







C++ Primer Plus
主要是面向对象的一些东西。总的来说这本书是一本烂书,既不适合零基础的初学者,也不适合有基础的进一步学习,更不适合希望了解语言的实现和细节的。烂完了
0 内存模型,一些开始前的注意事项
存储持续性,作用域,链接性
声明一个变量无非几种情况:
- 位置上:在函数体或者代码块中,或者在所有函数体和代码块外
- 是否有关键词
static - 使用动态内存分配
new,delete
| 存储描述 | 如何声明 | 持续性 | 作用域 | 链接性 |
|---|---|---|---|---|
| 自动 | 在代码块或函数体中 | 自动 | 代码块 | 无 |
| 寄存器 | 在代码块或函数体中,使用关键词register | 自动 | 代码块 | 无 |
| 无链接性静态 | 在代码块或函数体中,使用关键词static | 静态 | 代码块 | 无 |
| 内部链接性静态 | 在所有代码块或函数体外,使用关键词static | 静态 | 文件 | 内部 |
| 外部链接性静态 | 在所有代码块或函数体外 | 静态 | 文件 | 外部 |
-
持续性:讲的是储存变量的内存
- 自动:进入代码块或者函数创建,在代码块或函数执行完后销毁
- 静态:在程序运行时就创建,程序结束运行才消失
- 理解静态的关键是:静态就是在程序编译期间就完全确定下来并分配好内存,关键词:编译时期,即在程序运行之前
- 动态管理:
new创建delete销毁
-
作用域:讲的是变量的名字
- 文件:单一文件中可见,同名会被局部变量屏蔽
- 代码块:只在代码块中可见,内层屏蔽外层
-
链接性:名称的共享性
- 无:不许共享
- 内部:可以在单一文件中共享
- 外部:可以在多文件间共享
- 一个名称
int x在文件1.cpp中定义,为了在文件2.cpp中使用,需要引用声明extern int x
- 一个名称
常量
const从“不让这玩意儿修改”出发
const声明一出现,必须给他当场初始化喽- 当且仅当给他初始化的时候,
const修饰的东西才当左值,也就是禁止其被赋新值 const type *声明“指向常量的指针“ ,type const *声明"常量指针"(引用同理)- 只有
const type *能指向const type的对象- 意思是非
const type *的指针不许指向常量。(引用同理) - 意思是可以用
const type *指针指向可变的量,只是指完以后就不许用这个指针来改变指向的值了(引用同理)
- 意思是非
type fuction() const;声明的成员函数不能修改类的成员数据- 如果创建
const Object obj,即常量对象,则通过该对象只能调用以上声明的方法
- 如果创建
引用
引用是大部分语言用于取代指针的做法。意思就是”为该变量取个别名“
- 引用必须当场初始化且只能初始化一次
1 对象和类
oop 特性
- 抽象
- 封装和数据隐藏
- 多态
- 继承
- 代码重用
抽象和类
实现成员类函数
- 实现成员函数时,用作用域解析运算符
::指定函数所属的类 - 类方法可以访问类的private组件
当函数的定义直接位于类声明中,自动成为inline类型
类的构造函数和析构函数
使用构造函数来初始化一个对象,使用析构函数在对象被摧毁前做一些操作
在以下的讨论中,假设哦我们有一个Stock类
声明和定义构造函数
在类声明时,加入和类名一样的函数名,不要加入返回类型
class Stock{
public:
Stock(long n = 0,double f = 0.0);
}
实现时,像正常的类成员一样实现
Stock::Stock(long n = 0,double f = 0.0){
//do something
}
使用构造函数
每次创建对象时,都会调用类的构造函数
显式调用
Stock A = Stock(10,19.2);
隐式调用(括号初始化)
Stock A(10,19.2);
列表初始化,像C的struct一样
Stock A = {10,19.2};
new对象
Stock *pA = new Stock(10,19.2);
默认构造函数
- 如果没有创建自己的构造函数,则自动提供一个默认构造函数,不接受任何参数,不干任何事情
- 如果已经定义了自己的构造函数,就不再有默认的构造函数,但是构造函数可以重载,即可以有多个不同参数列表的构造函数
析构函数
- 当对象过期时,自动调用类的析构函数。通常不显式地调用析构函数,在对象的生命周期结束后,自然会调用
- 系统会提供默认的析构函数
- 析构函数不能接受任何参数
- 命名为
~Stock(),就是~加到类名之前 - 一般析构函数干的事就是“处理后事”,比如将构造函数
new出来的东西delete掉
this指针
- this指针总是作为隐藏参数传递给方法
- this指针指向调用它的对象的地址
书上的例子
const Stock & Stock::topval(const Stock &s) const {
if(s.val > val) return s;
else return *this
}
对象数组
这里书上有事实上的谬误,也可能是因为版本更迭,已更正
-
按照以下语法,创建并立即初始化对象数组,像下面这样
Stock stocks[7] = { Stock("saabi",10,10.1), Stock(10,8.0), }-
以上的流程是:
- 按照顺序调用类的构造函数
- 如果显式调用的构造函数数量 < 数组大小,则调用默认构造函数创建剩余的对象(也就是说遇到这种情况必须存在默认构造函数)
-
-
如果是先创建数组
Stock stocks[7];,但是没有显式调用别的构造函数,则立即调用默认构造函数,创建数组大小数量的对象,所以必须拥有默认构造函数(没有任何参数)。
类作用域
- 在类中定义的名称,作用域都为整个类
- 作用域为类的名称,只在类内是可知的,在类外不可知
作用域为类的常量
错误的用法:直接在类内声明为private,这是因为类的声明只是描述了类的模式,并没有分配内存。只有一个对象被实例化时,才会分配内存
正确的做法:
- 在类内声明一个枚举
class A{
private:
enum {constant=10};
}
- 直接声明为
static const:注意所有静态变量都是储存在同一个地方,并不会存储在为对象创建的内存内。同一类的多个对象中共享一个静态变量
class A{
private:
static const int constant = 10;
}
类作用域枚举
新的枚举语法,可以定义相同的名字了
enum class egg{small,big};
enum class potato{small,big}
使用时加入作用域解析符egg::small
2 使用类
运算符重载
将运算符扩展到用户的类型
美观,易于理解
返回类型 operator运算符(参数列表)
和函数差不多,既可以作为类成员,也可以不作为
时间类:运算符重载实例
class time{
private:
int hours;
int minutes;
public:
Time();
Time(int h,int m);
};
添加加法运算符
这里展示了如何重载有两个操作数的运算符
声明:
public:
Time operator+(const Time & t) const;
定义:
Time Time::operator+(const Time &t) const {
Time sum;
sum.minutes = minutes+t.minutes;
sum.hours = hours+t,hours+sum.minutes/60;
sum.minutes %= 60;
return sum;
}
调用:像函数一样调用,下面展示的是 作为类成员 的运算符重载被调用时的本质
total = a.operator+(b);
或者当成基本类型的运算符调用,对于二元运算符+,运算符左侧作为调用的对象,右侧作为参数对象。也就是说,下面的调用方式的本质是上面
