







今天,我们来讲一下希尔排序!
希尔排序的优缺点:
优点:
这种排序,比简单插入排序更加快速,适应环境的能力很强,每排序完一遍,就越接近有序虽然时间复杂度为o^1.3次方,但其实每一次它的情况就朝好的方向发展,所以几乎不能按照最坏的情况考虑,所以我认为不能从时间复复杂度方面考虑!
缺点:
希尔排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择,并且希尔排序非常容易实现,算法代码短而简单。 此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。算法的性能与所选取的分组长度序列有很大关系。只对特定的待排序记录序列,可以准确地估算关键词的比较次数和对象移动次数。想要弄清关键词比较次数和记录移动次数与增量选择之间的关系,并给出完整的数学分析,今仍然是数学难题。
引子:什么事希尔排序?希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”,是直接插入排序算法的一种更高效的改进版本。
其实,该方法实质上是一种分组插入方法
图解:如图我们将以下数据排序的话,我们可以采用插入排序来,但我们进一步优化,进行分组插入排序。(不同的颜色代表一组数据)
基本思路:算法先将要排序的一组数按某个增量gap分成若干组,每组中记录的下标相差gap.对每组中全部元素进行排序,然后再用一个较小的增量对它进行分组,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
也就是说,相当于多个插入排序的拼接!
那gap的取值应该为多少呢?
我们想(从预排角度考虑)
gap值越大,那数据间隔越大,数据跳跃的速度就越大,大的越容易跳到后面,小的越容易跳到前面,但是它的数据就越不有序!
而gap的值越小,那数据间隔越小,数据跳跃的速度就越慢,大的不容易跳到后面,小的越不容易跳到前面,但是它的数据就越有序!试想gap==1时,不就是妥妥的插入排序吗?于是到底取多少呢?不要着急,我们有前人大佬的帮助!
对此,他们提出,gap一开始可以取n,然后gap/=2,这种到最后一定有gap==1的情况,也就是插入排序。还有人提出,gap一开始可以取n,然后gap/=3+1; 这二种都具有可能性,都不错对此,我就选取第一种情况来写!
代码展示:
#include<stdio.h>
#include<stdlib.h>
void shellsort(int*a,int n)
{
int gap = n;//令gap一开始为n;
while (gap > 0)
{
gap /= 2;
for (int i = 0; i < gap; i++)//进行排序
{
for (int j = 0; j < n - gap; j += gap)//一遍排序
{
int end = j;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
}
void print(int* a,int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
}
效果展示:

检查效验:
我们随机生出100000个数据比较插入排序与希尔排序。
对此我们先给出插入排序的代码,翻遍比较
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
// [0, end] end+1
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
效果:
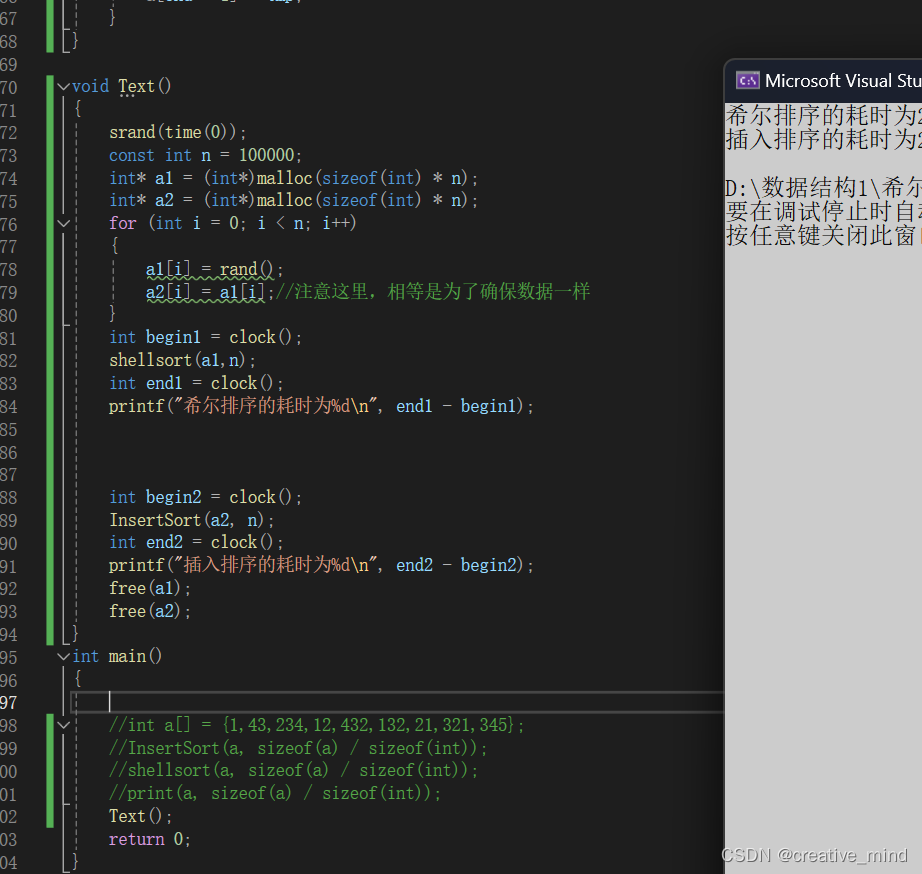
注意用relse来调整!
知道的铁汁们,可以私信我!
到此一游,今日就到这里啦!















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









