






本文以环境是linux系统,使用docker容器进行学习,就不再赘述他的简介了.
直接开始:
一、在服务器安装ES
1.安装ElasticSearch:
docker pull elasticsearch:8.7.0
2.创建存储数据目录和配置文件目录
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
3.配置配置文件
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
意思:往elasticsearch.yml文件的末尾添加一行 http.host: 0.0.0.0,即设置 Elasticsearch 监听的网络地址为 0.0.0.0,表示任何 IP 地址都可以访问 Elasticsearch 的 HTTP API。
4.启动
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx128m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:8.7.0
不出意外,肯定会出意外:
容器会启动成功几秒钟然后退出,
原因有好几个:
1.对我们刚刚新建的几个文件没有执行权限,所以我们使用命令:
chmod -R 777 /mydata
即可将这个目录下所有文件给所有人rwx权限
2.我们再查看es容器的启动日志:
使用:docker logs 容器名
发现:Exception in thread "main" java.nio.file.FileSystemException: /usr/share/elasticsearch/config/elasticsearch.yml.jlN6aclDSv2h_bdw2cfTzw.tmp -> /usr/share/elasticsearch/config/elasticsearch.yml: Device or resource busy
读取配置文件出现错误
我们查看配置文件:
貌似并没有问题,确实也没有问题, 因为当我们给目录x权限之后,容器还是无法启动,报这个错误的原因是es8的问题,我们要在配置文件第一行添加:
xpack.security.enabled: false
即可:
配置好了之后,使用:docker rm elasticsearch删除已经启动但失败的这个容器,避免其他影响,在执行一次上面的启动命令,就可以启动成功了!在浏览器访问:服务器ip:9200,可以来到es的home页:



二、基本概念
首先我们先了解几个概念
1.Index(索引)
相当于 MySQL 中的 Database
2.Type(类型)
在 Index (索引)中,可以定义一个或多个类型。类似于 MySQL 中的 Table ;每一种类型的数据放在一起;
3.Document(文档)
文档就是最终的数据了,可以认为一个文档就是一条记录。
是ES里面最小的数据单元,就好比表里面的一条数据
4. Field 字段
类比为表的字段
5.倒排索引机制
倒排索引(Inverted Index)是信息检索领域中常用的数据结构和技术,用于加速文本搜索操作。它是将文档集合中的每个单词映射到包含该单词的文档列表的一种数据结构。这种索引机制的名称“倒排”源于其与传统的正向索引(例如字典)相反,正向索引是将文档映射到单词,而倒排索引则是将单词映射到文档。
倒排索引的基本原理如下:
分词: 首先,对文档集合中的每个文档进行分词,将文本分割成单个的词语(单词或术语)。(比如中国万岁这个单词粗分可以分为:中国和万岁)
建立倒排索引: 对每个词语,记录包含该词语的文档列表。每个文档列表中包含了该词语在对应文档中的位置信息等。这样,可以根据词语来快速找到相关的文档列表。
查询处理: 当用户输入一个查询时,系统会检索查询中包含的每个词语的倒排索引。然后,将这些倒排索引的文档列表进行交集运算,以找到同时包含所有查询词语的文档。这些文档通常是与查询最相关的。
