n 天中相邻两天的销售量总是不同的,即 ai−1≠a。
注意,如果两天不相邻,销售量可能相同。
输入格式
输入的第一行包含一个整数 n。
第二行包含 n 个整数,用空格分隔,分别表示 a1,a2,…,an。
输出格式
输出一个整数,表示折点出现的数量。
数据范围
所有评测用例满足:1≤n≤1000,每天的销售量是不超过 10000 的非负整数。
输入样例:
7
5 4 1 2 3 6 4
输出样例:
2
源代码
//本题目考察的是枚举,说白了也就是简单题而已
//数据量不大,直接对数组进行枚举即可,结合数学的知识
//凡是满足“折点”的条件都计入答案,注意由于“折点”的特点,前后必须有数
//因此在遍历第一个元素和最后一个元素的时候直接跳过无需判断即可
#include <iostream>
using namespace std;
const int N = 1000000 + 10;
int a[N],ans = 0;
int main()
{
int n;
cin >> n;
for(int i = 1;i <= n;i ++ )cin >> a[i];
for(int i = 1;i <= n;i ++ )
{
if(i == 1 || i == n)continue;//直接跳过
if((a[i - 1] < a[i] && a[i] > a[i + 1])||(a[i - 1] > a[i] && a[i] < a[i + 1]))ans ++ ;
}
cout << ans << endl;
return 0;
}最大波动
小明正在利用股票的波动程度来研究股票。
小明拿到了一只股票每天收盘时的价格,他想知道,这只股票连续几天的最大波动值是多少,即在这几天中某天收盘价格与前一天收盘价格之差的绝对值最大是多少。
输入格式
输入的第一行包含了一个整数 n,表示小明拿到的收盘价格的连续天数。
第二行包含 n 个正整数,依次表示每天的收盘价格。
输出格式
输出一个整数,表示这只股票这 n 天中的最大波动值。
数据范围
对于所有评测用例,2≤n≤1000。
股票每一天的价格为 1 到 10000 之间的整数。
输入样例:
6
2 5 5 7 3 5
输出样例:
4
样例解释
第四天和第五天之间的波动最大,波动值为 |3−7|=4。
源代码
//简单的数组枚举题,注意进行枚举的时候,第一个元素不进行枚举
//因第一个元素之前没有元素,所以其不需要进行最大波动值的计算
//在最大波动值计算的过程之中可以使用max和abs函数进行嵌套从而求取
#include <iostream>
using namespace std;
const int N = 1000000 + 10;
int a[N],ans = 0;
int main()
{
int n;
cin >> n;
for(int i = 1;i <= n;i ++ )
{
cin >> a[i];
if(i != 1)ans = max(ans,abs(a[i] - a[i - 1]));
}
cout << ans << endl;
return 0;
}
画图
在一个定义了直角坐标系的纸上,画一个 (x1,y1) 到 (x2,y2) 的矩形指将横坐标范围从 x1 到 x2,纵坐标范围从 y1 到 y2 之间的区域涂上颜色。
下图给出了一个画了两个矩形的例子。
第一个矩形是 (1,1) 到 (4,4),用绿色和紫色表示。
第二个矩形是 (2,3) 到 (6,5),用蓝色和紫色表示。
图中,一共有 15 个单位的面积被涂上颜色,其中紫色部分被涂了两次,但在计算面积时只计算一次。
在实际的涂色过程中,所有的矩形都涂成统一的颜色,图中显示不同颜色仅为说明方便。
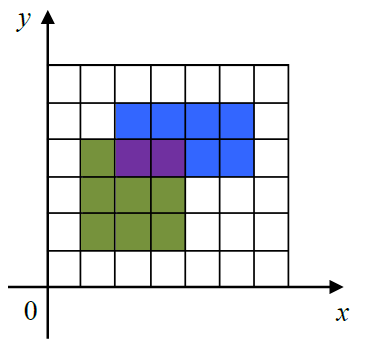
给出所有要画的矩形,请问总共有多少个单位的面积被涂上颜色。
输入格式
输入的第一行包含一个整数 n,表示要画的矩形的个数。
接下来 n 行,每行 4 个非负整数,分别表示要画的矩形的左下角的横坐标与纵坐标,以及右上角的横坐标与纵坐标。
输出格式
输出一个整数,表示有多少个单位的面积被涂上颜色。
数据范围
1≤n≤100,
0≤ 横坐标、纵坐标 ≤100
输入样例:
2
1 1 4 4
2 3 6 5
输出样例:
15源代码
//本题考察的算法为二维差分矩阵和二维前缀和矩阵
//首先用差分矩阵将涂色的矩阵模块置位非0,而后在前缀和的过程之中检查非零模块即可
//注意差分矩阵的下标是从1开始的。而题目中所给的样例是从0开始的,所以我们要对起始点的坐标进行小小的变动
#include <iostream>
using namespace std;
const int N = 1000 + 10;
int b[N][N];
void insert(int x1,int y1,int x2,int y2,int c)
{
b[x1][y1] += c;
b[x2 + 1][y1] -= c;
b[x1][y2 + 1] -= c;
b[x2 + 1][y2 + 1] += c;
}
int main()
{
int m,ans = 0;
cin >> m;
while(m -- )
{
int x1,y1,x2,y2;
