






本文的 原始地址 ,传送门
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
10wqps自适应限流?怎么解决的?
你们项目中,怎么限流的?
所以,这里尼恩给大家做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V145版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
问题说明:
考察对限流算法的掌握情况
限流:是大厂面试、高P面试的核心面试题
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请到文末《技术自由圈》公号获取
为什么要限流
简单来说:
限流在很多场景中用来限制并发和请求量,比如说秒杀抢购,保护自身系统和下游系统不被巨型流量冲垮等。
以微博为例,例如某某明星公布了恋情,访问从平时的50万增加到了500万,系统的规划能力,最多可以支撑200万访问,那么就要执行限流规则,保证是一个可用的状态,不至于服务器崩溃,所有请求不可用。
限流的思想
在保证可用的情况下尽可能多增加进入的人数,其余的人在排队等待,或者返回友好提示,保证里面的进行系统的用户可以正常使用,防止系统雪崩。
日常生活中,有哪些需要限流的地方?
像我旁边有一个国家景区,平时可能根本没什么人前往,但是一到五一或者春节就人满为患,这时候景区管理人员就会实行一系列的政策来限制进入人流量,
为什么要限流呢?
假如景区能容纳一万人,现在进去了三万人,势必摩肩接踵,整不好还会有事故发生,这样的结果就是所有人的体验都不好,如果发生了事故景区可能还要关闭,导致对外不可用,这样的后果就是所有人都觉得体验糟糕透了。
本地限流/本地限流的四大算法
限流算法很多,常见的有四大算法,分别是计数器算法、滑动窗口算法、 漏桶算法、令牌桶算法,下面逐一讲解。
限流的手段通常有计数器、漏桶、令牌桶。注意限流和限速(所有请求都会处理)的差别,视
业务场景而定。
(1)计数器:
也叫做 固定窗口算法。
在一段时间间隔内(时间窗/时间区间),处理请求的最大数量固定,超过部分不做处理。
(2)滑动窗口算法
滑动窗口限流是对固定窗口限流算法的一种改进。
在固定窗口限流中,时间窗口是固定划分的,而滑动窗口限流将时间窗口划分为多个更小的子窗口,随着时间的推移,窗口会不断地滑动。
在统计请求数量时,会统计当前滑动窗口内所有子窗口的请求总和,当请求数量超过预设的阈值时,就拒绝后续的请求。
(3)漏桶:
漏桶大小固定,处理速度固定,但请求进入速度不固定(在突发情况请求过多时,会丢弃过多的请求)。
(4)令牌桶:
令牌桶的大小固定,令牌的产生速度固定,但是消耗令牌(即请求)速度不固定(可以应对一些某些时间请求过多的情况);
每个请求都会从令牌桶中取出令牌,如果没有令牌则丢弃该次请求。
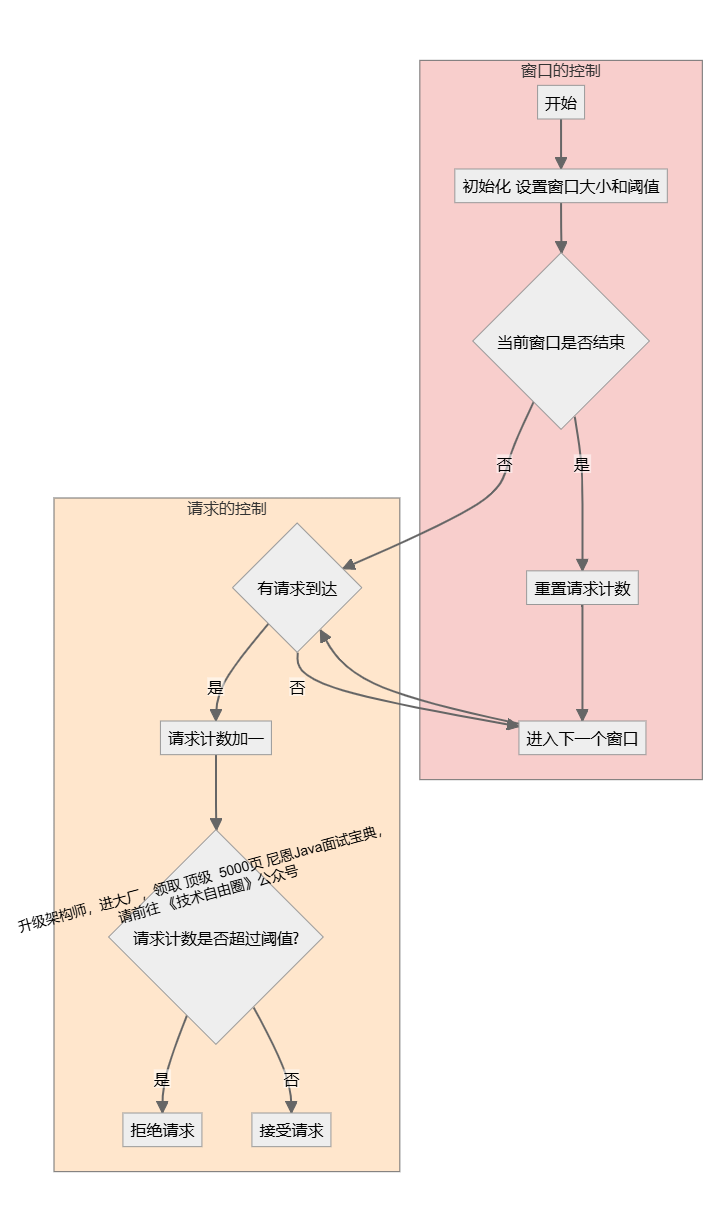
计数器限流(固定窗口限流)
图解:计数器限流原理
在一段时间间隔内(时间窗/时间区间),处理请求的最大数量固定,超过部分不做处理。
计数器限流 也叫做 固定窗口算法, 是一种简单直观的限流算法,其原理是将时间划分为固定大小的窗口,在每个窗口内限制请求的数量或速率。
计数器算法是限流算法里最简单也是最容易实现的一种算法。
计数器限流 具体实现时,可以使用一个计数器来记录当前窗口内的请求数,并与预设的阈值进行比较。
计数器限流 的原理如下:
-
将时间划分固定大小窗口,例如每秒一个窗口。
-
在每个窗口内,记录请求的数量。
-
当有请求到达时,将请求计数加一。
-
如果请求计数超过了预设的阈值(比如3个请求),拒绝该请求。
-
窗口结束后,重置请求计数。
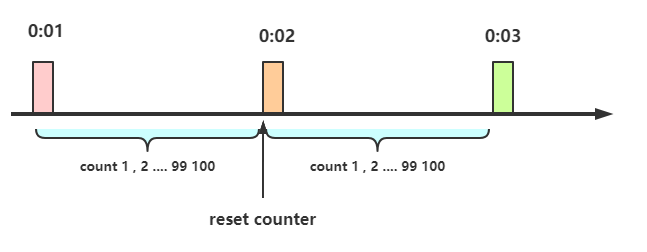
举个例子,比如我们规定对于A接口,我们1分钟的访问次数不能超过100个。
那么我们可以这么做:
- 在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个请求的间隔时间还在1分钟之内,那么说明请求数过多,拒绝访问;
- 如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,就是这么简单粗暴。
计数器限流(固定窗口限流)限流的实现
package com.crazymaker.springcloud.ratelimit;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
// 计速器 限速
@Slf4j
public class CounterLimiter
{
// 起始时间
private static long startTime = System.currentTimeMillis();
// 时间区间的时间间隔 ms
private static long interval = 1000;
// 每秒限制数量
private static long maxCount = 2;
//累加器
private static AtomicLong accumulator = new AtomicLong();
// 计数判断, 是否超出限制
private static long tryAcquire(long taskId, int turn)
{
long nowTime = System.currentTimeMillis();
//在时间区间之内
if (nowTime < startTime + interval)
{
long count = accumulator.incrementAndGet();
if (count <= maxCount)
{
return count;
} else
{
return -count;
}
} else
{
//在时间区间之外
synchronized (CounterLimiter.class)
{
log.info("新时间区到了,taskId{}, turn {}..", taskId, turn);
// 再一次判断,防止重复初始化
if (nowTime > startTime + interval)
{
accumulator.set(0);
startTime = nowTime;
}
}
return 0;
}
}
//线程池,用于多线程模拟测试
private ExecutorService pool = Executors.newFixedThreadPool(10);
@Test
public void testLimit()
{
// 被限制的次数
AtomicInteger limited = new AtomicInteger(0);
// 线程数
final int threads = 2;
// 每条线程的执行轮数
final int turns = 20;
// 同步器
CountDownLatch countDownLatch = new CountDownLatch(threads);
long start = System.currentTimeMillis();
for (int i = 0; i < threads; i++)
{
pool.submit(() ->
{
try
{
for (int j = 0; j < turns; j++)
{
long taskId = Thread.currentThread().getId();
long index = tryAcquire(taskId, j);
if (index <= 0)
{
// 被限制的次数累积
limited.getAndIncrement();
}
Thread.sleep(200);
}
} catch (Exception e)
{
e.printStackTrace();
}
//等待所有线程结束
countDownLatch.countDown();
});
}
try
{
countDownLatch.await();
} catch (InterruptedException e)
{
e.printStackTrace();
}
float time = (System.currentTimeMillis() - start) / 1000F;
//输出统计结果
log.info("限制的次数为:" + limited.get() +
",通过的次数为:" + (threads * turns - limited.get()));
log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));
log.info("运行的时长为:" + time);
}
}
计数器限流(固定窗口限流)的优点
-
实现简单:
固定窗口算法的实现相对简单,易于理解和部署。
-
稳定性较高:
对于突发请求能够较好地限制和控制,稳定性较高。
-
易于实现速率控制:
固定窗口算法可以很容易地限制请求的速率,例如每秒最多允许多少个请求。
计数器限流(固定窗口限流)的严重问题
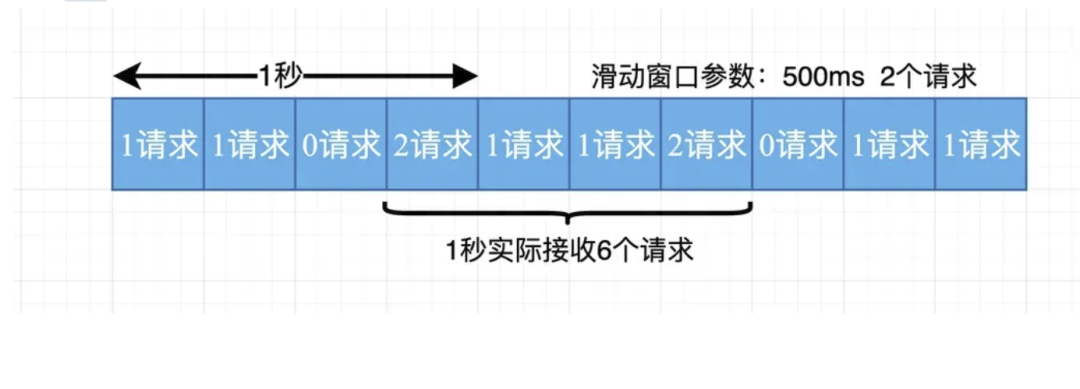
1. 临界问题(突刺现象)
- 问题描述:固定窗口限流在窗口切换的瞬间,可能会出现流量的突刺,导致在短时间内有大量请求通过,从而突破限流阈值,对系统造成冲击。
- 示例:假设设置每分钟允许 60 个请求,一个固定窗口的时间范围是从 0 分 0 秒到 1 分 0 秒。在 0 分 59 秒时,已经有 59 个请求通过了限流,此时还没有达到阈值。当时间进入 1 分 0 秒时,新的窗口开始,计数器重置为 0。在这一瞬间,又可以有 60 个请求通过,那么在 0 分 59 秒到 1 分 0 秒这极短的时间内,系统可能会收到多达 119 个请求,远远超过了每分钟 60 个请求的限流阈值。
- 影响:短时间内的大量请求可能会使系统资源耗尽,如 CPU 使用率过高、内存溢出等,从而导致系统性能下降甚至崩溃。
如果对临界问题(突刺现象)不了解,我们看下图:
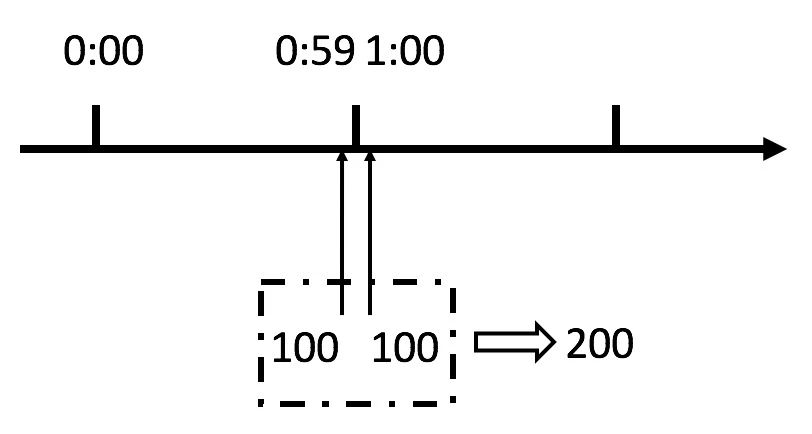
从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。
我们刚才规定的是1分钟最多100个请求(规划的吞吐量),也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。
用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
除了临界问题(突刺现象),还有其他问题:比如无法应对突发流量、限流精度低等等。
2. 无法应对突发流量
- 无法应对突发流量 的问题描述:
固定窗口限流只能对固定时间窗口内的平均流量进行限制,无法灵活应对突发的流量高峰。
即使在大部分时间内流量较低,但只要在某个窗口内流量突然增加并超过阈值,后续请求就会被拒绝,这可能会影响用户体验。
- 无法应对突发流量 的示例:
一个在线商城在正常情况下,每分钟的请求量大约为 20 个,但在促销活动开始的瞬间,可能会在几秒钟内产生大量的请求。
如果固定窗口限流的阈值设置为每分钟 50 个请求,那么在促销活动开始时,由于请求量突然增加,超过了阈值,后续的很多请求都会被拒绝,导致用户无法正常访问商城页面。
- 无法应对突发流量 的影响:
用户可能会因为频繁收到请求被拒绝的提示而感到不满,从而降低对系统的信任度,甚至可能会流失用户。
3. 限流精度低
- 限流精度低问题描述:
固定窗口的时间粒度通常是固定的,无法根据实际情况进行更细粒度的限流控制。例如,如果设置的时间窗口是 1 分钟,那么只能对每分钟的请求量进行统计和限制,无法对更短时间内的流量进行精确控制。
- 限流精度低示例:
在一些对流量控制要求较高的场景中,如金融交易系统,可能需要对每秒甚至更短时间内的请求量进行精确控制。但固定窗口限流只能以分钟为单位进行限流,无法满足这种高精度的限流需求。
- 限流精度低影响:
可能会导致系统在某些情况下无法及时对流量进行调整,从而影响系统的稳定性和可靠性。
滑动窗口限流
滑动窗口限流是对固定窗口限流算法的一种改进。在固定窗口限流中,时间窗口是固定划分的,而滑动窗口限流将时间窗口划分为多个更小的子窗口,随着时间的推移,窗口会不断地滑动。
在统计请求数量时,会统计当前滑动窗口内所有子窗口的请求总和,当请求数量超过预设的阈值时,就拒绝后续的请求。
这样可以更平滑地处理流量,减少固定窗口限流中可能出现的临界问题(突刺现象)。
滑动窗口算法在固定窗口的基础上,将一个计时窗口分成了若干个小窗口,然后每个小窗口维护一个独立的计数器。
当请求的时间大于当前窗口的最大时间时,则将计时窗口向前平移一个小窗口。
平移时,将第一个小窗口的数据丢弃,然后将第二个小窗口设置为第一个小窗口,同时在最后面新增一个小窗口,将新的请求放在新增的小窗口中。
同时要保证整个窗口中所有小窗口的请求数目之后不能超过设定的阈值。
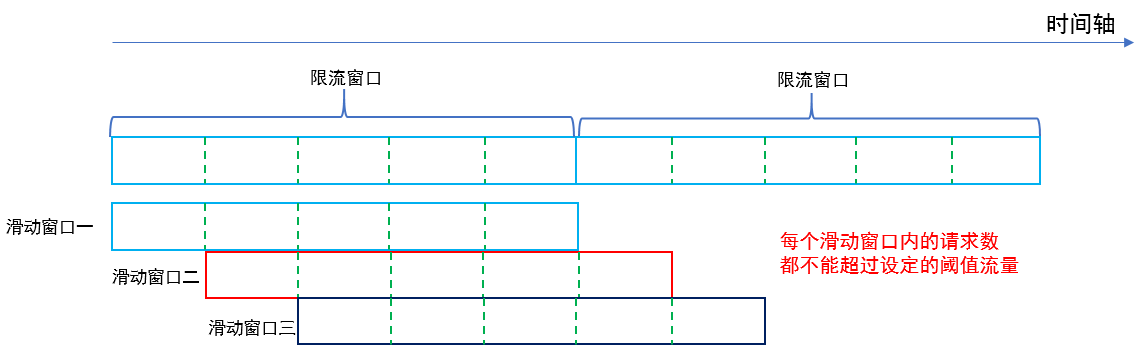
从图中不难看出,滑动窗口算法就是固定窗口的升级版。
将计时窗口划分成一个小窗口,滑动窗口算法就退化成了固定窗口算法。
而滑动窗口算法其实就是对请求数进行了更细粒度的限流,窗口划分的越多,则限流越精准。
图解:滑动窗口限流原理
上文已经说明当遇到时间窗口的临界突变时,固定窗口算法可能无法灵活地应对流量的变化。
滑动窗口限流 的原理如下:
-
窗口大小:
确定一个固定的窗口大小,例如1秒。
-
请求计数:
在窗口内,每次有请求到达时,将请求计数加1。
-
限制条件:
如果窗口内的请求计数超过了设定的阈值,即超过了允许的最大请求数,就拒绝该请求。
-
窗口滑动:
随着时间的推移,窗口会不断滑动,移除过期的请求计数,以保持窗口内的请求数在限制范围内。
-
动态调整:
在滑动窗口算法中,我们可以根据实际情况调整窗口的大小。当遇到下一个时间窗口之前,我们可以根据当前的流量情况来调整窗口的大小,以适应流量的变化。
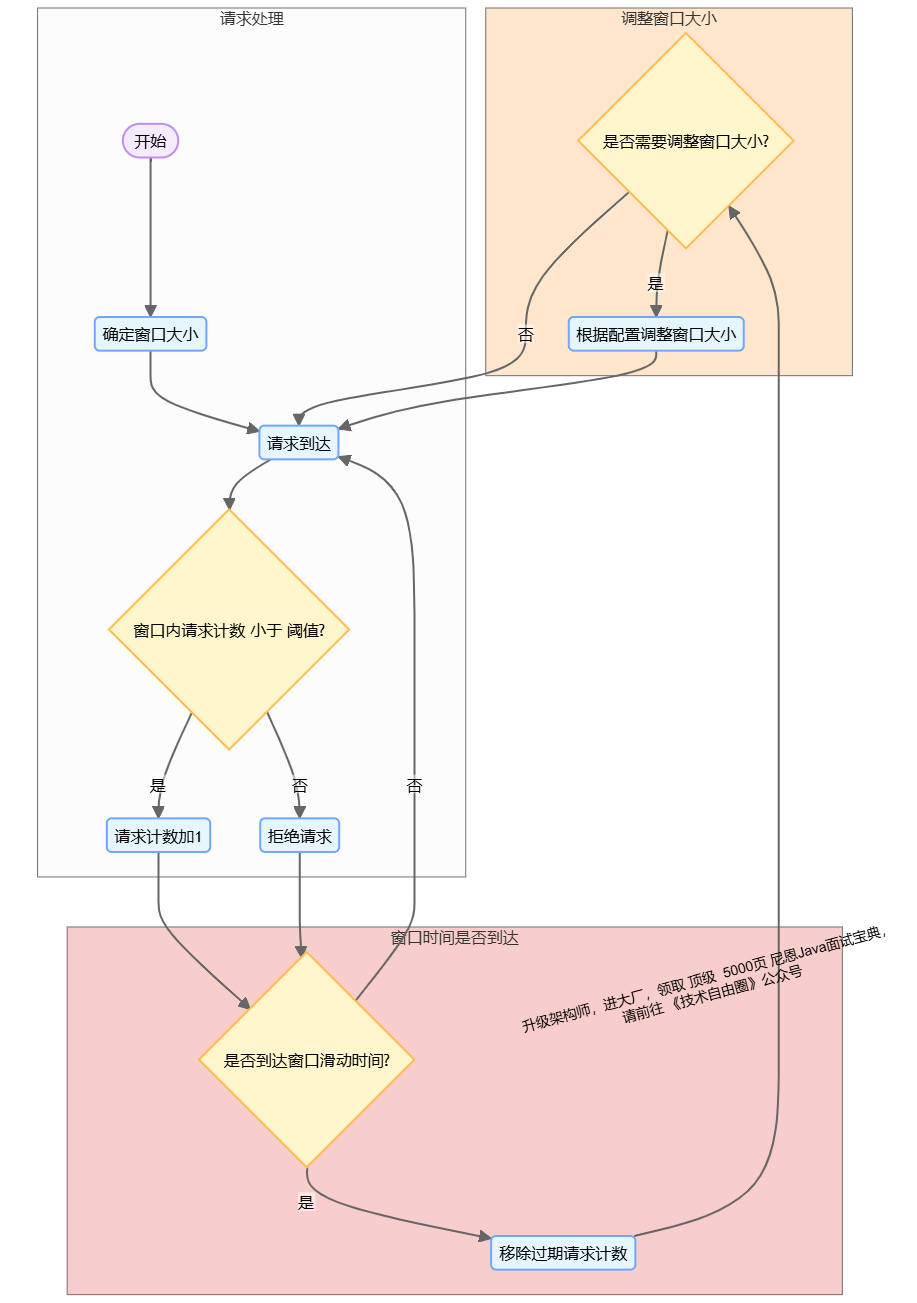
滑动窗口限流代码实现
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.atomic.AtomicInteger;
public class SlidingWindowRateLimiter {
// 时间窗口大小(毫秒)