倒排索引的优点在于它可以快速地定位包含特定词语的文档,从而加速文本搜索操作,特别是在大规模文档集合中。然而,构建和维护倒排索引需要一定的计算和存储开销,尤其是在文档集合变动较大时。倒排索引也需要考虑如何处理同义词、拼写错误等问题,以提高搜索的准确性。
倒排索引机制被广泛应用于各种信息检索系统,包括搜索引擎、数据库系统、文本分析工具等,以提供高效的文本搜索和检索功能。

6.安装可视化界面Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS= http://192.168.56.10:9200 -p 5601:5601 -d kibana:8.7.0此处,一定要将ELASTICSEARCH_HOSTS= http://192.168.56.10:9200换成自己es的地址,
7.使用kibana
点击左上角的三条横线打开菜单,找到最底下的Dev Tools

7.1.创建索引
//创建索引
PUT /products//为索引的字段定义映射,这会指定每个字段的数据类型和一些属性。
PUT /products/_mapping
{
"properties":{
"name":{
"type":"text"
},
"price":{
"type":"float"
},
"description":{
"type":"text"
}
}
}
补充:type的类型:
- "string": 存储文本数据,通常被分析为词语以支持全文搜索。
- "integer": 存储整数数据。
- "long": 存储长整数数据。
- "float": 存储单精度浮点数数据。
- "double": 存储双精度浮点数数据。
- "boolean": 存储布尔值数据。
- "date": 存储日期和时间数据。
- "geo_point": 存储地理坐标点数据(经度和纬度)。
- "object": 存储嵌套的 JSON 对象。
- "nested": 存储嵌套的 JSON 对象,支持嵌套查询和聚合。
- "ip": 存储 IPv4 或 IPv6 地址数据。
- "binary": 存储二进制数据。
- “keyword”:表示不被分词器分词的关键字
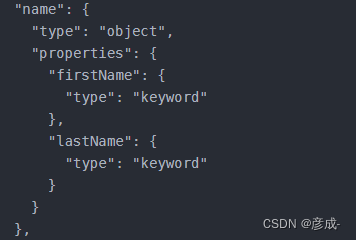
- “object”:即一个对象。对象字段可以嵌套其他字段,如:
跟type平级的属性;
1.通过设置
"index": false,指示 Elasticsearch 不对这个字段建立反向索引。这意味着 "email" 字段不可搜索,但可以用于过滤和聚合。2.
"analyzer": "ik_smart"设置了分析器,使用了中文分词器 "ik_smart",这会将文本内容进行中文分词

当索引创建完毕之后,我们也给他指定好属性之后,,我们就可以在里面添加数据了,不用再创建Type了,这是因为在Elasticsearch 7.0 开始,一个索引只能包含一个固定的文档类型,通常为 "_doc"。在创建索引时,你不再需要显式地指定文档类型,而是将所有类型的文档都存储在同一个 "_doc" 类型下。因此,在你的 "products" 索引中,所有的数据都可以视为商品类型,无需再新建额外的类型。
添加数据:
//添加一条数据,他的id是1
PUT /products/_doc/1
{
"name": "幸福的勇气:阿德勒心理学",
"price": 33.3,
"description": "《幸福的勇气》是勇气两部曲的下卷、完结篇。同样以百年前心理学者阿德勒思想为核心..."
}就是这么简单,你可以多添加几个数据,方便我们等会搜索
补充:
POST 新增。如果不指定 id ,会自动生成 id 。指定 id 就会修改这个数据,并新增版本号PUT 可以新增可以修改。 PUT 必须指定 id ;由于 PUT 需要指定 id ,我们一般都用来做修改操作,不指定 id 会报错。
简单查询;

三、进阶查询
1.ES 支持两种基本方式检索 :
如:
1的例子:查询name为非暴力沟通这本书
GET /products/_search?q=name:非暴力沟通
2.