cin >> x1 >> y1 >> x2 >> y2;
insert(x1 + 1,y1 + 1,x2,y2,1);
}
for(int i = 1;i <= 110;i ++ )
{
for(int j = 1;j <= 110;j ++ )
{
b[i][j] += b[i - 1][j] + b[i][j - 1] - b[i - 1][j - 1];
if(b[i][j] != 0)ans ++ ;
}
}
cout << ans << endl;
return 0;
}Z字形扫描
在图像编码的算法中,需要将一个给定的方形矩阵进行 Z 字形扫描(Zigzag Scan)。
给定一个 n×n 的矩阵,Z 字形扫描的过程如下图所示:
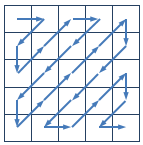
对于下面的 4×4 的矩阵,
1 5 3 9
3 7 5 6
9 4 6 4
7 3 1 3
对其进行 Z 字形扫描后得到长度为 16 的序列:1 5 3 9 7 3 9 5 4 7 3 6 6 4 1 3。
请实现一个 Z 字形扫描的程序,给定一个 n×n 的矩阵,输出对这个矩阵进行 Z 字形扫描的结果。
输入格式
输入的第一行包含一个整数 n,表示矩阵的大小。
输入的第二行到第 n+1 行每行包含 n 个正整数,由空格分隔,表示给定的矩阵。
输出格式
输出一行,包含 n×n个整数,由空格分隔,表示输入的矩阵经过 Z 字形扫描后的结果。
数据范围
1≤n≤500,
矩阵元素为不超过 1000 的正整数。
输入样例:
4
1 5 3 9
3 7 5 6
9 4 6 4
7 3 1 3
输出样例:
1 5 3 9 7 3 9 5 4 7 3 6 6 4 1 3源代码
//本题考察的为模拟,在这里我使用的是深搜
//首先我们对于该样例进行观察,发现蛇形矩阵的走法只有两种方式
//第一种:右->左下->下->右上
//第二种:下->左下->右->右上
//因此我们的DFS可以分支分两支,注意左下和右上要用while而不是if
//注意在我们每次走完一种方式之后,其必定会在左下或者右上的最后一个点
//那么下次我们在搜索的时候要从这一个点开始搜,但是对于重复搜索的话会导致元素的重复输出
//我们恰恰可以利用布尔数组来实现这一点,在某种情况的末端搜原点,但是由于原点已被打过标记的原因
//我们就可以利用标记,在DFS入口将没有打过标记的输出,打过标记的不输出即可
//另外还要注意特判,假设当前矩阵仅仅有一个元素的话,那么我们的这个方式是不会有输出的
//因此要设置当仅仅有一个元素的时候且起点即为终点的情况时我们直接将这一点进行输出即可,而后结束DFS
#include <iostream>
using namespace std;
const int N = 1000 + 10;
int a[N][N];
bool vis[N][N];
int n;
void dfs(int x,int y)
{
if(n == 1 && x == 1 && y == 1)
{
cout << a[x][y] << ' ';
return;
}
if(x == n && y == n)return;
if(!vis[x][y])cout << a[x][y] << ' ';
vis[x][y] = true;
if(y + 1 >= 1 && y + 1 <= n && x >= 1 && x <= n && !vis[x][y + 1])
{
vis[x][++ y] = true;
cout << a[x][y] << ' ';
while(!vis[x + 1][y - 1] && x + 1 >= 1 && x + 1 <= n && y - 1 >= 1 && y - 1 <= n)
{
vis[++ x][-- y] = true;
cout << a[x][y] << ' ';
}
if(x + 1 >= 1 && x + 1 <= n && y >= 1 && y <= n && !vis[x + 1][y])
{
vis[++ x][y] = true;
cout << a[x][y] << ' ';
}
while(!vis[x - 1][y + 1] && x - 1 >= 1 && x - 1 <= n && y + 1 >= 1 && y + 1 <= n)
{
vis[-- x][++ y] = true;
cout << a[x][y] << ' ';
}
dfs(x,y);
}
else if(x + 1 >= 1 && x + 1 <= n && y >= 1 && y <= n && !vis[x + 1][y])
{
vis[++ x][y] = true;
cout << a[x][y] << ' ';
while(!vis[x + 1][y - 1] && x + 1 >= 1 && x + 1 <= n && y - 1 >= 1 && y - 1 <= n)
{
vis[++ x][-- y] = true;
cout << a[x][y] << ' ';
}
if(y + 1 >= 1 && y + 1 <= n && x >= 1 && x <= n && !vis[x][y + 1])