private final long windowSize;
// 允许的最大请求数
private final int maxRequests;
// 子窗口数量
private final int subWindows;
// 每个子窗口的大小(毫秒)
private final long subWindowSize;
// 存储每个子窗口的请求计数
private final ConcurrentHashMap<Long, AtomicInteger> windowCounts;
// 存储子窗口的时间戳队列
private final ConcurrentLinkedQueue<Long> windowTimestamps;
public SlidingWindowRateLimiter(long windowSize, int maxRequests, int subWindows) {
this.windowSize = windowSize;
this.maxRequests = maxRequests;
this.subWindows = subWindows;
this.subWindowSize = windowSize / subWindows;
this.windowCounts = new ConcurrentHashMap<>();
this.windowTimestamps = new ConcurrentLinkedQueue<>();
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
// 移除过期的子窗口
while (!windowTimestamps.isEmpty() && currentTime - windowTimestamps.peek() > windowSize) {
long expiredTimestamp = windowTimestamps.poll();
windowCounts.remove(expiredTimestamp);
}
// 计算当前时间所在的子窗口时间戳
long currentSubWindow = currentTime - (currentTime % subWindowSize);
// 获取或创建当前子窗口的计数器
AtomicInteger currentCount = windowCounts.computeIfAbsent(currentSubWindow, k -> {
windowTimestamps.offer(currentSubWindow);
return new AtomicInteger(0);
});
// 计算当前滑动窗口内的总请求数
int totalRequests = windowCounts.values().stream().mapToInt(AtomicInteger::get).sum();
if (totalRequests < maxRequests) {
// 请求通过,增加当前子窗口的计数
currentCount.incrementAndGet();
return true;
}
return false;
}
public static void main(String[] args) {
// 时间窗口为 1000 毫秒,允许最大请求数为 100,子窗口数量为 10
SlidingWindowRateLimiter limiter = new SlidingWindowRateLimiter(1000, 100, 10);
for (int i = 0; i < 120; i++) {
if (limiter.allowRequest()) {
System.out.println("Request " + i + " allowed");
} else {
System.out.println("Request " + i + " denied");
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
调整窗口大小
为了实现根据提供的 API 方法调整窗口大小的功能, 需要对原有的 SlidingWindowRateLimiter 类进行一些修改。
主要思路是将 windowSize 和 subWindowSize 变为可变的属性,并提供一个公共方法来调整窗口大小,同时在调整窗口大小后,需要重新计算过期的子窗口。
以下是优化后的代码:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.atomic.AtomicInteger;
public class SlidingWindowRateLimiter {
// 时间窗口大小(毫秒)
private long windowSize;
// 允许的最大请求数
private final int maxRequests;
// 子窗口数量
private final int subWindows;
// 每个子窗口的大小(毫秒)
private long subWindowSize;
// 存储每个子窗口的请求计数
private final ConcurrentHashMap<Long, AtomicInteger> windowCounts;
// 存储子窗口的时间戳队列
private final ConcurrentLinkedQueue<Long> windowTimestamps;
public SlidingWindowRateLimiter(long windowSize, int maxRequests, int subWindows) {
this.windowSize = windowSize;
this.maxRequests = maxRequests;
this.subWindows = subWindows;
this.subWindowSize = windowSize / subWindows;
this.windowCounts = new ConcurrentHashMap<>();
this.windowTimestamps = new ConcurrentLinkedQueue<>();
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
// 移除过期的子窗口
removeExpiredWindows(currentTime);
// 计算当前时间所在的子窗口时间戳
long currentSubWindow = currentTime - (currentTime % subWindowSize);
// 获取或创建当前子窗口的计数器
AtomicInteger currentCount = windowCounts.computeIfAbsent(currentSubWindow, k -> {
windowTimestamps.offer(currentSubWindow);
return new AtomicInteger(0);
});
// 计算当前滑动窗口内的总请求数
int totalRequests = windowCounts.values().stream().mapToInt(AtomicInteger::get).sum();
if (totalRequests < maxRequests) {
// 请求通过,增加当前子窗口的计数
currentCount.incrementAndGet();
return true;
}
return false;
}
// 移除过期的子窗口
private void removeExpiredWindows(long currentTime) {
while (!windowTimestamps.isEmpty() && currentTime - windowTimestamps.peek() > windowSize) {
long expiredTimestamp = windowTimestamps.poll();
windowCounts.remove(expiredTimestamp);
}
}
// 调整窗口大小的 API 方法
public synchronized void adjustWindowSize(long newWindowSize) {
this.windowSize = newWindowSize;
// subWindows 子窗口数量不变
this.subWindowSize = newWindowSize / subWindows;
long currentTime = System.currentTimeMillis();
// 移除因窗口大小调整而过期的子窗口
removeExpiredWindows(currentTime);
}
public static void main(String[] args) {
// 时间窗口为 1000 毫秒,允许最大请求数为 100,子窗口数量为 10
SlidingWindowRateLimiter limiter = new SlidingWindowRateLimiter(1000, 100, 10);
for (int i = 0; i < 50; i++) {
if (limiter.allowRequest()) {
System.out.println("Request " + i + " allowed");
} else {
System.out.println("Request " + i + " denied");
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 调整窗口大小为 2000 毫秒
limiter.adjustWindowSize(2000);
for (int i = 50; i < 120; i++) {
if (limiter.allowRequest()) {
System.out.println("Request " + i + " allowed");
} else {
System.out.println("Request " + i + " denied");
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
代码解释:
-
属性修改:
将
windowSize和subWindowSize的final修饰符去掉,使其可以被修改。 -
removeExpiredWindows方法:封装了移除过期子窗口的逻辑,方便在
allowRequest方法和adjustWindowSize方法中复用。 -
adjustWindowSize方法:提供了一个公共的 API 方法,用于调整窗口大小。
在调整窗口大小后,重新计算
subWindowSize,并调用removeExpiredWindows方法移除因窗口大小调整而过期的子窗口。 -
main方法:模拟了先处理 50 个请求,然后调用
adjustWindowSize方法将窗口大小调整为 2000 毫秒,再处理后续的请求。
通过这些修改,我们实现了在运行时动态调整窗口大小的功能。
滑动窗口限流优点
-
灵活性:
滑动窗口算法可以根据实际情况动态调整窗口的大小,以适应流量的变化。
这种灵活性使得算法能够更好地应对突发流量和请求分布不均匀的情况。
-
实时性:
由于滑动窗口算法在每个时间窗口结束时都会进行窗口滑动,它能够更及时地响应流量的变化,提供更实时的限流效果。
-
精度:
相比于固定窗口算法,滑动窗口算法的颗粒度更小,可以提供更精确的限流控制。
滑动窗口限流缺点:
滑动窗口限流虽然是对固定窗口限流算法的改进,能更平滑地处理流量,减少临界问题,但它也存在一些缺点,具体如下:
滑动窗口不足之一:实现复杂度较高
-
逻辑复杂
相较于固定窗口限流,滑动窗口限流需要将时间窗口划分为多个子窗口,并对每个子窗口的请求计数进行维护。
在窗口滑动时,要判断哪些子窗口已经过期并移除其计数,这增加了算法的逻辑复杂度。
例如,在 Java 代码实现中,需要使用
ConcurrentHashMap存储子窗口的请求计数,使用ConcurrentLinkedQueue存储子窗口的时间戳,还需要处理线程安全问题,使得代码实现难度增大。 -
调试困难:
由于逻辑复杂,当出现限流不准确或其他问题时,调试难度较大。需要仔细检查子窗口的划分、过期子窗口的移除、请求计数的统计等多个环节,排查问题的时间和精力成本较高。
滑动窗口不足之二:资源消耗较大
-
内存占用:
为了存储每个子窗口的请求计数和时间戳,需要额外的内存空间。尤其是当子窗口数量较多时,内存占用会显著增加。例如,在高并发场景下,如果将时间窗口划分为大量的子窗口,
ConcurrentHashMap和ConcurrentLinkedQueue会占用较多的内存,可能导致系统内存资源紧张。 -
CPU 开销:
在每次请求到达时,需要遍历子窗口的时间戳队列,判断哪些子窗口已经过期并移除,这会带来一定的 CPU 开销。特别是在高并发情况下,频繁的请求会使这种 CPU 开销更加明显,影响系统的性能。
滑动窗口不足之三:时间精度有限
-
子窗口划分限制:
滑动窗口限流的时间精度取决于子窗口的划分粒度。
如果子窗口划分得不够细,仍然可能无法精确地应对短时间内的流量突变。
例如,将 1 秒的时间窗口划分为 10 个子窗口,每个子窗口为 100 毫秒,对于小于 100 毫秒内的流量高峰,可能无法进行精确的限流控制。
滑动窗口算法实际上是颗粒度更小的固定窗口算法,它可以在一定程度上提高限流的精度和实时性,并不能从根本上解决请求分布不均匀的问题。
特别是在极端情况下,如突发流量过大或请求分布极不均匀的情况下,仍然可能导致限流不准确。
因此,在实际应用中,要采用更复杂的算法或策略来进一步优化限流效果。
-
时钟同步问题:
在分布式系统中,不同节点的时钟可能存在一定的偏差,这会影响滑动窗口的准确性。例如,节点 A 和节点 B 的时钟不一致,可能导致在同一时刻,节点 A 认为某个子窗口已经过期,而节点 B 却认为该子窗口仍然有效,从而造成限流的不准确。
漏桶算法限流
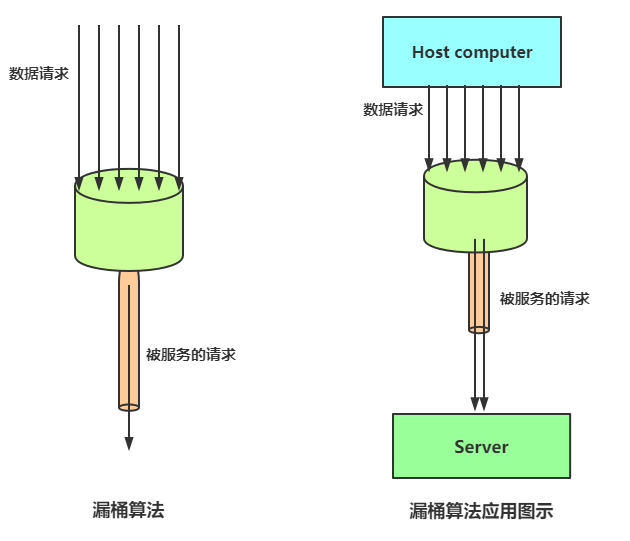
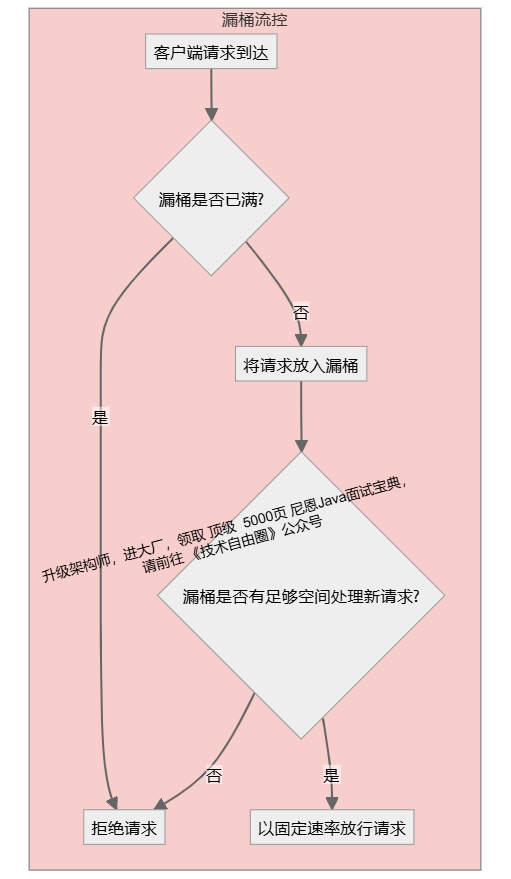
漏桶算法限流的基本原理为:
水(对应请求)从进水口进入到漏桶里,漏桶以一定的速度出水(请求放行),当水流入速度过大,桶内的总水量大于桶容量会直接溢出,请求被拒绝,如图所示。
大致的漏桶限流规则如下:
(1)进水口(对应客户端请求)以任意速率流入进入漏桶。
(2)漏桶的容量是固定的,出水(放行)速率也是固定的。
(3)漏桶容量是不变的,如果处理速度太慢,桶内水量会超出了桶的容量,则后面流入的水滴会溢出,表示请求拒绝。
图解:漏桶算法原理
漏桶算法思路很简单:
漏桶以一定的速度出水,水 代表了用户请求。
漏桶算法 可以粗略的认为就是注水 + 漏水过程,往桶中以任意速率注入水,以一定速率流出水,当水超过桶容量(capacity)则丢弃,因为桶容量是不变的,保证了整体的速率。
水 先进入到漏桶里,当水流入速度过大时, 会超过桶可接纳的容量时直接溢出。
**变化的地方:**入口变化,入口速度 变化。具体来说,可以以任意速率,往桶中 注入水。
**固定的部分:**出口固定,出口速度 变化漏桶算法 以一固定速率流出水。从 图 可以看出,漏桶算法能强行限制数据的出水速率。
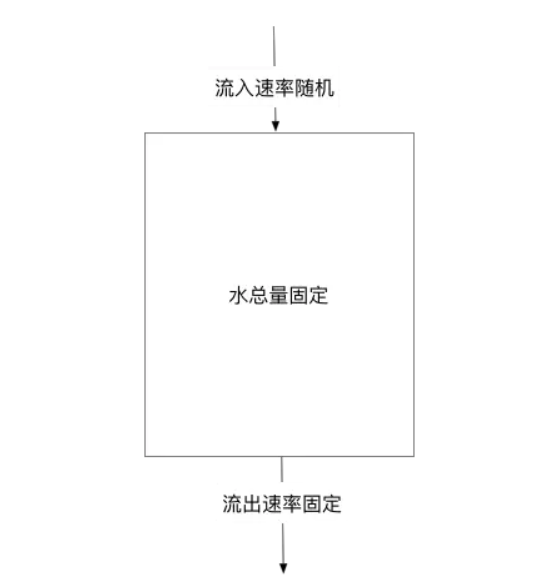
由于 出口固定,所以 漏桶算法至少有下面的两个作用:
削峰:有大量流量进入时,会发生溢出,从而限流保护服务可用
缓冲:不至于直接请求到服务器,缓冲压力
漏桶算法的实现
漏桶的容量就像队列的容量,当请求堆积超过指定容量时,会触发拒绝策略,即新到达的请求将被丢弃或延迟处理。
算法的实现如下:
-
漏桶容量:
确定一个固定的漏桶容量,表示漏桶可以存储的最大请求数。
-
漏桶速率:
确定一个固定的漏桶速率,表示漏桶每秒可以处理的请求数。
-
请求处理:
当请求到达时,生产者将请求放入漏桶中。
-
漏桶流出:
漏桶以固定的速率从漏桶中消费请求,并处理这些请求。如果漏桶中有请求,则处理一个请求;如果漏桶为空,则不处理请求。
-
请求丢弃或延迟:
如果漏桶已满,即漏桶中的请求数达到了容量上限,新到达的请求将被丢弃或延迟处理。
import java.util.concurrent.*;
public class LeakyBucketRateLimiter {
private final int capacity; // 漏桶容量
private final int rate; // 漏桶速率(每秒处理的请求数)
private final BlockingQueue<Runnable> bucket; // 漏桶(队列)
private final ScheduledExecutorService executor; // 定时任务执行器
public LeakyBucketRateLimiter(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
this.bucket = new LinkedBlockingQueue<>(capacity);
this.executor = Executors.newScheduledThreadPool(1);
// 启动漏桶的处理任务
executor.scheduleAtFixedRate(this::processRequest, 0, 1000L / rate, TimeUnit.MILLISECONDS);
}
// 尝试将请求放入漏桶
public boolean tryPutRequest(Runnable request) {
if (bucket.remainingCapacity() == 0) {
// 漏桶已满,拒绝请求
System.out.println("漏桶已满,请求被拒绝");
return false;
}
bucket.add(request);
System.out.println("请求已放入漏桶");
return true;
}
// 漏桶处理请求
private void processRequest() {
if (!bucket.isEmpty()) {
try {
Runnable request = bucket.take(); // 从漏桶中取出一个请求
request.run(); // 处理请求
System.out.println("请求已处理");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 关闭漏桶限流器
public void shutdown() {
executor.shutdown();
}
public static void main(String[] args) {
LeakyBucketRateLimiter limiter = new LeakyBucketRateLimiter(capacity: 10, rate: 2);
// 模拟多个请求
for (int i = 0; i < 15; i++) {
Runnable request = () -> System.out.println("处理请求: " + i);
limiter.tryPutRequest(request);
}
// 等待一段时间后关闭
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
limiter.shutdown();
}
}
}
漏桶算法是一种常用的限流算法,其核心思想是将请求比作水,漏桶以固定的速率处理请求,当请求超过漏桶容量时,新请求会被丢弃或延迟处理。下面详细介绍漏桶算法的优点和缺点。
漏桶算法的优点
1. 平滑流量输出
-
稳定处理速率:
漏桶算法以固定的速率处理请求,无论外部请求的流量波动有多大,漏桶都会按照预设的速率依次处理请求。这就像一个底部有固定大小小孔的桶,水总是以稳定的速度流出。
例如,在一个 API 服务中,设置漏桶的处理速率为每秒 10 个请求,那么无论在某一时刻是突然涌入 100 个请求还是只有 1 个请求,服务都会以每秒 10 个的速度处理这些请求,从而避免了系统因瞬间的高流量冲击而崩溃。
-
避免系统过载:
稳定的处理速率可以有效地保护系统资源,防止系统因处理过多请求而出现过载的情况。
当请求流量过大时,多余的请求会在漏桶中排队等待处理,或者被直接丢弃,这样可以确保系统始终在其处理能力范围内运行,保证系统的稳定性和可靠性。
2. 易于实现和理解
-
简单的逻辑结构:
漏桶算法的逻辑相对简单,主要涉及到两个核心概念:漏桶的容量和漏桶的处理速率。
在实现上,通常只需要使用一个队列来模拟漏桶,再通过一个定时器或者线程以固定的速率从队列中取出请求进行处理即可。
例如,在 Java 中可以使用
BlockingQueue来实现漏桶,使用一个线程以固定的时间间隔从队列中取出元素进行处理,代码实现较为简洁易懂。 -
直观的工作原理:
漏桶算法的工作原理与现实生活中的漏桶现象类似,容易让人理解。
开发者可以很直观地根据业务需求设置漏桶的容量和处理速率,从而实现对流量的控制。
3. 公平性
-
先进先出原则:
漏桶算法遵循先进先出(FIFO)的原则,即先进入漏桶的请求会先被处理。
这保证了每个请求都有公平的处理机会,不会因为请求的优先级或者其他因素而导致某些请求被优先处理。
例如,在一个多用户的系统中,每个用户的请求都会按照到达的顺序依次在漏桶中排队等待处理,不会出现某个用户的请求因为特殊原因而插队的情况,体现了公平性。
漏桶算法的缺点
1. 无法应对突发流量
-
固定处理速率的限制:
由于漏桶算法以固定的速率处理请求,当出现突发的高流量时,即使系统有足够的处理能力,也只能按照预设的速率处理请求,无法及时响应突发流量。
例如,在电商系统的促销活动开始瞬间,会有大量的用户同时发起请求,此时漏桶算法只能以固定的速率处理这些请求,导致大量请求在漏桶中排队等待,甚至被丢弃,用户体验会受到严重影响。
-
资源利用率低:
在流量低谷期,系统的处理能力可能远远没有达到上限,但漏桶算法仍然以固定的速率处理请求,无法充分利用系统的空闲资源。
这就导致了系统资源的浪费,降低了系统的整体性能。
2. 缺乏灵活性
-
参数调整困难:
漏桶算法的性能很大程度上取决于漏桶的容量和处理速率这两个参数的设置。
然而,在实际应用中,很难准确地预测系统的流量变化情况,因此很难设置出合适的参数。
如果参数设置过小,可能会导致大量请求被丢弃,影响系统的可用性;如果参数设置过大,又可能无法起到有效的限流作用。
-
不适应动态场景:
在一些动态变化的场景中,如系统的负载随着时间不断变化,或者不同类型的请求对系统资源的消耗不同,漏桶算法无法根据实际情况动态调整处理速率,缺乏灵活性。
3. 可能导致请求延迟
-
排队等待时间长:
当请求流量超过漏桶的处理速率时,请求会在漏桶中排队等待处理。
如果流量持续过高,排队的请求会越来越多,导致请求的处理延迟增加。
对于一些对实时性要求较高的业务场景,如金融交易、实时通信等,过长的请求延迟可能会带来严重的后果。例如,在金融交易中,延迟的交易请求可能会导致错过最佳的交易时机,造成经济损失。
漏桶算法的适用场景
适合漏桶算法的场景:
- 需要平滑流量的系统(如 API 网关、 Nginx 网关、消息队列)。
- 需要防止系统过载的场景(如 DDoS 防护、限流保护)。
- 资源受限的环境(如嵌入式系统、低资源服务器)。
不适合漏桶算法的场景:
- 需要处理突发流量的系统。
- 实时性要求较高的场景(如在线游戏、实时通信)。
- 需要区分请求优先级的场景(如任务调度、实时计算)。
图解:令牌桶限流原理
令牌桶算法以一个设定的速率产生令牌并放入令牌桶,每次用户请求都得申请令牌,如果令牌不足,则拒绝请求。
令牌桶算法中新请求到来时会从桶里拿走一个令牌,如果桶内没有令牌可拿,就拒绝服务。当然,令牌的数量也是有上限的。
令牌的数量与时间和发放速率强相关,时间流逝的时间越长,会不断往桶里加入越多的令牌,如果令牌发放的速度比申请速度快,令牌桶会放满令牌,直到令牌占满整个令牌桶。
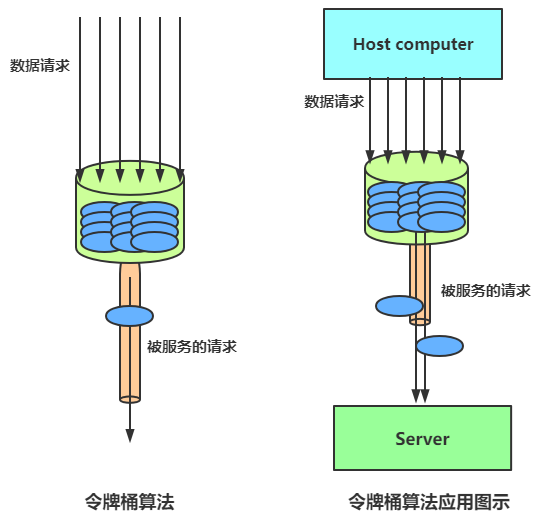
令牌桶限流大致的规则如下:
(1)进水口按照某个速度,向桶中放入令牌。
(2)令牌的容量是固定的,但是放行的速度不是固定的,只要桶中还有剩余令牌,一旦请求过来就能申请成功,然后放行。
(3)如果令牌的发放速度,慢于请求到来速度,桶内就无牌可领,请求就会被拒绝。
总之,令牌的发送速率可以设置,从而可以对突发的出口流量进行有效的应对。
令牌桶与漏桶相似,不同的是令牌桶桶中放了一些令牌,服务请求到达后,要获取令牌之后才会得到服务。
举个例子,我们平时去食堂吃饭,都是在食堂内窗口前排队的,这就好比是漏桶算法,大量的人员聚集在食堂内窗口外,以一定的速度享受服务,如果涌进来的人太多,食堂装不下了,可能就有一部分人站到食堂外了。
这就没有享受到食堂的服务,称之为溢出,溢出可以继续请求,也就是继续排队,这个还是带burst的漏桶算法。
那么这样有什么问题呢?
如果 有特殊情况,比如 要高考啦,这种情况就是突发情况,不能让考生排太长,得想办法并发处理掉这些突发流量, 比如 外调一批 厨师来 , 做更多的伙食, 把突发的流量满足掉。
所以,这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
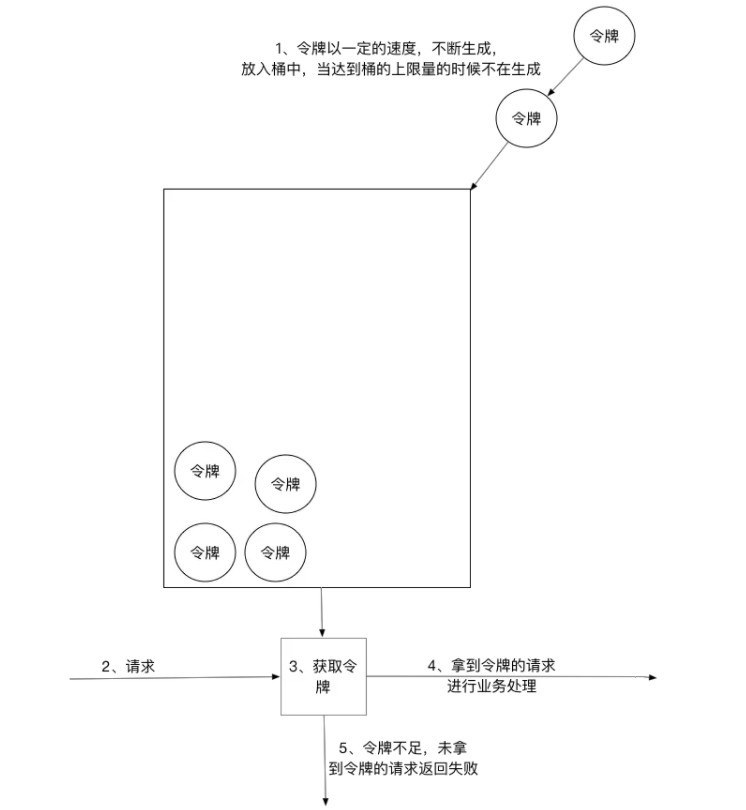
如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
令牌桶算法实现
令牌桶算法的实现步骤如下:
-
初始化一个令牌桶,包括桶的容量和令牌产生的速率。
-
持续以固定速率产生令牌,并放入令牌桶中,直到桶满为止。
-
当请求到达时,尝试从令牌桶中获取一个令牌。
-
如果令牌桶中有足够的令牌,则请求通过,并从令牌桶中移除一个令牌。
-
如果令牌桶中没有足够的令牌,则请求被限制或丢弃。
import java.util.concurrent.TimeUnit;
// 令牌桶限流器类
public class TokenBucketRateLimiter {
// 令牌桶的容量,即桶最多能容纳的令牌数量
private final int capacity;
// 令牌产生的速率,单位为每秒产生的令牌数
private final int rate;
// 当前令牌桶中的令牌数量
private int tokens;
// 上次更新令牌数量的时间戳,单位为毫秒
private long lastRefillTime;
/**
* 构造函数,用于初始化令牌桶限流器
* @param capacity 令牌桶的容量
* @param rate 令牌产生的速率(每秒产生的令牌数)
*/
public TokenBucketRateLimiter(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
// 初始化时令牌桶是满的
this.tokens = capacity;
// 记录初始化时的时间
this.lastRefillTime = System.currentTimeMillis();
}
/**
* 尝试获取一个令牌,如果有足够的令牌则返回 true,否则返回 false
* @return 如果成功获取令牌返回 true,否则返回 false
*/
public synchronized boolean tryAcquire() {
// 首先进行令牌的补充操作
refill();
// 检查令牌桶中是否有足够的令牌
if (tokens > 0) {
// 如果有足够的令牌,消耗一个令牌
tokens--;
return true;
}
// 没有足够的令牌,返回 false
return false;
}
/**
* 补充令牌的方法,根据时间间隔和令牌产生速率来补充令牌
*/
private void refill() {
// 获取当前时间戳
long now = System.currentTimeMillis();
// 计算从上次更新令牌数量到现在经过的时间(单位:秒)
long elapsedTime = TimeUnit.MILLISECONDS.toSeconds(now - lastRefillTime);
// 根据经过的时间和令牌产生速率计算应该补充的令牌数量
int newTokens = (int) (elapsedTime * rate);
if (newTokens > 0) {
// 更新令牌数量,取补充后的令牌数量和桶容量的最小值,确保令牌数量不超过桶的容量
tokens = Math.min(capacity, tokens + newTokens);
