







Chapter 14 Indexing
14.1 Basic Concepts
众所周知,索引就是用于加快检索滴,就像书的目录一样,维护了主题到页数的映射,我们通过某个关键字查找主题,然后再跳转到某一页进行内容的查看。本章主要介绍一些常见的索引技术,主要是Hash索引与B+tree索引,在本节让我们先了解一些基本概念。
有两种基本的索引类型:
- 顺序索引:基于key进行顺序排序
- 散列索引:将key散列到不同的hash桶中
索引技术非常多,适用于不同的场景,主要由以下几点衡量是否适用:
- 访问类型:能支持的访问类型(包括查询具有特定属性值的记录、查询特定属性值在某个特定区间范围的记录)
- 访问时间:找到一个特定记录或记录集所花费的时间
- 插入时间:插入一个新记录所需要的时间
- 删除时间:删除一个记录所需要的时间
- 空间复杂度:维护索引结构所需要的空间开销
通常我们会在一个文件中建立多个索引,比如我们可能希望按照作者、主题或者书名来查找图书馆里的一本书。其中,用于查找的关键字称为搜索码,搜索码可以由一个或多个属性组成。
14.2 Ordered Indices
顺序索引按照搜索码的值进行排序并存储,并将搜索码与包含该搜索码的记录关联起来。被索引的文件中的记录也可能按照某个顺序存储,若记录的排列顺序与索引中的搜索码排列顺序一致,则称为聚集索引或主索引;若顺序不一致,则称为非聚集索引或辅助索引。
在14.2.1-14.2.3中,我们假定所有提到的文件都按照某种搜索码顺序存储,这种在搜索码上存在聚集索引的文件称为索引顺序文件。在14.2.4中我们将介绍辅助索引。
14.2.1 Dense and Sparse Indices
首先介绍一个概念,索引项,由一个搜索码值和一个指针构成,其中指针指向具有该搜索码值的一条或多条记录。
顺序索引包含两类:
- 稠密索引:文件中的每个搜索码都有一个对应的索引项。在稠密聚集索引中,索引项包括搜索码值和指向具有该搜索码值的第一条记录的指针即可(因为聚集索引,所以文件中的记录按照搜索码值排序,具有相同搜索码值的其余记录会顺序地存储在第一条记录之后);而在稠密非聚集索引中,索引项必须包括索引值和指向具有该搜索码值的所有记录的指针列表
- 稀疏索引:只为某些搜索码值建立索引项。只有当索引是聚集索引时,才能使用稀疏索引。由于是聚集索引,索引项包括搜索码值和指向具有该搜索码值的第一条记录的指针即可。当我们定位一条记录时,根据索引找到一个最大搜索码值A,满足该搜索码值A小于等于我们所找记录的搜索码值,从搜索码值A对应的索引项指向的记录开始,顺着往后查询直到遇到我们所找记录。
一些具体的例子如下所示:
如下图为一个稠密索引的具体示例,其中的搜索码为
i
n
s
t
r
u
c
t
o
r
_
I
D
instructor\_ID
instructor_ID,由于
i
n
s
t
r
u
c
t
o
r
_
I
D
instructor\_ID
instructor_ID为主码,于是每个搜索码只存在一条对应的记录
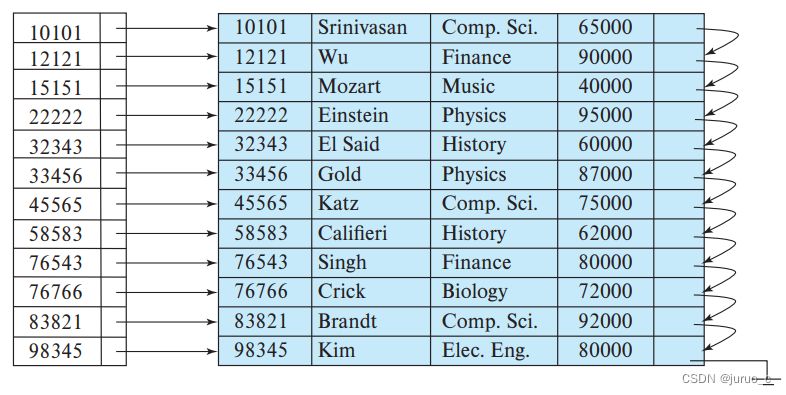
也可以建立出如下图所示的稀疏索引,若我们需要找到搜索码值为22222的记录,则根据索引项的搜索码值,找到小于等于22222的最大搜索码值为10101,则从10101对应的记录往下顺序寻找。
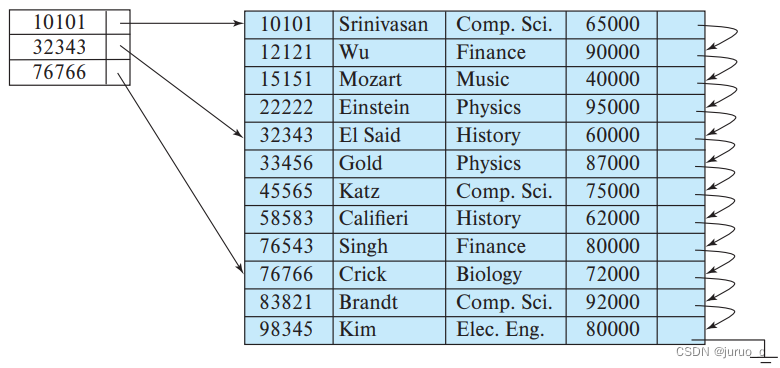
以上均为搜索码值为主码的例子,我们再看一个搜索码值不为主码的例子,如下图所示,以
d
e
p
t
n
a
m
e
dept_name
deptname为搜索码建立稠密聚集索引。由于
d
e
p
t
n
a
m
e
dept_name
deptname不为主码,故一个搜索码值可能对应多条记录,但由于该文件按照
d
e
p
t
n
a
m
e
dept_name
deptname排序,该索引为聚集索引,索引项只需要保存指向包含该搜索码值的第一条记录指针。
稠密索引定位记录的速度较快,而稀疏索引占用空间较小。一种较好的折中方案是为每个块建立一个索引项的稀疏索引,因为处理一个查询的主要开销在于将块从磁盘读到内存,使用这样的稀疏索引可以定位到包含所查找记录的块,使得磁盘访问次数较少。
14.2.2 Multilevel Indices
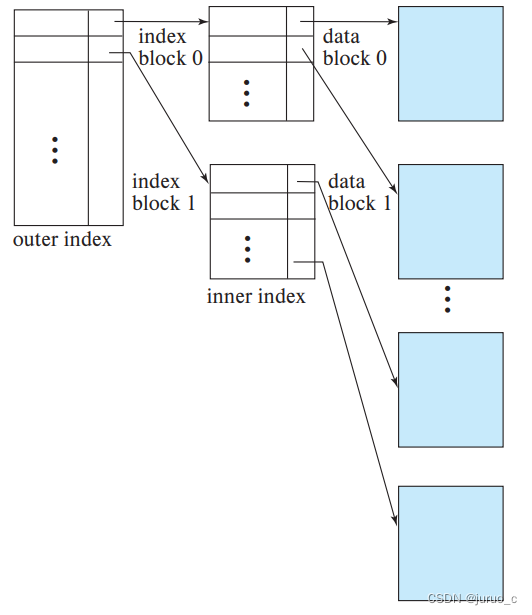
具有两级或两级以上的索引称为多级索引,多级索引的思想与文件系统中的多级索引存储非常类似,即建立索引的索引。如下图所示,我们将原始的索引称为内层索引,并在原始的索引上构造一个稀疏的外层索引,就像对记录构建索引那样去构建,外层索引项包含内存索引块中的最小搜索码值与内层索引块地址。由于内层索引的索引项是有序的,所以外层索引的索引项也是有序的,我们仍然可以使用二分法进行快速搜索。
像这样构建的多级索引有什么好处呢?考虑一个具体的例子,假设我们在具有
1
0
8
10^8
108个元组的关系主码上建立稠密索引,则索引项也有
1
0
8
10^8
108个,又假设一个4KB的块中可以容纳
100
100
100个索引项,那么所有的索引项共需要占用
1
0
6
10^6
106个块,换句话说需要4GB的空间,一般情况下不可能完全将索引存放进内存中。
定位一个索引项可以使用二分法,假设块数为
b
b
b,则大概需要读取
l
o
g
2
b
log_2b
log2b个块。对于以上例子,则大概需要读取
20
20
20个块,这已经是非常大的磁盘IO开销了。而如果我们使用二级索引,外层索引会有
1
0
6
10^6
106个索引项,则需要
1
0
4
10^4
104个索引块进行存储,大概需要40MB空间。
40MB的外层索引一次性加载进内存是可能的,那么我们不需要每次搜索的
20
20
20次磁盘IO,而只需要通过内存中对外层索引的二分找到特定的内层索引块,从而读取一个特定的内层索引块,将读取
20
20
20个块变为读取
1
1
1个块,性能可以提升
20
20
20倍。
如果内存不支持一次性放入40MB的外层索引,那么我们可以按照同样的思路再对外层索引做一次索引,即三级索引。
14.2.3 Index Update
当记录文件发生变化时(插入、删除或更新),对应的索引文件也需要变化,可以只考虑记录的插入和删除,因为更新可以转化为删除旧记录再插入新记录。以下的讨论基于单级索引,多级索引的操作本质上是一致的。
14.2.3.1 Insert
考虑插入一条记录时索引的更新,系统首先需要使用待插入记录中的搜索码值(我们记为 K e y Key Key)进行查找,并根据索引是稠密索引还是稀疏索引进行分情况讨论。
- 稠密索引:
- 若索引中不包含 K e y Key Key这个搜索码值,那么系统在合适的位置插入一个新索引项
- 若索引中包含
K
e
y
Key
Key
- 若为聚集索引(索引项只存储一个指向包含该搜索码值的第一条记录的指针),那么系统将待插入记录插入到具有相同搜索码值的其他记录之后
- 若为非聚集索引(索引项存储指向所有包含该搜索码值的记录的指针),那么系统在索引项中新增一个指针
- 稀疏索引:假设对每一个数据块建立一个索引项。
- 若系统为待插入记录新建了一个数据块,那么系统在合适的位置新增一个索引项(包含 K e y Key Key与指向新增数据块的指针)
- 若没有新增数据块
- 若 K e y Key Key为新插入记录所在块中的最小搜索码值,那么更新指向该块的索引项的搜索码值
- 否则不需做任何更改
14.2.3.2 Delete
考虑删除一条记录,首先系统需要找到待删除的记录,记待删除记录的搜索码值为 K e y Key Key,然后进行决策。
- 稠密索引:
- 若待删除的记录是具有这个 K e y Key Key的唯一一条记录,那么删除 K e y Key Key对应的索引项
- 若不是唯一记录
- 若为聚集索引且该记录为具有 K e y Key Key的第一条记录,则更新索引项中的记录指针指向具有 K e y Key Key的下一条记录
- 若为非聚集索引,则删除索引项中指向待删除记录的指针
- 稀疏索引:
- 若索引中不包含 K e y Key Key的索引项,则不需改动
- 若包含
K
e
y
Key
Key
- 若待删除记录是具有
K
e
y
Key
Key的唯一记录, 系统考虑使用下一个记录的搜索码来替换(按搜索码顺序)
- 若下一个搜索码已经存在索引项,则删除而不是替换
- 若不存在,则替换 K e y Key Key的索引项为下一个搜索码并指向下一条记录
- 若不是唯一记录,则更新索引项指向的记录为具有 K e y Key Key的下一条记录
- 若待删除记录是具有
K
e
y
Key
Key的唯一记录, 系统考虑使用下一个记录的搜索码来替换(按搜索码顺序)
14.2.4 Secondary Indices
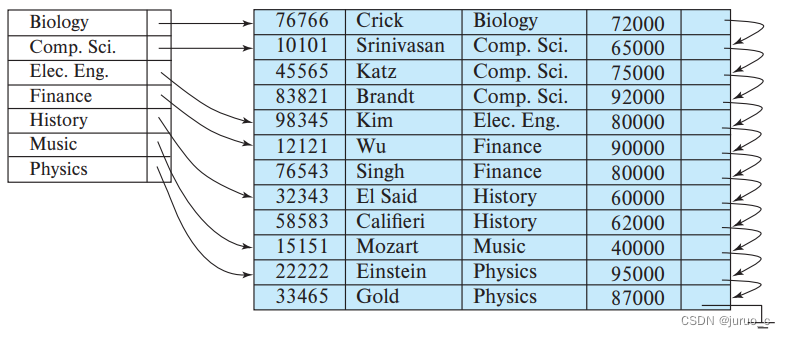
辅助索引中搜索码的排列顺序与被索引文件中的记录排列顺序不一致,换句话说,文件中的记录不按照辅助索引的搜索码排序。因此,辅助索引必须是稠密索引,不然会丢失记录的信息。在前面我们也介绍过,辅助索引的索引项必须包括搜索码值和指向具有该搜索码值的所有记录的指针列表。下面是一个简单的例子,在索引与被索引文件中增加了一层,用于放置指向记录的指针列表。