{
vis[x][++ y] = true;
cout << a[x][y] << ' ';
}
while(!vis[x - 1][y + 1] && x - 1 >= 1 && x - 1 <= n && y + 1 >= 1 && y + 1 <= n)
{
vis[-- x][++ y] = true;
cout << a[x][y] << ' ';
}
dfs(x,y);
}
}
int main()
{
cin >> n;
for(int i = 1;i <= n;i ++ )
{
for(int j = 1;j <= n;j ++ )
{
cin >> a[i][j];
}
}
dfs(1,1);
return 0;
}拼写正确
给定一个非负整数 N,你的任务是计算 N 的所有数字的总和,并以英语输出总和的每个数字。
输入格式
共一行,包含一个整数 N。
输出格式
共一行,用英语输出总和的每个数字,单词之间用空格隔开。
数据范围
0≤N≤10100
输入样例:
12345
输出样例:
one five源代码
//本题考察的为字符串的处理和模拟知识点,注意数据范围我们只能按照字符串类型来读入
//而后的累加的和由于我们不知道累加和的位数,输出有要求从最高位开始输出,因此我们可以使用库函数将累加和转换为字符串
//变成了字符串的累加和就可以从开头遍历至结尾了,将0-9的字符型数字进行一一英文单词的对应输出即可
#include <iostream>
#include <cstring>
using namespace std;
typedef long long ll;
int main()
{
string s;
cin >> s;
ll t = 0;
for(int i = 0;i < s.size();i ++ )t += (s[i] - '0');
string ans = to_string(t);
for(int i = 0;i < ans.size();i ++ )
{
if(ans[i] == '1')cout << "one" << ' ';
else if(ans[i] == '2')cout << "two" << ' ';
else if(ans[i] == '3')cout << "three" << ' ';
else if(ans[i] == '4')cout << "four" << ' ';
else if(ans[i] == '5')cout << "five" << ' ';
else if(ans[i] == '6')cout << "six" << ' ';
else if(ans[i] == '7')cout << "seven" << ' ';
else if(ans[i] == '8')cout << "eight" << ' ';
else if(ans[i] == '9')cout << "nine" << ' ';
else if(ans[i] == '0')cout << "zero" << ' ';
}
return 0;
}明明的随机数
明明想在学校中请一些同学一起做一项问卷调查。
为了实验的客观性,他先用计算机生成了 N 个 1 到 1000 之间的随机整数,对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。
然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。
请你协助明明完成“去重”与“排序”的工作。
输入格式
输入文件包含 2 行,第 1 行为 1 个正整数,表示所生成的随机数的个数:N。
第 2 行有 N 个用空格隔开的正整数,为所产生的随机数。
输出格式
输出文件也是 2 行,第 1 行为 1 个正整数 M,表示不相同的随机数的个数。
第 2 行为 M 个用空格隔开的正整数,为从小到大排好序的不相同的随机数。
数据范围
1≤N≤100
输入样例:
10
20 40 32 67 40 20 89 300 400 15
输出样例:
8
15 20 32 40 67 89 300 400源代码
//本题考察的快速排序和去重的算法
//借用vector动态数组和算法库来实现
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> A;
int main()
{
int n;
cin >> n;
while(n -- )
{
int num;
cin >> num;
A.push_back(num);
}
sort(A.begin(),A.end());
A.erase(unique(A.begin(),A.end()),A.end());
cout << A.size() << endl;
for(int i = 0;i < A.size();i ++ )cout << A[i] << ' ';
return 0;
}
比例简化
在社交媒体上,经常会看到针对某一个观点同意与否的民意调查以及结果。
例如,对某一观点表示支持的有 1498 人,反对的有 902 人,那么赞同与反对的比例可以简单的记为 1498:902。