// 更新上次更新令牌数量的时间戳
lastRefillTime = now;
}
}
public static void main(String[] args) {
// 创建一个令牌桶限流器,容量为 100,每秒产生 10 个令牌
TokenBucketRateLimiter limiter = new TokenBucketRateLimiter(100, 10);
// 模拟 20 次请求
for (int i = 0; i < 20; i++) {
if (limiter.tryAcquire()) {
System.out.println("Request " + i + " is allowed.");
} else {
System.out.println("Request " + i + " is denied.");
}
try {
// 模拟请求间隔 100 毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
令牌桶的好处
令牌桶的好处之一就是可以方便地应对 突发出口流量(后端能力的提升)。
比如,可以改变令牌的发放速度,算法能按照新的发送速率调大令牌的发放数量,使得出口突发流量能被处理。
Guava RateLimiter
Guava是Java领域优秀的开源项目,它包含了Google在Java项目中使用一些核心库,包含集合(Collections),缓存(Caching),并发编程库(Concurrency),常用注解(Common annotations),String操作,I/O操作方面的众多非常实用的函数。
Guava的 RateLimiter提供了令牌桶算法实现:
平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
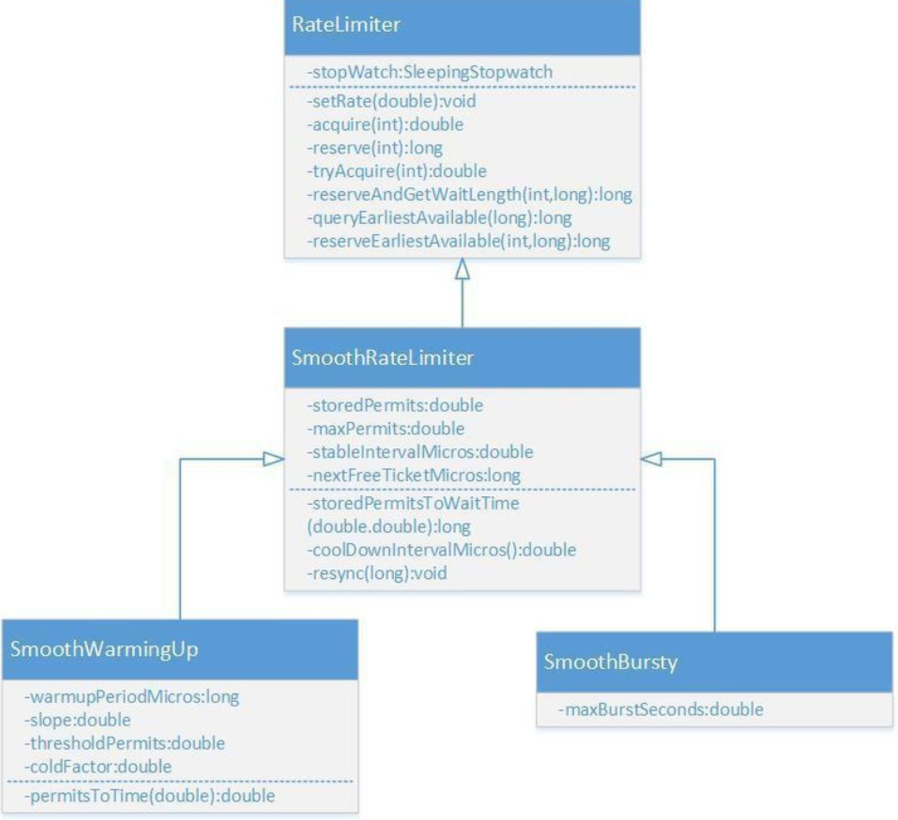
令牌桶的 优缺点
优点:
-
平滑流量:令牌桶算法可以平滑突发流量,使得突发流量在一段时间内均匀地分布,避免了流量的突然高峰对系统的冲击。
-
灵活性:令牌桶算法可以通过调整令牌生成速率和桶的大小来灵活地控制流量。
-
允许突发流量:由于令牌桶可以积累一定数量的令牌,因此在流量突然增大时,如果桶中有足够的令牌,可以应对这种突发流量。
缺点:
-
实现复杂:相比于其他一些限流算法(如漏桶算法),令牌桶算法的实现稍微复杂一些,需要维护令牌的生成和消耗。
-
需要精确的时间控制:令牌桶算法需要根据时间来生成令牌,因此需要有精确的时间控制。如果系统的时间控制不精确,可能会影响限流的效果。
-
可能会有资源浪费:如果系统的流量持续低于令牌生成的速率,那么桶中的令牌可能会一直积累,造成资源的浪费。
四种基本算法的对比
| 算法 | 优点 | 缺点 | 适合场景 |
| – | | - | ----- |
| 固定窗口 | 简单直观,易于实现 适用于稳定的流量控制 易于实现速率控制 | 无法应对短时间内的突发流量 流量不均匀时可能导致突发流量 | 稳定的流量控制,不需要保证请求均匀分布的场景 |
| 滑动窗口 | 平滑处理突发流量 颗粒度更小,可以提供更精确的限流控制 | 实现相对复杂 需要维护滑动窗口的状态 存在较高的内存消耗 | 需要平滑处理突发流量的场景 |
| 漏桶算法 | 平滑处理突发流量 可以固定输出速率,有效防止过载 | 对突发流量的处理不够灵活 无法应对流量波动的情况 | 需要固定输出速率的场景 避免流量的突然增大对系统的冲击的场景 |
| 令牌桶 | 平滑处理突发流量 可以动态调整限流规则 能适应不同时间段的流量变化 | 实现相对复杂 需要维护令牌桶的状态 | 需要动态调整限流规则的场景 需要 处理突发流量的场景 |
菜鸟级答案:60分答案
尼恩提示,讲完 4大算法, 可以得到 60分了。
但是要直接拿到大厂offer,或者 offer 直提,需要 120分答案。

尼恩带大家继续。
工业级案例:Nginx 的漏桶 限流 原理
Nginx 的漏桶算法限流的使用
解下来,可以给面试官吹吹,工业级组件 Nginx 的源码如何限流的?
Nginx 基于请求速率的限流 (ngx_http_limit_req_module)模块基于漏桶算法实现请求速率的限制,它可以控制每个客户端 IP 或其他标识的请求频率,防止过多请求对服务器造成压力。
Nginx的限流功能通过ngx_http_limit_req_module模块实现,主要通过limit_req_zone和limit_req指令进行配置。以下是一些常见的限流配置示例和说明,帮助你快速理解和应用Nginx的限流功能。
1. 基本限流配置
以下是一个简单的限流配置示例,限制每个客户端IP地址的请求速率:
http {
# 定义一个限流区域
limit_req_zone $binary_remote_addr zone=my_limit:10m rate=1r/s;
server {
listen 80;
server_name example.com;
location / {
# 应用限流规则
limit_req zone=my_limit;
}
}
}
limit_req_zone 的配置说明:
- $binary_remote_addr:基于客户端IP地址进行限流。
- zone=my_limit:10m:定义一个名为
my_limit的共享内存区域,大小为10MB。 - rate=1r/s:每秒最多处理1个请求。
limit_req的配置说明
zone=my_limit:引用limit_req_zone定义的共享内存区域。
2. 处理突发流量
如果需要允许突发流量,可以使用burst参数。例如,允许突发5个请求:
location / {
limit_req zone=my_limit burst=5;
}
burst=5:允许在短时间内额外处理5个请求。超出部分的请求会被延迟处理。
3. 延迟处理与立即拒绝
默认情况下,超出速率的请求会被延迟处理。如果希望立即拒绝超出速率的请求,可以使用nodelay参数:
location / {
limit_req zone=my_limit burst=5 nodelay;
}
nodelay:取消延迟处理,超出速率的请求会立即返回错误(默认为503)。
4. 自定义拒绝状态码
可以通过limit_req_status指令自定义拒绝请求时返回的状态码。例如,返回429状态码(Too Many Requests):
location / {
limit_req zone=my_limit burst=5 nodelay;
limit_req_status 429;
}
5. 基于不同键的限流
除了基于客户端IP地址,还可以使用其他键进行限流,例如基于请求路径或用户代理:
http {
# 基于请求路径限流
limit_req_zone $request_uri zone=path_limit:10m rate=2r/s;
# 基于用户代理限流
limit_req_zone $http_user_agent zone=agent_limit:10m rate=1r/s;
server {
listen 80;
server_name example.com;
location / {
limit_req zone=path_limit burst=3;
}
location /api/ {
limit_req zone=agent_limit burst=2 nodelay;
}
}
}
在Nginx中,$http_user_agent 是一个内置变量,用于获取客户端请求中的 User-Agent 头部信息。
假设客户端请求中包含一个自定义头部user-id,你可以通过以下配置实现基于user-id的限流:基于 user-id 的header限流
http {
# 定义基于 user-id 的限流区域
limit_req_zone $http_user_id zone=user_id_limit:10m rate=1r/s;
server {
listen 80;
server_name example.com;
location / {
# 应用限流规则
limit_req zone=user_id_limit burst=5 nodelay;
limit_req_status 429; # 返回 429 Too Many Requests
}
}
}
在Nginx中,可以通过$http_header_name变量结合limit_req_zone指令实现基于HTTP头部(如user-id)的限流。
4、Nginx 请求处理与限流的核心源码
Nginx 核心的请求处理和限流判断在 ngx_http_limit_req_lookup 函数中实现:
static ngx_int_t
ngx_http_limit_req_lookup(ngx_http_limit_req_limit_t *limit, ngx_uint_t hash,
ngx_str_t *key, ngx_uint_t *ep, ngx_uint_t account)
{
size_t size;
ngx_int_t rc, excess;
ngx_msec_t now;
ngx_msec_int_t ms;
ngx_rbtree_node_t *node, *sentinel;
ngx_http_limit_req_ctx_t *ctx;
ngx_http_limit_req_node_t *lr;
now = ngx_current_msec;
ctx = limit->shm_zone->data;
node = ctx->sh->rbtree.root;
sentinel = ctx->sh->rbtree.sentinel;
while (node != sentinel) {
if (hash < node->key) {
node = node->left;
continue;
}1
if (hash > node->key) {
node = node->right;
continue;
}
/* hash == node->key */
lr = (ngx_http_limit_req_node_t *) &node->color;
rc = ngx_memn2cmp(key->data, lr->data, key->len, (size_t) lr->len);
/* hash 值相同,且 key 相同,才算是找到 */
if (rc == 0) {
/* 这个节点最近才访问,放到队列首部,最不容易被淘汰(LRU 思想)*/
ngx_queue_remove(&lr->queue);
ngx_queue_insert_head(&ctx->sh->queue, &lr->queue);
/*
* 漏桶算法:以固定速率接受请求,每秒接受 rate 个请求,
* ms 是距离上次处理这个 key 到现在的时间,单位 ms
* lr->excess 是上次还遗留着被延迟的请求数(*1000)
* excess = lr->excess - ctx->rate * ngx_abs(ms) / 1000 + 1000;
* 本次还会遗留的请求数就是上次遗留的减去这段时间可以处理掉的加上这个请求本身(之前 burst 和 rate 都放大了 1000 倍)
*/
ms = (ngx_msec_int_t) (now - lr->last);
excess = lr->excess - ctx->rate * ngx_abs(ms) / 1000 + 1000;
if (excess < 0) {
/* 全部处理完了 */
excess = 0;
}
*ep = excess;
if ((ngx_uint_t) excess > limit->burst) {
/* 这段时间处理之后,遗留的请求数超出了突发请求限制 */
return NGX_BUSY;
}
if (account) {
/* 这个请求到了最后一个“域”的限制
* 更新上次遗留请求数和上次访问时间
* 返回 NGX_OK 表示没有达到请求限制的频率
*/
lr->excess = excess;
lr->last = now;
return NGX_OK;
}
/*
* count++;
* 把这个“域”的 ctx->node 指针指向这个节点
* 这个在 ngx_http_limit_req_handler 里用到
*/
lr->count++;
/* 这一步是为了在 ngx_http_limit_req_account 里更新这些访问过的节点的信息 */
ctx->node = lr;
/* 返回 NGX_AGAIN,会进行下一个“域”的检查 */
return NGX_AGAIN;
}
node = (rc < 0) ? node->left : node->right;
}
/* 没有在红黑树上找到节点 */
*ep = 0;
/*
* 新建一个节点,需要的内存大小,包括了红黑树节点大小
* ngx_http_limit_req_node_t 还有 key 的长度
*/
size = offsetof(ngx_rbtree_node_t, color)
+ offsetof(ngx_http_limit_req_node_t, data)
+ key->len;
/* 先进行 LRU 淘汰,传入 n=1,则最多淘汰 2 个节点 */
ngx_http_limit_req_expire(ctx, 1);
/* 由于调用 ngx_http_limit_req_lookup 之前已经上过锁,这里不用再上 */
node = ngx_slab_alloc_locked(ctx->shpool, size);
if (node == NULL) {
/* 分配失败考虑再进行一次 LRU 淘汰,及时释放共享内存空间,这里 n = 0,最多淘汰 3 个节点 */
ngx_http_limit_req_expire(ctx, 0);
node = ngx_slab_alloc_locked(ctx->shpool, size);
if (node == NULL) {
ngx_log_error(NGX_LOG_ALERT, ngx_cycle->log, 0,
"could not allocate node%s", ctx->shpool->log_ctx);
return NGX_ERROR;
}
}