14.3 B+Tree Index Files
前面介绍的索引顺序文件(顺序的组织形式)都有一个共同的缺点,就是当索引项增多时,索引查找的性能和数据顺序扫描的性能都会下降。而本节的B+树索引结构,是使用最广泛、数据插入和删除时仍能保持执行效率的几种索引结构之一。
14.3.1 Structure of a B+Tree
采用平衡树结构,其中从树根到树叶的每条路径长度都是相同的;树中的每个非叶节点(除根之外)有
⌈
n
/
2
⌉
\lceil n/2 \rceil
⌈n/2⌉到
n
n
n个孩子,根节点有
2
2
2到
n
n
n个孩子。其中,
n
n
n对于特定的树都是固定的。
B+树索引是一种多级索引,但与上节中提到的多级索引顺序文件不一样。在下面的讨论中,我们先假设没有重复的搜索码值,即每个搜索码值最多出现在一条记录中。
B+数的节点结构如下图所示,对于大小为
n
n
n的B+树,其节点最多包含
n
−
1
n-1
n−1个搜索码值
K
1
K_1
K1,
K
2
K_2
K2,…,
K
n
−
1
K_{n-1}
Kn−1,以及
n
n
n个指针
P
1
P_1
P1,…,
P
n
−
1
P_{n-1}
Pn−1,
P
n
P_n
Pn,节点内的搜索码有序存放,即对于任意
i
<
j
i < j
i<j,都有
K
i
<
K
j
K_i < K_j
Ki<Kj

首先考察叶子节点的结构,如下图例子所示,对
i
=
1
,
2
,
.
.
.
,
n
−
1
i = 1, 2, ..., n-1
i=1,2,...,n−1,指针
P
i
P_i
Pi指向具有搜索码值
K
i
K_i
Ki的记录,而指针
P
n
P_n
Pn用于指向下一个叶子节点(有利于进行高效的顺序处理)。叶子节点的一些性质如下:
- 每个叶子节点最多有 n − 1 n-1 n−1个搜索码值
- 每个叶子节点最少包含 ⌈ ( n − 1 ) / 2 ⌉ \lceil (n-1)/2 \rceil ⌈(n−1)/2⌉个搜索码值
- 如果 L i L_i Li和 L j L_j Lj是叶节点且 i < j i < j i<j,则 L i L_i Li中的任意搜索码 v i v_i vi均小于 L j L_j Lj中的任意搜索码 v j v_j vj
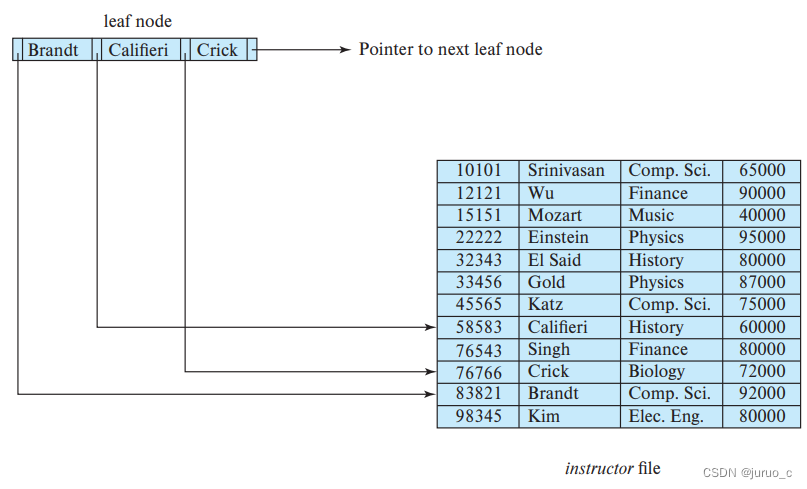
考虑非叶子节点,与多级索引类似,非叶子节点形成叶子节点或者下层的非叶子节点上的一个稀疏索引。非叶子节点的结构与叶子节点一致,但是非叶子节点的指针均指向树节点,且最多容纳
n
n
n个指针,且必须至少容纳
⌈
n
/
2
⌉
\lceil n / 2 \rceil
⌈n/2⌉。考虑一个包含
m
m
m个指针的非叶子节点(其中
m
<
=
n
m <= n
m<=n),则对于
i
=
2
,
3
,
.
.
.
,
m
−
1
i = 2, 3, ..., m-1
i=2,3,...,m−1,指针
P
i
P_i
Pi指向的子树中的搜索码值域为
[
K
i
−
1
,
K
i
)
[K_{i-1}, K_i)
[Ki−1,Ki)(左闭右开),指针
P
1
P_1
P1指向子树中的搜索码值均小于
K
1
K_1
K1,
P
m
P_m
Pm指向子树中的搜索码值均大于等于
K
m
−
1
K_{m-1}
Km−1
考虑根节点,它与一般的非叶节点不同,它包含的指针数可以少于
⌈
n
/
2
⌉
\lceil n / 2 \rceil
⌈n/2⌉个;但是除非整棵树只由一个根节点组成,不然根节点至少包含两个指针
一棵
n
=
4
n=4
n=4的完整B+树例子如下所示:
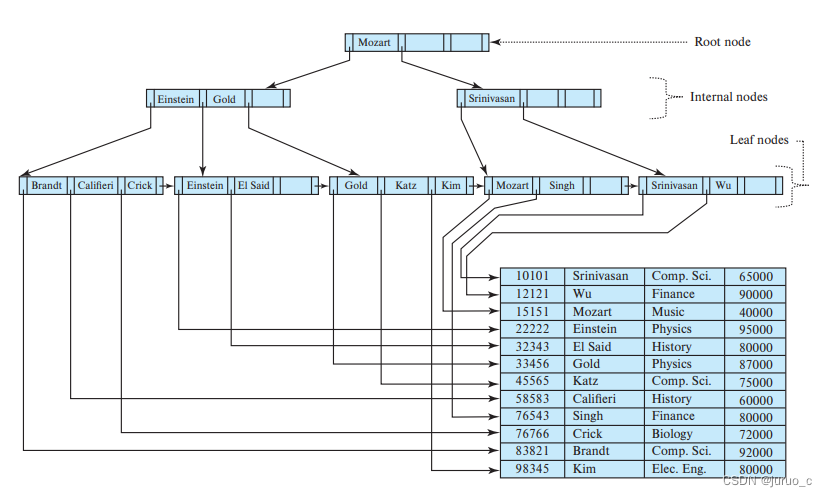
对于相同的文件,也可以建立
n
=
6
n=6
n=6的B+树,如下:

上述考虑的是没有重复搜索码的情况,但是一般情况下,搜索码都有重复项。对于非唯一搜索码情况,一种简单的修改方法是修改树节点的搜索码排序条件,将
i
<
j
i < j
i<j则
K
i
<
K
j
K_i < K_j
Ki<Kj改为
K
i
≤
K
j
K_i \le K_j
Ki≤Kj,但是这种修改会使得插入和删除代价变得很大。另一种修改方法是,将指针指向的内容从一条记录变为一个记录列表,或者说一个桶,但是效率也不高。
大多数数据库的处理方式是将搜索码构造成唯一的。一种构造方式是将非唯一搜索码与任意一个候选码组合起来成为一个超码,超码就是候选码的超集,候选码已是唯一的,超码也必然是唯一的。14.3.5节将更详细地介绍处理非唯一搜索码问题。
14.3.2 Queries on B+Trees
了解了上述B+树的结构之后,在B+树上的查询就比较好理解了,过程都是类似的,顺着树往下走到叶子节点,判断所查询的搜索码是否存在即可(对于范围搜索可以借助
P
n
P_n
Pn指针往下一个叶子节点跳进行下一步判断),不做过多赘述了。
考虑在B+树索引上查询的代价,每次我们查询需要遍历树中从根到某个叶子节点的一条路径,对于节点大小为
n
n
n的树,假设当前搜索码数量为
N
N
N,路径长度最坏情况下为
⌈
l
o
g
⌈
n
/
2
⌉
(
N
)
⌉
\lceil log_{\lceil n/2 \rceil}(N) \rceil
⌈log⌈n/2⌉(N)⌉。
看一个具体的例子,大多数数据库中,B+树索引的节点规模与磁盘块的规模一致,通常为4KB。假设搜索码大小为12Byte,指针大小为8Byte,那么
n
n
n大约为200,即使采用更保守的估计:搜索码大小为32Byte,则
n
n
n大约为100。在
n
=
100
n=100
n=100的情况下,如果文件中存在100万种搜索码值,那么每次查询大约需要访问
⌈
l
o
g
5
0
(
1000000
)
⌉
\lceil log_50(1000000) \rceil
⌈log50(1000000)⌉=
4
4
4个节点,也就是遍历树的一条路径最多访问4个磁盘块。
当搜索到叶子节点时,对于单搜索值查询而言,只需要再执行一次磁盘IO获取匹配的记录。而对于范围查询而言,则还需要额外的代价,因为需要顺着叶子节点的指针
P
n
P_n
Pn向后搜索后续叶子节点,在这种情况下,假设符合查询范围的指针数量有
M
M
M个,则最多还需访问
⌈
M
/
(
n
/
2
)
⌉
+
1
\lceil M/(n/2) \rceil + 1
⌈M/(n/2)⌉+1个叶子节点;而对于获取匹配记录的磁盘IO,最坏情况下也需要
M
M
M次,因为可能每个记录都在独立的磁盘块上(如辅助索引)。
考虑非唯一搜索码的情况,在上节我们讨论过,通过将非唯一搜索码构造为唯一搜索码进行数据的组织。假设某个非唯一搜索码为
a
a
a,我们构造的唯一搜索码为
(
a
,
A
p
)
(a, A_p)
(a,Ap),现在考虑查询
a
=
v
a=v
a=v的所有记录,则可以转换成范围查询搜索码
(
a
,
A
p
)
(a, A_p)
(a,Ap)在
[
(
v
,
−
∞
)
,
(
v
,
+
∞
)
]
[(v, -\infty), (v, +\infty)]
[(v,−∞),(v,+∞)]这个值域范围内的所有记录,其中
−
∞
-\infty
−∞表示
A
p
A_p
Ap的最小值,
+
∞
+\infty
+∞表示
A
p
A_p
Ap的最大值(
A
p
A_p
Ap可能是某个属性也可能是某些属性的集合,且为候选码)
14.3.3 Updates on B+Trees
B+树索引的更新考虑记录的插入和删除的情况即可(记录更新的情况可以转化为删除后插入)
插入与删除记录比查询记录更为复杂,因为刚插入或刚删除的记录可能会使得节点变得过大需要拆分或者变得过小(指针数量少于
⌈
n
/
2
⌉
⌉
\lceil n/2 \rceil⌉
⌈n/2⌉⌉)需要合并。
14.3.3.1 Insert
首先考虑记录的插入流程,首先执行上节所述的查询流程,找到待插入记录应该插入的叶子节点。若该叶子节点还有空间,则直接插入,否则需要考虑节点的拆分操作。
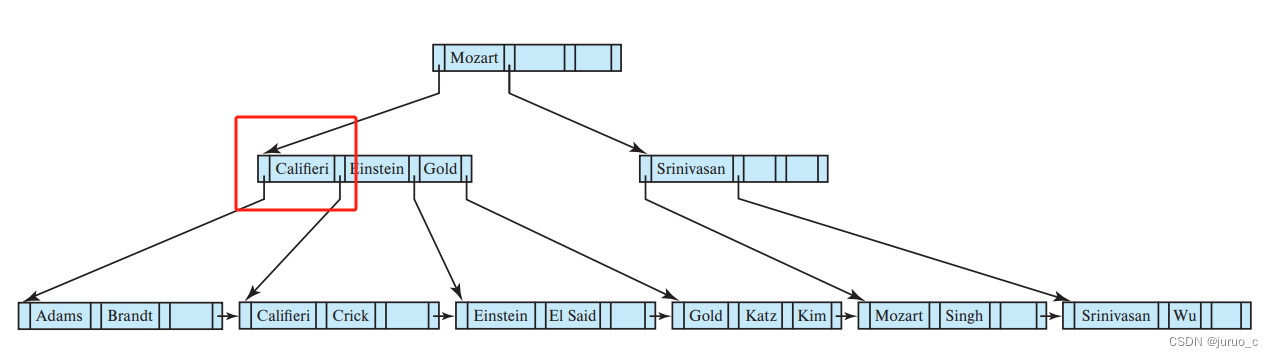
让我们先考虑记录插入导致叶子节点拆分的情况,假设我们在上节所示的表中插入一条搜索码值为Adams的记录,由查询过程我们知道,该记录应该插入的叶子节点如下图所示。

由于该节点已满,需要将该节点拆分为两个新节点,如下图所示。由于当节点溢出时会有
n
n
n个搜索码值,一般来说我们会将按搜索码顺序的前
⌈
n
/
2
⌉
\lceil n/2 \rceil
⌈n/2⌉个值放在原来的节点中,将剩下的值放在新创建的节点中

