







一,联合查询
1.基本概念
是可以合并多个相似选择查询的结果集,等同于将一个表追加到另一个表,从而事先将两个表的查询组合到一起,使用union或者union all。
联合查询:将多个查询的结果合并到一起,纵向合并,字段数不便,多个查询的记录数合并。
2.应用场景
- 将同一张表中不同的结果(需要对应多条查询语句来实现),合并到一起展示。
男生身高升序,女生身高降序。
- 常见:在数据量大的情况下,会对表进行分表操作,需要对每张表进行部分统计,使用联合查询将数据放到一起展示。
3.基本语法
Select 语句 + union (union选项)+select 语句
union选项:与select选项基本一致
all:保留所有结果
distinct:去重,去掉完全重复的数据(默认的)
男生身高升序,女生身高降序
select * from my_student where sex='男' ORDER BY heigh asc;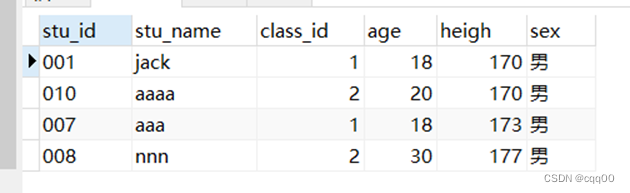
select * from my_student where sex='女' ORDER BY heigh desc; 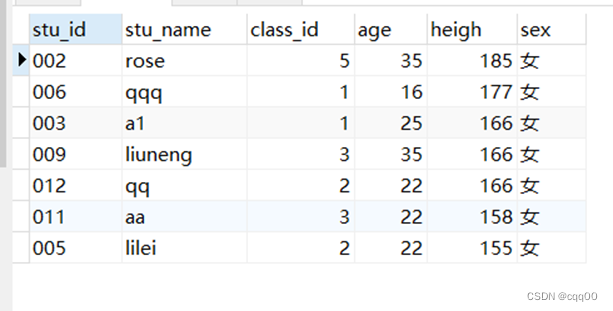
细节:在联合查询中,如果要使用order by 那么对应的select语句必须要用括号括起来
(select * from my_student where sex='男' ORDER BY heigh asc)
UNION (all)
(select * from my_student where sex='女' ORDER BY heigh desc);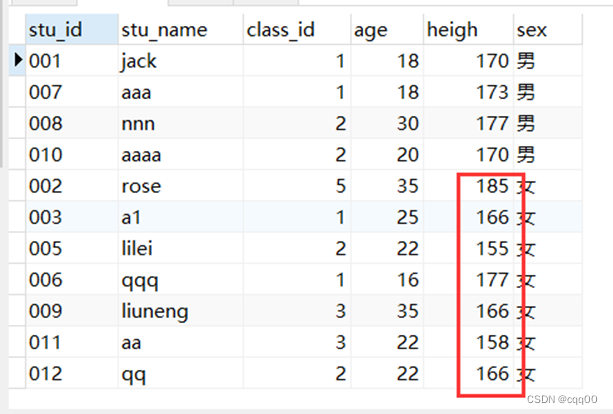
排序问题没有解决
Order by在联合查询若要生效,必须配合使用limit,而limit后面必须要跟对应的限制数量,通常我们可以使用一个较大的值,大于对应的记录数。
(select * from my_student where sex='男' ORDER BY heigh asc LIMIT 12)
UNION
(select * from my_student where sex='女' ORDER BY heigh desc limit 12);问题解决。
二, 连接查询
将多张表连到一起进行查询,会导致记录数行和字段列 发生变化。
意义:在关系模型数据库设计过程中,表与表之间存在很多关系。
在关系模型数据库表的设计过程中,遵循则表关系来设计,一对一,一对多,多对多,通常在实际操作中,需要利用这层关系来保证数据的完整性。
1.交叉连接
定义:把两张表的数据与另外一张表彼此交叉。
原理:从第一张表中一次取出每一条数据记录,取出之后与另外一张表的全部记录依次匹配,最终把所有的结果全部进行保留,记录数=第一张表的记录数*第二张表的记录数,字段是=第一张表的字段数+第二张表的字段数
语法:select from 表1 cross join 表2;
应用:产生笛卡尔积,没有实际应用,避免。
本质与select from 表1,表2没有区别。
2.内连接
Inner join:从一张表中取出所有记录与另外一张表匹配,利用匹配条件,进行过滤,匹配成功则保留,失败则放弃。
原理:从第一张表中取出一条记录,去另外一张表匹配,匹配到,保留,继续向下匹配,失败,继续向下匹配,如果全部匹配都失败,则没有结果。
语法: 表1 inner join 表2 on 匹配条件
查询所有学生信息,包含班级信息
select my_student.*,my_class.class_name from my_student
INNER join my_class on my_student.class_id=my_class.class_id;内连接通常是在对数据有精确要求的时候使用,必须保证两张表中都有符合要求的数据,如果没有on,内连接就是交叉连接,内连接因为不强制必须使用匹配条件,因此我们可以在查询数据后使用where条件,效果一样,但是推荐使用on,因为效率高。
3.外连接
左外连接,又称为左连接。
右外连接,又称为右连接。
Outer join :按照某一张表作为主表,(主表的所有字段最后都会保留,)根据条件去连接另外一张表,分为左连接、右连接。
原理:确定连接主表,左连接 left join 左边的表为主表,右连接 right join是右边的表为主表,拿主表的每条记录去匹配另外一张表(从表)每条记录。如果满足条件,保留,否则不放入内存中。但是如果主表在从表中一条记录都没有匹配成功,那么这条记录依然会被保留,从表对应的字段都为null
