







一、前置知识
1.File对象: 选择文件时,这些文件被存储在File对象中
2.Blob对象: Blob表示二进制数据,常用来表示大型数据对象(图片、音频)。File对象是Blob对象的一个子类,它继承了Blob对象的所有属性和方法
3.formData对象: 前端(二进制)先将文件存储在formData对象中才能传给后端
const formData = new FormData();
formData.append("file", file);
4.slice方法:
File对象的slice方法是从其父类Blob对象继承来的。用于从文件中提取一段范围的数据.
大文件上传的核心步骤是对文件进行切割成若干个小文件
参数:
- start: 开始提取数据的字节偏移量,默认0
- end: 结束提取数据的字节偏移量,默认为文件或Blob对象的总字节数
- slice方法的返回值是一个新的Blob对象,包含从原始文件或Blob对象中提取的指定字节范围的数据。
5.md5
hash算法可以把任何数据换算成一个固定长度的字符串,这种换算是单向的(数据 -> 字符串)且对数据的变化非常敏感,利用hash算法可以唯一的代表一个文件的整个内容,md5是hash算法中常用的一种。
如何在客户端计算出文件的hash值?
利用spark-md5第三方库
安装:pnpm install spark-md5 --save
引入:import SparkMD5 from ‘spark-md5’
二、问题
- 谁负责资源分块?
- 谁负责资源整合?
- 如何进行资源分块?
- 如何确定前端分块已上传完成?
- 上传失败如何处理?
三、大文件上传思路
1.选择上传资源,判断是否需要符合大文件范围,是否需要大文件上分块上传
2.进行切片,再分片上传
3.考虑断点续传:
上传文件前,请求接口获取文件切片上传状态,获取已上传的切片索引
4.上传完成后,请求合并,告诉服务端整合资源
需要进行多个请求:
检查分片
分片上传
合并分片
四、实现步骤
文件切片:
- 获取File文件对象
- 使用File对象的slice方法提取部分数据(例如,前200KB)
const file = fileInput.files[0];
const sliceBlob = file.slice(0, 1024*200, file.type); // 0~200个字节的内容
1024个字节 = 1KB, 截取前200KB的内容
- 使用FileReader对象读取slicedBlobFileReader对象有一个onload回调函数
const reader = new FileReader();
reader.onload = function(e){
imgElement.src = e.target.result;
imgElement.style.display = "block";
}
reader.readAsDataURL(slicedBlob)
简易流程:
- 设置chunkSize表示切片体积
- 调用file.slice()方法进行切片
- 得到切片后的小文件chunk
- 将chunk添加到formData对象中
- 将formData对象传给后端
const chunkSize = 100 * 1024; // 切片大小 100KB
const totalChunks = Math.ceil(file.size / chunkSize);// 切片数量
for(let i = 0; i < totalChunks; i++) {
const start = i * chunkSize;
// 判断结束字节是否已经大于总体积,获取最小值
