







目录标题
- 覆盖与追加
-
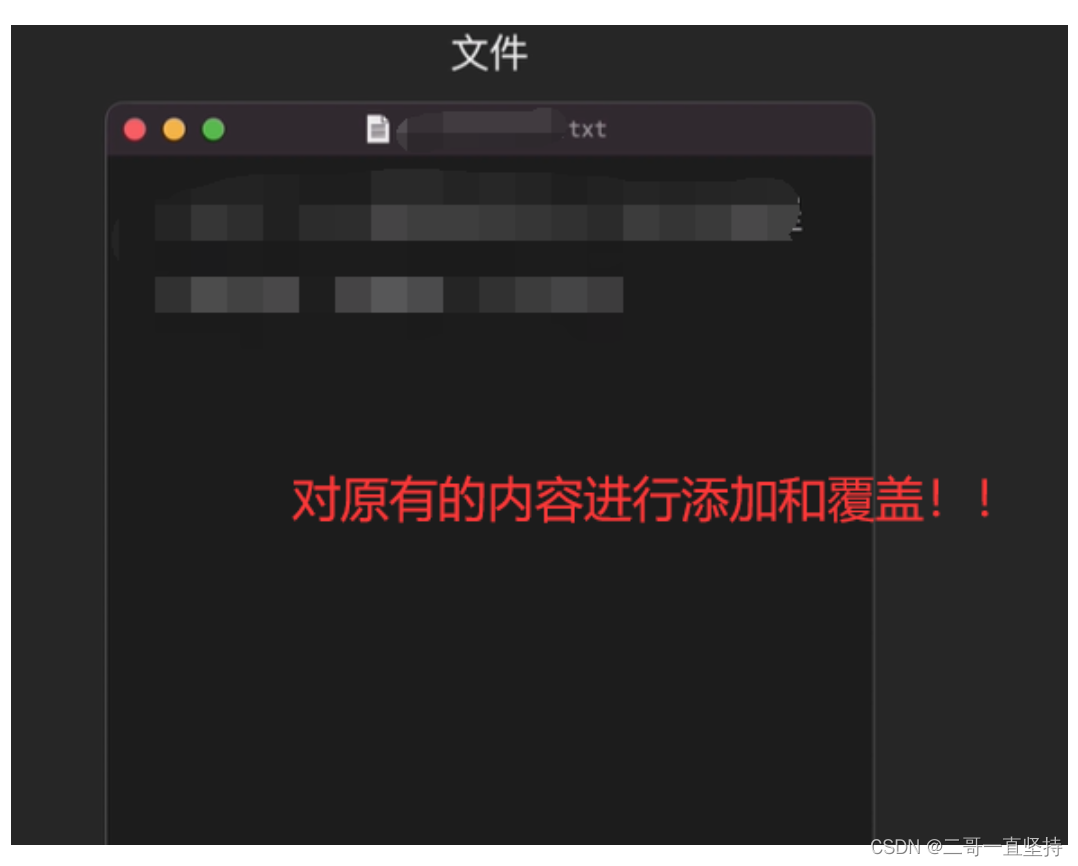
- 在日常开发中 难免会对文件 进行写入操作 有些时候需要清空原有的内容 写入新内容 或者有些时候需要在原有内容的基础上 接着写
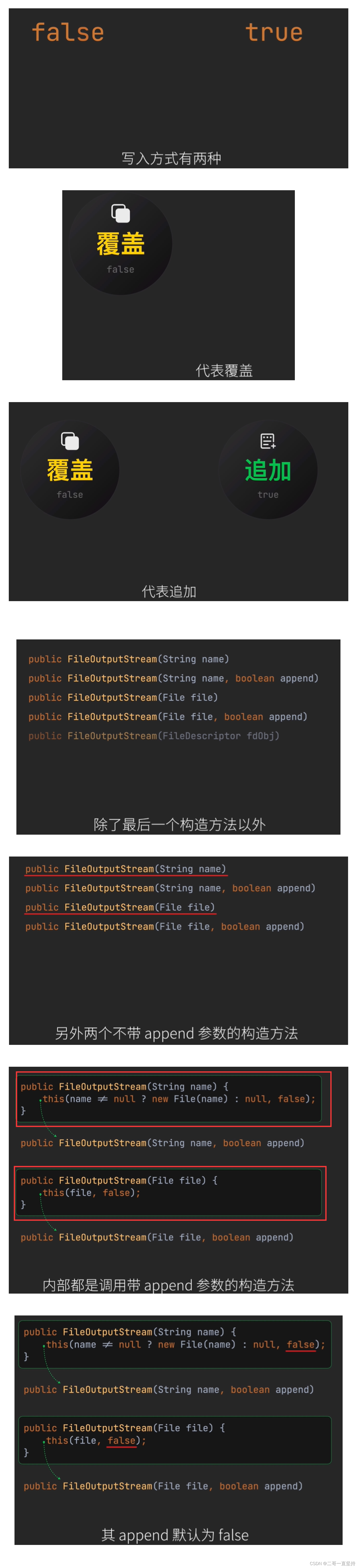
- 这时就需要针对不同情况 使用不同的构造方法 在下面的五个构造方法中 只有带append参数的构造方法 才可以指定写入方式
- 写入的方式有两种 一种是 false 代表覆盖 还有 一种是true 代表追加 除了最后一个构造方法以外 另外两个不带append参数的构造方法 内部都是调用带append参数的构造方法(重点!!!) 其append 默认为 false 即写入方式默认为覆盖
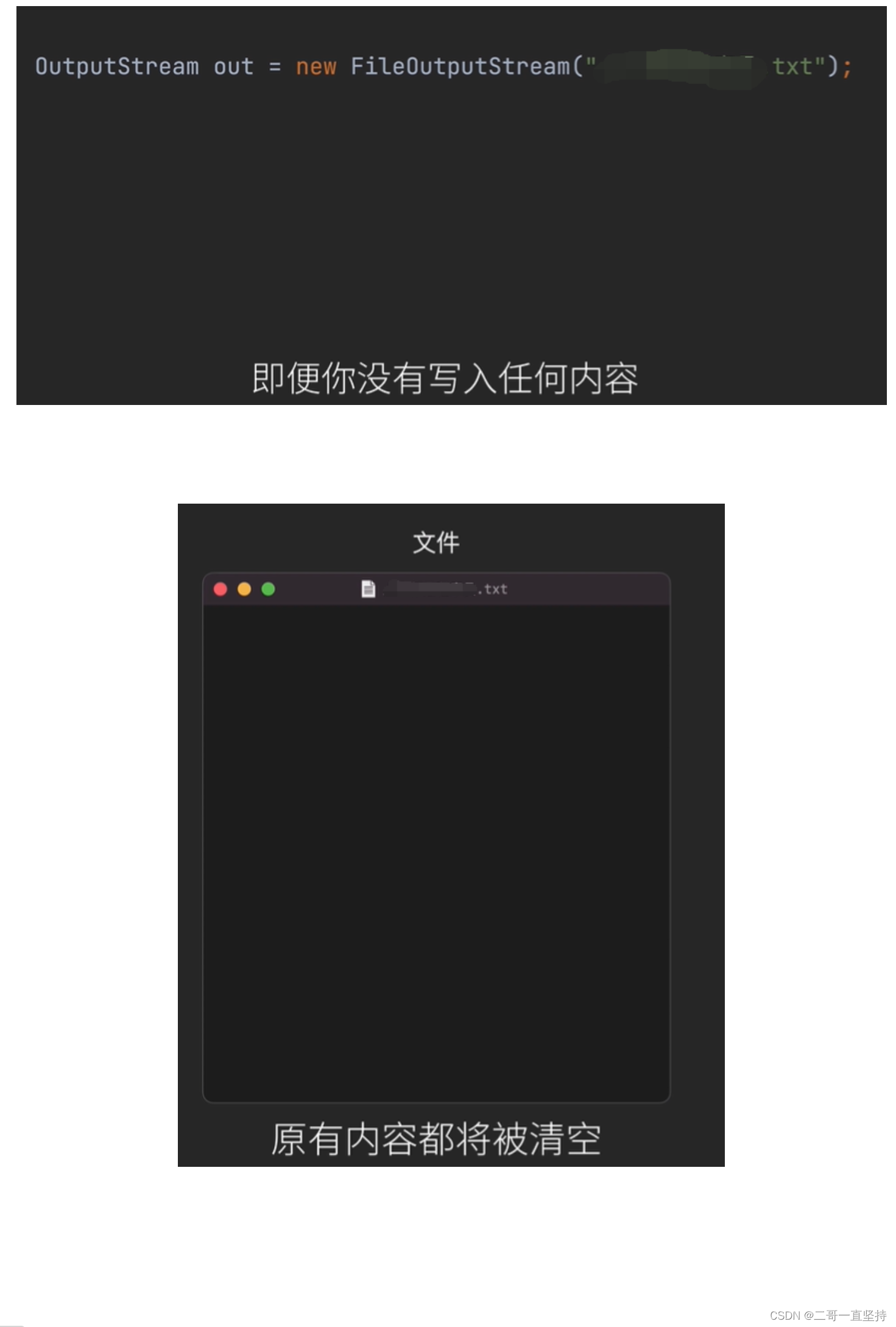
- 在覆盖方式下 只要是创建了输出流 即便你没有写入任何内容 原有内容都将被清空 这一点是非常危险的
- 练习
- 下面我们来验证 覆盖 是不是 如上面所说的 下面这是一段有内容的文件 然后我们仅仅只是创建了输出流 没有写入任何内容 执行程序后
- 打开刚刚的文件 可以看到 文件的内容 已经被清空 由此可见 在日常开发中 覆盖这种方式 要谨慎使用 (重点!!!) 因为这样 很容易误删文件里面的内容 造成不必要的损失
- 反观 追加方式 要安全的多
- 下面演示一下 追加的例子 还是创建一个有内容的文件 这次 我们使用追加方式来创建输出流
- 将 append参数值 设置为 true 然后顺便 追加一些新内容 执行程序后 打开刚刚的文件 可以看到
- 最后总结
- Java复制文件
-
- 复制的本质其实是 把数据从一个文件中读出来 然后再写到另一个文件中去 这个过程是边读边写的 读到 -1 时结束
- 复制的前后内容一致
- 上面 提到的 ”读“ 和 ”写“ 分别需要用到对应的流
- 读取数据 需要用到输入流 InputStream 这里我们选择它其中的一个子类 FileInputStream
- 而写入数据 需要用到 输出流OutputStream 这里我们选择它其中的一个子类 FileOutputStream
- 选好输入输出流以后 接下来 编写示例代码 下面是我们要复制的文件 内容是 ”abc“