POST /products/_search
{
"query": {
"match": {
"name": "非暴力沟通"
}
}
}
2.Query DSL
- match
- match_all
- multi_match
- match_phrase
- phrase_prefix
- regexp
他的典型结构:
2.1 查询products下所有
POST /products/_search
{
"query":{
"match_all": {}
}
}
"query"是一个查询语句的容器,在这里我们定义了一个查询。"match_all"是一种查询类型,它会匹配索引中的所有文档。
2.2 分页:
POST /products/_search
{
"query":{
"match_all": {}
},
"from": 0,
"size":5,"_source": ["price"]
}//从0开始,返回0-5的数据
"_source": 控制返回的文档字段。在这个例子中,
"price"是一个字段名称,表示查询结果中只包含文档的price字段。其他字段将被排除在查询结果之外,可以提高查询性能
2.3 match【匹配查询】
POST /products/_search
{
"query":{
"match": {
"price": "33.3"
}
}
}//对于基本类型(非字符串),精确匹配,也就是如果我的索引下没有price=33.3的,将查询不到结果
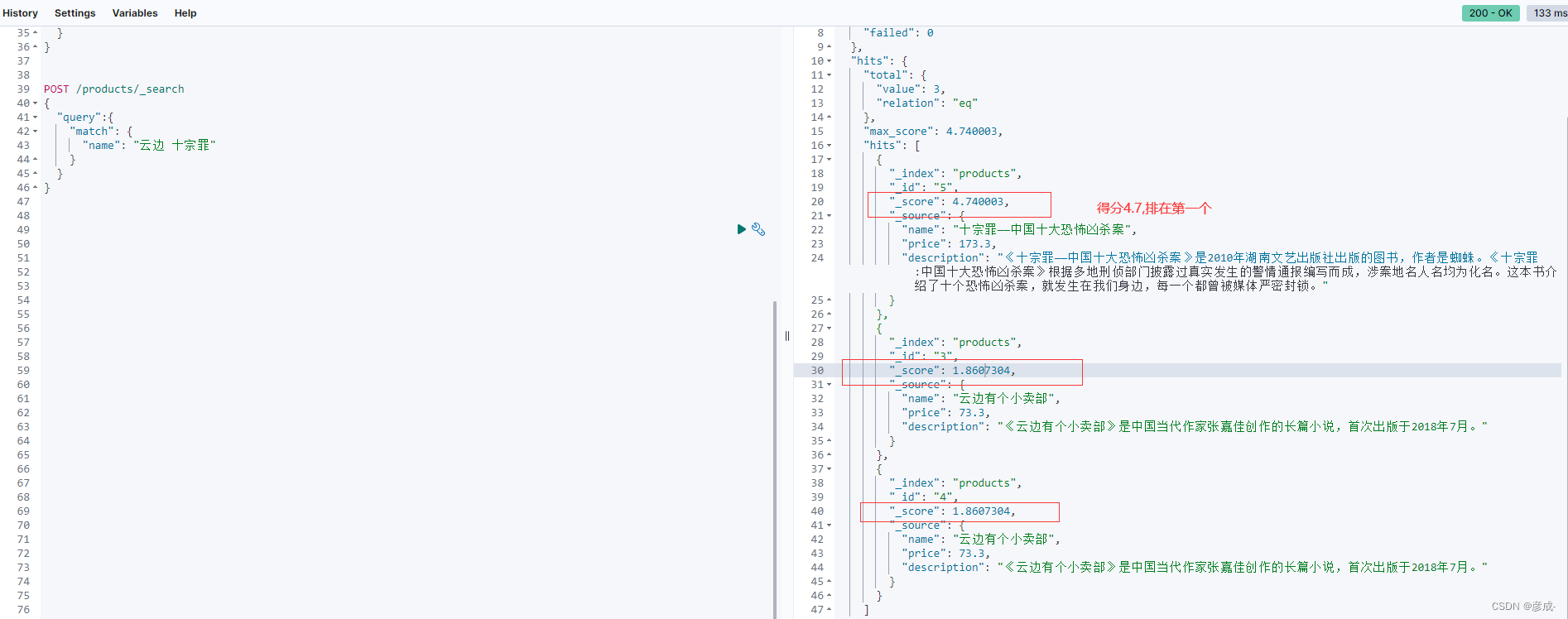
POST /products/_search
{
"query":{
"match": {
"name": "云边 十宗罪"
}
}
}//查询出name字段中包含含有云边或十宗罪的所有记录,并且记录相关性得分
2.4 match_phrase 短语匹配
POST /products/_search
{
"query":{
"match_phrase": {
"name": "云边有个"
}
}
}//此时,name后面的参数将会被当成一个整体,查询name字段中包含"云边有个"的所有记录,假如我们写成2.3例子中的"云边 十宗罪"将会匹配完整匹配"云边 十宗罪",则查询不到结果
2.5 multi_match【多字段匹配】
POST /products/_search
{
"query":{
"multi_match": {
"query": "云边",
"fields": ["name"]
}
}
}//查询name字段中包含"云边"的所有记录
2.6 bool【复合查询】
POST /products/_search
{
"query":{
"bool": {
"must": [
{
"match":
{
"name": "云边"
}
},
{
"match": {
"price": "73.3"
}
}
]
}
}
}//must:必须达到 must 列举的所有条件,
上面这个例子,我们再must里面放入了两个match条件,也就是查询出的记录name字段必须包含"云边"且price字段必须等于73.3
2.6.1 should
POST /products/_search
{
"query":{
"bool": {
"must": [
{
"match":
{
"name": "云边"
}
},
{
"match": {
"price": "73.3"
}
}
],
"should": [
{
"match": {
"name": "云边"
}
}
]
}
}
}//这个例子和2.6一样,只是添加了should条件,添加了这个之后,相关得分从2.8增加到了4.7相关性得分的提高会使这一条记录排名靠前
2.6.2 must_not 必须不是指定的情况
几乎与should一直,就不再举例,唯一不同是不会增加相关性得分
以上都是查询语句
以下都是过滤语句
2.7 filter【结果过滤】
- term
- terms
- range
- exists
2.7.1 term和terms
POST /products/_search
{
"query": {
"bool":{
"filter": [
{
"terms": {
"price": [
"33.3",
"73.3"
]
}
}
]
}
}
}
POST /products/_search
{
"query": {
"bool":{
"filter": [
{
"term": {
"price": "33.3"
}
}
]
}
}
}他会过滤出记录中price字段等于33.3和73.3的记录
2.7.2 range
