






尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
1.谈谈你对MySQL联合索引的认识?
2.在MySQL中,联合索引是如何实现的?请简述其工作原理。
3.什么是最左前缀匹配原则?为什么要遵守?
4.MySQL一定要遵循最左前缀匹配吗?
最近有小伙伴在面试 贝壳、soul,又遇到了相关的面试题。小伙伴懵了,因为没有遇到过,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V171版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,回复:领电子书
联合索引 和 mysql 调优的关系
mysql 调优 的一个核心动作,就是 通过 联合索引 实现 索引覆盖。
在MySQL中,合理使用联合索引可以提高查询效率,通过 联合索引 实现 索引覆盖 ,常常需要注意一些技巧:
- 选择合适的列: 联合索引的列顺序非常重要。应该优先选择最频繁用于查询条件的列,以提高索引的效率。其次考虑选择性高的列,这样可以过滤出更少的数据。
- 避免冗余列: 联合索引的列应该尽量避免包含冗余列,即多个索引的前缀相同。这样会增加索引的维护成本,并占用更多的存储空间。
- 避免过度索引: 不要为每个查询都创建一个新的联合索引。应该根据实际情况,分析哪些查询是最频繁的,然后创建针对这些查询的索引。
- 覆盖索引: 如果查询的列都包含在联合索引中,并且不需要访问表的其他列,那么MySQL可以直接使用索引来执行查询,而不必访问表,这种索引称为覆盖索引,可以提高查询性能。
- 使用EXPLAIN进行查询计划分析: 使用MySQL的EXPLAIN语句可以查看MySQL执行查询的执行计划,以便优化查询语句和索引的使用。
- 定期优化索引: 随着数据库的使用,索引的效率可能会下降,因此需要定期进行索引的优化和重建,以保持查询性能的稳定性。
- 分析查询日志: 监控数据库的查询日志,分析哪些查询是最频繁的,以及它们的查询模式,可以帮助确定需要创建的联合索引。
- 避免过度索引更新: 避免频繁地更新索引列,因为每次更新索引都会增加数据库的负载和IO操作。
综上所述,联合索引是mysql 调优的一个核心动作, 通过 联合索引进行mysql 调优时,需要综合考虑列的选择、索引的覆盖、查询的频率和模式等因素,以提高MySQL数据库的查询性能。
正因为如此, 联合索引 是面试的重点和难点。
回答这个面试题,我们可以从最为基础的MySQL索引机制 开始讲起。
基础知识:MySQL索引机制
数据库索引,官方定义如下
在关系型数据库中,索引是一种单独的、物理的数据,对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合,以及相应的指向表中物理标识这些值的数据页的逻辑指针清单。
通俗的理解为
在关系型数据库中,索引是一种用来帮助快速检索目标数据的存储结构。
索引的创建
MySQL可以通过CREATE、ALTER、DDL三种方式创建一个索引。
- 使用CREATE语句创建
CREATE INDEX indexName ON tableName (columnName(length) [ASC|DESC]);
- 使用ALTER语句创建
ALTER TABLE tableName ADD INDEX indexName(columnName(length) [ASC|DESC]);
- 建表时DDL语句中创建
CREATE TABLE tableName(
columnName1 INT(8) NOT NULL,
columnName2 ....,
.....,
INDEX [indexName] (columnName(length))
);
索引的查询
SHOW INDEX from tableName;
索引的删除
ALTER TABLE table_name DROP INDEX index_name;
DROP INDEX index_name ON table_name;
MySQL联合索引
什么是联合索引