- 首先 声明 输入输出流 初始值 为null 然后 写上try 代码块 在 try 代码块中 初始化 输入输出流 输入流 传入的是 目标文件路径 (也就是你要复制哪个文件) 输出流传入的是目的地文件路径(也就是你要把复制的文件放在哪) 创建输入输出流有异常抛出 使用catch将其捕获
- 接下来 创建一个字节数组 长度为 1024 这是最常用的长度 接着 声明一个用于记录读取字节数的变量 length 使用 while语句 循环读取字节 读到 -1 时结束 每读取一次 都调用输出流的write方法 写入字节数组 偏移量 为 0(也就是从字节数组下标0的位置开始写) 每次写入的长度为 当前读取的字节数length 至此 try代码块里面的内容编写完成
- 接下来 写上 finally代码块 在finally代码块中 关闭输入输出流 在关闭流之前 先判断一下 流是否为空 至此 整个示例编写完成
- 执行程序 观察执行结果 从执行结果来看 程序没有报错 文件复制成功 内容一模一样
- 总结
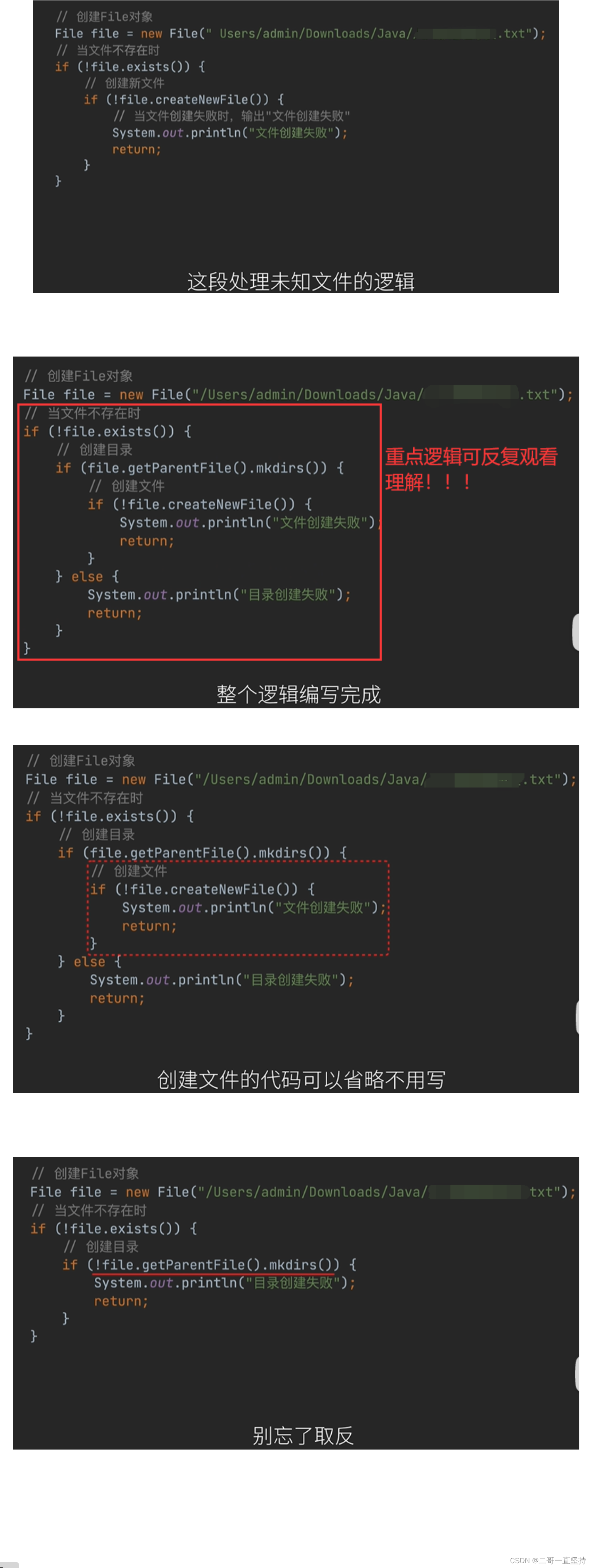
- 处理未知文件(未知目录不存在)
-
- 我们可能会遇到这种问题 向文件中写入数据时 明明已经判断了 当文件不存在时 创建新文件 可还是会出现错误 会显示 “No such file or directory”(无此文件或目录)
- “无此文件”可以理解 所以我们才要创建 问题就出现在“无此目录”上 文件名之前的都是目录
- 经过验证: Users(用户)目录存在 admin目录存在 Downloads(下载)目录存在 发现问题 Java目录不存在 所以只要其中有一个目录不存在 文件就会创建失败
- 在实际开发中 究竟是哪一个目录不存在 我们不得而知 但无论是哪个目录不存在 我们都可以使用 File对象的mkdirs方法轻松解决 它可将路径中所有不存在的目录都创建出来
- 接下来 我们来重写 这段处理未知文件的逻辑 依然是使用File对象 当文件不存在时 调用file 对象的mkdirs方法创建目录
- 注意点! 这里的 “二哥一直坚持.txt” 是我们要创建的文件 它不是一个目录 它前面的才是目录 所以需要先调用getParentFile()方法 获得父路径 返回的是 一个File对象 紧接着再调用mkdirs方法 创建目录
- 当目录创建失败时 输出“目录创建失败” 并 return 当目录创建成功时 继续创建文件 当文件创建失败时 输出“文件创建失败” 并 return 至此 整个逻辑编写成功(重点 重点 重点!!!)