total = a + b;
由于返回的类型还是对象,所以该运算符还可以链式调用,向下面所示是合法的
total = a+b+c;
//total = ( a.operator+(b) ).operator+(c);
重载限制
- 重载后的运算符必须至少有一个操作数是用户定义的类型
- 不能违反原有的运算符规则:
- 不能改变操作数数量
- 不能改变运算符优先级
- 不能创建新的运算符
- 有不能被重载的运算符
- 有只能被重载为成员函数的运算符:
=赋值()函数调用[]下标->指针访问类成员
重载语法总结
令@表示运算符
- 成员函数
- 一元
- 前缀:
@x,原型是返回类型 operator@(); - 后缀:只有
x++,x--,原型是返回类型 operator@(int);- 注意
(int)这个形参不做任何作用,仅是为了与前缀一元运算符区分
- 注意
- 前缀:
- 二元:
x@b,原型是返回类型 operator@(类类型 b);
- 一元
- 友元函数
- 一元
- 前缀:
@x,原型是friend 返回类型 operator@(类类型 x); - 后缀:只有
x++,x--,原型是friend 返回类型 operator@(类类型 x,int);- 注意
,int)这个形参不做任何作用,仅是为了与前缀一元运算符区分
- 注意
- 前缀:
- 二元:
x@b,原型是friend 返回类型 operator@(类类型1 a,类类型2 b);
- 一元
友元
友元有三种
- 友元函数
- 友元类
- 友元成员函数、
在这里只讨论友元函数
通过让函数成为类的友元,可以赋予该函数与类成员相同的访问权限
为何需要友元:希望函数能直接访问作为参数传递的类的私有成员
创建友元
将原型放在类声明中,并在前面加上关键字friend
friend Time operator*(double w,const Time & t) ;
注意:
- 该函数不是成员函数,不能像成员函数一样调用
- 与成员函数的访问权相同
编写函数定义:
Time operator*(double w,const Time & t){
Time ans;
long total_minutes = t.hours*m*60 + t.minutes*m;
ans.hours = total_minutes/60 ;
ans.minutes = total_minutes%60 ;
return ans;
}
注意:
- 首先是非成员的二元运算符重载,第一个参数作为左操作数,第二个参数作为右操作数
- 编写定义时,不要使用作用域解析
::
提示
- 如果想要重载运算符,但是不想把类成员作为左操作数,则使用友元
常用方法:重载<<
目标:实现cout<<一个对象这样的效果,由于要重载操作符,且自定义的对象不作为左操作数,所以最好用友元
- 第一版
void operator<<(ostream & os, const Time & t){
os << "hours:" << t.hours << endl;
os << "minutes:" << t.minutes << endl;
}
- 如果想实现像
cout<<"a"<<endl,这样的连环调用,只需要让函数继续返回一个os对象即可
ostream & operator<<(ostream & os, const Time & t){
os << "hours:" << t.hours << endl;
os << "minutes:" << t.minutes << endl;
return os;
}
再谈重载:一个矢量类(多表示的类)
这一节在SICP中其实更加详细的讨论过
多表示的类:矢量既有 ( x , y ) (x,y) (x,y)的表示,又有 ( ρ , θ ) (\rho,\theta) (ρ,θ)的表示,两种表示能互相转换,各有利弊,为了同时在一个类的实现中,同时保有两种表示方式,需要做一些工作
直接给相出以下实例
#include <iostream>
namespace VECTOR{
class Vector{
public:
enum Mode {RECT,POL};
private:
double x,y;
double mag,ang;
Mode mode;
//for setting values
void set_mag();
void set_ang();
void set_x();
void set_y();
public:
Vector();
Vector(double m,double n,Mode form = RECT);
~Vector();
//getter
double xval() const {return x;}
double yval() const {return y;}
double magval() const {return mag;}
double angval() const {return ang;}
//mode setter
void polar_mode();
void rect_mode();
//operator overloading
Vector operator+(const Vector & v) const;
Vector operator-(const Vector & v) const;
Vector operator-() const;
Vector operator*(double n) const;
//friends
friend Vector operator*(double n,const Vector & v);
friend std::ostream &
operator<<(std::ostream &os,const Vector & v);
};
}
该类使得用户可以直接将两个矢量进行运算,而无需关心矢量底层究竟是使用了“何种表示方法”
下面讨论一些特性
使用状态成员
上述在类声明中声明了一个枚举量mode,用来表示当前对象用了什么表示方式。
类的构造函数和重载的<<将判断mode值,并作出不同的行为
Vector::Vector(double m,double n,Mode form){
mode = form;
if(form == RECT){
x = m;
y = n;
set_ang();
set_mag();
}
else if(form == POL){
mag = m;
ang = n;
set_x();
set_y();
}
else {
cout << "ILLEGAL FORM" << endl;
cout << "setting vector to zero" << endl;
x = y = ang = mag = 0;
}
}
这个构造函数还指出了,如果需要类有多种表示,可以采用上面的方法:
- 定义代表 表示方式 的变量
- 定义私有方法:多种表示互转
- 在构造函数内判断表示方式,初始化后调用互转的私有方法
为Vector重载算术运算符
这里体现了C++PP讲的烂的地方:对于矢量类来说,极坐标形式没有太大的价值。在SICP中,以复数举例。
为什么复数是个好例子?因为复数运算的独特性质:对于加法来说,直角坐标形式非常简单;对于乘法来说,极坐标非常方便
-
展示了如何利用用构造函数简化加法的实现:即用一种表示方法计算完后,将结果传递给构造函数,以“广播”到所有表示方法
Vector Vector::operator+(const Vector & v) const{ return Vector(x+v.x,y+v.y); } -
展示了重载一元运算符的过程,注意类里的声明和实现:这里重载了取负运算符
-Vector operator-() const;Vector Vector::operator-() const{ return Vector(-x,-y); }
类的自动转换和强制类型转换
首先复习内置类型转换:
- 将一个标准变量的值赋给另一个的时候,如果两种类型兼容,自动执行类型转换,统一为接受变量的类型。例如