POST /products/_search
{
"query": {
"bool":{
"filter": [
{
"range": {
"price": {
"gt": 50,
"lt": 100
}
}
}
]
}
}
}这个例子会过滤出所有记录的price字段大于50小于100的记录
2.7.3 exists
POST /products/_search
{
"query": {
"bool":{
"filter": [
{
"exists": {
"field": "name"
}
}
]
}
}
}过滤出name字段有值的记录
2.7.4 ids
POST /products/_search
{
"query": {
"bool":{
"filter": [
{
"exists": {
"field": "name"
}
},
{
"ids": {
"values": [
"1","2","3"
]
}
}
]
}
}
}//过滤出name字段存在的jilu,和id为等于1,2,3的记录
3.聚合函数
POST /products/_search
{
"query": {
"match_all": {}
},
"aggs": {
"avg_prices": {
"avg": {
"field": "price"
}
}
}
}//求出所有记录的平均价格
GET bank/account/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_avg": {
"terms": {
"field": "age",
"size": 1000
},
"aggs": {
"banlances_avg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 1000
}// 按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
4.Mapping
1、字段类型

2.映射
GET /products/_mapping

Es7 及以上移除了 type 的概念。关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但 ES 中不是这样的。 elasticsearch 是基于 Lucene 开发的搜索引擎,而 ES 中不同 type下名称相同的 filed 最终在 Lucene 中的处理方式是一样的。两个不同 type 下的两个 user_name ,在 ES 同一个索引下其实被认为是同一个 filed ,你必须在两个不同的 type 中定义相同的 filed 映射。否则,不同 type 中的相同字段名称就会在处理中出现冲突的情况,导致 Lucene 处理效率下降。去掉 type 就是为了提高 ES 处理数据的效率。Elasticsearch 7.xURL 中的 type 参数为可选。比如,索引一个文档不再要求提供文档类型。Elasticsearch 8.x 不再支持 URL 中的 type 参数。解决:1 )、将索引从多类型迁移到单类型,每种类型文档一个独立索引2 )、将已存在的索引下的类型数据,全部迁移到指定位置即可。详见数据迁移
2.1更新映射
2.2 数据迁移
1.创建新索引和映射PUT /new_products
PUT /new_products/_mapping
{
"properties": {
"description": {
"type": "text"
},
"name": {
"type": "text"
},
"price": {
"type": "float"
},
"addr": {
"type": "keyword"
}
}
}//新映射添加了一个addr属性
2.使用Reindex API进行迁移: 使用Elasticsearch的Reindex API,从旧索引读取数据并将其重新索引到新索引。你可以通过添加一个转换步骤,将数据从旧映射的字段映射到新映射的字段。
他的语法:
POST _reindex
{
"source": {
"index": "old_index"
},
"dest": {
"index": "new_index"
},
"script": {
"source": "ctx._source.addr = ctx._source.location", // 假设将旧的 "location" 字段映射到新的 "addr" 字段
"lang": "painless"
}
}
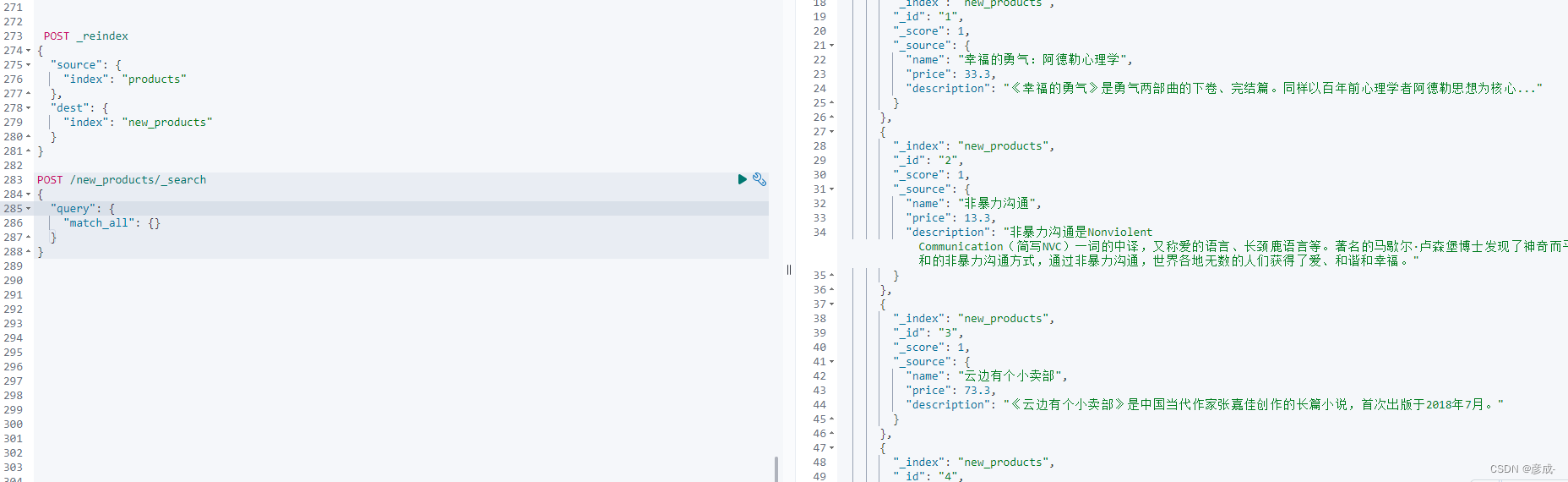