- 但是这部分代码还可以优化 创建文件的代码可以省略不用写 因为使用输出流时 若文件不存在 系统会自动帮我们创建 else 这部分代码 可以移动到 if 语句中 不要忘记取反 至此 优化后的代码编写完成
- 在日常开发中 我们可以用下面这段代码 来创建未知文件 接下来 我们用新逻辑替换掉上面的逻辑代码 再试试看 重点: 对比两者的不同
- 从执行结果来看: 程序没有报错 不存在的目录 和 文件都已经创建好 内容也写了进去
- 对比两者 总结为什么代码会出错
- 总结:
- 字符编码
-
- 学习字符编码相关知识 有助于我们了解 计算机是如何储存字符的
- 一:ASCII 计算机里面只能存 0 和 1 存不了 A,B,C, 更存不了中文
- 那该怎么办呢? 只能搞一张表格 让字符与 “O” 和 “1" 对应起来 例如 01000001对应A 01000010对应B
- 以此类推 最早搞这张表的是美国 他们取名叫 “ASCII编码表” 也叫 “ASCII字符集” 共128个字符 其中包括 32个不可打印的控制符 10个数字 26个大写字母 26个小写字母 和 34个标点符号
- 随着计算机的普及 发展壮大 各国开始制作自家的编码表 我国也不例外
- 1981年 5月1日 发布 “GB(国标)2312字符集” 共 7445 个字符 其中包括 6763个汉字 编码表中的第一个汉字 是 “啊”
- 其码值如下图所示 一个字节最多可以表示 256 个字符 两个字节最多可以表示 65535 个字符
- 而 GB2312字符集里面 有七千多个字符 一个字节不够存 所以 它里面的字符 都是两个字节
- 每一个国家都搞一张表 意味着在互联网上 你想看懂其他国家在说什么 还要去下载他们的编码表解析一下 否则看到的就是乱码 这样不利于各国之间的合作与交流
- 二 : GB2312
- 于是 国际组织提议 全世界共用一张表 把各国的子符都容纳进来 这张表就叫做 :“Unicode编码表” 也叫 “Unicode字符集”
- 其中汉字在 4E00-9FFF 区间 字符集中的第一个汉字是 “一” 其Unicode编码是U+4E00 Unicode编码都以 “U+” 开头
- 大家可以看到: 下图中 并没有列出 “ 一 ” 的十六进制 十进制 和 二进制 存储形式 原因是 Unicode只负责给字符编码 不负责具体怎么储存
- 它为什么不负责存储呢 举例 : 拿 大写字母 “A” 来说 它的Unicode编码是 “U+0041” 转成 二进制 有 16 位 占两个字节 实际上 :存储“A”用不了两个字节 一个字节就够了 类似于这样的字符 还有很多 为了 节省存储空间 Unicode在存储这方面不做具体规定
- 具体的由 UTF-8 UTF-16 UTF-32 等 去负责怎么存储 其中日常开发中用得较多的是UTF-8 使用可变长度字节来存储存 Unicode字符
- 有关 UTF-8 相关知识 在下一节知识讲解会
- 三:Unicode
- 总结:
- 中文是如何存储在电脑上的(UTF-8)
-
- 下面我们要学习 UTF-8 相关知识 在上面知识中 介绍了 计算机是如何给 字符编码的 了解到 Unicode 只负责 编码工作 也就是只负责给每个字符编一个号 它不负责存储工作 也就是不规定 每个字符 占 几个字节
- 原因是每个字符 所占 字节数 不同 例如:英文 占一个 字节 拉丁文 占 两个 字节 中文 占三个字节 图形文字 占 四个字节
- 如果进行统一规定 : 所有字符都 占 四个字节 那么 : 占字节数较少的字符就很浪费存储空间
- 为了 节省存储空间 Unicode 在存储这方面 不做 具体规定 具体的由 UTF-8 UTF-16 和 UTF-32等 去负责
- 其中 日常开发中 用的比较多的是 UTF-8 使用可变长度字节来储存Unicode字符 字节数 能省则 省
- 从这些字符的二进制里 我们可以找到一些存储的规律 例如: 占四个字节的字符 它的第一个字节 开头有 4 个连续的 “ 1 ” 占三个字节的字符 它的第一个字节 开头有 3 个连续的“ 1 ” 占二个字节的字符 它的第一个字节 开头有 2 个连续的“ 1 ” 占一个字节的字符 它的第一个字节 开头有 0 个连续的“ 1 ”
- 由此我们可以总结出 UTF-8 的第一个特点: 除字节数为1的字符以外 其余字符的第一个字节里 开头有多少个连续的 “1” 就代表着该字符使用多少个字节来储存
- 另外 我们还可以发现 字节数大于 1 的字符 除第一个字节以外 其余字节 都以 “10” 开头 由此 我们可以总结出 :UTF-8的第二个特点: 字节数大于 1的字符 除第一个字节以外 其余字节都以“ 10 ” 开头
- 现在每个字节开头要么代表 字符所占字节数 要么就是固定写法 那么剩余的字符又有什么含义呢
- 那么剩余的字符又有什么含义呢 我们可以将 字符的Unicode 编码转为 二进制 查看 我们发现 它们是一一对应的关系 从后往前 依次填充 直到填满为止
- 由此我们可以总结出 UTF-8编码规则: 如果 Unicode编码值 在 0-7F 区间 则使用 1 个字节存储 字节的第一位 填充 “ 0 ”
- 如果Unicode编码值 在 80-7FF 区间 则使用两个字节 存储 第一个字节的前三位 填充 “ 110 ” 第二个字节的前两位 填充 “ 10 ”
- 如果Unicode编码值 在 800-FFFF区间 则使用三个字节存储 第一个字节的 前四位 填充 “ 1110 ” 第 二 三 个字节的前两位 填充 “ 10 ”
- 如果 Unicode编码值 在 10000-10FFFF区间 则使用 四个 字节存储 第一个字节 的前五位 填充 “ 11110 ” 第 二 三 四 个字节的前两位 填充 “ 10 “
- 练习
- 总结:
- 以字符为单位读取数据
-
- 什么是 以字符为单位读取数据 通过 下图两节的学习
- 已经学习了 字符编码 Unicode的基础知识 以及 如何存储 Unicode字符的 UTF-8 编码
- 在这节学习中 你要学习到 什么是 ” 以字符为单位读取数据 “ 我们学过 字符是以 字节的形式存储在文件中的 既然 要以字符为单位 进行读取 那么就必须知道 这个字符 占几个字节
- 若读到的字节 以 ” 0 “ 开头 说明该字符 占一个字节 读完一个字节后 再将读到的字节值转为 Unicode编码 然后再根据编码 在Unicode字符集中 找到对应的字符 得到 U+004D 也就是 字符 ”M“
- 若读到的字节 以” 110 “ 开头 有两个 连续的 ” 1 “ 说明该字符 占 两个 字节 读完两个字节以后 以同样的方法 找到相应的字符 这是一个拉丁文字符
