



HDFS客户端操作的三种方式
1.命令行操作
HDFS命令行工具通过hadoop fs或hdfs dfs命令集实现操作,适合快速执行基础文件管理任务。
常用命令示例:
- 查看目录内容:
hdfs dfs -ls /user - 上传文件:
hdfs dfs -put localfile /hdfs/path - 下载文件:
hdfs dfs -get /hdfs/path localfile - 创建目录:
hdfs dfs -mkdir /newdir - 删除文件:
hdfs dfs -rm /file/to/delete
命令格式遵循Linux文件操作习惯,支持通配符和递归操作。管理员权限操作需添加-sudo参数。
1.1HDFS相关进程的启停管理命令
HadoopHDFS组件内置了HDFS集群的一键启停脚本。
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
除了一键启停外,也可以单独控制进程的启停。
$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh(start|status|stop)(namenode|secondarynamenode|datanode)
$HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs--daemon(start|status|stop)(namenode|secondarynamenode|datanode) 2.2 HDFS文件系统操作命令
2.2 HDFS文件系统操作命令
DFS文件系统基本信息HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。•HDFS同Linux系统一样,均是以/作为根目录的组织形式
关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系。用法完全一致,任选其一即可。
hadoop命令(老版本用法)
用法:hadoopfs[genericoptions]
hdfs命令(新版本用法)
用法:hdfsdfs[genericoptions]1.3创建 HDFS 目录并验证
创建命令
hadoop fs -mkdir -p /hdfs_demo/input
验证命令
hadoop fs -ls /![]()
1.4上传本地文件到 HDFS
本地创建测试文件test.txt,内容为hello hdfs。
上传
hadoop fs -put test.txt /hdfs_demo/input
验证
hadoop fs -ls /hdfs_demo/input
查看
hadoop fs -cat /hdfs_demo/input/test.txt

1.5追加本地数据到 HDFS 文件
本地创建新文件append.txt,内容为append data。
创建
echo "append data" > append.txt
追加
hadoop fs -appendToFile append.txt /hdfs_demo/input/test.txt
验证
hadoop fs -cat /hdfs_demo/input/test.txt1.6复制 HDFS 文件(含重命名)
复制文件并修改名称,实现文件备份或重命名。