语法: 主表 left join 从表 on 匹配条件
从表 right join 主表 on 匹配条件
特点:主表数据记录一定会被保存。连接之后,不会出现记录数少于主表的情况。内连接有可能。
select s.*,c.class_name from my_student s
LEFT join
my_class c on s.class_id=c.class_id; //没有5班
select s.*,c.class_name from my_student s
right join
my_class c on s.class_id=c.class_id; //没有class_id为5的学生 因为匹配不上
select s.*,c.class_name from my_student s
inner join
my_class c on s.class_id=c.class_id; //既没有class_id为5的学生也没有4班应用:非常常用的一种获取数据的方式,作为数据获取对应的主表以及其他关联数据的重要方式。
左右连接可以互换。
作业:以上sql尝试左右连接互换达到同样效果。
4.自然连接
自然连接:natural join是一种特殊的并连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且结果集中把重复的属性列去掉。
如果A表中有a,b,c字段,B表中有c,d字段,则select * from A natural join B相当于
Select A.a,A.b,A.c,B.d from A join B on A.c=B.c
5.Using
是在连接查询中用来代替on关键字的,进行条件匹配。
原理:在连接查询时,使用on的地方使用 using
使用using的前提是对应的两张表连接的字段是同名的,自然连接自动匹配
如果使用using关键,对应的同名字段,最终只保留一个
语法:表1 (inner,left,right) join 表2 using (同名字段)
select * from my_student
LEFT join my_class USING(class_id);三,子查询
1.子查询概念
子查询:sub query
子查询是一种常用计算机语言,select sql语言中,嵌套查询下层的程序模块,当一个查询是另外一个查询的条件时,称之为子查询。
子查询:指在一条select语句中,嵌入了另外一条select语句,那么被嵌入的select语句称之为子查询语句。子查询语句是可以独立运行的。
主查询概念
主查询:主要的查询对象,第一条select语句,确定了用户所有获取的数据目标(从数据源)
以及要得到的字段信息。
子查询和主查询的关系
- 子查询是嵌入到主查询中的
- 子查询是为了辅助主查询,要么作为条件,要么作为数据源。
- 子查询其实是可以独立存在的,它本身就是一条完整的select语句,可以独立运行。
- 主查询决定最终结果,子查询是作为辅助条件
2.子查询分类
按照功能分
标量子查询:子查询返回的结果是一个数据,一行一列。
列子查询:子查询返回的结果是一列,一列多行。
行子查询:子查询返回的结果是一行,一行多列。
表子查询:返回的结果是多行多列。、
Exists子查询:返回的结果是1或者0类似于boolean布尔。
按照位置分
Where子查询:子查询出现的位置在where条件中
From子查询:子查询出现的位置在from数据源之后,作为数据源(常用)
3.标量子查询
概念:子查询返回的结果是一个数据,一行一列。
语法
Select * from 数据源 where 条件判断 =/<> (select 字段名 from 数据源 where 条件判断) //子查询的结果只有一个值
知道一个学生的名字,XXX得到他所在的班级名字
1.通过学生获取他所在的班级id
2.通过班级id找到对应的班级名字
select * from my_class where class_id=
(select class_id from my_student where stu_name='jack');需求决定主查询,条件决定子查询。
4.列子查询
概念:列子查询:子查询返回的结果是一列,一列多行。
语法: 主查询 where 条件 in (列子查询)
想获取已有学生在班的所有班级名称
1.找出学生表中所有的班级id
2.找对对应班级的名字
班级是否有学生,如果这个班级的id在学生表中出现过,那么一定可以确定有学生
select class_name from my_class where class_id in
(select class_id from my_student);5.行子查询
概念:子查询返回的结果是一行,一行多列。