- 若读到的字节 以” 1110 “ 开头 有三个连续的 “ 1 ” 说明该字符 占 三个 字节 读完三个字节 以后 以同样的方法 找到相应的字符 这个一个中文字符
- 若读到的字节 以“ 11110 ” 开头 有 四个连续的 “ 1 ” 说明该字符 占 四个字节 读完四个 字节以后 以同样的方法 找到相应的字符 这是一个图形字符
- 所有的字节已读完 均已找到对应的字符 以上就是“ 以字符为单位读取数据 ” 的意思
- 总结 :
- 字符输入流 Reader
-
- 如果我们想以 字符为单位读取数据的话 就需要借助 字符输入流 Reader
- 和字节输入流 一样 字符输入流 也有一套体系 共有十个类 名称均以:“ Reader ” 结尾
- 针对不同的需求 选择合适的类 比较常用的有: 带缓冲区的字符输入流 :BufferedReader 带行号的字符输入流:LineNumberReader 和用于读取文本文件的: 文件字符输入流FileReader
- 以及 将字节输入流转换为 字符输入流: InputStreamReader
- 练习
- 接下来 : 使用FileReader 编写一个 读取文本文件内容的示例
- 它一共有五个构造方法 第一个参数 我们在 ” 字节输入流InputStream “ 中介绍过 第二个参数: 指定文件的字符集 现在一般都是 ” UTF-8 “
- 还不会字符集的 要学习上面的内容 :字符编码学习和UTF-8编码
- 示例: 下面是我们读取的文件: 内容为:” abcdefg 二哥一直坚持! “
- 首先 先声明一个字符输入流: 初始值为null 然后初始化它 传入 你要读取的文本文件路径 创建FileReader 有异常抛出 使用 try-catch 将其捕获 写上 finally 代码块
- 在finally代码块中 调用 输入流 的close方法 关闭流 在关闭流 之前 先判断一下 流是否为空 当流不为空时 再关闭流 close方法 有异常抛出 使用 try-catch 将其捕获
- 接下来 我们来编写读取数据的部分 声明一个用于记录每次读到的字符变量 为什么是int类型 在上面学习中我们已经学到了 “ read方法读的是字节 为什么返回 int “ 已经解释过了
- 然后使用while循环 每次读取单个字符 读到 -1 时结束 最后 输出读到的字符
- 若直接输出 ” c “ 得到的只是字节值 想要得到字符 需要将其转为char类型
- 另外这里不要用 println进行输出 它会一行输出 一个字符 建议使用print 进行输出 这样输出的内容格式 和 原来的文件 是一样的
- 到此 示例代码编写完成 执行程序 观察执行结果 从执行结果来看 程序输出的内容 和原来的文件一模一样
- 每次只读一个字节的效率太低 可以使用字符数组 进行批量读取 依次来提高效率
- 总结:
- 以字符为单位写入数据
-
- 之前我们写数据都是通过字节写入的 即使你写入的数据是字符 那也要将它们转为 字节 然后再通过字节写入 若是要省去手动 ” 字符转字节 “ 这个环节 直接以字符为单位 写入的话 需要借助 字符输出流 Writer
- 在了解 字符输出流之前 先来 了解 ” 以字符为单位写入数据 “ 的过程是怎么样的
- 以 Unicode字符为例 假如我们要写入汉字 ” 一 “ 首先找到它的Unicode编码 然后根据Unicode编码所属范围 确定 UTF-8 编码方式
- 最后将 Unicode编码 根据 UTF-8编码方式转为 二进制 写入文件中
- 这些就是 ” 以字符为单位写入数据 “ 的过程 虽然它的本质还是通过字节来写入的 但是它省去了 手动字符 转字节这个过程 写程序就更方便了
- 字符输出流Writer
-
- 我们要学习 什么是字符输出流
- 字符输出流体系 它和字符输入流 Reader一样 也有一套体系 常用的类有四个 第一个是:带缓冲区的 BufferedWriter 第二个是:将字节输出流转换为 字符输出流的OutputStreamWriter 第三个是:以字符为单位将数据输出到文件的 FileWriter 第四个是:打印各种类型数据的打印流 PrintWriter
- 接下来 使用 FileWriter 完成一个复制文件的示例 它一共有九个构造方法 虽然看起来比较多 但实际上 我们只用 带 append参数的方法 一共有四个
- 第一个参数: 我们在 ” 字节输入流 InputStream “ 中学到过 charset参数 指定文件的字符集 一般为 ” UTF-8 “ 我们在 ” 字符编码 Unicode “ 和 ” 中文是如何存储到电脑上的(UTF-8编码) “ 中 学习过
- append参数 我们在 ” 追加和覆盖 “ 中学习过 它可以指定写入模式 true为追加 false 为覆盖 建议使用 追加方式 覆盖这种方式要慎用 因为这样很容易误删 文件里的内容 造成不必要的损失
- 练习
- 介绍完上面的参数 接下来我们要编写 复制文件 示例 下图为我们要复制的文件 内容为: ” abcdefg 二哥一直坚持! “
- 首先声明 字符输入输出流 初始值都为 null 然后初始化它们 读取的是源文件 输出的是副本 创建输入输出流时 有异常抛出 使用try-catch 将其捕获 写上finally 代码块
- 在finally代码块中 调用close方法关闭流 在关闭流之前 先判断流 是否为空 当流不为空时 再关闭流 close方法 有异常抛出 使用try-catch 将其捕获
- 接下来 我们来编写复制数据的部分 定义一个长度为 100 的字符数组 作为缓冲区 读取数据的时候 直接读到缓冲区里面
- 输出的时候 直接从缓冲区里面输出 接着 定义一个变量length 用于记录每次已读字符数 当length 等于 -1 时 说明数据已读完
- 接下来 使用while循环 批量读取字符 读到 -1 时结束 最后使用 writer输出 读到的字符
- 第一个参数为字符缓冲区 第二个参数 为偏移量 是 0 表示从 缓冲区的第一位 开始输出 第三个参数 为 输出的长度 就是已读到的字符数 读多少 输出多少
- 到此 示例代码编写完成 执行程序 观察执行结果 从执行结果来看 程序没有报错
- 文件已经复制完成 副本与源文件内容一摸一样
- 总结:
- 复制文本文件一行代码搞定
- 总结
覆盖与追加
在日常开发中
难免会对文件 进行写入操作
有些时候需要清空原有的内容
写入新内容
或者有些时候需要在原有内容的基础上
接着写
这时就需要针对不同情况
使用不同的构造方法
在下面的五个构造方法中
只有带append参数的构造方法
才可以指定写入方式

写入的方式有两种
一种是 false 代表覆盖
还有 一种是true 代表追加
除了最后一个构造方法以外
另外两个不带append参数的构造方法
内部都是调用带append参数的构造方法(重点!!!)