在将节点拆分后,我们还需要修改原始节点的父亲节点以包含指向新节点的指针,方法时将新节点中的第一个搜索码值插入到父节点中的正确位置,并修改指针项,修改完的结构如下图所示。由于目前父亲节点还存在空间,故不需要进一步拆分。
现在我们考虑插入记录导致非叶子节点拆分的情况,依然以上面的表为例子,我们继承并继续插入具有搜索码值Lamport的记录,不难得到插入的叶子节点位置如下图所示。
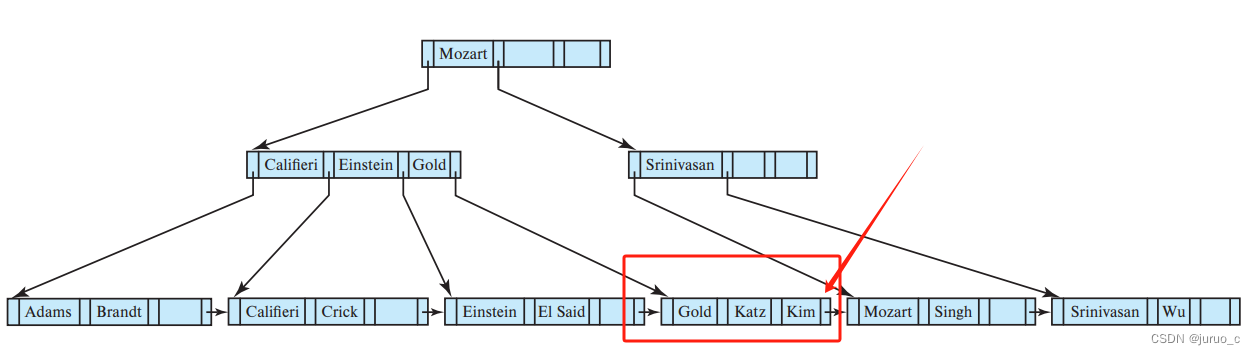
由于该叶子节点已满,我们需要进行拆分,如下图所示。

而且我们需要在父亲节点中插入搜索码Kim与指向新节点的指针,但是由于父亲节点已满,所以需要进一步拆分父亲节点。当拆分一个过满的非叶子节点时,该节点首先概念性的扩大(就是假装扩大),先把新搜索码容纳进去,如下所示。

然后新建节点,孩子指针将在原始节点与新建节点之间进行划分,如下图所示,我们将五个指针(原始的4个和新增的1个)中的三个划分给原始节点(左),剩余两个划分给新建节点(右)。这里,我们将划分到原始节点的最右边指针记为pLeft,将划分到新建节点的最左边指针记为pRight。对于搜索码处理,pLeft往左的搜索码值将被保留在原始节点中,pRight往右的搜索码值将被存放在新建节点中。

而pLeft与pRight中间的搜索码值将被区别对待(在这里该搜索码值为Gold),由于新建了一个节点,所以原始节点的父亲节点必须包含指向新建节点的指针。在我们的例子中,搜索码Gold将与新建节点的指针一起被插入到父亲节点中。若父亲节点也需要拆分,则按照相同的步骤,直到递归到根节点。若根节点也需要拆分,则整个树的深度会加1。
14.3.3.2 Delete
现在考虑删除过程,若删除某个搜索码后,其所在叶子节点的大小小于
⌈
(
n
−
1
)
/
2
⌉
\lceil (n-1)/2 \rceil
⌈(n−1)/2⌉,则需要考虑将节点合并。
以一个具体例子来看删除过程,若在如下图所示的B+树索引中删除搜索码Srinivasan,则其对应的叶子节点(称为节点A)就只剩下一个搜索码值Wu了,在这个例子里
n
=
4
n=4
n=4,则该叶子节点的大小
1
<
⌈
(
4
−
1
)
/
2
⌉
=
2
1 < \lceil (4-1)/2 \rceil=2
1<⌈(4−1)/2⌉=2,需要考虑与其他节点合并。

在这个例子中,被删除搜索码的节点A可以与左边的兄弟节点B合并起来,如下图所示,同时删除父亲节点C中指向节点A的指针与该指针之前的搜索码(因为该搜索码已失效,在这个例子里与被删除的搜索码一样,但就算它与被删除的搜索码不一样也会失效,因为节点合并了)。