int i = 3.1 - 对于不兼容的类型,可以使用强制类型转换。例如
int *p = (int *)10
对于类,所有 接受一个参数 的构造函数,可以使得该类的对象与该参数类型的变量进行自动的参数转换
例如,下面这个类里面有两个可以只接受一个参数的构造函数
class A{
int x;
double y;
public:
A(){x = 0;y = 0;}
A(double yy){y = yy;x = 0;}
A(int xx,double yy = 0.0){x = xx;y = yy;}
};
于是可以像下面这样:
A a1,a2;
a1 = 3.1;//double to A
a2 = 4; //int to A
自动类型转换发生在下面的场景:
- 将
A对象初始化为double类型 - 将
double类型赋给A对象 - 将
double值传给接受A对象的函数 - 返回
A对象的函数试图返回double值
关键词explicit可以关闭自动类型转换的功能:explicit A(double yy){x = 0;y = yy;},但是仍然可以使用强制类型转换a1 = A(3.1)或者a1 = (A)3.1
转换函数
上面的例子展示了怎么1将基本类型转化为对象类型,如果想要做相反的操作,则需要重载类型转换运算符,这称为转换函数。原型是operator typename();。有以下要求
- 只能作为类的方法被重载
- 不能指定返回类型
- 不能有参数
例:
class A{
int x;
double y;
public:
A(double yy);
operator double() const;
};
A::A(double yy){
x = int(yy);
y = yy - x;
}
A::operator double() const{
return x+y;
}
在这个例子里,A类型就与double类型完全可以互转了
A a = 12.1;
double x = a;
同样的,可以用关键词explicit关闭隐式的自动类型转换,只保留强制类型转换的功能
类与其他类型运算
如果想要承载上面提到的A类与double的加法,有两种方法:
- 直接重载成接受
double为参数的运算符- 优点:运行快
- 缺点:写的长,繁琐。如果我需要与多种类型相加,那就需要不断重载
- 只重载一个接受
A类为参数的运算符,让类型转换帮助我们将double类型自动转化成A类- 优点:方便写,方便管理
- 缺点:内存和时间开销大
3 类和动态内存分配
动态内存和类
newdelete管理内存- 析构函数的使用
- 重载赋值运算符
复习动态内存分配和静态类成员
例子:StringBad类
class StringBad {
private:
char *str;
int len;
static int num_strings;
public:
StringBad(const char *s);
StringBad();
~StringBad();
friend ostream & operator<<(ostream os,const StringBad & st);
};
静态类成员:
-
在内存中只有一份,即该类的所有对象公用一个
static成员,并在编译阶段就提供初始化int StringBad::num_strings = 0; -
并且该初始化不能放在类声明中,因为类声明只是描述类的结构,并不进行内存分配
-
该初始化不能放在类声明的头文件中,这是因为头文件被多次包含,导致多次初始化,会出问题
包含new的构造函数
StringBad::StringBad(const char *s){
len = strlen(s);
str = new char[len+1];//动态分配内存
strcpy(str,s);
num_strings++;
}
包含delete的析构函数
StringBad:: ~StringBad(){
num_strings--;
delete[] str;//释放内存
}
这个类有非常多的问题,问题的原因在下面
特殊成员函数
创建类时,C++自动提供下面的成员函数
- 默认构造函数,如果还没有定义构造函数
- 默认析构函数,如果没有定义
- 复制构造函数,如果没有定义
- 赋值运算符,如果没有定义
- 地址运算符,如果没有定义
默认构造函数
如果没有定义构造函数,C++将提供一个,不接受任何参数,不进行任何操作的默认构造函数
如果定义了构造函数,该默认构造函数也就不存在了。如果仍然想在对象创建时不显式的对其进行初始化,则需要定义自己的不接受任何参数的构造函数,意思是:
- 纸面上的意思,在已定义好的接收参数的构造函数外再定义一个不接受任何参数的构造函数
- 直接提供一个,所有参数都有默认值的构造函数
A(int x = 0,int y= 0,int z = 0);
复制构造函数
类的复制构造函数的原型通常如下:
Class_name(const Class_name &)
接受一个指向类对象的常量引用作为参数
-
何时调用复制构造函数:新建一个对象,并将其初始化为同类现有对象时
- 最常见,就是将新对象显式的初始化为现有对象
- 每当程序生成了对象副本时,编译器都将使用复制构造函数
- 按值传递的函数
- 函数返回一个对象
-
默认构造函数的功能:
- 逐个复制非静态成员,复制的是成员的值(浅复制)
- 如果成员本身又是类对象,则将再调用这个类的复制构造函数来复制对象
赋值运算符
C++允许类对象赋值,这是通过自动为类重载赋值运算符实现的,原型如下:
Class_name & Class_name::operator=(const Class_name &);
赋值运算符和复制构造函数功能基本上相同,只是调用时机不同
- 当将已有的对象赋值给另一个时,调用赋值运算符
- 逐个复制非静态成员,如果成员本身又是类对象,则将再调用这个类的赋值运算符来复制对象
错误的改正与类的改进
一切错误的根源,都在于在StringBad类中,为了动态管理内存,我们采用指向分配的指针作为类的成员,而这与浅复制的搭配极其危险,原因是:
- 进行浅复制时,只复制了指针的值,而不是新开辟了一片空间。这就导致了多个指针指向同一个内存
- 每次对象过期时,调用析构函数,导致多次删除同一地址,会导致未定义的动作
要想修正这个问题,只有进行深复制
定义显式的复制构造函数
StringBad::StringBad(const StringBad &v){
num_strings++;
len = v.len;
str = new char[len+1];
strcpy(str,v.str);
}
定义显式的赋值运算符
与复制构造函数一样,但是有所区别
- 目标对象可能引用了以前分配的数据,所以要先用
delete[]删除这些数据 - 避免将对象赋值给自身
- 返回一个指向调用对象的引用,以满足连续赋值的需求
StringBad & StringBad::operator=(const StringBad &v){
if(this == &v) return *this; //什么都不干
delete[] str;//删除旧内容
str = new char[v.len+1];
len = v.len;
strcpy(str,v.str);
return *this;
}
重载中括号[]
-
非常量版本:支持对于类的按索引读写
char & StringBad::operator[](int i){ return str[i]; }尽管我们好像是在狠狠的访问私有成员,但是由于
operator[]是共有,所以可以直接对私有成员做出改变 -
常量版本:只读,适用于声明为
const的变量const char & StringBad::operator[](int i) const { return str[i]; }
静态类成员函数
- 静态成员函数不与任何对象相关联,所以只能使用类的静态成员
- 静态成员函数只能由类作用域解析调用
Class_name::Static_member_func(...)