/* 设置相关的信息 */
node->key = hash;
lr = (ngx_http_limit_req_node_t *) &node->color;
lr->len = (u_short) key->len;
lr->excess = 0;
ngx_memcpy(lr->data, key->data, key->len);
ngx_rbtree_insert(&ctx->sh->rbtree, node);
ngx_queue_insert_head(&ctx->sh->queue, &lr->queue);
if (account) {
/* 同样地,如果这是最后一个“域”的检查,就更新 last 和 count,返回 NGX_OK */
lr->last = now;
lr->count = 0;
return NGX_OK;
}
/* 否则就令 count = 1,把节点放到 ctx 上 */
lr->last = 0;
lr->count = 1;
ctx->node = lr;
return NGX_AGAIN;
}
5、Nginx 漏桶算法核心逻辑
这段代码是 Nginx ngx_http_limit_req_module 模块的核心部分,主要功能是检查当前请求是否超过限流阈值。
ngx_http_limit_req_module 结合了漏桶算法(leaky bucket),用于处理请求速率限制和突发流量。
这里不对 ngx_http_limit_req_module 的c代码做介绍, 下面尼恩用java 模拟一下上面的 nginx语言代码,大概是下面这样的:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
// 漏桶限流器类
public class LeakyBucketRateLimiter {
// 漏桶容量,即漏桶最多能存储的请求数量
private final int capacity;
// 漏桶处理请求的速率,单位为每秒处理的请求数
private final int rate;
// 存储请求的队列,模拟漏桶
private final BlockingQueue<Integer> bucket;
// 上次处理请求的时间戳,单位为毫秒
private long lastProcessTime;
/**
* 构造函数,初始化漏桶限流器
* @param capacity 漏桶容量
* @param rate 漏桶处理请求的速率
*/
public LeakyBucketRateLimiter(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
this.bucket = new LinkedBlockingQueue<>(capacity);
this.lastProcessTime = System.currentTimeMillis();
}
/**
* 尝试添加一个请求到漏桶中
* @return 如果请求被接受返回 true,否则返回 false
*/
public synchronized boolean addRequest() {
// 计算从上次处理请求到现在应该流出的请求数量
long now = System.currentTimeMillis();
int leakedCount = (int) ((now - lastProcessTime) * rate / 1000);
if (leakedCount > 0) {
// 移除已经流出的请求
for (int i = 0; i < Math.min(leakedCount, bucket.size()); i++) {
bucket.poll();
}
lastProcessTime = now;
}
// 判断漏桶是否还有空间
if (bucket.size() < capacity) {
// 漏桶未满,将请求放入桶中
bucket.offer(1);
return true;
} else {
// 漏桶已满,拒绝请求
return false;
}
}
public static void main(String[] args) {
// 创建一个漏桶限流器,容量为 10,每秒处理 2 个请求
LeakyBucketRateLimiter limiter = new LeakyBucketRateLimiter(10, 2);
for (int i = 0; i < 20; i++) {
if (limiter.addRequest()) {
System.out.println("Request " + i + " accepted");
} else {
System.out.println("Request " + i + " rejected");
}
try {
// 模拟请求间隔 100 毫秒
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
关键性的代码是
//代码1
int leakedCount = (int) ((now - lastProcessTime) * rate / 1000);
// 代码2
if (leakedCount > 0) {
// 代码3
// 移除已经流出的请求
for (int i = 0; i < Math.min(leakedCount, bucket.size()); i++) {
bucket.poll();
}
// 代码4
lastProcessTime = now;
}
先看下面的代码1:
int leakedCount = (int) ((now - lastProcessTime) * rate / 1000);
now 和 lastProcessTime
now是通过System.currentTimeMillis()获取的当前系统时间戳,单位为毫秒。它代表当前请求到来时的时间点。lastProcessTime记录的是上一次处理请求的时间戳,同样以毫秒为单位。now - lastProcessTime时间间隔, 计算出从上次处理请求到当前时刻所经过的时间间隔,单位是毫秒。
rate:
表示漏桶处理请求的速率,单位是每秒处理的请求数。
例如,若 rate 为 2,意味着漏桶每秒可以处理 2 个请求。
(now - lastProcessTime) * rate:
这一步计算在 now - lastProcessTime 这段时间内,如果漏桶一直以 rate 的速率处理请求,理论上可以处理的请求数量。
由于 rate 是每秒处理的请求数,而 now - lastProcessTime 是时间间隔(毫秒),所以这里得到的结果是一个基于毫秒时间间隔的理论请求处理数量。
(now - lastProcessTime) * rate / 1000:
因为 rate 是每秒处理的请求数,而 now - lastProcessTime 是毫秒级的时间间隔,为了将时间单位统一为秒,需要将前面计算的结果除以 1000(1 秒 = 1000 毫秒)。
这样得到的结果就是在 now - lastProcessTime 这段时间内,漏桶实际应该处理的请求数量。
再看下面的代码2
if (leakedCount > 0) {
// 移除已经流出的请求
for (int i = 0; i < Math.min(leakedCount, bucket.size()); i++) {
bucket.poll();
}
lastProcessTime = now;
}
当 leakedCount > 0 时,说明从上次处理请求到现在已经过去了一段时间,漏桶应该有请求流出,所以需要执行移除请求的操作。
如果 leakedCount 为 0,说明时间间隔过短,还没有到下一次应该处理请求的时间,不需要进行移除操作。
再看下面的代码3
for (int i = 0; i < Math.min(leakedCount, bucket.size()); i++) {
bucket.poll();
}
-
Math.min(leakedCount, bucket.size()):
取
leakedCount和当前漏桶中实际请求数量(bucket.size())的最小值。这是因为在某些情况下,计算得出的应该流出的请求数量可能会超过漏桶中实际存在的请求数量。
例如,计算得出应该流出 5 个请求,但漏桶中实际只有 3 个请求,那么只能移除 3 个请求。所以使用
Math.min函数确保不会移除超过漏桶中实际请求数量的请求。 -
bucket.poll():
bucket是一个BlockingQueue,用于存储漏桶中的请求。poll()方法是BlockingQueue接口提供的方法,它的作用是移除并返回队列的头部元素。在这个循环中,每次调用
bucket.poll()就会从漏桶中移除一个请求,模拟漏桶中请求的流出。
再看下面的代码4
lastProcessTime = now;
lastProcessTime 记录的是上一次处理请求的时间。
在完成了移除请求的操作后,需要将 lastProcessTime 更新为当前时间(now),这样下次新的请求到来时,就可以基于这个新的时间点来计算从这次处理请求到下一次请求到来时应该流出的请求数量。
仔细去看 Nginx 漏桶算法核心逻辑,和上面的java 逻辑是差不多的。
上面的逻辑,和前面的简单例子不同,没有用定时器去进行 请求的 漏出,而是通过时间范围一次性去减掉 流出的请求。
所以,漏桶其实很简单的。
Nginx 为什么不用令牌桶算法?
接下来,可以给面试官吹吹,Nginx 为什么不用令牌桶算法?
Nginx 是一个高性能的 HTTP 服务器和反向代理服务器,广泛用于负载均衡、API 网关、静态资源服务等场景。在限流方面,Nginx 使用的是 漏桶算法(Leaky Bucket Algorithm),而不是 令牌桶算法(Token Bucket Algorithm)。
Nginx 选择漏桶算法而不是令牌桶算法的原因主要是:平滑流量,避免突发流量对后端服务造成冲击
1. Nginx 限流设计目标:平滑流量
Nginx 的核心设计目标之一是 平滑流量,避免突发流量对后端服务造成冲击。
Nginx 作为反向代理或负载均衡器,通常需要保护后端服务免受突发流量的影响,因此漏桶算法更符合其设计目标。
漏桶算法以固定的速率处理请求,能够将突发的流量平滑为稳定的输出流量,非常适合 Nginx 的使用场景。
-
漏桶算法的特点:
以固定速率处理请求。
能够有效平滑突发流量。
-
令牌桶算法的特点:
允许突发流量,适合需要处理突发请求的场景。
Nginx 加入了burst 的 突发流量队列, 允许了突发流量。
2. Nginx 限流防止突发流量对后端服务的冲击
Nginx 通常用于保护后端服务(如应用服务器、数据库等),避免它们被突发流量压垮。
漏桶算法能够严格限制请求速率,确保后端服务不会过载。
-
漏桶算法的效果:
严格限制请求速率,避免突发流量。
适合保护后端服务的场景。
-
令牌桶算法的效果:
允许突发流量,可能对后端服务造成压力。
Nginx 的设计目标之一是保护后端服务,因此漏桶算法更适合其需求。
3. Nginx 限流配置简单,易于理解
Nginx 的限流模块(如 ngx_http_limit_req_module)使用漏桶算法,配置简单且易于理解。
用户只需要设置速率和桶大小即可实现限流。
-
漏桶算法的配置:
只需要设置速率(rate)和桶大小(burst)。
例如:
limit_req zone=one burst=5 rate=10r/s; -
令牌桶算法的配置:
需要设置令牌生成速率和桶容量。
配置相对复杂。
Nginx 的设计哲学之一是简单易用,漏桶算法的配置方式更符合这一理念。
4. 漏桶算法的公平性
漏桶算法以固定的速率处理请求,确保每个请求都能按照先到先得的原则被处理。
这种公平性非常适合 Nginx 的使用场景。
-
漏桶算法的公平性:
请求按顺序处理,避免某些请求长时间得不到处理。
-
令牌桶算法的公平性:
允许突发流量,可能导致某些请求被优先处理。
Nginx 作为反向代理或负载均衡器,需要公平地处理所有请求,因此漏桶算法更适合。
5. 令牌桶算法的局限性
虽然令牌桶算法在某些场景下非常有用,但它也存在一些局限性,不适合 Nginx 的设计目标:
-
允许突发流量:
令牌桶算法允许突发流量,可能对后端服务造成压力。
-
实现复杂度较高:
令牌桶算法需要维护令牌生成逻辑,增加了实现的复杂性和性能开销。
-
不适合保护后端服务:
Nginx 的核心目标之一是保护后端服务,而令牌桶算法可能无法有效防止突发流量对后端的冲击。
Sentinel 什么场景用漏桶,什么场景令牌桶 ,什么场景滑动窗口?
接下来,可以给面试官吹吹,Sentinel 什么场景用漏桶,什么场景令牌桶 ,什么场景滑动窗口?
前面讲了了,。限流算法常见的有三种实现:滑动时间窗口,令牌桶算法,漏桶算法。
Sentinel 什么场景用漏桶,什么场景令牌桶 ,什么场景滑动窗口?
而sentinel内部比较复杂:
-
默认限流模式是基于滑动时间窗口算法
针对资源做统计,一个资源队列 + 一个滑动窗口算法,统计的数据较少,内存使用不高。
-
流控效果为排队等待的限流模式基于漏桶算法
需要排队等待效果
-
而流控规则的热点参数限流 是基于令牌桶算法
参数较多,只需要记录参数对应的请求时间信息
在 Sentinel 中,不同的限流算法对应着不同的源码实现和应用场景,本文太长,下一篇文章,尼恩给大家做具体展开吧。
单体限流,能支持10Wqps高并发吗?
随着微服务架构的普及,系统的服务通常会部署在多台服务器上,此时就需要分布式限流来保证整个系统的稳定性。
单体限流,大部分场景是不行的。
单体限流指针对单一服务器的情况,通过限制单台服务器在单位时间内处理的请求数量,防止服务器过载。
于是,我们需要 分布式限流。
分布式限流包括:
- 中心化的限流
- 中心化+ 本地结合的联邦式限流
先看 基于中心化的限流方案 。
基于中心化的限流方案
接下来,可以给面试官吹吹,基于中心化的限流方案
通过一个中心化的限流器来控制所有服务器的请求。实现方式:
- 选择一个中心化的组件,例如— Redis。
- 定义限流规则,例如:可以设置每秒钟允许的最大请求数(QPS),并将这个值存储在 Redis 中。
- 对于每个请求,服务器需要先向 Redis 请求令牌。
- 如果获取到令牌,说明请求可以被处理;如果没有获取到令牌,说明请求被限流,可以返回一个错误信息或者稍后重试。
