






本学习笔记为阿里云天池龙珠计划Docker训练营的学习内容,学习链接为:-天池实验室-实时在线的数据分析协作工具,享受免费计算资源 (aliyun.com)
一、学习知识点概要
本文主要通过一道入门级别竞赛题,对赛题,数据及预测指标作了详细说明,并给出了部分代码示例。
以下是学习目标:
- 理解赛题数据和目标,清楚评分体系。
- 完成相应报名,下载数据和结果提交打卡(可提交示例结果),熟悉比赛流程
二、学习内容
1.评估指标
评估指标即是我们对于一个模型效果的数值型量化。(有点类似与对于一个商品评价打分,而这是针对于模型效果和理想效果之间的一个打分)
分类算法常见的评估指标如下:
- 对于二类分类器/分类算法,评价指标主要有accuracy, [Precision,Recall,F-score,Pr曲线],ROC-AUC曲线。
- 对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]。
平均绝对误差(Mean Absolute Error,MAE):
-
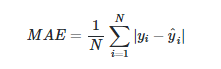
-
均方误差(Mean Squared Error,MSE)
-
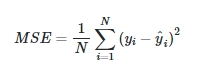
-
R2(R-Square)的公式为:
-

-
R2R2用于度量因变量的变异中可由自变量解释部分所占的比例,取值范围是 0~1,R2R2越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变化的部分就越多,回归的拟合程度就越好。所以R^2也称为拟合优度(Goodness of Fit)的统计量。
-
yiyi表示真实值,^yiy^i表示预测值,¯¯¯yiy¯i表示样本均值。得分越高拟合效果越好。
2.分析赛题
- 此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。
- 此题是一个典型的回归问题。
- 主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常用库或者框架来进行数据挖掘任务。
- 通过EDA来挖掘数据的联系和自我熟悉数据。
-
#下载数据
# 下载数据
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/DM/data.zip
# 解压下载好的数据
!unzip data.zip
#数据读取pandas
import pandas as pd
import numpy as np
path = './data/'
## 1) 载入训练集和测试集;
Train_data = pd.read_csv(path+'train.csv', sep=' ')
Test_data = pd.read_csv(path+'testA.csv', sep=' ')
print('Train data shape:',Train_data.shape)
print('TestA data shape:',Test_data.shape)Train data shape: (75414, 31) TestA data shape: (50000, 30)
3.分类指标评价计算示例
## accuracy
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 1]
print('ACC:',accuracy_score(y_true, y_pred))ACC=0.75
## Precision,Recall,F1-score
from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
print('Precision',metrics.precision_score(y_true, y_pred))
print('Recall',metrics.recall_score(y_true, y_pred))
print('F1-score:',metrics.f1_score(y_true, y_pred))Precision 1.0 Recall 0.5 F1-score: 0.6666666666666666## AUC
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('AUC socre:',roc_auc_score(y_true, y_scores))
AUC socre: 0.75
4.回归指标评价计算示例
# coding=utf-8
import numpy as np
from sklearn import metrics# MAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true))y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])# MSE
print('MSE:',metrics.mean_squared_error(y_true, y_pred))
# RMSE
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_true, y_pred)))
# MAE
print('MAE:',metrics.mean_absolute_error(y_true, y_pred))
# MAPE
print('MAPE:',mape(y_true, y_pred))MSE: 0.2871428571428571 RMSE: 0.5358571238146014 MAE: 0.4142857142857143 MAPE: 0.1461904761904762## R2-score
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print('R2-score:',r2_score(y_true, y_pred))
R2-score: 0.9486081370449679
三、学习问题与解答
最近做的一道自然语言处理的题目中,发现自己对于列表及字典的运用并不熟练,总是出现把列表当作字典用的问题。此篇文章让我了解到其实认真解读赛题,构造好的特征比运用好的算法更能提高模型的性能。
四、学习思考与总结
1.学会分析问题是否可行,哪些指标可以做到线上线下一致,并通过EDA来寻求他们直接的关系,构造满意的特征
2.分析出哪些数据是关键数据,可以构造更好的特征,线下验证方式更稳定。
3.由于模型的线上验证有次数限制,,所以构建验证集和验证的评价指标十分有必要。
4.找出赛题背后隐藏的关键条件。


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