联合索引(Composite Index)是一种索引类型,它由多个列组成。
MySQL的联合索引(也称为复合索引)是建立在多个字段上的索引。这种索引类型允许数据库在查询时同时考虑多个列的值,从而提高查询效率和性能。
- 联合索引:也称复合索引,就是建立在多个字段上的索引。联合索引的数据结构依然是 B+ Tree。
- 当使用(col1, col2, col3)创建一个联合索引时,创建的只是一颗B+ Tree,在这棵树中,会先按照最左的字段col1排序,在col1相同时再按照col2排序,col2相同时再按照col3排序。
联合索引存储结构
联合索引是一种特殊类型的索引,它包含两个或更多列。
在MySQL中,联合索引的数据结构通常是B+Tree,这与单列索引使用的数据结构相同。
当创建联合索引时,需要注意列的顺序,因为这将影响到索引的使用方式。
如下图所示,表的数据如右图,ID 为主键,创建的联合索引为 (a,b),注意联合索引顺序,下图是模拟的联合索引的 B+ Tree 存储结构
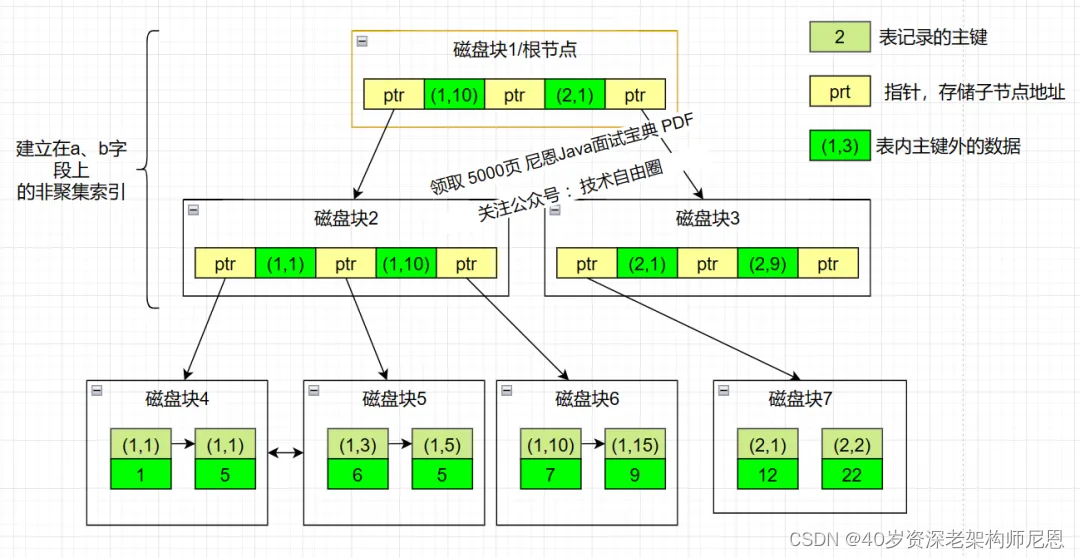
最左前缀匹配原则
联合索引还是一颗B+树,只不过联合索引的健 数量不是一个,而是多个。
构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
假如创建一个(a,b)的联合索引,联合索引B+ Tree结构如下:
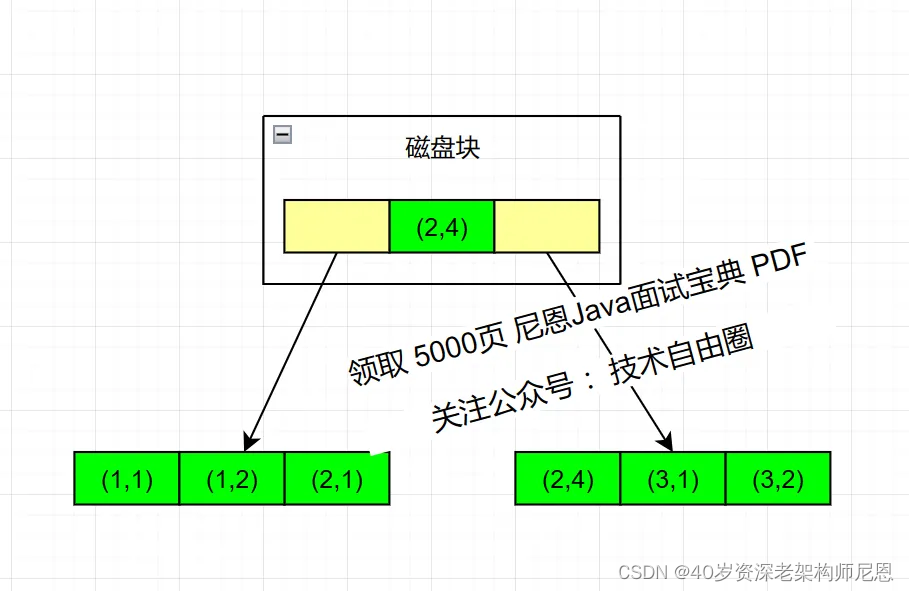
结合上述联合索引B+ Tree结构,可以得出如下结论:
1.a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。
所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
2.当a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。
所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。
例如a = 1 and b = 2 ,a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
最左匹配原则:
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
下面我们以建立联合索引(a,b,c)为例,进行详细说明
1 全值匹配查询时
下述SQL会用到索引,因为where子句中,几个搜索条件顺序调换不影响查询结果,因为MySQL中有查询优化器,会自动优化查询顺序。
select * from table_name where a = '1' and b = '2' and c = '3'
select * from table_name where b = '2' and a = '1' and c = '3'
select * from table_name where c = '3' and b = '2' and a = '1'
2 匹配左边的列时
下述SQL,都从最左边开始连续匹配,用到了索引。
select * from table_name where a = '1'
select * from table_name where a = '1' and b = '2'
select * from table_name where a = '1' and b = '2' and c = '3'
下述SQL中,没有从最左边开始,最后查询没有用到索引,用的是全表扫描。
select * from table_name where b = '2'
select * from table_name where c = '3'
select * from table_name where b = '1' and c = '3'
下述SQL中,如果不连续时,只用到了a列的索引,b列和c列都没有用到
select * from table_name where a = '1' and c = '3'