高性能的中心化组件可以使用Redis+Lua来开发,京东的抢购就是使用Redis+Lua完成的中心化 限流。
并且无论是Nginx外部网关还是Zuul内部网关,都可以使用Redis+Lua限流组件。
自研中心化限流组件:redis+lua分布式限流组件
接下来,可以给面试官吹吹,自研中心化限流组件:redis+lua分布式限流组件
--- 此脚本的环境: redis 内部,不是运行在 nginx 内部
---方法:申请令牌
--- -1 failed
--- 1 success
--- @param key key 限流关键字
--- @param apply 申请的令牌数量
local function acquire(key, apply)
local times = redis.call('TIME');
-- times[1] 秒数 -- times[2] 微秒数
local curr_mill_second = times[1] * 1000000 + times[2];
curr_mill_second = curr_mill_second / 1000;
local cacheInfo = redis.pcall("HMGET", key, "last_mill_second", "curr_permits", "max_permits", "rate")
--- 局部变量:上次申请的时间
local last_mill_second = cacheInfo[1];
--- 局部变量:之前的令牌数
local curr_permits = tonumber(cacheInfo[2]);
--- 局部变量:桶的容量
local max_permits = tonumber(cacheInfo[3]);
--- 局部变量:令牌的发放速率
local rate = cacheInfo[4];
--- 局部变量:本次的令牌数
local local_curr_permits = 0;
if (type(last_mill_second) ~= 'boolean' and last_mill_second ~= nil) then
-- 计算时间段内的令牌数
local reverse_permits = math.floor(((curr_mill_second - last_mill_second) / 1000) * rate);
-- 令牌总数
local expect_curr_permits = reverse_permits + curr_permits;
-- 可以申请的令牌总数
local_curr_permits = math.min(expect_curr_permits, max_permits);
else
-- 第一次获取令牌
redis.pcall("HSET", key, "last_mill_second", curr_mill_second)
local_curr_permits = max_permits;
end
local result = -1;
-- 有足够的令牌可以申请
if (local_curr_permits - apply >= 0) then
-- 保存剩余的令牌
redis.pcall("HSET", key, "curr_permits", local_curr_permits - apply);
-- 为下次的令牌获取,保存时间
redis.pcall("HSET", key, "last_mill_second", curr_mill_second)
-- 返回令牌获取成功
result = 1;
else
-- 返回令牌获取失败
result = -1;
end
return result
end
--eg
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , acquire 1 1
-- 获取 sha编码的命令
-- /usr/local/redis/bin/redis-cli -a 123456 script load "$(cat /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua)"
-- /usr/local/redis/bin/redis-cli -a 123456 script exists "cf43613f172388c34a1130a760fc699a5ee6f2a9"
-- /usr/local/redis/bin/redis-cli -a 123456 evalsha "cf43613f172388c34a1130a760fc699a5ee6f2a9" 1 "rate_limiter:seckill:1" init 1 1
-- /usr/local/redis/bin/redis-cli -a 123456 evalsha "cf43613f172388c34a1130a760fc699a5ee6f2a9" 1 "rate_limiter:seckill:1" acquire 1
--local rateLimiterSha = "e4e49e4c7b23f0bf7a2bfee73e8a01629e33324b";
---方法:初始化限流 Key
--- 1 success
--- @param key key
--- @param max_permits 桶的容量
--- @param rate 令牌的发放速率
local function init(key, max_permits, rate)
local rate_limit_info = redis.pcall("HMGET", key, "last_mill_second", "curr_permits", "max_permits", "rate")
local org_max_permits = tonumber(rate_limit_info[3])
local org_rate = rate_limit_info[4]
if (org_max_permits == nil) or (rate ~= org_rate or max_permits ~= org_max_permits) then
redis.pcall("HMSET", key, "max_permits", max_permits, "rate", rate, "curr_permits", max_permits)
end
return 1;
end
--eg
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , init 1 1
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua "rate_limiter:seckill:1" , init 1 1
---方法:删除限流 Key
local function delete(key)
redis.pcall("DEL", key)
return 1;
end
--eg
-- /usr/local/redis/bin/redis-cli --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , delete
local key = KEYS[1]
local method = ARGV[1]
if method == 'acquire' then
return acquire(key, ARGV[2], ARGV[3])
elseif method == 'init' then
return init(key, ARGV[2], ARGV[3])
elseif method == 'delete' then
return delete(key)
else
--ignore
end
第三方中心化限流组件:Redisson 中心化限流实现
接下来,可以给面试官吹吹,第三方中心化限流组件:Redisson 中心化限流实现, 可以吹吹 源码
除了自研,还可以使用 成熟的,第三方中心化限流组件。
Redisson 提供了一个高性能的分布式限流组件 RRateLimiter,基于 Redis 实现,支持令牌桶算法。
RRateLimiter 采用令牌桶思想和固定时间窗口,trySetRate方法设置桶的大小,利用redis key过期机制达到时间窗口目的,控制固定时间窗口内允许通过的请求量。
spring cloud gateway集成redis限流,但属于网关层限流
1. 使用 RRateLimiter 的demo
首先,通过一个简单的示例了解如何使用 RRateLimiter,它创建了一个限流器并启动多个线程来获取令牌:
import org.redisson.Redisson; // 导入 Redisson 的核心类,用于创建 Redisson 客户端
import org.redisson.api.RRateLimiter; // 导入 RRateLimiter 接口,用于实现分布式限流
import org.redisson.api.RedissonClient; // 导入 RedissonClient 接口,用于与 Redis 进行交互
import org.redisson.config.Config; // 导入 Redisson 的配置类,用于配置 Redis 连接
import java.util.concurrent.CountDownLatch; // 导入 CountDownLatch 类,用于控制线程同步
public class RateLimiterDemo { // 定义一个公共类 RateLimiterDemo
public static void main(String[] args) throws InterruptedException { // 主方法,程序入口,可能抛出 InterruptedException
RRateLimiter rateLimiter = createRateLimiter(); // 创建一个 RRateLimiter 实例
int totalThreads = 20; // 定义总线程数为 20
CountDownLatch latch = new CountDownLatch(totalThreads); // 创建一个 CountDownLatch 实例,初始计数为 totalThreads
long startTime = System.currentTimeMillis(); // 记录开始时间,用于计算总耗时
for (int i = 0; i < totalThreads; i++) { // 循环创建并启动 20 个线程
new Thread(() -> { // 创建一个新线程
rateLimiter.acquire(1); // 每个线程尝试获取 1 个令牌,若令牌不足则阻塞等待
latch.countDown(); // 线程完成后,调用 countDown() 方法减少计数器
}).start(); // 启动线程
}
latch.await(); // 主线程等待,直到所有子线程完成
System.out.println("Total elapsed time: " + (System.currentTimeMillis() - startTime) + " ms"); // 打印总耗时
}
/**
* 创建并配置 RRateLimiter 的方法
*
* @return 配置好的 RRateLimiter 实例
*/
private static RRateLimiter createRateLimiter() { // 创建并配置 RRateLimiter 的方法
Config config = new Config(); // 创建一个新的 Redisson 配置实例
config.useSingleServer() // 配置使用单一 Redis 服务器
.setAddress("redis://127.0.0.1:6379") // 设置 Redis 服务器地址
.setTimeout(1000000); // 设置连接超时时间(毫秒)
RedissonClient redisson = Redisson.create(config); // 根据配置创建一个 Redisson 客户端实例
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter"); // 获取名为 "myRateLimiter" 的 RRateLimiter 实例
rateLimiter.trySetRate(RRateLimiter.RateType.OVERALL, 3, 5, RateIntervalUnit.SECONDS); // 初始化限流器,设置全局速率为每秒5个令牌
return rateLimiter; // 返回配置好的限流器实例
}
}
以下是对 Redisson 限流组件的源码分析和关键实现原理的总结:
2. 限流器初始化
限流器通过 RedissonClient.getRateLimiter(String name) 获取,并通过 trySetRate 方法设置限流规则。
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter");
rateLimiter.trySetRate(RateType.OVERALL, 3, 5, RateIntervalUnit.SECONDS);
-
RateType.OVERALL:
表示所有实例共享同一个限流器。
-
trySetRate 方法:
通过 Redis 的
EVAL命令设置限流规则,包括令牌生成速率(rate)、时间间隔(interval)和限流类型(type)。
rateLimiter.trySetRate(RateType.OVERALL, 3, 5, RateIntervalUnit.SECONDS); 这一句的意思:
- 设置全局限流规则:所有客户端共享同一个限流器。
- 限流规则:每 5 秒内最多允许 3 个请求通过。
- 时间单位:时间间隔为秒。
Redisson 的限流器支持分布式环境,多个服务实例可以共享同一个限流器。
- RateType.OVERALL:所有实例共享同一个限流器。
- RateType.PER_CLIENT:每个客户端实例独立限流。