此时,父亲节点C也破坏了非叶子节点的性质(包含指针数不少于
⌈
n
/
2
⌉
\lceil n/2 \rceil
⌈n/2⌉,当
n
=
4
n=4
n=4时,这个值为2,但目前节点C的指针数为1),于是父亲节点也需要合并。但是从图中可以看出,此时兄弟节点D已经满了,无法再容纳一个指针,这种情况下的解决方案为在待合并节点C与兄弟节点D之间重新分配孩子指针(注意此处为非叶子节点的重新分配),使得每个节点至少含有
⌈
n
/
2
⌉
\lceil n/2 \rceil
⌈n/2⌉个指针。于是,我们将节点D中的最后一个指针lastPtr移动到节点C中,如下图所示。
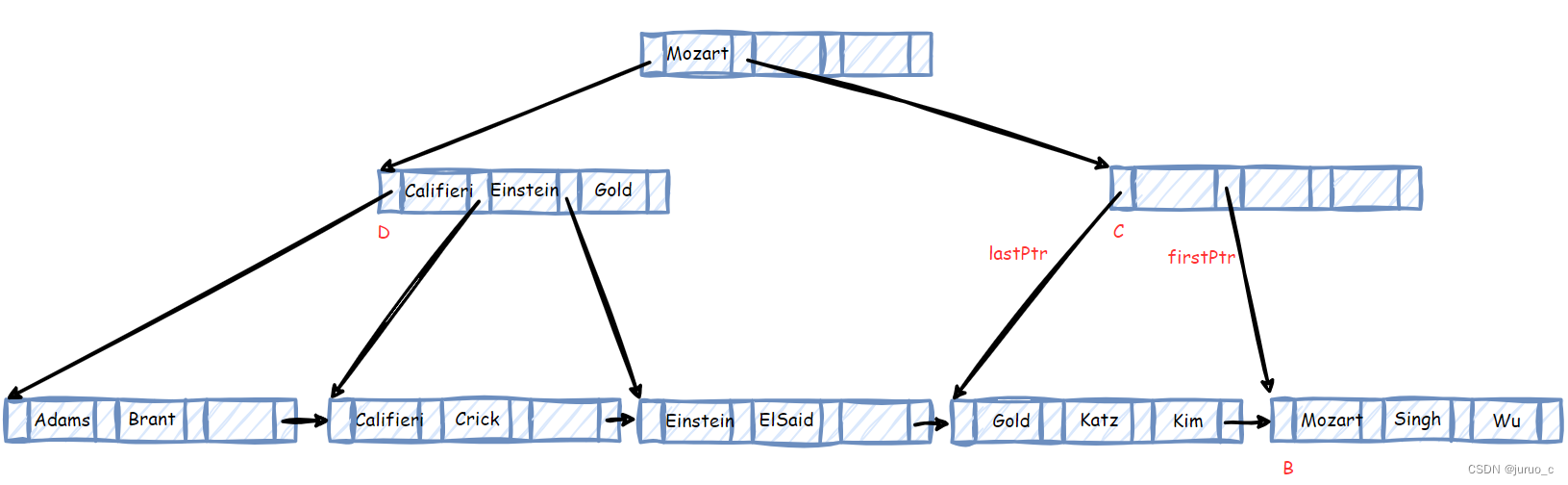
此时我们需要寻找可以将lastPtr和firstPtr隔开的搜索码值,其实,这个搜索码值就是B节点的第一个搜索码Mazart,于是将其放入C节点中,如下图所示。