其append 默认为 false
即写入方式默认为覆盖
在覆盖方式下
只要是创建了输出流
即便你没有写入任何内容
原有内容都将被清空
这一点是非常危险的
练习
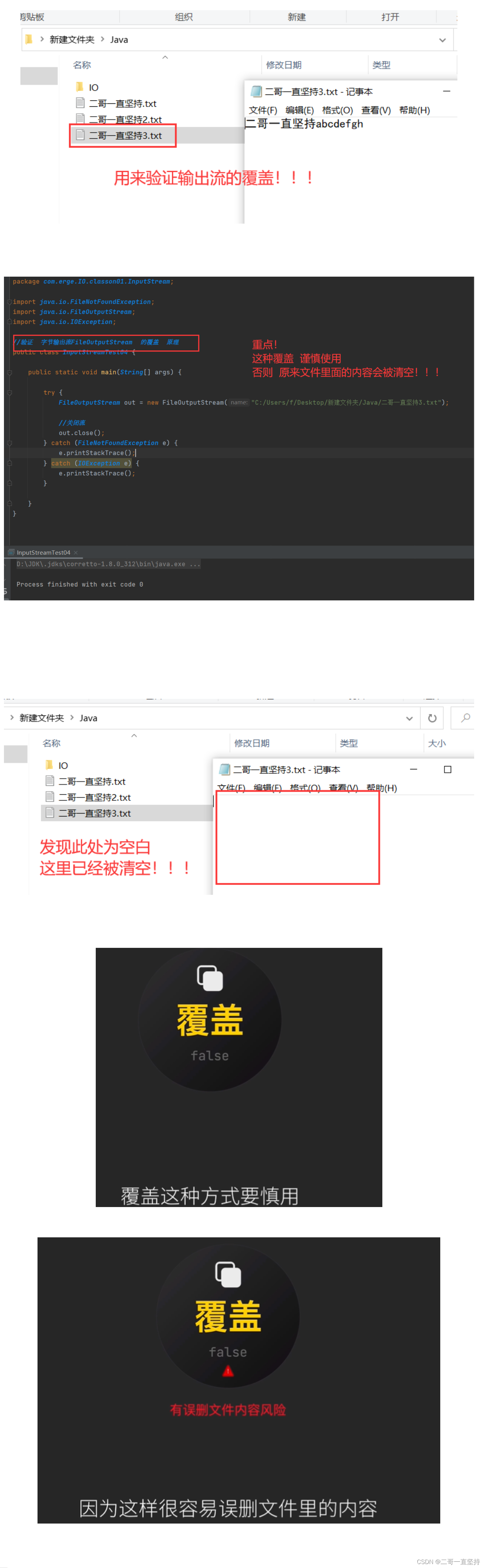
下面我们来验证
覆盖 是不是 如上面所说的
下面这是一段有内容的文件
然后我们仅仅只是创建了输出流
没有写入任何内容
执行程序后
打开刚刚的文件
可以看到
文件的内容 已经被清空
由此可见 在日常开发中
覆盖这种方式 要谨慎使用 (重点!!!)
因为这样 很容易误删文件里面的内容
造成不必要的损失
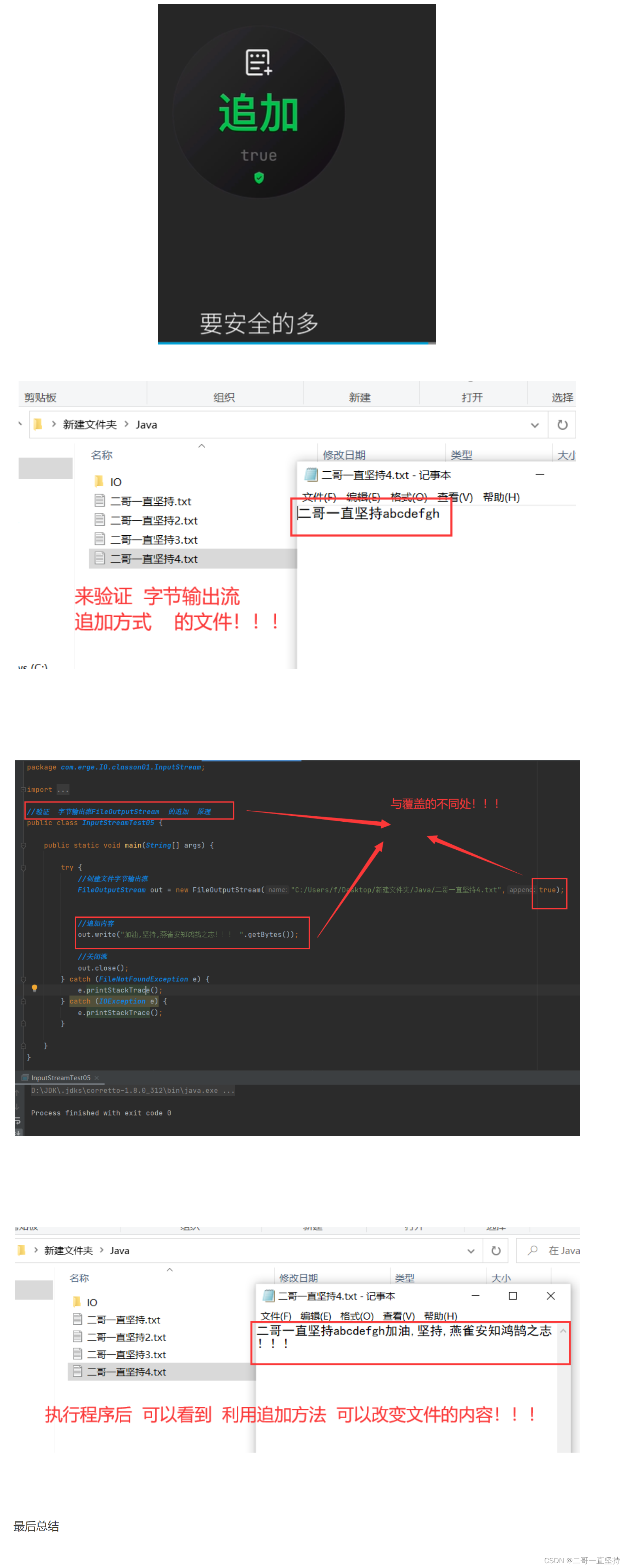
反观 追加方式
要安全的多
下面演示一下 追加的例子
还是创建一个有内容的文件
这次 我们使用追加方式来创建输出流
将 append参数值 设置为 true
然后顺便 追加一些新内容
执行程序后
打开刚刚的文件
可以看到
最后总结
本节 介绍了 append参数的两种含义
覆盖与 追加

Java复制文件
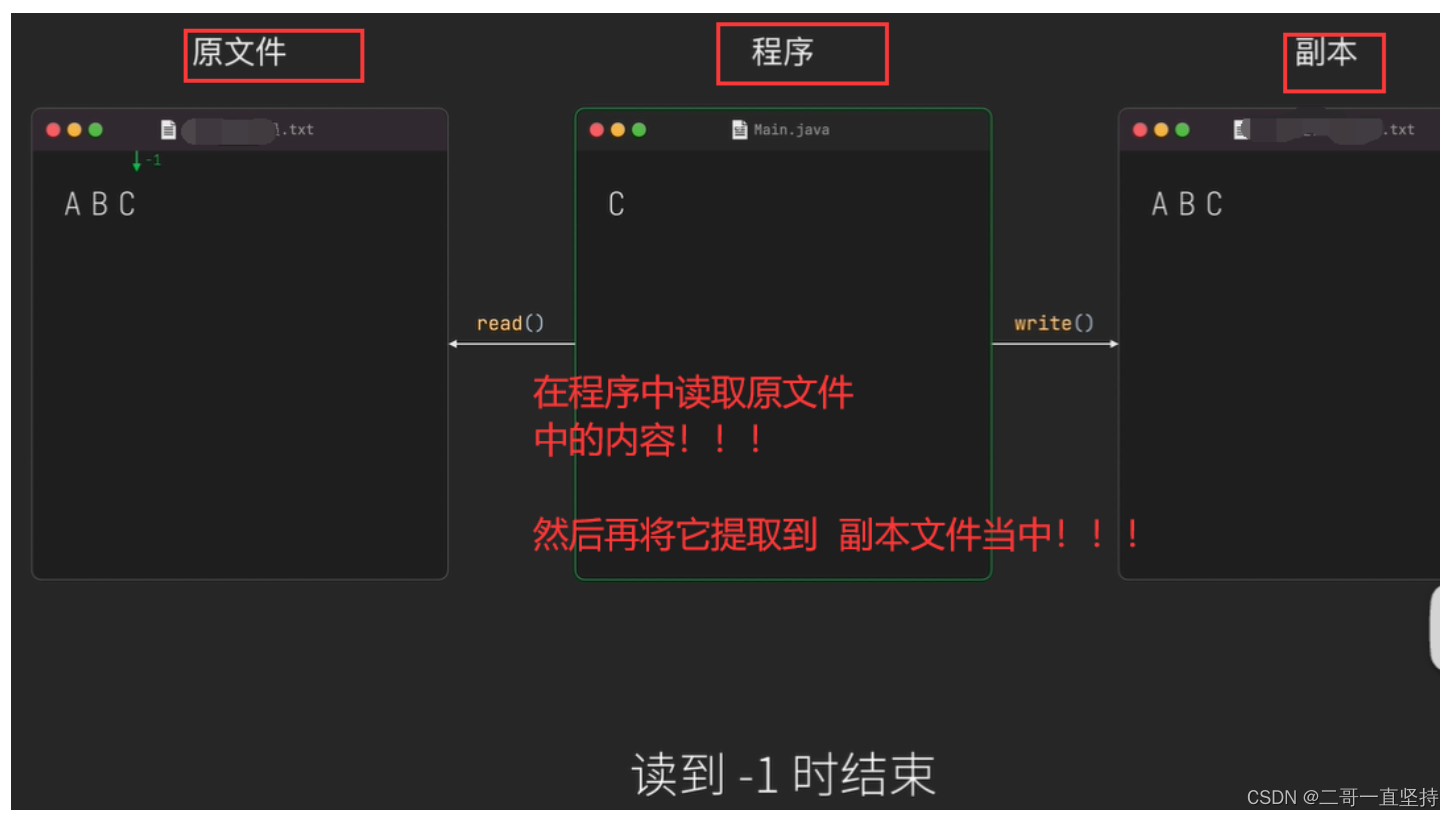
复制的本质其实是
把数据从一个文件中读出来
然后再写到另一个文件中去
这个过程是边读边写的
读到 -1 时结束
复制的前后内容一致
上面 提到的 ”读“ 和 ”写“
分别需要用到对应的流
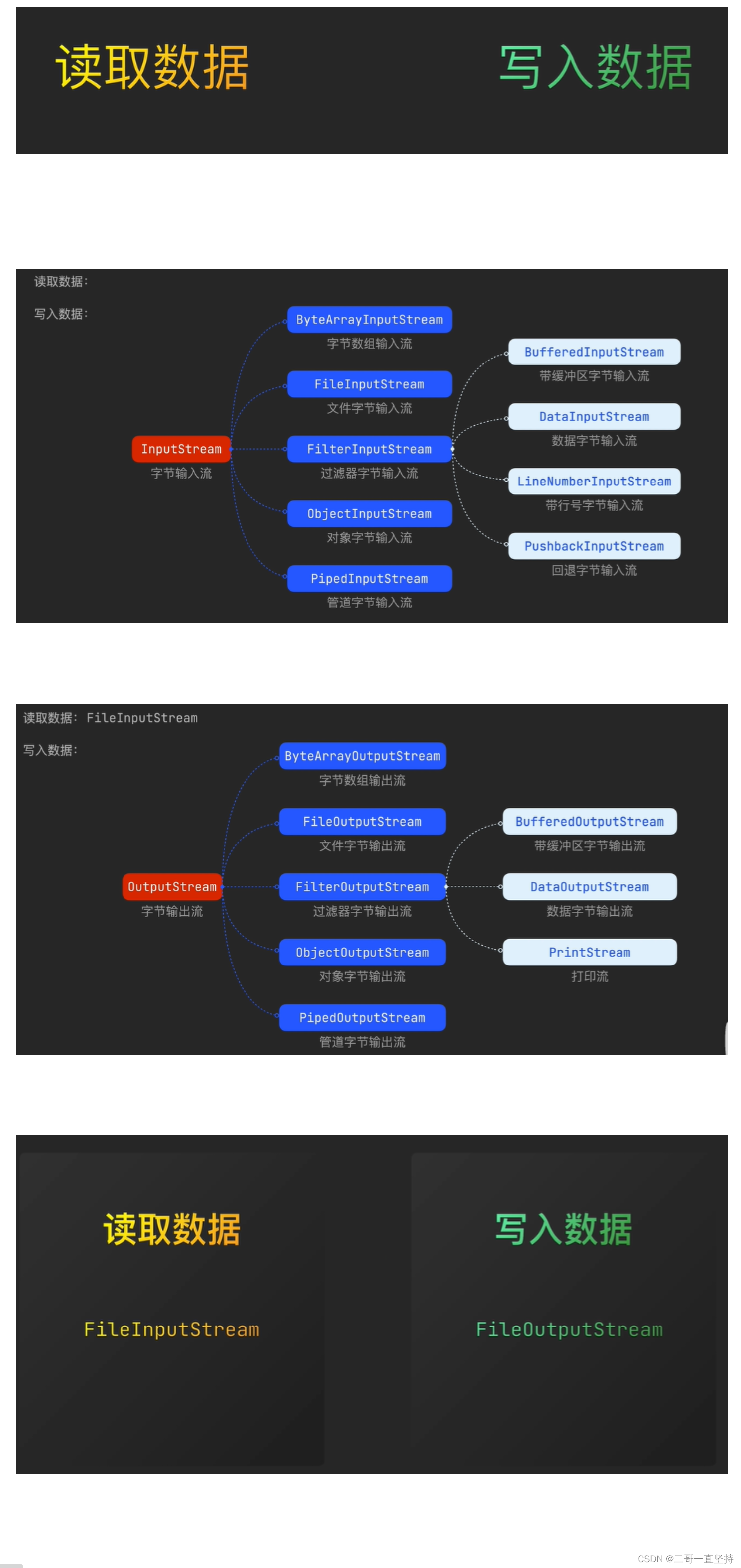
读取数据 需要用到输入流 InputStream
这里我们选择它其中的一个子类