行元素:字段元素是指一个字段对应的值,行元素对应的就是多个字段,多个字段合起来作为一个元素参与运算,把这种情况称之为行元素。
语法:
主查询 where 条件 (构造一个行元素) = 子查询
获取班级上年龄最大,且身高最高的学生。
1.求出班级上年龄最大的值
2.求出班级上身高最高的值
3.求出对应的学生。
select * from my_student where age=max(age) and heigh=max(heigh);
--报错 where不能使用聚合函数
select * from my_student having age=max(age) and heigh=max(heigh);
--having是在group by之后,使用having就代表前面的group by执行了一次
那如果执行了group by结果就只返回第一行
select * from my_student where (age,heigh) =
(select max(age),max(heigh) from my_student);目前学习了3个子查询,标量、列、行子查询,都属于where子查询。
6.表子查询
概念:子查询返回的结果是多行多列。也有可能是一行一列。表子查询与行子查询长的类似,只是行子查询需要构建行元素,表子查询没有。行子查询是用作条件,而表子查询是用作数据源。
语法
Select 字段列表 from (表子查询) as 别名 (where group by having order by limit)
获取每个班级上身高最高的学生(只保留一个)
1.将每个班级最高学生排到最前面 order by
2.再针对结果进行group by 分组
select * from my_student order by heigh desc;
select * from (select * from my_student order by heigh desc) a GROUP BY a.class_id;7.exist子查询
概念:返回的结果是1或者0类似于boolean布尔。
Where exists (查询语句) //exixts就是根据查询得到的结果进行判断,如果结果存在,那么返回1,否则返回0
求出有学生在班的所有班级
select * from my_class c where EXISTS
(select class_id from my_student s where s.class_id=c.class_id);8.特数字
In
主查询 where in (列子查询)
Any
任意一个
=any (列子查询):条件在查询结果中有任意一个匹配即可,等价于in
<>any (列子查询):条件在查询结果中不等于任意一个
1=any(1,2,3); //true
1<>any(1,2,3); //true 不等于其中任意一个 所以返回了true
select * from my_student where class_id in (select class_id from my_class);
select * from my_student where class_id =any (select class_id from my_class);
select * from my_student where class_id <>any (select class_id from my_class);Some
与any完全一样,英语中some与any的正面含义一致,但是否定就大不相同,not some与not any不一样,一些和一点也不
开发者为了让对应的使用者在语法上不纠结,重新设计了some。
All
=all(子查询):等于所有
<>all(子查询):不等于所有
select * from my_student where class_id =all (select class_id from my_class); --无结果
select * from my_student where class_id <>all (select class_id from my_class); --5班
select * from my_class where class_id =all (select class_id from my_student); --无结果
select * from my_class where class_id <>all (select class_id from my_student); --4班















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