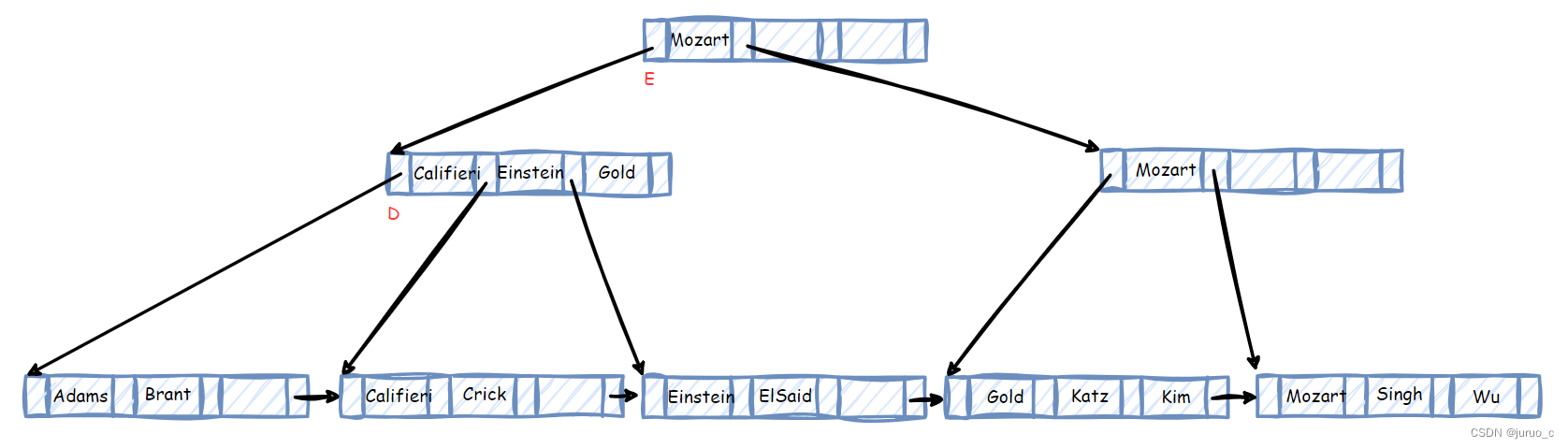
此时,我们发现节点D中的Gold搜索码值无效了,可以将其去掉。同时,节点E中的搜索码值Mazart也不对了,需将其修改为Gold,最终修改结果如下图所示。
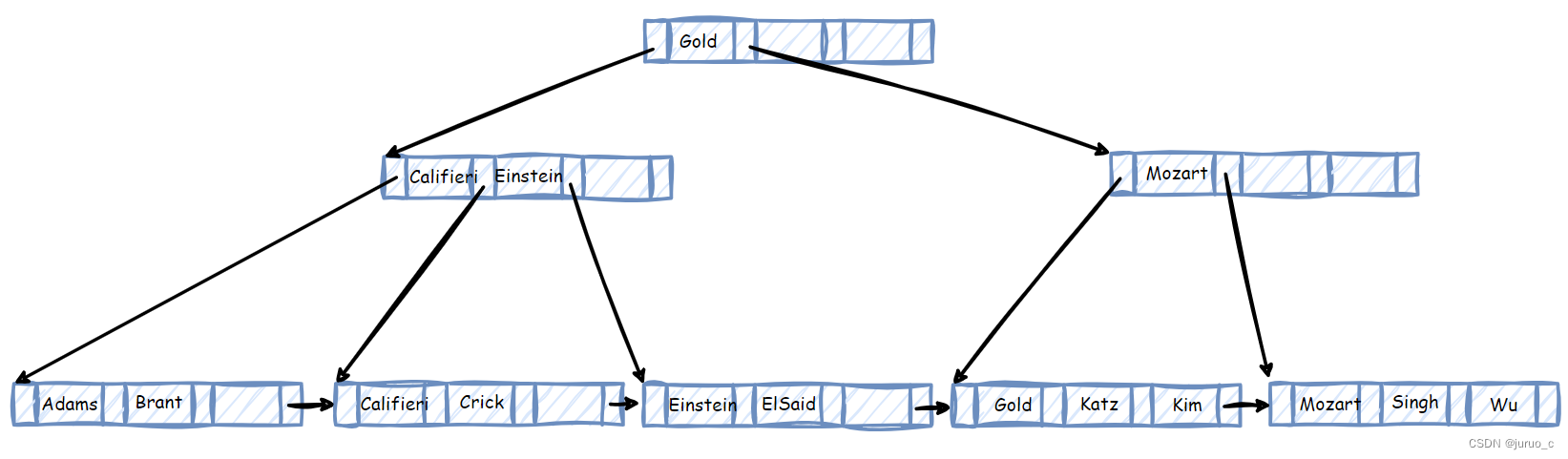
让我们再看一个例子,当我们继续删除搜索码Wu与搜索码Singh时,对应的叶子节点A需要与B合并,但此时B已满,如下图所示。
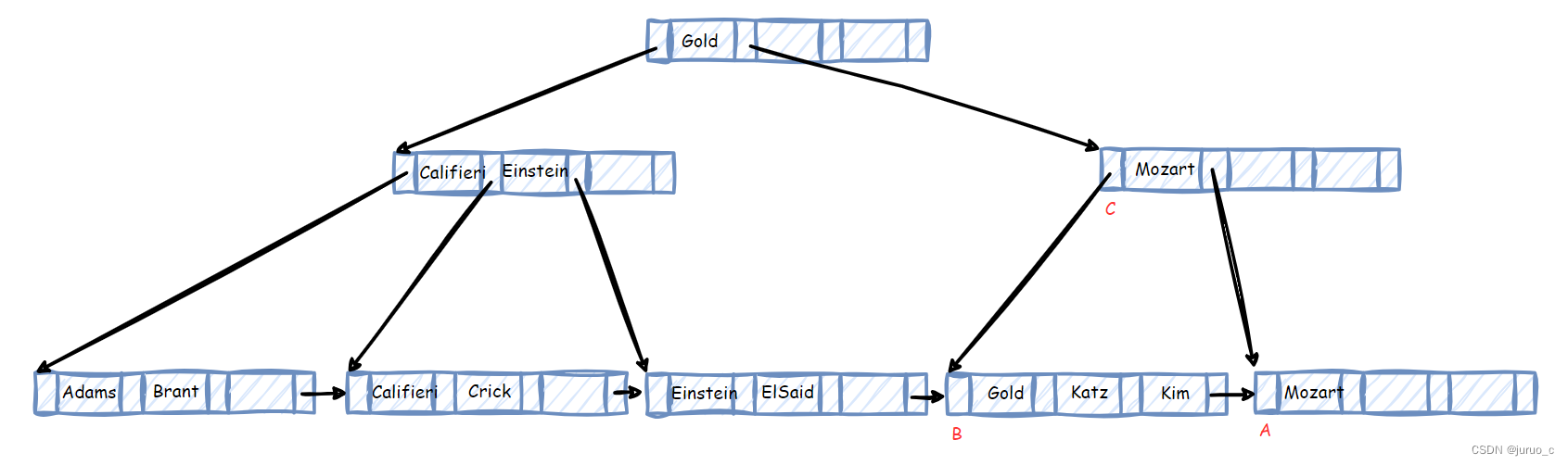
于是我们需要对节点A和节点B做重新分配(注意此处为叶子节点间的重新分配),在这个例子中,我们只需要将Kim及其对应指针(指针没有画出)移动到节点A中,并修改节点C中对应的搜索码值即可,如下图所示。
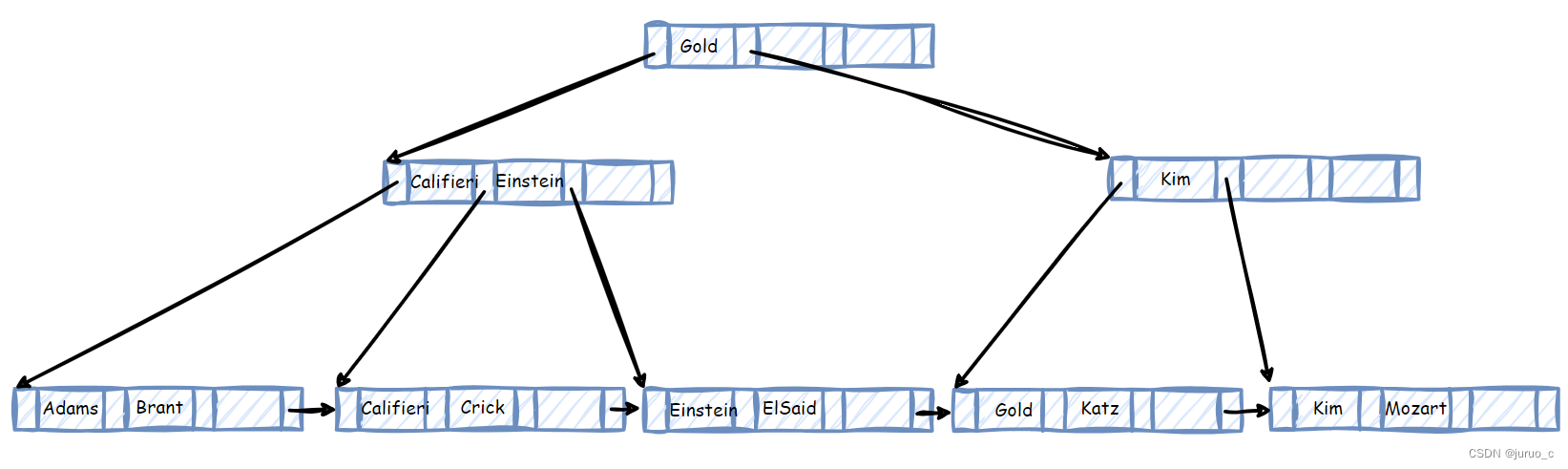
最后,我们再考虑删除搜索码值Gold,叶子节点合并后如下图所示。