FileInputStream
而写入数据 需要用到 输出流OutputStream
这里我们选择它其中的一个子类
FileOutputStream
选好输入输出流以后
接下来 编写示例代码
下面是我们要复制的文件
内容是 ”abc“
首先 声明 输入输出流
初始值 为null
然后 写上try 代码块
在 try 代码块中 初始化 输入输出流
输入流 传入的是 目标文件路径 (也就是你要复制哪个文件)
输出流传入的是目的地文件路径(也就是你要把复制的文件放在哪)
创建输入输出流有异常抛出
使用catch将其捕获
接下来 创建一个字节数组
长度为 1024
这是最常用的长度
接着 声明一个用于记录读取字节数的变量 length
使用 while语句
循环读取字节 读到 -1 时结束
每读取一次 都调用输出流的write方法
写入字节数组 偏移量 为 0(也就是从字节数组下标0的位置开始写)
每次写入的长度为 当前读取的字节数length
至此 try代码块里面的内容编写完成
接下来 写上 finally代码块
在finally代码块中 关闭输入输出流
在关闭流之前
先判断一下 流是否为空
至此
整个示例编写完成
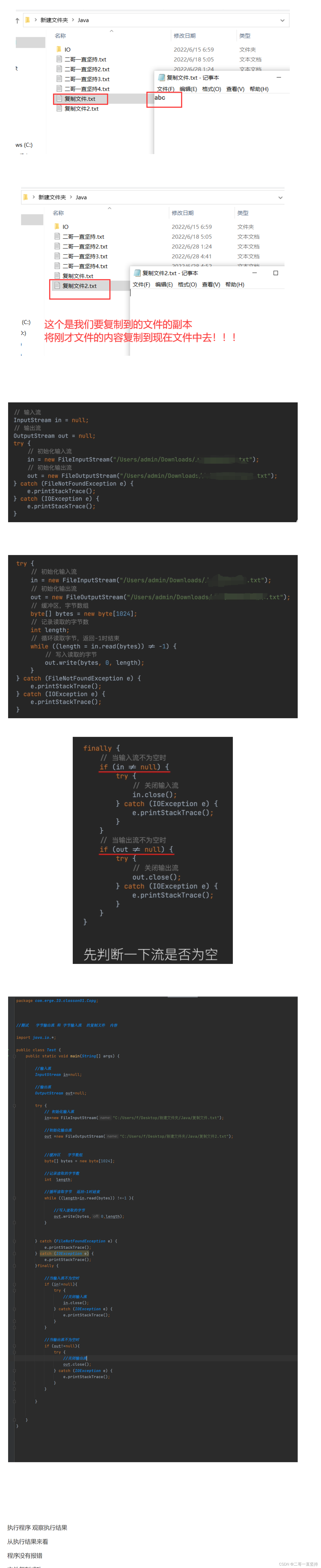
执行程序 观察执行结果
从执行结果来看
程序没有报错
文件复制成功
内容一模一样
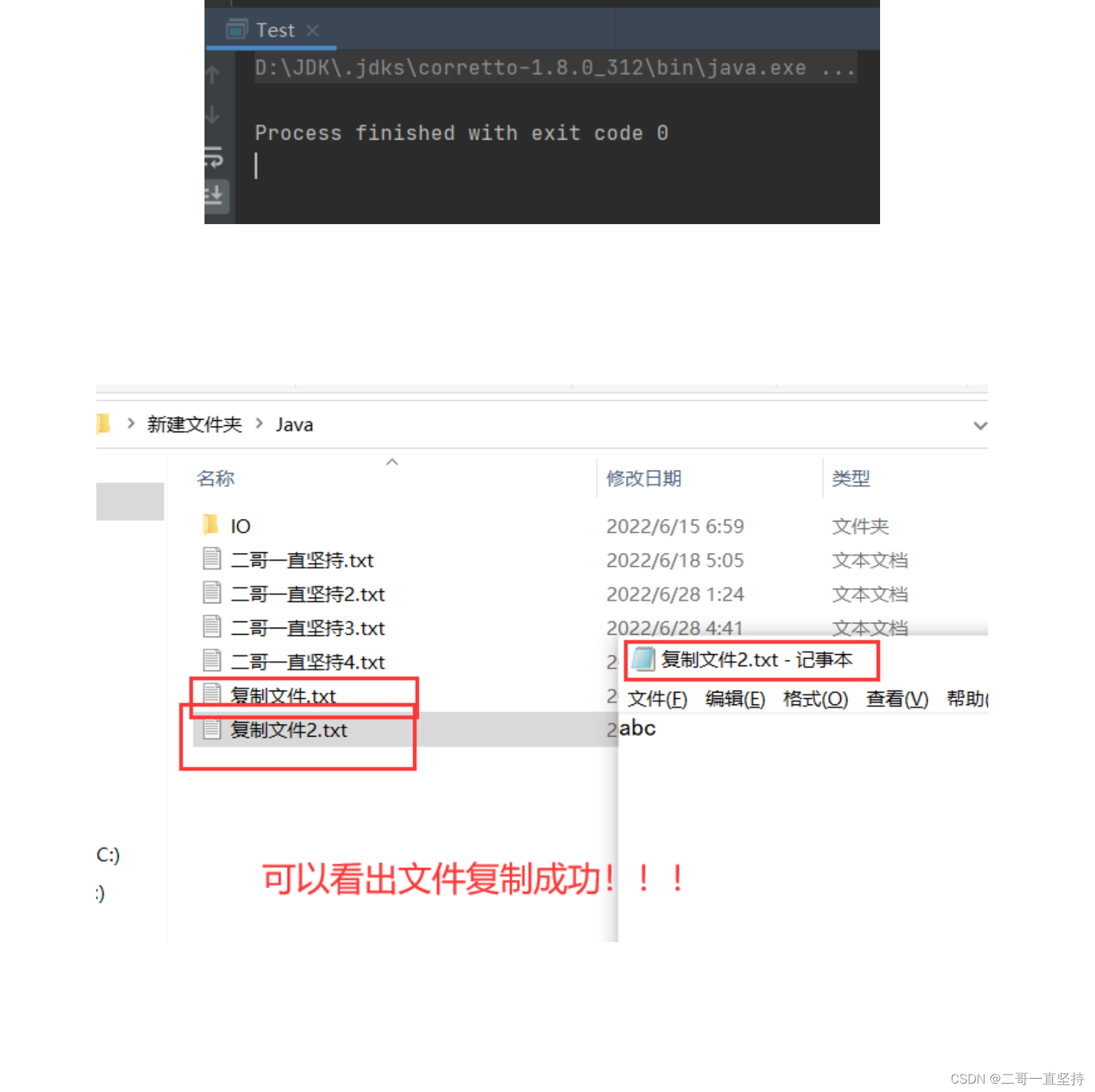
总结
本节介绍了 使用输入输出流 完成复制功能
一共有四步
第一步:声明输入输出流