进一步重载赋值运算符
为了让String类与char[]更兼容,如果经常存在向对象赋值一个字符数组的情况时,按照以前我们讲的是下面的情况:
- 首先调用只含有一个参数的构造函数进行隐式的类型转换,创建临时对象
- 调用接受类
String类为参数的oprator=,进行赋值 - 临时对象过期,调用析构函数
如果这种操作非常频繁,将会十分影响效率,所以考虑直接重载一个接受字符数组为参数的operator=
StringBad & StringBad::operator=(const char *s){
delete[] str;//删除旧内容
len = strlen(s);
str = new char[len+1];
strcpy(str,s);
return *this;
}
重载运算符>>
首先定义一个常量static const int CIN_LIM = 80;
来指定输入最大的字符串长度
与<<一样,我们将>>定义为友元
istream & operator>>(istream &is,StringBad &st){
char temp[StringBad::CIN_LIM];
is.get(temp,StringBad::CIN_LIM);
if(is){
st = temp; //直接使用赋值运算符方便
}
while(is && is.get() != '\n') continue;//清理多余字符
return is;
}
在构造函数中使用new时的注意事项
- 如果在构造函数中使用
new,则必须在析构函数用delete释放内存 new和delete匹配,注意有无方括号- 应以深度复制的方式重写复制构造函数
- 应以深度复制的方式定义赋值运算符
有关返回对象的说明
- 返回对象的引用:通常是出于效率的考虑
- 返回作为参数传递的对象
- 返回
*this - 返回一个没有公有复制构造函数的对象,必须返回引用(
ostream类等)
- 返回对象
- 函数中的局部变量:比如重载运算符
- 返回const对象
- 不声明为
const的返回对象,有被作为左值的风险。通常这会带来意想不到的错误,比如在不声明为常量的加法重载中,a+b = c这样的语法是合法的
- 不声明为
使用指向对象的指针
主要是讲了new创建对象
Class_name *object = new Class_name(...)
将调用对应的构造函数
在下述情况下析构函数将被调用
- 如果对象是动态变量,执行完定义该对象的程序块时,调用析构函数
- 如果对象时静态变量,执行完整个程序,调用析构函数
- 对象由
new创建,当且仅当其被delete,析构函数被调用 - 对象由定位
new创建,则需要显式调用析构函数- 创建缓冲区
char *buffer = new char[BUFF_SIZE] - 定位:
somclass* p1 = new (buffer) someclass(...)- 其中
new后第一个括号内的参数是:开始分配内存的地址 - 继续在缓冲区内分配内存,注意调整以上参数
someclass* p2 = new (buffer+sizeof(someclass)) someclass(...)
- 其中
- 这是因为
delete可以与常规的new配合,但无法配合定位new - 想要删除定位
new出来的对象,只能delete[]整个缓冲区,此时缓冲区上的所有东西会被“抹去”,并不会执行析构函数 - 想要为其执行析构函数,直接显式调用
p1->~somclass()
- 创建缓冲区
4 类继承
一个简单的基类
从一个类派生出另一个类时,原来的类称为基类,派生出来的叫派生类
以下假设我们已经有了一个Father类
派生一个类
C++的类继承写法
class Son : public Father {
//...
};
- 冒号指出
Son是派生自Father public表示Father是一个公有基类,这被称为共有派生- 基类的公有成员称称为派生类的公有成员
- 基类的私有部分成为派生类的一部分,但只能通过基类的共有和保护方法访问
- 派生类存储了基类的数据成员
- 派生类可以使用基类的方法
需要在继承特性中做什么:
- 派生类需要自己的构造函数
- 派生类根据需要添加数据成员和成员函数
构造函数与析构函数
派生类的构造函数要点:
- 首先创建基类对象
- 派生类构造函数应该通过 成员初始化列表 将基类信息传递给基类构造函数
- 派生类构造函数应初始化新增的数据成员
成员初始化列表的语法如下:
derived::derived(type1 x1,type2 x2,...,typen xn) : base1(x1),base2(x2),...,basen(xn){ /... }
- 冒号后面跟的一串是各个基类的构造方法
- 意思是将派生类构造方法中的某些参数传递给基类的构造方法,并依次执行基类的构造方法
对于某个层层派生出的类,整个构造-析构的顺序如下:
使用派生类
使用派生类,则必须能够访问基类的声明
一般将基类和派生类的声明放在同一头文件
派生类和基类之间的特殊关系
- 派生类可以使用基类的方法,只要方法不是私有的
- 引用(指针)兼容
- 基类指针可以在不进行显式的类型转换下指向派生类的对象
- 基类引用可以在不进行显式的类型转换下引用派生类的对象
- 基类的指针和引用就算是指向了派生类对象,也只能调用基类的方法
- 函数参数传递时,可以将派生类传递给接受基类的形参
- 可以用派生类对象初始化基类,这相当于
- 调用基类的复制构造函数,该函数需要一个基类的形参
- 派生类被传递给该形参
- 可以将派生类对象赋值给基类对象,这相当于
- 调用基类的
operator=,需要一个基类的形参 - 派生类被传递给该形参
- 调用基类的
继承:is-a 关系
-
公有继承建立is-a 关系,也就是 is-a-kind-of ,即派生类对象也是一种基类对象,所有对基类对象能执行的操作,也都能对派生类执行
-
不建立 has-a 关系,一般has-a 关系通过类组合来建模