限流规则存储在 Redis 的哈希结构中,例如:
HSET myRateLimiter rate 3 interval 5000 type 0
- rate:令牌生成速率。
- interval:时间间隔(毫秒)。
- type:限流类型(
0表示OVERALL,1表示PER_CLIENT)。
3. trySetRateAsync 设置限流规则源码分析
trySetRate方法设置桶的大小
@Override
public RFuture<Boolean> trySetRateAsync(RateType type, long rate, long rateInterval, RateIntervalUnit unit) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"redis.call('hsetnx', KEYS[1], 'rate', ARGV[1]);" +
"redis.call('hsetnx', KEYS[1], 'interval', ARGV[2]);" +
"return redis.call('hsetnx', KEYS[1], 'type', ARGV[3]);",
Collections.<Object>singletonList(getName()), rate, unit.toMillis(rateInterval), type.ordinal());
}
使用 EVAL 命令原子性地设置限流规则。
@Override
public RFuture<Boolean> trySetRateAsync(RateType type, long rate, long rateInterval, RateIntervalUnit unit)
这是一个异步方法,用于尝试设置限流器的速率。
参数:
-
type:限流类型(RateType),可以是 全局限流 或 单客户端限流。 -
rate:限流速率,表示在rateInterval时间范围内允许的请求数量。 -
rateInterval:限流时间间隔。 -
unit:时间间隔的单位(如秒、毫秒等)。 -
返回值:返回一个
RFuture<Boolean>,表示异步操作的结果。true表示设置成功,false表示设置失败(通常是因为限流器已经存在)。
trySetRateAsync 调用的是 commandExecutor.evalWriteAsync方法。
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"redis.call('hsetnx', KEYS[1], 'rate', ARGV[1]);" +
"redis.call('hsetnx', KEYS[1], 'interval', ARGV[2]);" +
"return redis.call('hsetnx', KEYS[1], 'type', ARGV[3]);",
Collections.<Object>singletonList(getName()), rate, unit.toMillis(rateInterval), type.ordinal());
commandExecutor.evalWriteAsync
执行一个 Lua 脚本,用于在 Redis 中原子性地设置限流器的参数。
参数:
getName():限流器的名称,作为 Redis 的 Key。LongCodec.INSTANCE:用于编码和解码 Long 类型的值。RedisCommands.EVAL_BOOLEAN:表示 Lua 脚本的返回类型为布尔值。- Lua 脚本:具体的限流逻辑。
Collections.singletonList(getName()):Lua 脚本的KEYS参数,传入限流器的名称。rate、unit.toMillis(rateInterval)、type.ordinal():Lua 脚本的ARGV参数,传入限流速率、时间间隔和限流类型。
具体的限流 Lua 脚本
redis.call('hsetnx', KEYS[1], 'rate', ARGV[1]);
redis.call('hsetnx', KEYS[1], 'interval', ARGV[2]);
return redis.call('hsetnx', KEYS[1], 'type', ARGV[3]);
作用:在 Redis 中原子性地设置限流器的参数。
逐行分析:
-
redis.call(‘hsetnx’, KEYS[1], ‘rate’, ARGV[1]):
使用
hsetnx命令将 限流速率(rate)写入 Redis 的 Hash 结构中。hsetnx 是 “Hash Set If Not Exists” 的缩写,只有在字段不存在时才会设置值。
KEYS[1] 是限流器的名称,
ARGV[1]是限流速率。 -
redis.call(‘hsetnx’, KEYS[1], ‘interval’, ARGV[2]):
使用
hsetnx命令将 限流时间间隔(interval)写入 Redis 的 Hash 结构中。ARGV[2]是时间间隔(以毫秒为单位)。 -
return redis.call(‘hsetnx’, KEYS[1], ‘type’, ARGV[3]):
使用
hsetnx命令将限流类型(type)写入 Redis 的 Hash 结构中。ARGV[3]是限流类型的枚举值(RateType.ordinal())。返回
hsetnx的结果,表示是否设置成功。
trySetRateAsync 方法通过 Lua 脚本在 Redis 中原子性地设置限流器的参数。该方法的设计充分考虑了原子性、灵活性和性能,是 Redisson 分布式限流功能的核心实现之一。使用 hsetnx 命令确保参数只设置一次,避免重复设置。异步执行提高了性能,适用于高并发场景。
具体的特点如下:
-
原子性操作:
使用 Lua 脚本确保设置限流参数的原子性,避免并发问题。
hsetnx命令保证只有在字段不存在时才会设置值,避免覆盖已有配置。 -
异步执行:
通过
evalWriteAsync方法异步执行 Lua 脚本,提高性能。 -
灵活性:
支持动态设置限流速率、时间间隔和限流类型,适用于不同的限流场景。
-
Redis 数据结构:
使用 Redis 的 Hash 结构存储限流器的参数,便于管理和扩展
4. 获取令牌
限流的核心逻辑是通过 tryAcquire 方法尝试获取令牌。如果获取成功,请求通过;否则,请求被拒绝。
boolean allowed = rateLimiter.tryAcquire(1);
if (!allowed) {
throw new RuntimeException("Rate limit exceeded");
}
tryAcquire 方法的获取令牌:
- 如果当前时间窗口内有足够令牌,则减少令牌数量并返回成功。
- 如果令牌不足,返回失败。
5. tryAcquireAsync 方法令牌桶限流源码分析**
private <T> RFuture<T> tryAcquireAsync(RedisCommand<T> command, Long value) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"local rate = redis.call('hget', KEYS[1], 'rate');" +
"local interval = redis.call('hget', KEYS[1], 'interval');" +
"local type = redis.call('hget', KEYS[1], 'type');" +
"assert(rate ~= false and interval ~= false and type ~= false, 'RateLimiter is not initialized')" +
"local valueName = KEYS[2];" +
"if type == 1 then " +
"valueName = KEYS[3];" +
"end;" +
"local currentValue = redis.call('get', valueName);" +
"if currentValue ~= false then " +
"if tonumber(currentValue) < tonumber(ARGV[1]) then " +
"return redis.call('pttl', valueName);" +
"else " +
"redis.call('decrby', valueName, ARGV[1]);" +
"return nil;" +
"end;" +
"else " +
"redis.call('set', valueName, rate, 'px', interval);" +
"redis.call('decrby', valueName, ARGV[1]);" +
"return nil;" +
"end;",
Arrays.<Object>asList(getName(), getValueName(), getClientValueName()), value);
}
核心是lua脚本 :
-- 获取限流器的速率、时间区间和类型
local rate = redis.call("hget", KEYS[1], "rate") -- 从哈希表中获取速率
local interval = redis.call("hget", KEYS[1], "interval") -- 获取时间区间(毫秒)
local type = redis.call("hget", KEYS[1], "type") -- 获取限流器的类型(单机或集群)
assert(rate ~= false and interval ~= false and type ~= false, "RateLimiter is not initialized") -- 确保限流器已初始化
-- 默认情况下,使用 {name}:value 和 {name}:permits
local valueName = KEYS[2] -- 当前令牌数的键名
local permitsName = KEYS[4] -- 记录请求的有序集合键名
-- 如果类型为 "1"(单机模式),则使用不同的键名
if type == "1" then
valueName = KEYS[3] -- 单机模式下的令牌数键名
permitsName = KEYS[5] -- 单机模式下的有序集合键名
end
-- 确保请求的令牌数不超过限流器的速率
assert(tonumber(rate) >= tonumber(ARGV[1]), "Requested permits amount could not exceed defined rate")
-- 获取当前剩余的令牌数
local currentValue = redis.call("get", valueName)
-- 第一次请求直接走else
-- 第二次请求因为 valueName 更新有值,走if
if currentValue ~= false then
-- 获取已过期的请求(初始时间 至 (当前时间(ARGV[2])-时间间隔(interval)) 准备清理失效的令牌数据
local expiredValues = redis.call("zrangebyscore", permitsName, 0, tonumber(ARGV[2]) - interval)
local released = 0 -- 初始化拟新增失效令牌数
-- 遍历过期的请求,释放相应的令牌
for i, v in ipairs(expiredValues) do
local random, permits = struct.unpack("fI", v)
released = released + permits
end
-- 如果有释放的令牌,更新当前可用令牌数并移除过期的请求
if released > 0 then
redis.call("zrem", permitsName, unpack(expiredValues)) -- 清除 permitsName 中包含 expiredValues 的数据
currentValue = tonumber(currentValue) + released -- 清理失效令牌后计算总可用令牌数
redis.call("set", valueName, currentValue) -- 更新可用令牌
end
-- 如果当前令牌数不足以满足请求
if tonumber(currentValue) < tonumber(ARGV[1]) then
-- 计算需要等待的时间
local nearest = redis.call('zrangebyscore', permitsName, '(' .. (tonumber(ARGV[2]) - interval), tonumber(ARGV[2]), 'withscores', 'limit', 0, 1) -- 找到最近一次的请求时间 nearest
local random, permits = struct.unpack("fI", nearest[1]) -- 解压为时间戳+请求令牌数
-- 返回等待时间,也可以写为 tonumber(nearest[2])+interval-tonumber(ARGV[2])
return tonumber(nearest[2]) - (tonumber(ARGV[2]) - interval) -- nearest[2] 为上行的 random
else
-- 当前可用令牌数足够,记录此次请求并减少可用令牌数
redis.call("zadd", permitsName, ARGV[2], struct.pack("fI", ARGV[3], ARGV[1])) -- 记录请求记录
redis.call("decrby", valueName, ARGV[1]) -- 更新可用令牌数 valueName -= ARGV[1](请求令牌数)
return nil -- 成功获取令牌
end
else
-- 第一次请求,初始化令牌数和有序集合
redis.call("set", valueName, rate) -- 设置当前令牌数为最大速率值