第二步:初始化输入输出流
第三步:边读边写
第四步:关闭输入输出流

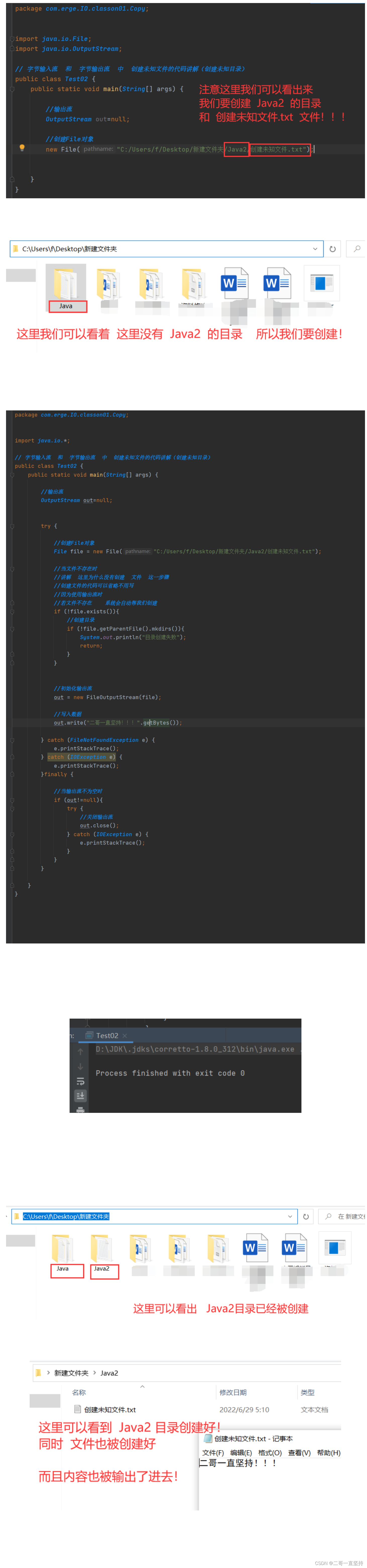
处理未知文件(未知目录不存在)
我们可能会遇到这种问题
向文件中写入数据时
明明已经判断了 当文件不存在时 创建新文件 可还是会出现错误
会显示 “No such file or directory”(无此文件或目录)
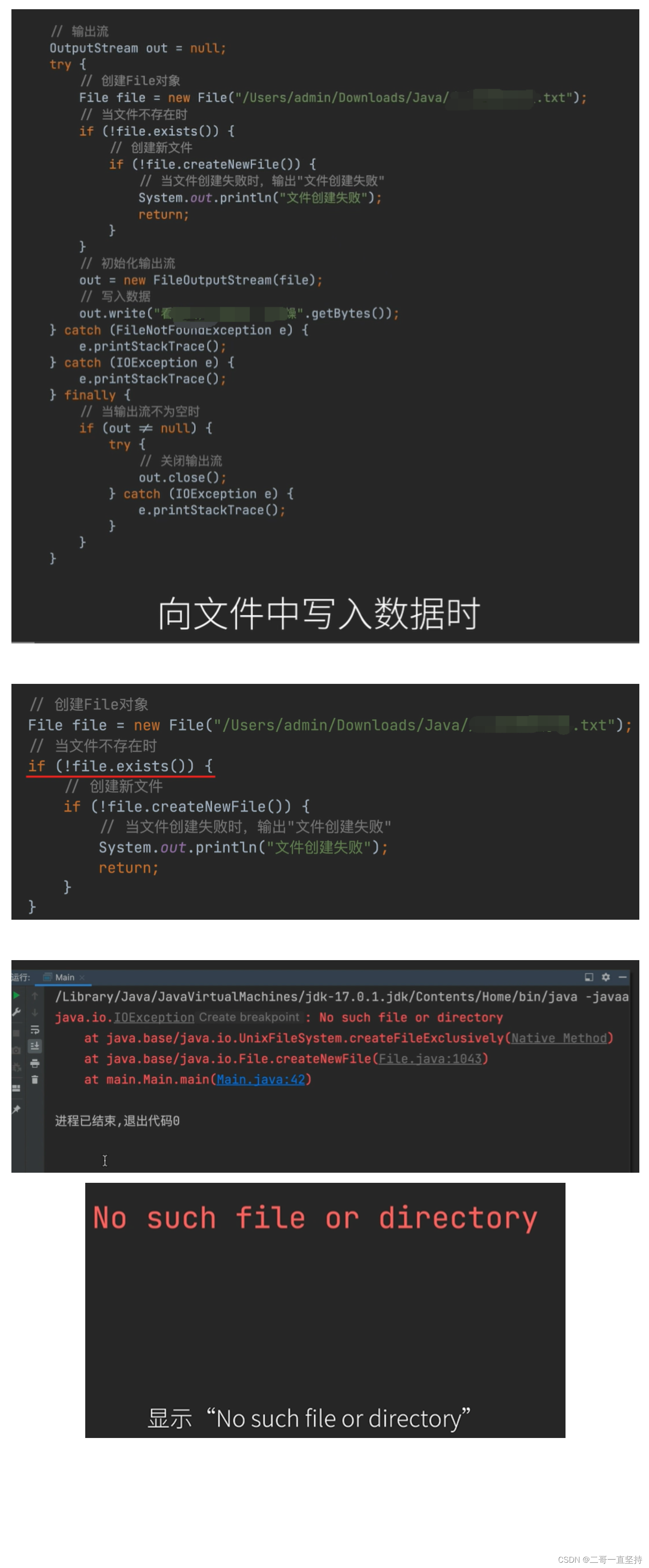
“无此文件”可以理解 所以我们才要创建
问题就出现在“无此目录”上
文件名之前的都是目录
经过验证: Users(用户)目录存在
admin目录存在 Downloads(下载)目录存在
发现问题 Java目录不存在
所以只要其中有一个目录不存在 文件就会创建失败
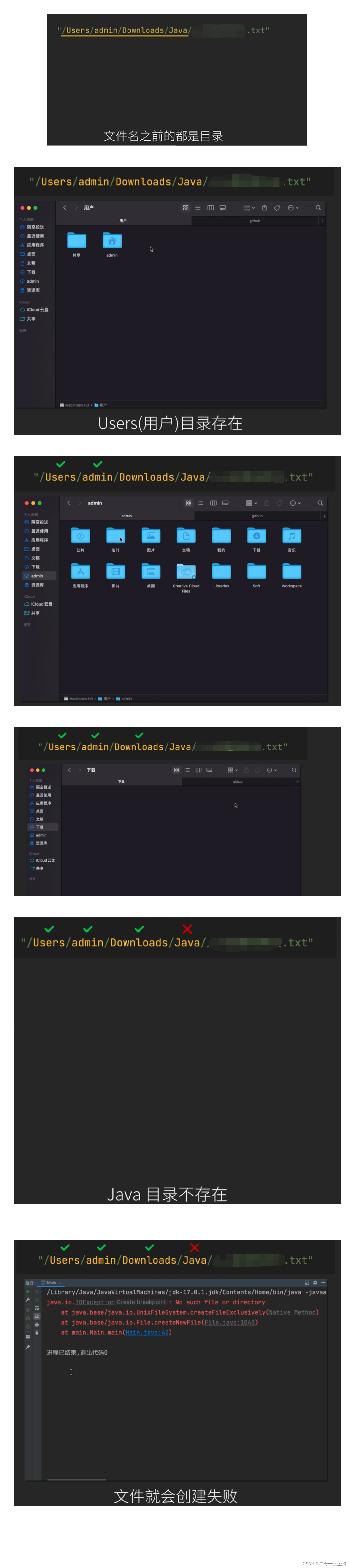
在实际开发中 究竟是哪一个目录不存在
我们不得而知
但无论是哪个目录不存在
我们都可以使用
File对象的mkdirs方法轻松解决
它可将路径中所有不存在的目录都创建出来

接下来 我们来重写
这段处理未知文件的逻辑
依然是使用File对象
当文件不存在时
调用file 对象的mkdirs方法创建目录
注意点! 这里的 “二哥一直坚持.txt” 是我们要创建的文件
它不是一个目录
它前面的才是目录
所以需要先调用getParentFile()方法
获得父路径 返回的是 一个File对象
紧接着再调用mkdirs方法 创建目录
当目录创建失败时 输出“目录创建失败”
并 return