不过,如果把调查结果就以这种方式呈现出来,大多数人肯定不会满意。
因为这个比例的数值太大,难以一眼看出它们的关系。
对于上面这个例子,如果把比例记为 5:3,虽然与真实结果有一定的误差,但依然能够较为准确地反映调查结果,同时也显得比较直观。
现给出支持人数 A,反对人数 B,以及一个上限 L,请你将 A:B 化简为A′:B′,要求在 A′ 和 B′ 均不大于 L 且 A′ 和 B′ 互质(两个整数的最大公约数是 1)的前提下,A′/B′≥A/B且A′/B′−A/B 的值尽可能小。
输入格式
输入共一行,包含三个整数 A,B,L,每两个整数之间用一个空格隔开,分别表示支持人数、反对人数以及上限。
输出格式
输出共一行,包含两个整数 A′,B′,中间用一个空格隔开,表示化简后的比例。
数据范围
1≤A,B≤10^6
1≤L≤100,A/B≤L
输入样例:
1498 902 10
输出样例:
5 3源代码
//本题考查的算法为二分加枚举,在这里由于数据不是太大我直接用的枚举
//并没有用二分优化,即枚举新的A和B,当所枚举的A和B互质且满足其他的条件是
//开始进行下一层的判断,在下一层当中,为了不断的使ans的值尽可能地小,即一旦当前所枚举的A和B的值运算的ans小于所给的ans的时候
//就进行答案A和B的更新,注意,答案A和B的更新与题目所给的和我们一直使用的A和B要分开存储
//不然在进行条件判断时利用的A和B也会不断的更新变动,导致答案出错
#include <iostream>
using namespace std;
int gcd(int a,int b)
{
if(a % b == 0)return b;
else return gcd(b,a % b);
}
int main()
{
int a,b,l;
cin >> a >> b >> l;
int A,B;
double ans = 1e9;
for(int i = 1;i <= l;i ++ )
{
for(int j = 1;j <= l;j ++ )
{
if(gcd(i,j) == 1)
{
double x1 = (i * 1.0) / (j * 1.0);
double x2 = (a * 1.0) / (b * 1.0);
if(x1 - x2 < ans && x1 >= x2)
{
ans = x1 - x2;
A = i;
B = j;
}
}
}
}
cout << A << ' ' << B << endl;
return 0;
}数字反转
给定一个整数,请将该数各个位上数字反转得到一个新数。
新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零。
输入格式
输入共 1 行,1 个整数 N。
输出格式
输出共 1 行,1 个整数表示反转后的新数。
数据范围
|N|≤10^9
输入样例:
123
输出样例:
321
输入样例:
-380
输出样例:
-83源代码
//本题考察的为字符串处理和模拟的知识,在这里我利用的是vector动态数组和算法库中的reverse函数
//首先我们对于输入的数字直接以字符串的类型进行读入,然后开始从头遍历,若第一位是符号位置标志为0,跳过塞入,否则则塞入
//而后将字符串的其余部分塞入动态数组当中,对于末尾0先进行删除再反转
//输出的时候注意特判0,再末尾0的删除过程中,若结果是0,那么动态数组中就会仅仅存0一个,此时不用管符号直接输出0即可
//其余的情况则为正数(flag == 1),直接输出反转后的字符串即可
//另一情况则为负数(flag == 0),再输出反转的字符串之前输出一个负号即可
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<char> A;
int main()
{
string s;
cin >> s;
int flag = 1;
for(int i = 0;i < s.size();i ++ )
{
if(i == 0)
{
if(s[i] == '-')flag = 0;
if(flag == 1)A.push_back(s[i]);
}
else A.push_back(s[i]);
}
while(A.size() > 1 && A.back() == '0')A.pop_back();
reverse(A.begin(),A.end());
if(A.size() == 1 && A[0] == '0')cout << '0' << endl;
else
{
if(flag == 0)cout << '-';
for(int i = 0;i < A.size();i ++ )cout << A[i];
}
return 0;
}
质因数分解
已知正整数 n 是两个不同的质数的乘积,试求出较大的那个质数。
输入格式
输入只有一行,包含一个正整数 n。
输出格式
输出只有一行,包含一个正整数 p,即较大的那个质数。
数据范围
6≤n≤2∗10^9
输入样例:
21
输出样例:
7源代码
//考察数论小知识:任意一个大于1的质数其必为质数的乘积所组成
//也就是说只要一个质数我们能够求出其中一个因子,那么另一个因子必为质数,就不用再判断了