-
不建立 is-implemneted-as-a 关系,例如可以用数组实现栈,但是不能将栈从数组中派生出来,因为栈 isn’t a 数组。正确的做法是,栈类将把数组作为私有成员来实现
-
不建立 is-like-a 关系,公有继承派生类有基类的所有成员,所以派生并不适合 is-like-a。好的做法是重新设计
-
不建立 uses-a 关系,使用的关系最好用友元函数和友元类来处理类之间的通信
多态公有继承
希望同一个方法在派生类和基类的行为不同,方法的行为应该取决于调用该方法的对象,这被称为多态
有两种重要的机制可以用来实现多态共有继承
- 在派生类中重写基类的方法
- 使用虚方法
重写类方法
在派生类中声明名称和参数列表完全与基类某方法相同的名称,即两函数原型完全一致
注意,这里是重写而不是重载,重写的派生类的实现将覆盖基类的实现,连带基类重载过的版本
所以在应用多态时,需要纯纯的复制粘贴,把基类该方法名的所有声明都复制一遍粘贴到派生类
虚方法
虚方法和普通方法的差别主要体现在引用和指针上,如前面所述,一个基类的指针(引用)可以指向派生类的对象,
- 对于一般的重写的方法来说,调用方法的版本与指针(引用)相匹配。即:如果基类引用派生类对象,则调用基类版本
- 如果将方法声明成
virtual,则调用方法的版本与被指(被引用)相匹配。即:如果基类引用派生类对象,则调用派生类版本
应用虚方法的例子
-
我们现在有用户和VIP用户,满足 is-a 关系,我们让
class Vipuser派生自class User。-
我们现在想 创建一个数组对所有用户统一进行管理,如果使用对象数组,则由于数组内类型相同的限制,无法将VIP用户加入管理
-
好的选择是,用对象指针数组。这又利用了基类指针可以指向派生类的特性,创建一个基类指针数组,则同样可以存放派生类的数组
-
为了让重写的函数保持 “在基类和派生类中有不同的行为” 的特性,则必须将有需要方法声明为
virtual
-
-
另外的例子是,比如我现在有一个接受基类引用的函数
f(Base & object),我在函数体中调用了类方法object.somfunc()- 假如我要求,该函数对所有的派生类也使用,同时派生类的行为要与基类不同
- 那必须把方法
somfunc()声明为virtual
为何需要虚析构函数
需要虚析构函数的原因如下:
- 首先如果一个基类的指针现在指向派生类对象,如果析构函数不虚,则在
delete该指针时。上来就直接调用的是基类的析构函数 - 将虚构函数设为虚后,能保证析构函数永远自动按照正确的 派生类->基类 的顺序调用
静态联编和动态联编
将源代码中的函数调用解释为执行特定的函数代码被称为函数名联编
- 在编译过程中完成的联编称为 静态联编,基本上解决函数重载等情况
- 虚函数的存在使得静态联编不能解决一切情况,必须在程序运行的时候进行联编,这被称为动态联编
指针和引用类型的兼容性
将派生类引用或指针转换为基类的,被称为向上强制转换
这是处于 is-a 规则,派生类 is-a 基类,一切能对基类满足的操作也都能施加于派生类,所以才可以使用向上强制转换而不发生错误
原理是:将派生类中继承得来的基类组件的地址,赋值给基类指针(引用),该指针(引用)指向的是派生类对象的一部分
相反的过程在不进行显式的强制类型转换的情况下是不允许的,即一般情况下不允许基类的引用或指针随意转换成派生类的,这与 is-a 关系不可逆也有所关系
虚成员函数和动态联编
编译器总是对虚方法进行动态联编,即在运行时确定调用的版本
下面有几个问题
- 为什么不把动态联编设定为默认的方式?
- 出于效率的考虑,显然,为了进行动态联编,必须采取一些方法追踪指针指向的对象类型,这回带额外的开支
- 大部分情况,用不到动态联编
- 虚函数的工作原理
- 给每个对象添加一个隐藏成员,隐藏成员保存了指向函数地址数组的指针,这种数组被称为虚函数表
- 虚函数表中存储了为类对象进行声明的虚函数地址
- 对于派生类的虚函数,如果没有进行重写,则在派生类的虚函数表中存储基类虚函数的地址
- 如果对虚函数进行了重写,则在派生类的虚函数表中存储新的地址
- 虚函数被调用时,到对象的虚函数表中进行查找,选择正确的虚函数地址进行执行
有关虚函数的注意事项
- 构造函数:构造函数不能是虚函数。同析构函数不同,创建派生对象时,只会调用派生类的构造函数。基类的构造函数是我们人工加进去调用的。构造函数为虚没有什么意义
- 析构函数:如前文讨论,析构函数应该是虚的,除非类不作为基类
- 静态成员函数:不能为虚函数。因为静态成员在必须在编译时期确定并分配内存,不可能参与动态联编
- 友元:友元不能是虚函数,因为只有成员函数才能做虚函数
访问控制 protected
派生类能直接访问基类的protected成员,但不能访问private成员
剩下于private没有区别
慎用protected,虽然能够简化实现,但是没有把数据声明成private并提供能访问数据的公有接口来的安全
抽象基类(ABC)
包含至少一个纯虚函数的类成为抽象基类
- 纯虚函数是虚函数,其声明结尾为
=0;:例如virtual int func() const = 0; - 在类中可以不定义该函数
- 抽象基类不能创建对象
- 需要在派生类中实现虚函数
也就是抽象基类就是为了类设计的一种“残缺的”类,是为了解决一些纯类继承解决不了的问题,如下:
假设定义了一个椭圆类Ellipse和一个圆Circle,虽然我们说“圆 is a 椭圆”,在这里似乎能够使用类继承,但是这里尴尬的点是:
- 派生类继承了基类的所有成员
- 但是要确定一个椭圆,需要的参数(长轴,短轴,中心点,倾斜度),比确定一个圆(圆心,半径)要多很多
- 对于椭圆的操作(平移,旋转,伸缩),比圆的操作(平移,等比例扩大)要多
- 所以全部继承过来就很奇怪。。。
一个更好的方法是将其都有的部分搞成一个抽象基类,然后分别派生出圆和椭圆
class BaseEllipse{
private:
double x,y;
public:
BaseEllipse(double x0 = 0, double y0 = 0) :x(x0),y(y0) {}
virtual ~BaseEllipse() {}
void Move(int nx,int ny) {x = nx,y=ny;}
virtual double Area() const = 0;
};
class Circle: public BaseEllipse{
private:
double r;
public:
Circle(double x0 = 0, double y0 = 0, double r0 = 0) : BaseEllipse(x0,y0),r(r0) {}
virtual ~Circle(){}
void extend(double k){r *= k;}
virtual double Area() {return 3.14*r*r;}
};
class Ellipse :public BaseEllipse{
private:
double a,b;
double angle;
public:
Ellipse(double x0 = 0, double y0 = 0,double a0 = 0,double b0 = 0,double angle0 = 0):BaseEllipse(x0,y0),a(a0),b(b0),angle(angle0) {}
virtual ~Ellipse(){}
void extend(double ka,double kb){a *= ka;b *= kb;}
void spin(double delta){angle += delta;}
virtual double Area() {return 3.14*a*b;}
};
ABC理念
一种学院派的思想认为,只能将不会被用来当基类的类设计为具体的类,剩下的全搞成抽象类
事实上,ABC理念接近于一种“接口约定”
继承和动态内存分配
以下假设基类使用动态内存分配,并重新定义复制构造函数和赋值
派生类不使用new
由于对象嗝屁时会自动调用析构函数序列,所以没有析构函数是可以的
由于默认的复制构造函数和赋值运算符会按成员复制,而对于继承来的基类成员,则会自动调用基类的复制构造函数和赋值运算符,所以不定义也是可以的
派生类使用new
-
析构函数:各管各的就好,派生类的析构函数只需要清理派生出来的数据,基类的析构函数会被自动调用
-
复制构造函数:像构造函数一样,使用成员初始化列表
derived::derived(const derived & d) : base(d){\...},显式调用基类的复制构造函数,先给把基类的给复制了,再干自己的事 -
赋值运算符,也是需要显式调用基类的运算符
drived & derived::operator=(const derived &d){ if(this == &d) return *this; base::operator=(d);//真就嗯调用啊 //... return *this }
类函数小结
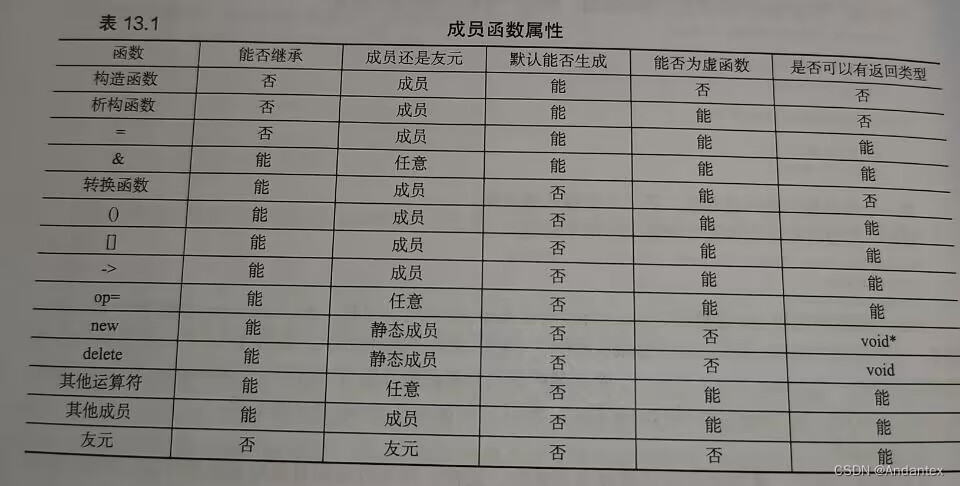
5 面向对象的代码重用
- Composition or Containment or Layering
- Class Template
包含对象成员的类
例子:一个包含了string类和valarray类的Student类
class Student {
private:
typedef valarray<int> Sc;//类作用域的类型重命名
string name;
Sc score;
public:
Student() : name("NULL"),score() {}
explicit Student(const string &s) : name(s),score() {}
explicit Student(const int n) : name("NULL"),score(n) {}
Student(const string &s,const Sc & scores) : name(s),score(scores) {}
~Student() {}
};
正如名字所示,这里解决的是 has-a 关系,用的方式就是将其他类的对象作为类的私有成员,在这么干时,需要注意以下几点
- 初始化被包含的对象
- 在继承的关系中,需要在初始化列表中使用基类的类名调用基类的构造函数;而在组合中,在初始化列表中使用对象名调用作为私有成员的类对象的构造函数
- 必须在构建其他成员之前,构建好所有成员对象,所以如果不在成员初始化列表中显式调用成员对象的构造函数,C++会在调用当前类的构造函数时自动调用成员对象的构造函数,先将成员对象创建好
- 初始化顺序:初始化会按照声明的顺序,而不是在初始化列表中调用的顺序。比如在例子中,不管按何方式写在初始化列表中,永远会先初始化
name对象,再初始化score对象
- 使用被包含对象的接口
- 被包含对象也是私有对象,其接口只能通过类方法或友元,先访问到该被包含的对象,再通过该对象调用其自身的接口
私有继承
还有一种实现 has-a 关系的途径:私有继承
将上面那个类进行少许更改,得到以下通过私有继承实现的Student
-
使用私有继承,基类的所有成员都将成为派生类的私有成员,这也意味着基类方法不会成为派生类的共有接口,但是仍然可以在派生类的成员函数中访问他们
-
包含将一个类的对象进行了命名,并添加到另一个类中。私有继承则将基类的对象作为一个未被命名的对象加入到派生类(派生类未显式的声明包含该对象)
- 用术语 子对象 来表示通过继承关系添加的对象
class Student : private string,private valarray<int>{
private:
typedef valarray<int> Sc;//类作用域的类型重命名
public:
Student() : string("NULL"),Sc() {}
explicit Student(const string &s) : string(s),Sc() {}