hadoop fs -cp /hdfs_demo/input/test.txt /hdfs_demo/input/test_copy.txt
hadoop fs -ls /hdfs_demo/input1.7移动 HDFS 文件(含重命名)
命令作用:移动文件到新目录,或直接重命名文件。
1.8下载 HDFS 文件到本地
命令作用:将 HDFS 文件下载到本地文件系统,用于本地分析或备份。
创建目标目录
mkdir -p local_demo
下载命令
hadoop fs -get /hdfs_demo/input/test.txt local_demo/
验证
ls local_demo/
1.9删除 HDFS 文件与目录
命令作用:清理不再需要的 HDFS 文件和目录,释放存储空间。删除以后预期输出中不再包含/hdfs_demo目录
删除文件命令
hadoop fs -rm /hdfs_demo/input/test_rename.txt
删除目录命令(需递归删除)
hadoop fs -rm -r /hdfs_demo
验证删除结果:
hadoop fs -ls /2。网页界面操作(9870端口)
通过浏览器访问NameNode的Web UI(默认9870端口)提供可视化操作界面,适合监控和基础管理。
核心功能模块:
- Overview:展示集群存储容量、节点健康状态等摘要信息
- DataNodes:查看所有DataNode的存储分布和负载情况
- Utilities:
Browse the file system:图形化文件浏览器Logs:实时查看各组件日志Configuration:检查运行参数
文件操作支持拖拽上传、右键菜单删除等交互方式。可通过http://<namenode_host>:9870访问,需配置防火墙放行该端口。
1.访问NameNode的Web界面
http://<namenode-host>:500703.Java API操作
3.1 概览
在大数据开发中,HDFS 命令行操作虽灵活但不够直观。借助 JetBrains 系列 IDE(如 DataGrip、IDEA、PyCharm)的 Big Data Tools 插件,我们可以在 Windows 本地以图形化方式操作 Linux 虚拟机上的 HDFS 集群。
3.2 准备工作(我们在之前的步骤已经启动HDFS集群)
运行环境:Windows 本地 运行 DataGrip,Linux 虚拟机 运行 HDFS 集群。
通信方式:Windows 通过网络访问虚拟机的 HDFS 服务端口,实现图形化操作。
临时关闭虚拟机防火墙:systemctl stop firewalld
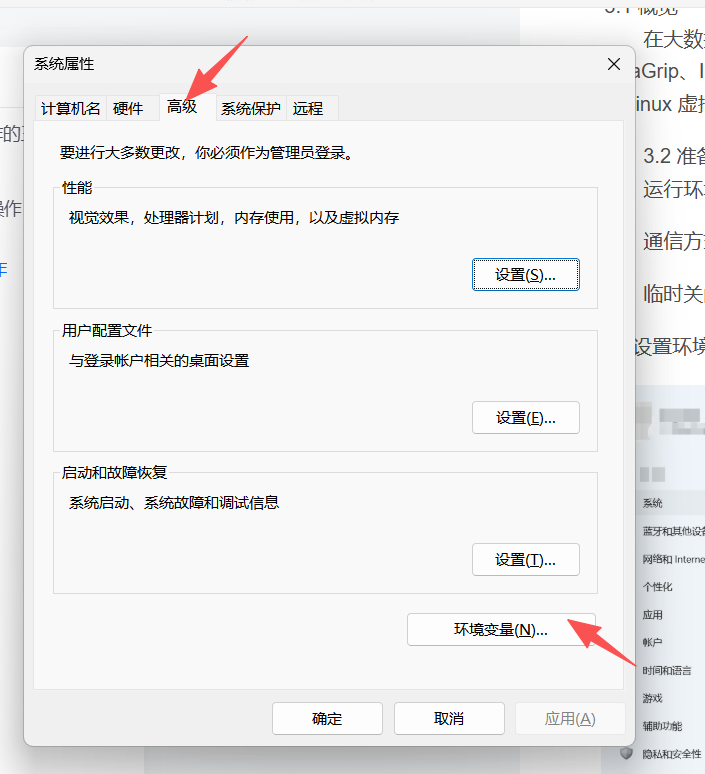
3.3 设置环境变量
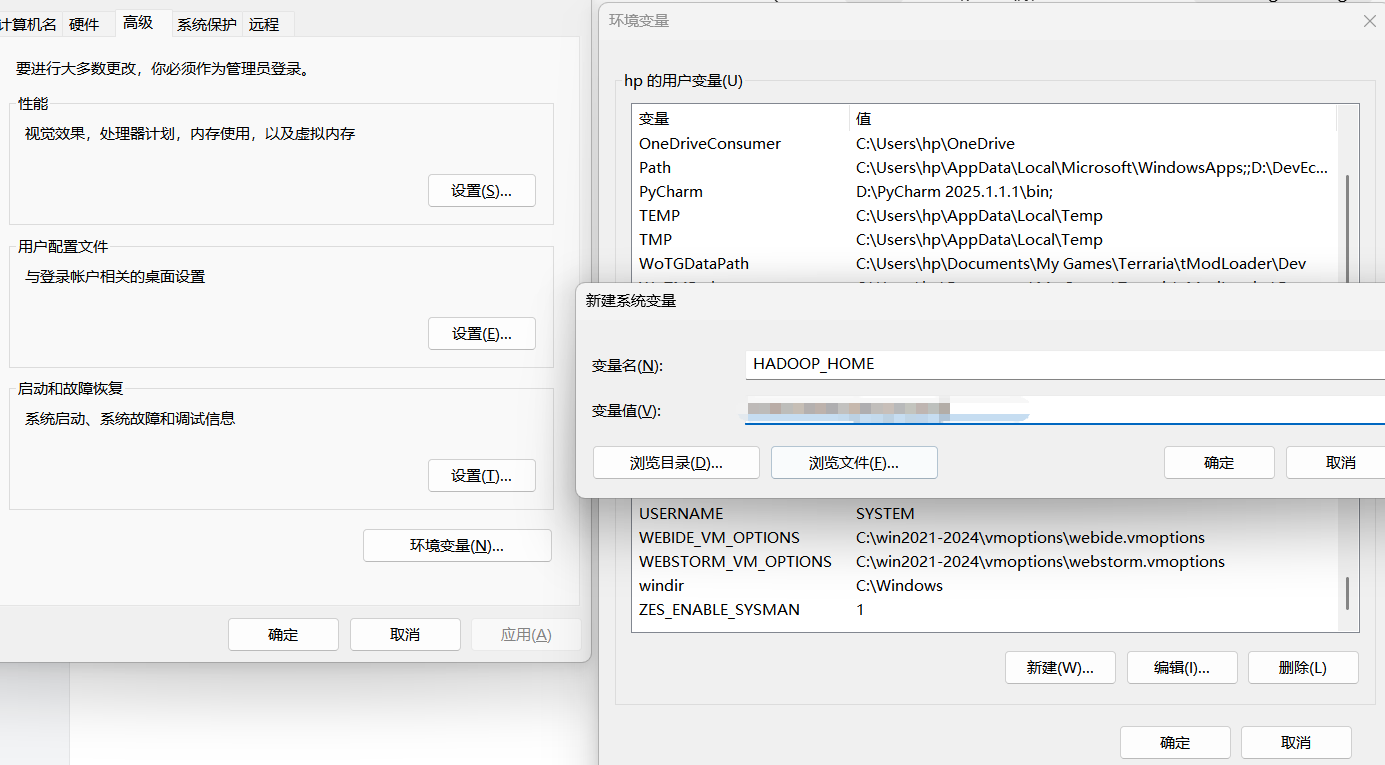
新建系统变量 HADOOP_HOME
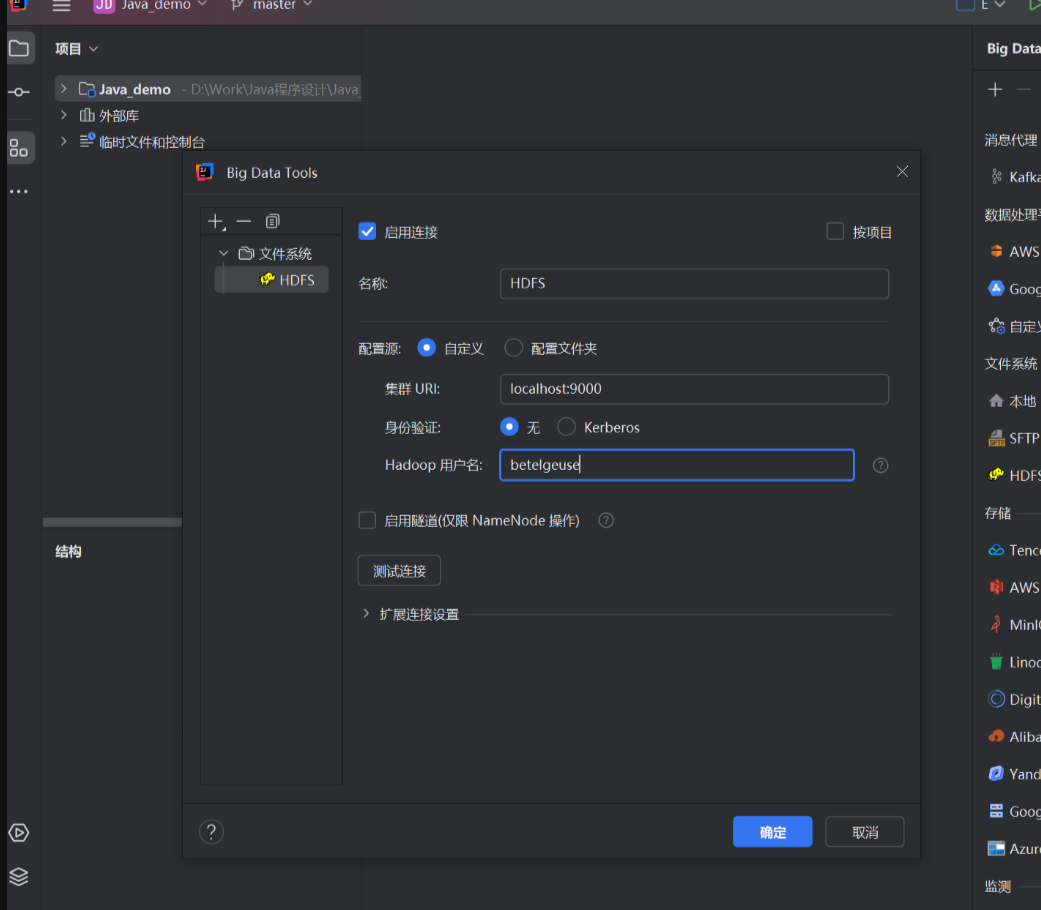
3.4 安装并配置Big Data Tools插件
打开IDEA,在插件栏安装Big Data Tools,然后重启IDEA