示例:POST _reindex
{
"source": {
"index": "products"
},
"dest": {
"index": "new_products"
}
}
5.分词
四.springBoot整合
1.导入依赖:
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version> </dependency> //此处可能会与springboot版本做的版本规定版本不一致 //在这将elasticsearch.version的版本改为和导的版本一样<properties> <java.version>1.8</java.version> <elasticsearch.version>7.4.2</elasticsearch.version>#这样 </properties>
2.编写配置类,
新建config包,然后创建配置类:ElasticConfig
package com.syctest.test1.conf;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
//设置elasticsearchd的请求的一些参数
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader( "Authorization","Bearer " +TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 *1024 * 1024));
COMMON_OPTIONS = builder.build();
}
public RestHighLevelClient elasticClint(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")));
return client;
}
}
使用:
case1:查询
@Autowired
RestHighLevelClient client;
@GetMapping("/test1")
public Result test1() throws IOException {
System.out.println("--被访问--");
// 1.创建检索请求
SearchRequest searchRequest = new SearchRequest();
//设置在索引下进行查询new_products
searchRequest.indices("new_products");
// 2.创建条件构造器(DSL)
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(AggregationBuilders.terms("price").field("price").size(10));
//查看price的平均值
builder.aggregation(AggregationBuilders.avg("avePrice").field("age"));
//其他条件
builder.query(QueryBuilders.matchQuery("name","云边"));
//当你要使用其他,如matchall等,直接使用QueryBuilders点他的名称即可:QueryBuilders.matchAllQuery()
// 3.执行查询
searchRequest.source(builder);
SearchResponse search = client.search(searchRequest, ElasticConfig.COMMON_OPTIONS);
System.out.println(search);
//4.分析结果:
//{"took":17,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},
// "hits":{"total":{"value":2,"relation":"eq"},"max_score":2.2864978,
// "hits":[{"_index":"new_products","_id":"3","_score":2.2864978,
// "_source":{"name":"云边有个小卖部","price":73.3,
// "description":"《云边有个小卖部》是中国当代作家张嘉佳创作的长篇小说,首次出版于2018年7月。"}},
// {"_index":"new_products","_id":"4","_score":2.2864978,