3 匹配列前缀
如果列是字符型的话它的比较规则是先比较字符串的第一个字符,第一个字符小的哪个字符串就比较小,如果两个字符串第一个字符相通,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小,依次类推,比较字符串。
如果a是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描了
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询
select * from table_name where a like '%As'; //全表查询
select * from table_name where a like '%As%'; //全表查询
4 匹配范围值
下述SQL,可以对最左边的列进行范围查询
select * from table_name where a > 1 and a < 3
多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引。
在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤。
select * from table_name where a > 1 and a < 3 and b > 1;
5 精确匹配某一列并范围匹配另外一列
如果左边的列是精确查找的,右边的列可以进行范围查找,如下SQL中,a=1的情况下b是有序的,进行范围查找走的是联合索引
select * from table_name where a = 1 and b > 3;
6 排序
一般情况下,我们只能把记录加载到内存中,再用一些排序算法,比如快速排序,归并排序等在内存中对这些记录进行排序,有时候查询的结果集太大不能在内存中进行排序的话,还可能暂时借助磁盘空间存放中间结果,排序操作完成后再把排好序的结果返回客户端。
Mysql中把这种再内存中或磁盘上进行排序的方式统称为文件排序。文件排序非常慢,但如果order子句用到了索引列,就有可能省去文件排序的步骤
select * from table_name order by b,c,a limit 10;
因为b+树索引本身就是按照上述规则排序的,所以可以直接从索引中提取数据,然后进行回表操作取出该索引中不包含的列就好了,order by的子句后面的顺序也必须按照索引列的顺序给出,比如下SQL:
select * from table_name order by b,c,a limit 10;
在以下SQL中颠倒顺序,没有用到索引
select * from table_name order by a limit 10;
select * from table_name order by a,b limit 10;
以下SQL中会用到部分索引,联合索引左边列为常量,后边的列排序可以用到索引
select * from table_name where a =1 order by b,c limit 10;
为什么要遵循最左前缀匹配?
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
如下,我们以age,name两个字段建立一个联合索引,非叶子节点中记录age,name两个字段的值,而叶子节点中记录的是age,name两个字段值及主键Id的值,在MySQL中B+ Tree 索引结构如下:
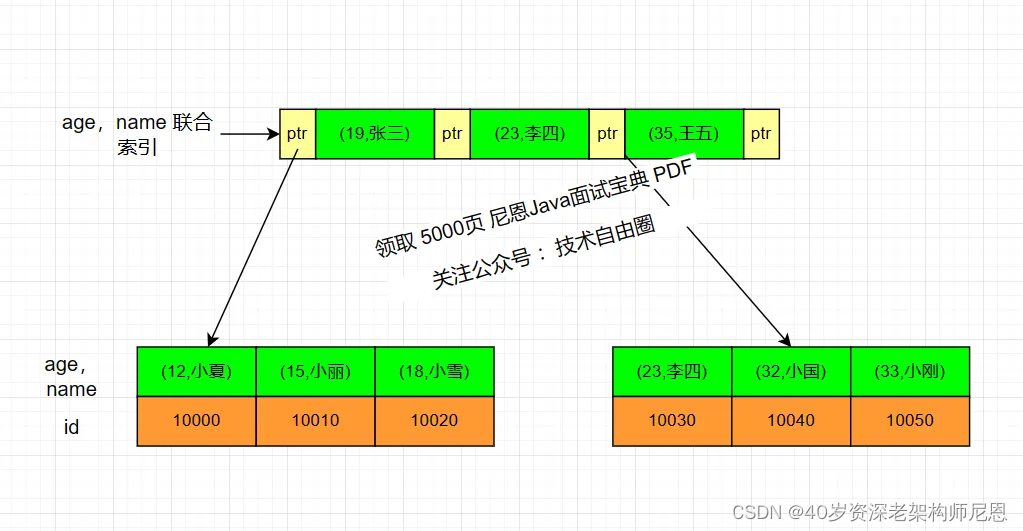
在上述联合索引存储数据过程中,首先会按照age排序,当age相同时则按照name排序。
-
结合上述索引结构,可以看出联合索引底层也是一颗B+Tree,在联合索引中构造B+Tree的时候,会先以最左边的key进行排序,如果左边的key相同时,则再依次按照右边的key进行排序。
-
所以在通过索引查询的时候,也需要遵守最左前缀匹配的原则,也就是需要从联合索引的最左边开始进行匹配,这时候就要求查询语句的where条件中,包含最左边的索引的值。
一定要遵循最左前缀匹配吗?