当目录创建成功时 继续创建文件
当文件创建失败时 输出“文件创建失败”
并 return
至此 整个逻辑编写成功(重点 重点 重点!!!)
但是这部分代码还可以优化
创建文件的代码可以省略不用写
因为使用输出流时
若文件不存在 系统会自动帮我们创建
else 这部分代码
可以移动到 if 语句中
不要忘记取反
至此 优化后的代码编写完成
在日常开发中 我们可以用下面这段代码
来创建未知文件
接下来 我们用新逻辑替换掉上面的逻辑代码
再试试看
重点: 对比两者的不同
从执行结果来看:
程序没有报错
不存在的目录 和 文件都已经创建好
内容也写了进去
对比两者 总结为什么代码会出错

总结:
本节介绍了
如何处理未知文件
一共有四步
第一步 创建 File对象
第二步 判断文件是否存在
第三步 创建目录
第四步 处理创建失败的情况

字符编码
学习字符编码相关知识
有助于我们了解
计算机是如何储存字符的

一:ASCII
计算机里面只能存 0 和 1
存不了 A,B,C,
更存不了中文
那该怎么办呢?
只能搞一张表格
让字符与 “O” 和 “1" 对应起来
例如 01000001对应A
01000010对应B
以此类推
最早搞这张表的是美国 他们取名叫 “ASCII编码表”
也叫 “ASCII字符集”
共128个字符
其中包括 32个不可打印的控制符
10个数字 26个大写字母 26个小写字母
和 34个标点符号

 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