此时,父亲节点A指针数目过少,需要进一步合并。由于其兄弟节点B的剩余容量可以容纳A中的所有指针,于是直接将A中的所有指针合入到B中。记一开始节点B中的最后一个指针为lastPtr,节点A中的第一个指针为firstPtr,则合并后这两个指针中间会缺少一个搜索码值,如下图所示。
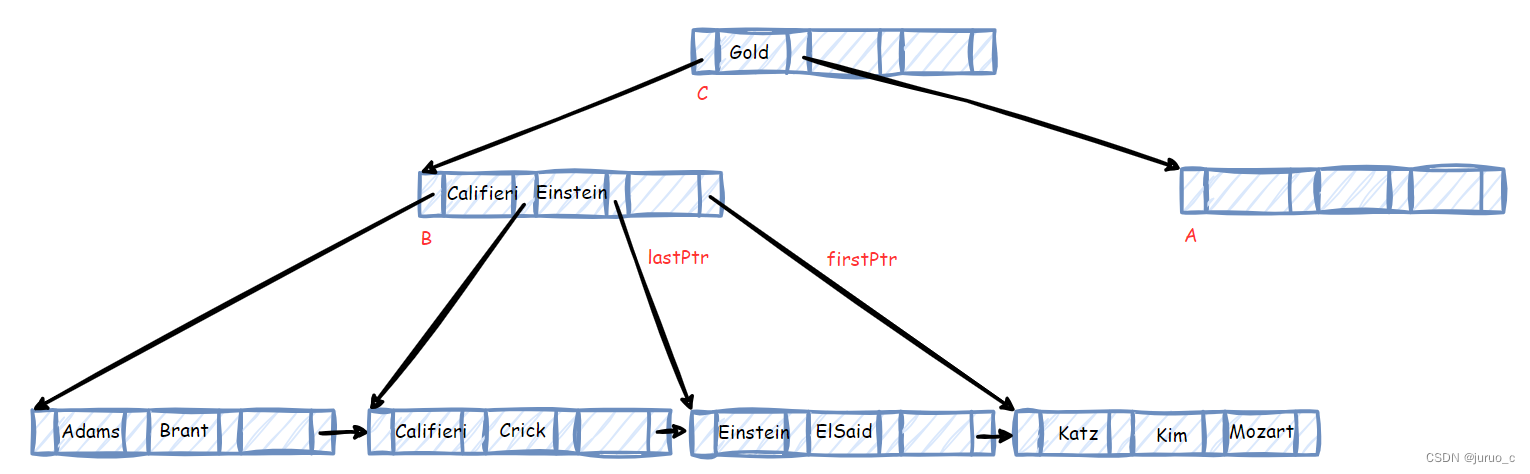
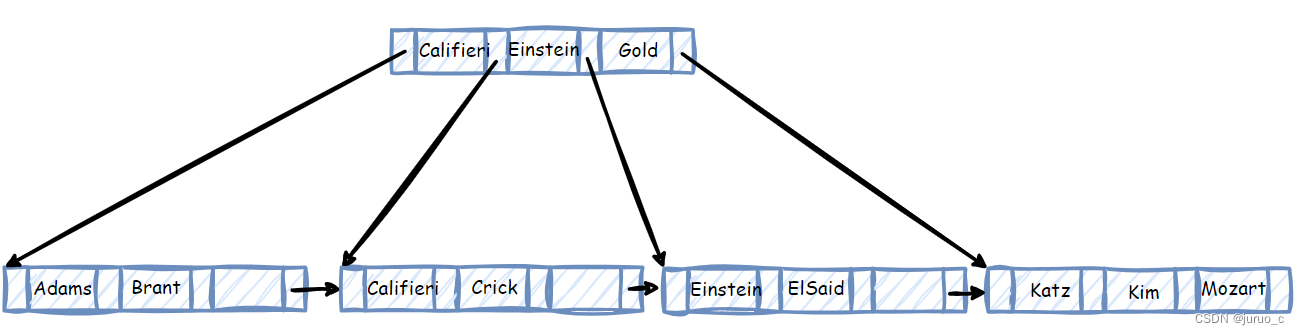
此时可以将A和B的父亲节点C中的Gold做为lastPtr与firstPtr之间的搜索码值(我觉得也可以用firstPtr指向的子节点的第一个搜索码值?这里是Katz)。由于A已为空,故删除,同时删除C中的指针与搜索码值。