explicit Student(const int n) : string("NULL"),Sc(n) {}
Student(const string &s,const Sc & scores) : string(s),Sc(scores) {}
~Student() {}
};
-
初始化基类组件:与公有继承一样,在初始化序列中用类名来调用构造函数
-
访问基类方法:用类名和作用域解析符来调用基类方法,比如在
Student的某个方法中用string::size()来调用string子对象的方法 -
访问基类对象:这里有些取巧,方法是使用强制类型转换,如为了访问
Student类中的string子对象:const string & Student::Name() const { return (const string & ) *this }- 意思是 强行把调用该方法的对象转换成其基类的一个引用
- 逻辑是这样的:
- 转换成基类的引用后,通过该引用的操作都只是把当前对象当作一个
string来使 - 而这样进行的操作,真正被读取或者修改的地方都是当前对象包含的
string子对象 - 相当于说访问到了子对象
- 转换成基类的引用后,通过该引用的操作都只是把当前对象当作一个
-
访问基类的友元函数:由于友元函数不是成员函数,所以不能通过作用域解析调用到,方法还是一样的,需要调用友元函数时,将参数强制类型转换成基类。这个方法对于公有继承也有效,是因为
- 不进行强制类型转换,则有先匹配上当前类型的友元函数,容易发生无穷递归
- 多重继承的麻烦
使用包含还是私有继承
- 通常,应该使用包含来建立has-a关系,因为简单明了
- 除非是需要访问原有类的保护成员,或者需要重写虚函数,否则不应该使用私有继承
保护继承
用protected在基类前声明
-
儿子辈,保护继承和私有继承基本相同
特征 公有继承 保护继承 私有继承 公有成员 派生类的公有成员 派生类的保护成员 派生类的私有成员 保护成员 派生类的保护乘员 派生类的保护成员 派生类的私有成员 私有成员 只能通过基类接口访问 只能通过基类接口访问 只能通过基类接口访问 能否隐式向上转换 是 是(但只能在派生类中) 否 -
孙子辈,
- 私有继承的第三代不能使用基类的接口,这是因为该接口在第二代已经变成了私有方法
- 基类的公有方法在第二代中成为受保护的,所以第三代仍然能使用
使用using重新定义访问权限
使得基类方法在派生类外也可用(像派生类的共有方法一样)
- 在类声明的
public:中加入using valarray<int>::min;将使得valarray<int>类的min()方法像一个派生类的公有方法一样加入到Student类中。也就是对派生类完全开放其这个接口 - 注意只用写成员名称,不用加圆括号。被重载的运算符也同理:
using valarray<int>::operator[];
多重继承(MI)
许多人痛恨多重继承,实际上Java就没有这个特性
在接下来的讨论中,主要讨论下面这个例子:
具体来说,在SingingWaiter类中会有两个问题:
- 这个类里装了几个
Worker - 哪个方法
有多少基类成员
假设class SingingWaiter : public Singer,public Waiter {\...}
则SingingWaiter包含一个Singer组件和一个Waiter组件,由于这两个类都由Worker派生来,则其都包含了Worker组件,进而SingingWaiter包含有两个Worker
这十分有问题:
- 应用基类指针引用
SingingWaiter时,必须显式的指明引用了何组件中的基类组件:Worker *p = (Singer *) &singingwaiter - 数据成员的冗余,不符合我们设计类的初衷
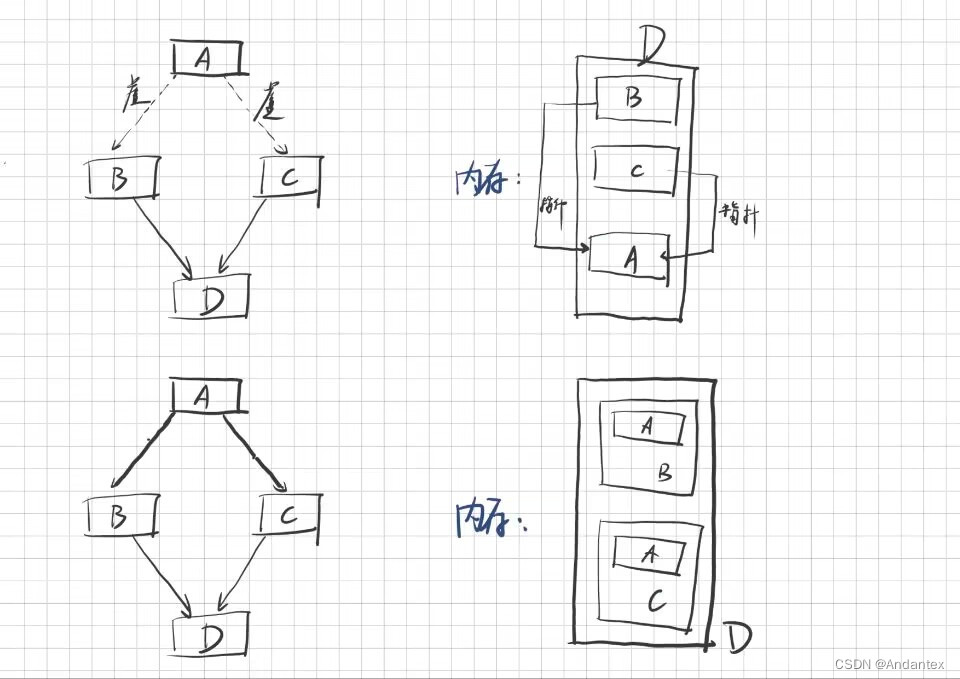
需要新特性引入:虚基类
虚基类
这部分讲的模模糊糊,且和我自己的实验有所冲突。。。。
在类声明中使用virtual,使得基类成为虚基类
class Singer:virtual public Worker {\...}
class Singer:virtual public Singer{\...}
class SingingWaiter : public Singer,public Waiter {\...}
原理是,现在所有在声明中以virtual模式继承Worker的派生类,在派生出新类时,在三代类中都共享一个虚基类组件,而不是各自引入自己的基类组件
大概的原理我搜了一下,如下图所示:
新的构造函数规则
在一般的继承关系中,由于我们硬规定初始化新增成员前,必须先初始化基类组件。所以当前类的构造需要且仅需要调用上一级的构造函数,构造函数通过这种“类似递归”的方式,层层向上,直到把最基本的基类组件初始化
如下图的class C所示
class A{
int a;
public:
A(int aa):a(aa){}
};
class B:public A{
int b;
public:
B(int aa,int bb):A(aa),b(bb){}
};
class C:public B{
int c;
public:
C(int aa,int bb,int cc):B(aa,bb),c(cc){}
};
对于虚继承,这样做会出现问题。这是因为我们现在只有一个虚基类组件了,所以对于虚基类,必须在三代及以上的派生类中显式的调用虚基类的构造函数
就像下面的class D
class A{
int a;
public:
A(int aa):a(aa){}
};
class B:virtual public A{
int b;
public:
B(int aa,int bb):A(aa),b(bb){}
};
class C:virtual public A{
int c;
public:
C(int aa,int cc):A(aa),c(cc){}