//注意本题陷阱,所给的n必定为质数,我们求出组成其的一个因子即可
#include <iostream>
#include <cmath>
using namespace std;
typedef long long ll;
bool judge(ll n)
{
for(int i = 2;i <= sqrt(n);i ++ )
{
if(n % i == 0)return false;
}
return true;
}
int main()
{
ll n;
cin >> n;
for(ll i = 2;i <= n / 2;i ++ )
{
if(judge(i) && n % i == 0)
{
cout << max(i,n / i);
break;
}
}
return 0;
}陶陶摘苹果
陶陶家的院子里有一棵苹果树,每到秋天树上就会结出 10 个苹果。
苹果成熟的时候,陶陶就会跑去摘苹果。
陶陶有个 30 厘米高的板凳,当她不能直接用手摘到苹果的时候,就会踩到板凳上再试试。
现在已知 10 个苹果到地面的高度,以及陶陶把手伸直的时候能够达到的最大高度,请帮陶陶算一下她能够摘到的苹果的数目。
假设她碰到苹果,苹果就会掉下来。
输入格式
输入文件包括两行数据。
第一行包含 10 个 100 到 200 之间(包括 100 和 200)的整数(以厘米为单位)分别表示 10 个苹果到地面的高度,两个相邻的整数之间用一个空格隔开。
第二行只包括一个 100 到 120 之间(包含 100 和 120)的整数(以厘米为单位),表示陶陶把手伸直的时候能够达到的最大高度。
输出格式
输出文件包括一行,这一行只包含一个整数,表示陶陶能够摘到的苹果的数目。
输入样例:
100 200 150 140 129 134 167 198 200 111
110
输出样例:
5源代码
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1000000+10;
int q[N];
void quick_sort(int q[],int l,int r)//快速排序
{
if(l>=r)return;
int x=q[l+r>>1],i=l-1,j=r+1;
while(i<j)
{
do i++;while(q[i]<x);
do j--;while(q[j]>x);
if(i<j)swap(q[i],q[j]);
}
quick_sort(q,l,j);
quick_sort(q,j+1,r);
}
int main()
{
for(int i = 1;i <= 10;i ++ )scanf("%d",&q[i]);
quick_sort(q,1,10);
int high,num=0,touch;
scanf("%d",&high);
touch=high+30;
for(int i = 1;i <= 10;i ++ )
{
if(touch>=q[i])num=num+1;
}
printf("%d",num);
}数列
给定一个正整数 k,把所有 k 的方幂及所有有限个互不相等的 k 的方幂之和构成一个递增的序列,例如,当 k=3 时,这个序列是:
1,3,4,9,10,12,13,…
该序列实际上就是:3^0,3^1,3^0+3^1,3^2,3^0+3^2,3^1+3^2,3^0+3^1+3^2,…
请你求出这个序列的第 N 项的值(N 用 10 进制数表示,从 1 开始)。
例如,对于 k=3,N=100,正确答案应该是 981
输入格式
输入文件只有 1 行,为 2 个正整数,用一个空格隔开:k,N。
输出格式
输出文件为计算结果,是一个正整数(在所有的测试数据中,结果均不超过 2.1×10^9)。(整数前不要有空格和其他符号)。
数据范围
3≤k≤15
10≤N≤1000
输入样例:
3 100
输出样例:
981
源代码
//本题考查的为二进制映射,我们可以对数列进行观察发现
//数列的底数k是一定的,我们把n转化为二进制之后,可以发现如果套用底数来进行二进制的运算的话
//所得的答案正好是以k为底的第n项的数字
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long ll;
vector<int> A;
int main()
{
int k,n;
cin >> k >> n;
//将n转换为二进制数
while(n > 0)
{
int num = n % 2;
A.push_back(num);
n /= 2;
}
//反转二进制数,得到正序二进制数
reverse(A.begin(),A.end());
//开始进行以k为底的二进制数的转换工作
ll ans = 0;
//定义权重
int w = 1;
for(int i = A.size() - 1;i >= 0;i -- )
{
ans += A[i] * w;
w = w * k;
}
cout << ans << endl;
return 0;
}















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