通过org.apache.hadoop.fs包实现编程式访问,适用于需要集成到应用系统的场景。
基础代码框架:
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
// 创建目录
Path dirPath = new Path("/api_created_dir");
fs.mkdirs(dirPath);
// 写入文件
Path filePath = new Path(dirPath, "test.txt");
try(FSDataOutputStream out = fs.create(filePath)) {
out.writeUTF("HDFS API写入测试");
}
// 读取文件
try(FSDataInputStream in = fs.open(filePath)) {
System.out.println(in.readUTF());
}
关键类说明:
FileSystem:核心操作入口,线程安全推荐复用实例Path:所有HDFS路径的抽象表示FSDataInputStream/FSDataOutputStream:扩展了标准IO流的功能
异常处理需重点关注IOException子类,如FileNotFoundException、AccessControlException等。生产环境建议添加重试机制。
操作方式对比
| 维度 | 命令行 | Web UI | Java API |
|---|---|---|---|
| 适用场景 | 运维/脚本 | 监控/简单管理 | 系统集成开发 |
| 功能覆盖 | 完整 | 基础操作 | 完整 |
| 自动化能力 | 中等(需脚本封装) | 无 | 高 |
| 学习曲线 | 低 | 最低 | 高 |
| 权限控制 | Kerberos/LDAP | 同命令行 | 编程实现 |
安全配置需注意:Kerberos环境下,Java API需先调用UserGroupInformation.loginFromKeytab()完成认证,Web UI会重定向到认证网关。

















 1575
1575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