但是,此时根节点只剩下一个指针,我们规定根节点至少要有两个指针(因为只有一个指针没啥用啊),于是将根节点也删除,并让它指向的那个儿子作为新的根节点,最终的修改结果如下所示。
最后的最后,我们来总结一下B+树索引的删除流程。
假设通过查询过程,找到被删除搜索码所属的叶子节点为leaf,删除搜索码后,有以下两种情况:
leaf中搜索码值数量少于 ⌈ ( n − 1 ) / 2 ⌉ \lceil (n-1)/2 \rceil ⌈(n−1)/2⌉,需要考虑叶子节点间合并,可以考虑与当前叶子节点leaf的前一个或后一个兄弟节点合并,假设所选择的兄弟节点为brother,他们的父亲节点为father- 若
brother中的剩余容量可以容纳leaf中的所有搜索码值及指针,则可以将leaf节点及father节点中指向leaf节点的指针删除,这会使得father节点包含的指针数量变少,若数量少于 ⌈ n / 2 ⌉ \lceil n / 2 \rceil ⌈n/2⌉会导致非叶子节点上递归的合并,下面再讨论 - 若
brother中的剩余容量不够容纳leaf中的所有搜索码值及指针,则需要在leaf和brother之间进行重新分配,并改变father中的一个搜索码值即可(指向leaf与brother这个两个节点指针中间那个搜索码值),不会改变father节点包含的指针数量,不会导致递归的合并
- 若
leaf中搜索码值数量大于等于 ⌈ ( n − 1 ) / 2 ⌉ \lceil (n-1)/2 \rceil ⌈(n−1)/2⌉,则删除后不需做其他操作
假设需要合并的非叶子节点为node,其兄弟节点为brother,他们的父亲节点为father,则非叶子节点间的合并需要考虑以下情况:
- 若
brother中的剩余容量可以容纳node中的所有指针,则将node中的所有指针合并到brother节点中,对于搜索码值的修改可以参考上面所讲的具体例子,并从父亲节点father中删除指向node的指针,可能导致进一步的递归合并 - 若容量不够,那么重新分配
node与brother之间的指针,假设从brother节点中转移一些指针到node中,此时会使得node中存在一个搜索码空位,需要使用father中的搜索码值,并更新father中的搜索码值,具体过程看之前例子。
个人理解,叶子节点的合并比较简单,因为叶子节点中的搜索码值与指针是一对一的关系,但是非叶子节点相对比较复杂一点,因为搜索码值与指针是一个范围关系。
14.5 Hash Indices
散列索引应用广泛,可以在内存中临时创建以处理join运算,也可以是主存数据库中的永久性结构,还可以是文件中记录的一种组织方式。
14.5.1 In Memory Hash
散列索引的思想比较简单,即维护许多个存放记录的桶,每个桶存放若干条记录的指针。当插入记录时,通过某个哈希函数
h
h
h对记录中的搜索码取哈希值,根据这个哈希值,得到桶编号,将指向该记录的指针放入指定的桶中。
当有多条记录的搜索码哈希值一样时,桶中会存在多条记录,有许多不同的方式处理这种情况,目前我们描述的方式为溢出链方式,即每个桶为一条链表。
散列索引可以高效地支持搜索码上的相等查询,但不支持高效的范围查询。
14.5.2 Disk-Based Hash
在基于磁盘的散列索引中,一个桶可由多个磁盘块组成,当插入一条记录时,与上述一致,先通过哈希函数定位桶,若目标桶仍有空间存放该记录,则存放;若空间不足以存放该记录,通过使用溢出桶来处理,也就是多分配一个桶,然后用链表串起来,如图所示。

大量的桶溢出会导致查询速率变慢,为了处理这个问题,可以采用重构法来解决,即增多桶的数量,将记录重新通过哈希函数映射并插入新的桶中。但是,重构索引的缺点是如果这个relation中的记录数量很多,可能需要很多时间进行重构,可能阻塞事务的进行。
如上所述的方式称为静态散列,即索引创建时桶的数量是固定的;目前还有一些动态散列的方案,将于24.5节讨论。















 2863
2863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