最左前缀匹配原则,也就是SQL的查询条件中必须要包含联合索引的第一个字段,这样才能命中联合索引查询,但实际上这条规则也并不是100%遵循的。
因为在MySQL8.x版本中加入了一个新的优化机制,也就是索引跳跃式扫描,这种机制使得咱们即使查询条件中,没有使用联合索引的第一个字段,也依旧可以使用联合索引,看起来就像跳过了联合索引中的第一个字段一样,这也是跳跃扫描的名称由来。
我们来看如下例子,理解一下索引跳跃式扫描如何实现的。
比如此时通过(A、B、C)三个列建立了一个联合索引,此时有如下一条SQL:
SELECT * FROM table_name WHERE B = `xxx` AND C = `xxx`;
按正常情况来看,这条SQL既不符合最左前缀原则,也不具备使用索引覆盖的条件,因此绝对是不会走联合索引查询的。
但这条SQL中都已经使用了联合索引中的两个字段,结果还不能使用索引,这似乎有点亏啊?
因此MySQL8.x推出了跳跃扫描机制,但跳跃扫描并不是真正的“跳过了”第一个字段,而是优化器为你重构了SQL,比如上述这条SQL则会重构成如下情况:
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx`
UNION ALL
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx` AND A = "yyy"
......
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx` AND A = "zzz";
通过MySQL优化器处理后,虽然你没用第一个字段,但我(优化器)给你加上去,今天这个联合索引你就得用,不用也得给我用。
但是跳跃扫描机制也有很多限制,比如多表联查时无法触发、SQL条件中有分组操作也无法触发、SQL中用了DISTINCT去重也无法触发等等,总之有很多限制条件,具体的可以参考《MySQL官网8.0-跳跃扫描》。
最后,可以通过通过如下命令来选择开启或关闭跳跃式扫描机制。
set @@optimizer_switch = 'skip_scan=off|on';
联合索引注意事项
-
选择合适的列:应选择那些经常用于查询条件的列来创建联合索引。
-
考虑列的顺序:在创建联合索引时,应该根据实际的查询需求来安排列的顺序,以确保索引能够被有效利用。
-
避免过长的索引:虽然联合索引可以包含多个列,但过长的索引可能会增加维护成本,并且在某些情况下可能不会带来预期的性能提升。
-
避免范围查询:如果查询中包含范围操作符(如BETWEEN, <, >, LIKE),则MySQL可能无法有效地利用联合索引,因为它需要检查索引中的每个范围边界。
-
考虑索引的区分度:如果某个列的值重复率很高,那么该列作为联合索引的一部分可能不会提供太大的性能提升,因为它不能有效地区分不同的记录。
联合索引作为数据库中的一种索引类型,它由多个列组成,在使用时,一般遵循最左匹配原则,以加速数据库查询操作。
说在最后:有问题找老架构取经
联合索引 相关的面试题,是非常常见的面试题。也是核心面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典》V174,在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来帮扶、领路。
- 大龄男的最佳出路是 架构+ 管理
- 大龄女的最佳出路是 DPM,
女程序员如何成为DPM,请参见:
DPM (双栖)陪跑,助力小白一步登天,升格 产品经理+研发经理
领跑模式,尼恩已经指导了大量的就业困难的小伙伴上岸。
前段时间,领跑一个40岁+就业困难小伙伴拿到了一个年薪100W的offer,小伙伴实现了 逆天改命 。
另外,尼恩也给一线企业提供 《DDD 的架构落地》企业内部培训,目前给不少企业做过内部的咨询和培训,效果非常好。

尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓















 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