// "_source":{"name":"云边有个小卖部","price":73.3,"description":"《云边有个小卖部》是中国当代作家张嘉佳创作的长篇小说,首次出版于2018年7月。"}}]},
// "aggregations":{"sterms#agePrice":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[]}}}
//4.1获取所有命中的记录
SearchHits hits = search.getHits();
//查询出来的数据
SearchHit[] hits1 = hits.getHits();
for (SearchHit documentFields : hits1) {
/*_index:属于哪个索引
* _id:唯一id
* _score:得分
* _source:真正存进去的java对象
* */
System.out.println(documentFields.getIndex());
System.out.println(documentFields.getId());
Map<String, Object> sourceAsMap = documentFields.getSourceAsMap();//返回键值对
String sourceAsString = documentFields.getSourceAsString();//返回json字符串
System.out.println(sourceAsString);
// 将json转为我们需要的对象
}
//4.2获取这次的聚合函数分析的结果
Aggregations aggregations = search.getAggregations();
//获取我们命名的聚合,可以直接使用Terms对象接收
Terms ageAgg = aggregations.get("price");
for (Terms.Bucket bucket : ageAgg.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("keyAsString:"+keyAsString);
}
Avg avgAgg = aggregations.get("avePrice");
System.out.println("平均年龄:"+ avgAgg.getValue());
System.out.println(search);
return Result.success(null);
} @GetMapping("addData")
public Result addData() throws IOException {
//设置要插入数据的索引
IndexRequest indexRequest = new IndexRequest("new_products");
//设置这条数据的id,不设置的话会自动生成一个唯一的id
indexRequest.id("12");
//携带数据的方式
//1.
// indexRequest.source("name","三国演义","price",18.1,"addr","天津印刷//厂","description","关羽张飞刘备");
//2.创建对象,将其转为jSON格式的字符串,然后将json字符串作为哦source的内容传过去
User user = new User("syc1",18,"男");
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writeValueAsString(user);
indexRequest.source(s, XContentType.JSON);
//3创建map,存储键值对
// HashMap<String, String> map = new HashMap();
// map.put("userName","syc");
// map.put("age","18");
// map.put("sex","男");
//执行操作
IndexResponse index = client.index(indexRequest, ElasticConfig.COMMON_OPTIONS);
return Result.success(index);
}方式2最常用














 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









