转:http://my.oschina.net/baoer1024/blog/62826
(在求卡特兰数时有 一定作用)
问题:求解组合数C(n,m),即从n个相同物品中取出m个的方案数,由于结果可能非常大,对结果模10007即可。
方案一
暴力求解,C(n,m)=n*(n-1)*...*(n-m+1)/m!
int Combination(int n, int m)
{
const int M = 10007;
int ans = 1;
for(int i=n; i>=(n-m+1); --i)
ans *= i;
while(m)
ans /= m--;
return ans % M;
}
这种方案的缺陷是,在计算过程中很快ans就溢出了,一般情况下,n不能超过12。补救办法之一是将先乘后除改为交叉地进行乘除,先除能整除的,但也只能满足n稍微增大的情况,n最多只能满足两位数。补救办法之二是换用高精度运算,这样结果不会有问题,只是需要实现大数相乘、相除和取模等运算,实现起来比较麻烦,时间复杂度为O(n)。
方案二
打表,C(n,m)=C(n-1,m-1)+C(n-1,m)
由于组合数满足以上性质,可以预先生成所有用到的组合数,使用时,直接查找即可。生成的复杂度为O(n^2),查询复杂度为O(1)。较方案一而言,支持的数量级大有提升,在1秒内,基本能处理10000以内的组合数。算法的预处理时间较长,另外空间花费较大,都是平方级的,优点是实现简单,查询时间快。
const int M = 10007;
const int MAXN = 1000;
int C[MAXN+1][MAXN+1];
void Initial()
{
int i,j;
for(i=0; i<=MAXN; ++i)
{
C[0][i] = 0;
C[i][0] = 1;
}
for(i=1; i<=MAXN; ++i)
{
for(j=1; j<=MAXN; ++j)
C[i][j] = (C[i-1][j] + C[i-1][j-1]) % M;
}
}
int Combination(int n, int m)
{
return C[n][m];
}
方案三
质因数分解,C(n,m)=n!/(m!*(n-m)!),设n!分解因式后,质因数p的次数为a;对应地m!分解后p的次数为b;(n-m)!分解后p的次数为c;则C(n,m)分解后,p的次数为a-b-c。计算出所有质因子的次数,它们的积即为答案,即C(n,m)=p1
a1-b1-c1p2
a2-b2-c2…pk
ak-bk-ck。n!分解后p的次数为:n/p+n/p
2+…+n/p
k。
算法的时间复杂度比前两种方案都低,基本上跟n以内的素数个数呈线性关系,而素数个数通常比n都小几个数量级,例如100万以内的素数不到8万个。用筛法生成素数的时间接近线性。该方案1秒钟能计算 1kw数量级的组合数。如果要计算更大,内存和时间消耗都比较大。
//用筛法生成素数
const int MAXN = 1000000;
bool arr[MAXN+1] = {false};
vector<int> produce_prim_number()
{
vector<int> prim;
prim.push_back(2);
int i,j;
for(i=3; i*i<=MAXN; i+=2)
{
if(!arr[i])
{
prim.push_back(i);
for(j=i*i; j<=MAXN; j+=i)
arr[j] = true;
}
}
while(i<=MAXN)
{
if(!arr[i])
prim.push_back(i);
i+=2;
}
return prim;
}
//计算n!中素因子p的指数
int Cal(int x, int p)
{
int ans = 0;
long long rec = p;
while(x>=rec)
{
ans += x/rec;
rec *= p;
}
return ans;
}
//计算n的k次方对M取模,二分法
int Pow(long long n, int k, int M)
{
long long ans = 1;
while(k)
{
if(k&1)
{
ans = (ans * n) % M;
}
n = (n * n) % M;
k >>= 1;
}
return ans;
}
//计算C(n,m)
int Combination(int n, int m)
{
const int M = 10007;
vector<int> prim = produce_prim_number();
long long ans = 1;
int num;
for(int i=0; i<prim.size() && prim[i]<=n; ++i)
{
num = Cal(n, prim[i]) - Cal(m, prim[i]) - Cal(n-m, prim[i]);
ans = (ans * Pow(prim[i], num, M)) % M;
}
return ans;
}
方案四
Lucas定理,设p是一个素数(题目中要求取模的数也是素数),将n,m均转化为p进制数,表示如下:
满足下式:
即C(n,m)模p等于p进制数上各位的C(ni,mi)模p的乘积。利用该定理,可以将计算较大的C(n,m)转化成计算各个较小的C(ni,mi)。
该方案能支持整型范围内所有数的组合数计算,甚至支持64位整数,注意中途溢出处理。该算法的时间复杂度跟n几乎不相关了,可以认为算法复杂度在常数和对数之间。
#include <stdio.h>
const int M = 10007;
int ff[M+5]; //打表,记录n!,避免重复计算
//求最大公因数
int gcd(int a,int b)
{
if(b==0)
return a;
else
return gcd(b,a%b);
}
//解线性同余方程,扩展欧几里德定理
int x,y;
void Extended_gcd(int a,int b)
{
if(b==0)
{
x=1;
y=0;
}
else
{
Extended_gcd(b,a%b);
long t=x;
x=y;
y=t-(a/b)*y;
}
}
//计算不大的C(n,m)
int C(int a,int b)
{
if(b>a)
return 0;
b=(ff[a-b]*ff[b])%M;
a=ff[a];
int c=gcd(a,b);
a/=c;
b/=c;
Extended_gcd(b,M);
x=(x+M)%M;
x=(x*a)%M;
return x;
}
//Lucas定理
int Combination(int n, int m)
{
int ans=1;
int a,b;
while(m||n)
{
a=n%M;
b=m%M;
n/=M;
m/=M;
ans=(ans*C(a,b))%M;
}
return ans;
}
int main(void)
{
int i,m,n;
ff[0]=1;
for(i=1;i<=M;i++) //预计算n!
ff[i]=(ff[i-1]*i)%M;
scanf("%d%d",&n, &m);
printf("%d\n",func(n,m));
return 0;
}
方案五:
一个比较有用且是在O(n)时间内实现公式:C(n,r)=(n-r+1)/r*C(n,r-1);
由C(n,0)直接往上推即可;
方案六:(一般这种方法在计算机上不能对大数进行实现)
计算组合数最大的困难在于数据的溢出,对于大于150的整数n求阶乘很容易超出double类型的范围,那么当C(n,m)中的n=200时,直接用组合公式计算基本就无望了。另外一个难点就是效率。
对于第一个数据溢出的问题,可以这样解决。因为组合数公式为:
C(n,m) = n!/(m!(n-m)!)
为了避免直接计算n的阶乘,对公式两边取对数,于是得到:
ln(C(n,m)) = ln(n!)-ln(m!)-ln((n-m)!)
进一步化简得到:

这样我们就把连乘转换为了连加,因为ln(n)总是很小的,所以上式很难出现数据溢出。
为了解决第二个效率的问题,我们对上式再做一步化简。上式已经把连乘法变成了求和的线性运算,也就是说,上式已经极大地简化了计算的复杂度,但是还可以进一步优化。从上式中,我们很容易看出右边的3项必然存在重复的部分。现在我们把右边第一项拆成两部分:

这样,上式右边第一项就可以被抵消掉,于是得到:

上式直接减少了2m次对数计算及求和运算。但是这个公式还可以优化。对于上面公式里的求和,当m<n/2时,n-m是一个很大的数,但是当m>n/2时,n-m就会小很多。我们知道:
C(n,m) = C(n,n-m)
那么通过这个公式,我们可以把小于n/2的m变为大于n/2的n-m再进行计算,结果是一样的,但是却能减少计算量。
当计算出ln(C(n,m))后,只需要取自然对数,就可以得到组合数:
C(n,m) = exp(ln(C(n,m)))
这样就完成了组合数的计算。
用这种方法计算组合数,如果只计算ln(C(n,m))的话,n可以取到整型数据的极限值65535,
ln(C(65535,32767)) = 45419.6
而计算时间只需要0.01ms。当然,如果要取对数得到最终的组合数的话,n的取值就不能达到这么大了。但是这种算法仍然可以保证n取到1000以上,而不是开头说的150这个极限值。例如:
C(1000,500) = 2.70288e+299
计算时间仍然小于0.01ms。
采用我这种算法,不仅n的取值范围大,而且计算速度高,不像用递归算法实现这个问题的时候,很容易陷入递归层次太深而导致计算时间太长。
算法代码实现如下:
1 double lnchoose(int n, int m)
2 {
3 if (m > n)
4 {
5 return 0;
6 }
7 if (m < n/2.0)
8 {
9 m = n-m;
10 }
11 double s1 = 0;
12 for (int i=m+1; i<=n; i++)
13 {
14 s1 += log((double)i);
15 }
16 double s2 = 0;
17 int ub = n-m;
18 for (int i=2; i<=ub; i++)
19 {
20 s2 += log((double)i);
21 }
22 return s1-s2;
23 }
24
25 double choose(int n, int m)
26 {
27 if (m > n)
28 {
29 return 0;
30 }
31 return exp(lnchoose(n, m));
32 }









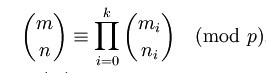















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