const end = Math.min(start + chunkSize, file.size);
const chunk = file.silce(start, end);
const result = await uploadChunk(chunk)
}
async function uploadChunk(chunk){
const formData = new FormData();
formData.append('file', chunk)
}
示例:
const inp = document.querySelector('input');
inp.onchange = async (e) => {
const file = inp.files[0];
if(!file){
return;
}
const chunks = createChunks(file, 10 *1024 * 1024);
const result = await getHash(chunks)
}
// 文件分块
function createChunks(file, chunkSize){
const result = [];
for (let i = 0; i < file.size; i += chunkSize) {
result.push(file.slice(i, i + chunkSize));
}
return result;
}
// 计算文件hash值, chunks 分块数据
function getHash(chunks) {
return new Promise((resolve) => {
const currentChunk = 0;
const spark = new SparkMD5.ArrayBuffer();
function _read(chunkIndex: number) {
if (chunkIndex >= chunks.length) {
// 读取完成
resolve(spark.end());
return;
}
const blob = chunks[chunkIndex];
// 使用FileReader对象读取分块内容
const fileReader = new FileReader();
// FileReader对象有一个onload回调函数
fileReader.onload = function (e) {
const bytes = e.target?.result as ArrayBuffer; // 读取到的字节数;
spark.append(bytes);
chunkIndex++;
_read(chunkIndex);
};
fileReader.readAsArrayBuffer(blob);
}
_read(currentChunk);
});
}
注意: 在计算文件hash时,不推荐一次性计算整个文件的hash值,如果文件过大内容会吃不消,分块计算hash(增量算法)
因为计算的时间较长不回放到主线程中去做,可以利用web worker 单独放到一个线程中去处理,避免浏览器卡死。
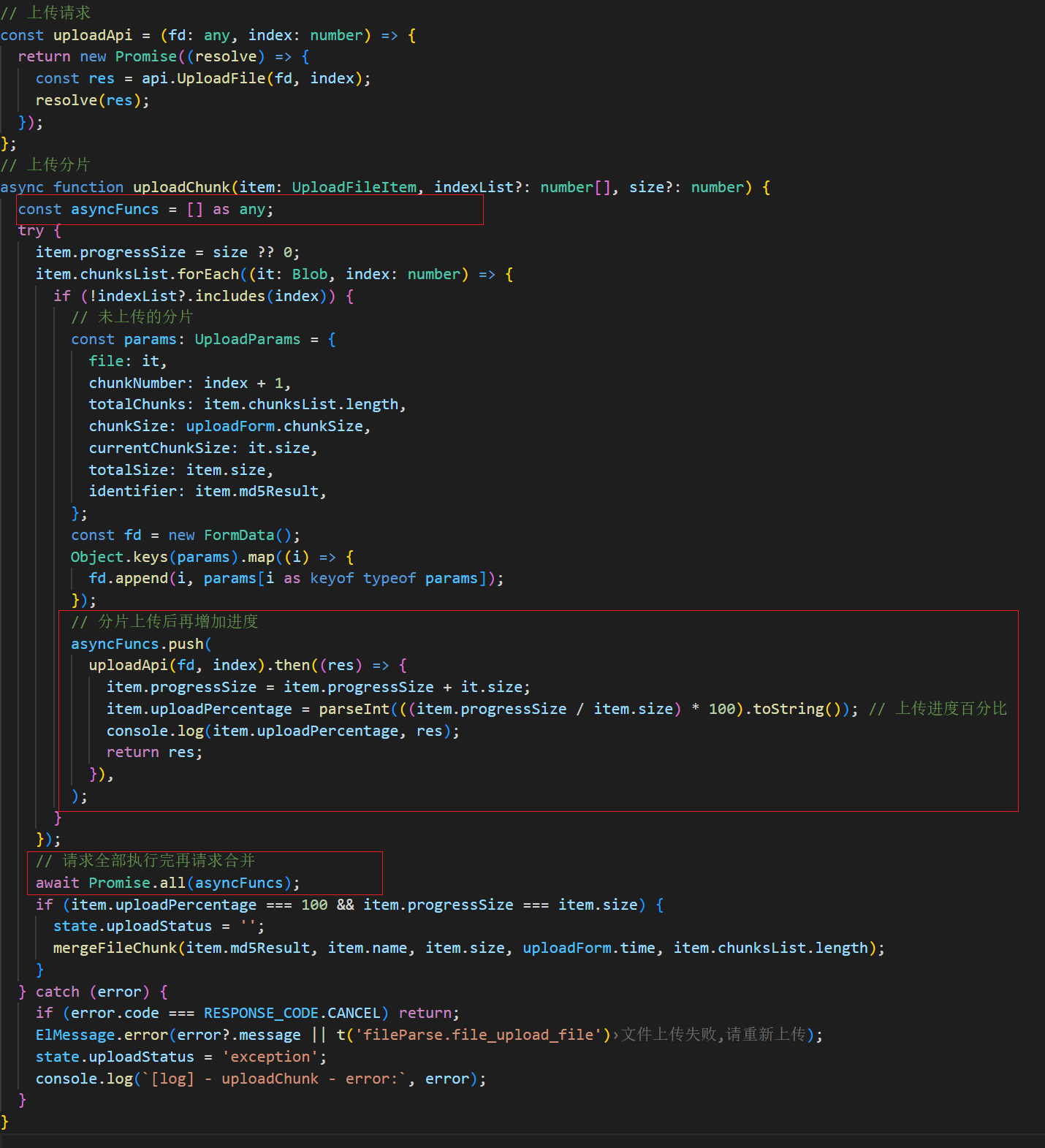
分片上传:
上传分片请求了很多次上传接口,要确保再全部分片上传后再去执行请求合并的方法,用到了Promise.all()方法。且在每一次请求分片执行完后再去计算进度,在uploadAip(fd, index).then()中去计算进度,代码如下:















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