redis.call("zadd", permitsName, ARGV[2], struct.pack("fI", ARGV[3], ARGV[1])) -- 记录请求记录
redis.call("decrby", valueName, ARGV[1]) -- 更新可用令牌数 valueName -= ARGV[1](请求令牌数)
return nil -- 成功获取令牌
end
1. 初始化检查 代码
首先,确保限流器的速率(rate)、时间间隔(interval)和类型(type)已初始化。
local rate = redis.call("hget", KEYS[1], "rate")
local interval = redis.call("hget", KEYS[1], "interval")
local type = redis.call("hget", KEYS[1], "type")
assert(rate ~= false and interval ~= false and type ~= false, "RateLimiter is not initialized")
说明:
- 从 Redis 的 Hash 结构中获取限流器的配置。
- 如果配置不存在,抛出异常,提示限流器未初始化。
2. 获取当前令牌数
获取当前可用的令牌数。
local currentValue = redis.call("get", valueName)
说明:
valueName是存储当前令牌数的键名。- 如果
currentValue为false,表示第一次请求,需要初始化令牌数。
3. 处理第一次请求
初始化令牌数和请求记录。
redis.call("set", valueName, rate)
redis.call("zadd", permitsName, ARGV[2], struct.pack("fI", ARGV[3], ARGV[1]))
redis.call("decrby", valueName, ARGV[1])
return nil
说明:
- 将当前令牌数设置为最大速率值(
rate)。 - 使用有序集合(
permitsName)记录当前请求的时间戳和令牌数。 - 减少当前令牌数,并返回
nil表示成功。
4. 处理非第一次请求
检查过期令牌, 并更新当前令牌数。
-- 获取已过期的请求(初始时间 至 (当前时间(ARGV[2])-时间间隔(interval)) 准备清理失效的令牌数据
local expiredValues = redis.call("zrangebyscore", permitsName, 0, tonumber(ARGV[2]) - interval)
local released = 0 -- 初始化拟新增失效令牌数
-- 遍历过期的请求,释放相应的令牌
for i, v in ipairs(expiredValues) do
local random, permits = struct.unpack("fI", v)
released = released + permits
end
if released > 0 then
redis.call("zrem", permitsName, unpack(expiredValues))
currentValue = tonumber(currentValue) + released
redis.call("set", valueName, currentValue)
end
- 查找已过期的请求(时间戳小于当前时间减去时间间隔)。
- 计算并释放过期请求占用的令牌数。
- 更新当前令牌数。
5. 检查令牌是否足够
判断当前令牌数是否满足请求。
-- 如果当前令牌数不足以满足请求
if tonumber(currentValue) < tonumber(ARGV[1]) then
-- 计算需要等待的时间
local nearest = redis.call('zrangebyscore', permitsName, '(' .. (tonumber(ARGV[2]) - interval), tonumber(ARGV[2]), 'withscores', 'limit', 0, 1) -- 找到最近一次的请求时间 nearest
local random, permits = struct.unpack("fI", nearest[1]) -- 解压为时间戳+请求令牌数
-- 返回等待时间,也可以写为 tonumber(nearest[2])+interval-tonumber(ARGV[2])
return tonumber(nearest[2]) - (tonumber(ARGV[2]) - interval) -- nearest[2] 为上行的 random
else
-- 当前可用令牌数足够,记录此次请求并减少可用令牌数
redis.call("zadd", permitsName, ARGV[2], struct.pack("fI", ARGV[3], ARGV[1])) -- 记录请求记录
redis.call("decrby", valueName, ARGV[1]) -- 更新可用令牌数 valueName -= ARGV[1](请求令牌数)
return nil -- 成功获取令牌
end
说明:
- 如果令牌不足,计算需要等待的时间,并返回等待时间。
- 如果令牌足够,记录当前请求并减少令牌数,返回
nil表示成功。
关键点总结
- 初始化检查:
- 确保限流器的配置已正确初始化。
- 第一次请求:
- 初始化令牌数和请求记录。
- 非第一次请求:
- 检查并释放过期令牌,更新当前令牌数。
- 令牌检查:
- 判断当前令牌数是否满足请求,如果不足则返回等待时间。
- 数据结构:
- 使用 Redis 的 Hash 结构存储限流器配置。
- 使用有序集合(
zset)记录请求的时间戳和令牌数。
5. 使用场景
Redisson 的限流器适用于多种场景,例如:
- 接口限流:限制接口的访问频率。
- 用户限流:基于用户 ID 限制请求。
- IP 限流:限制来自特定 IP 的请求。
6. 优势
- 高性能:基于 Redis 的高性能和原子性操作。
- 分布式支持:多个服务实例可以共享同一个限流器。
- 灵活配置:支持多种限流类型和时间单位。
通过 Redisson 的 RRateLimiter,开发者可以轻松实现分布式限流功能,满足高并发场景下的需求。
高手级答案:80分答案
尼恩提示,讲完中心化 , 可以得到 80分了。
但是要直接拿到大厂offer,或者 offer 直提,需要 120分答案。

尼恩带大家继续。
中心化限流能支持10Wqps高并发吗?
Redisson 的 RRateLimiter 是一个基于 Redis 实现的分布式限流组件,支持高并发场景。
然而,不能 支持 10万 QPS 的限流。
为什么?
关键限制
-
Redis 单实例性能:
RRateLimiter的限流 QPS 上限取决于 Redis 单实例的性能。如果 Redis 单实例的性能瓶颈在 1 万 QPS 左右,那么单个RRateLimiter无法突破这一限制。 -
单限流器的性能瓶颈:
单个
RRateLimiter的性能受限于 Redis 的读写能力。即使 Redis 集群的总体性能较高,单个限流器的 QPS 上限仍然受限于单个 Redis 实例。
Redisson 的 RRateLimiter 本身无法直接支持 10万 QPS 的限流,因为其性能受限于单个 Redis 实例的处理能力。不过,通过拆分多个限流器和优化分布式架构,可以实现更高的总体 QP
10Wqps的高扩展、自伸缩、自适应限流策略
接下来, 高潮来了
可以给面试官吹吹,10Wqps的高扩展、自伸缩、自适应限流策略
Sentinel + Nacos 结合的 中心协调+本地流控结合的 分布式方案,实现 10Wqps的高扩展、自伸缩、自适应限流策略
架构设计:中心协调 + 本地流控结合
- 中心协调:通过 Nacos 作为配置中心,集中管理限流规则,确保全局一致性。
- 本地流控:每个服务实例使用 Sentinel 进行本地限流,减少对中心节点的依赖,提高性能。
分布式架构
- Sentinel:本地流控,作为流量控制、熔断降级的中间件,负责本地流控和规则检查。Sentinel 提供本地限流能力,结合 Nacos 的动态配置功能,实现规则的实时更新
- Nacos: 中心协调,充当配置中心,对限流规则进行集中管理和动态推送。使用 Spring Cloud Alibaba 和 Nacos 实现服务注册与发现,确保服务的动态扩展。
- 中心协调:借助 Nacos 存储和推送限流规则,保证各节点规则的一致性。
- 本地流控:每个节点依据本地的 Sentinel 实例执行限流操作,降低对中心节点的依赖。
中心协调 + 本地流控结合 特点
1 规则动态更新
- 将 Sentinel 的限流规则存储在 Nacos 中,通过 Nacos 的配置管理功能动态更新限流规则。
- Sentinel 支持从 Nacos 拉取规则,并实时生效,无需重启服务。
2 服务扩展
- 使用 Nacos 的服务注册与发现功能,动态感知服务实例的增减,确保限流规则的全局一致性。
- 在高并发场景下,通过水平扩展服务实例,分散流量压力。
Sentinel 通过nacos 的发布订阅进行 速率调整
在 Sentinel 中,可以通过与 Nacos 的集成,利用 Nacos 的发布订阅功能来实现速率调整,以下是一般的步骤:
引入相关依赖
在项目的构建文件(如 Maven 的 pom.xml 或 Gradle 的 build.gradle)中,引入 Sentinel 与 Nacos 相关的依赖:
<!-- Sentinel Nacos依赖 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
<version>${sentinel.version}</version>
</dependency>
配置 Nacos 数据源
在应用的配置文件(如 application.yml 或 application.properties)中,配置 Sentinel 使用 Nacos 作为数据源来获取流量控制规则等配置信息,示例如下:
spring:
cloud:
sentinel:
datasource:
# 定义数据源名称
ds1:
nacos:
server-addr: nacos-server-address:8848 # Nacos服务器地址
dataId: sentinel-rules # Nacos中存储Sentinel规则的Data ID
groupId: DEFAULT_GROUP # Nacos中存储Sentinel规则的分组
data-type: json # 规则数据格式为JSON
定义 Sentinel 规则
在 Nacos 的配置管理界面或通过 Nacos 的 API,创建一个名为sentinel-rules(与配置文件中 dataId 一致)的配置项,用于存储 Sentinel 的流量控制规则。
以下是一个简单的流量控制规则示例:
[
{
"resource": "your_resource_name",
"limitApp": "default",
"grade": 1,
"count": 10,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
上述规则表示对名为your_resource_name的资源进行流量控制,QPS 阈值为 10。
其中:
resource:要保护的资源名称。limitApp:来源应用,default表示所有应用。grade:限流阈值类型,1 表示 QPS 限流,0 表示线程数限流。count:限流阈值。strategy:流控模式,0 为直接模式,1 为关联模式,2 为链路模式。controlBehavior:流控效果,0 为快速失败,1 为 Warm Up,2 为排队等待。clusterMode:是否为集群模式。
在应用中获取并应用规则
在应用启动时,Sentinel 会从 Nacos 中获取配置的规则,并应用到相应的资源上。
当需要调整速率时,只需要在 Nacos 中修改sentinel-rules配置项中的count值等相关参数,Sentinel 会通过 Nacos 的发布订阅机制,实时感知到规则的变化,并自动更新应用中的流量控制策略。
代码中动态获取规则
在代码中,可以通过 Sentinel 的 API 来动态获取当前应用的流量控制规则,示例代码如下:
import com.alibaba.csp.sentinel.slots.block.flow.FlowRule;
import com.alibaba.csp.sentinel.slots.block.flow.FlowRuleManager;
import java.util.List;
public class SentinelRuleUtils {
public static void printCurrentRules() {
// 获取所有流量控制规则
List<FlowRule> rules = FlowRuleManager.getRules();
for (FlowRule rule : rules) {
System.out.println("Resource: " + rule.getResource() + ", QPS Limit: " + rule.getCount());
}
}
}
你可以在需要的地方调用SentinelRuleUtils.printCurrentRules()方法来查看当前应用的流量控制规则。
未完待续:
作为 10wqps 自适应限流方案, 尼恩团队讲持续完善, 后面再发最新版本,敬请期待。
塔尖级答案:120分
尼恩提示,讲完 自适应限流, 可以得到 120分了。

终于,大厂offer到手,或者 offer 直提了。
借助此文,尼恩给解密了一个高薪的 秘诀,大家可以 放手一试。保证 屡试不爽,涨薪 100%-200%。
后面,尼恩java面试宝典回录成视频, 给大家打造一套进大厂的塔尖视频。
通过这个问题的深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。
很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