};
class D:public B,public C{
int d;
public:
D(int aa,int bb,int cc,int dd) : A(aa),B(aa,bb),C(aa,cc),d(dd) {}
};
哪个方法
正常的继承关系中,可以通过链式的调用不断为某个方法附加内容,如下所示的show(),不断在基类的内容上打印新内容:
class A{
int a;
public:
A(int aa):a(aa){}
void show(){cout << "a" << endl;}
};
class B: public A{
int b;
public:
B(int aa,int bb):A(aa),b(bb){}
void show(){A::show();cout << "b" << endl;}
};
class C: public A{
int c;
public:
C(int aa,int cc):A(aa),c(cc){}
void show(){A::show();cout << "c" << endl;}
};
对于菱形继承来说,这样有些不太好使。这是因为如果我们继续采用相同的方式,则基类的信息会被打印两遍。
一个好方法拆解成更多模块,进行组合,而不是一味的链式下去,如下面的A\B\C\D类
class A{
int a;
public:
A(int aa):a(aa){}
void showA(){cout << "a" << endl;}
virtual void show(){showA();}
};
class B:virtual public A{
int b;
public:
B(int aa,int bb):A(aa),b(bb){}
void showB(){cout << "b" << endl;}
virtual void show(){showA();showB();}
};
class C:virtual public A{
int c;
public:
C(int aa,int cc):A(aa),c(cc){}
void showC(){cout << "c" << endl;}
virtual void show(){showA();showC();}
};
class D:public B,public C{
int d;
public:
D(int aa,int bb,int cc,int dd) : A(aa),B(aa,bb),C(aa,cc),d(dd) {}
void showD(){cout << "d" << endl;}
virtual void show(){showA();showB();showC();showD();}
};
其他问题
混合使用虚基类和非虚基类
如下图所示:
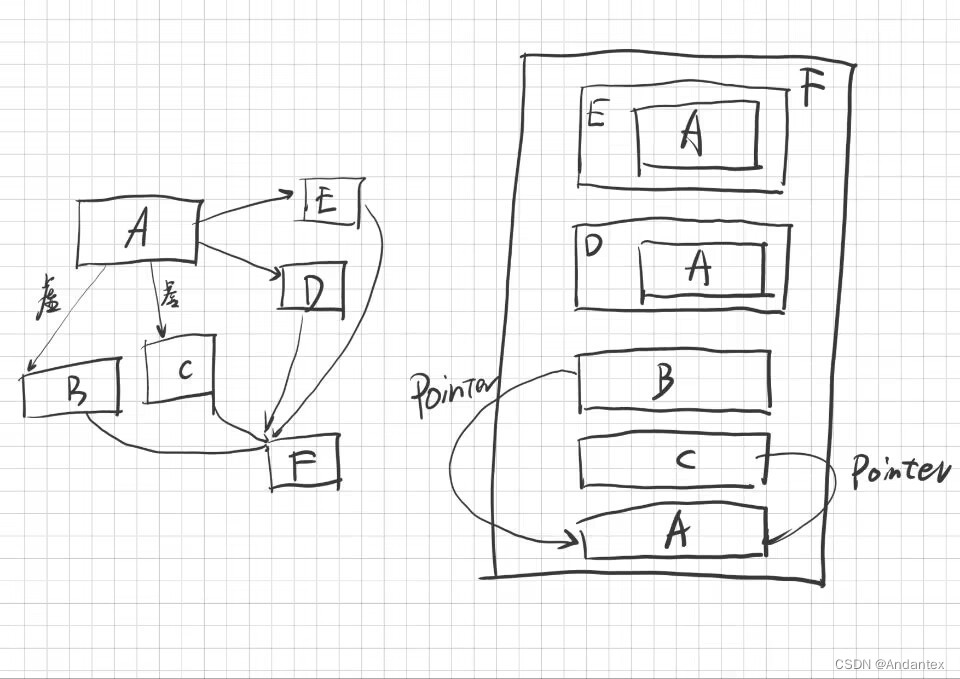
虚基类与优先级
这块真是翻译了个几把
- 使用虚基类时,如果某个名称优先于所有名称,则可以不加限定符地调用
- 谁在派生链上出生最晚,谁最优先
如下图所示:
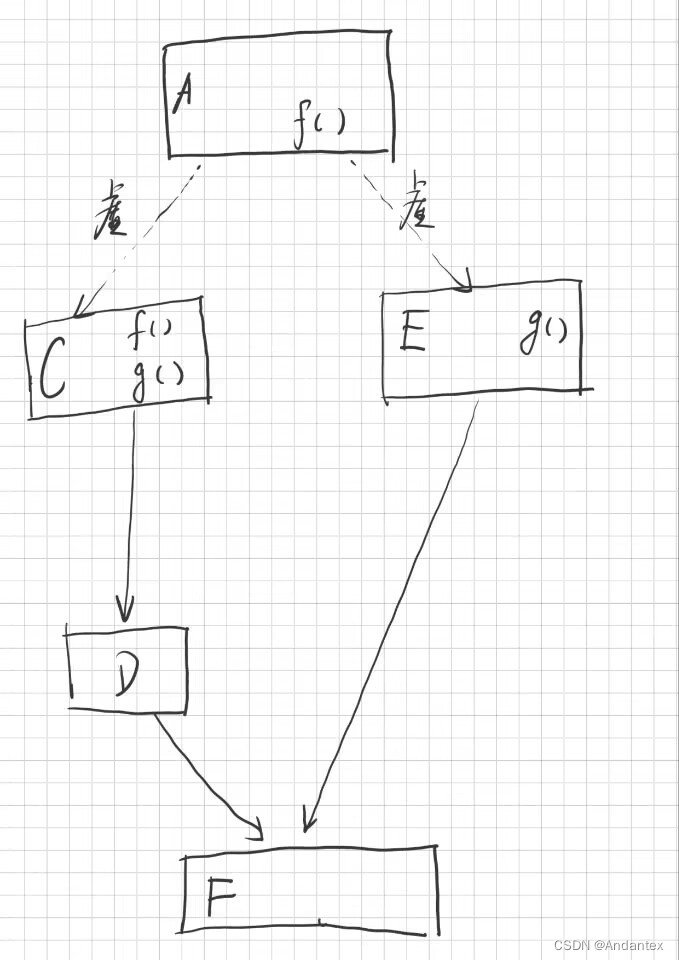
在F类中,
-
可以不加限定符的使用
f(),因为C类中的f()是优先级最高的 -
不加限定符的使用
g()则会产生二义性,因为并没有一个g()比其他所有都优先
初始化列表总结
const成员和引用成员必须在初始化列表中初始化- 因为这两者必须一声明就初始化
- 各种继承来的,必须在初始化列表调用基类构造函数
- 注意虚基类的特殊情况
- 组合来的,必须在初始化列表调用构造函数
- 否则将调用组合的默认构造函数
类模板
泛型
定义类模板
- 首先在类声明前加入模板前缀
template<class Type,...> - 在方法函数的实现前也加入模板前缀
template<class Type,...> - “模板”不是类或函数的定义,真正成为定义还需要进行所谓的“实例化”
- 把所有模板信息放在同一文件中,不要拆开
在下面给出一个栈的类模板
template <class T>
class Stack{
enum {SIZE=10};
int size;
T *items;
int top;
public:
explicit Stack(int ss = SIZE);
Stack(const Stack &st);
~Stack(){delete[] items;}
bool is_empty(){return top == 0;}
bool is_full(){return top == size;}
bool push(const T &item);
bool pop(T &item);
Stack & operator=(const Stack &st);
};
template <class T>
Stack<T>::Stack(int ss):size(ss),top(0) {
items = new T[size];
}
template <class T>
Stack<T>::Stack(Stack const &st){
size = st.size;
top = st.pop();
items = new T[size];
for(int i = 0;i < top;i++){
items[i] = st.items[i];
}
}
template <class T>
bool Stack<T>::push(const T & item){
if(top >= size) return false;
items[top++] = item;
return true;
}
template <class T>
bool Stack<T>::pop(T & item){
if(top <= 0) return false;
item = items[--top];
return true;
}
template <class T>
Stack<T> & Stack<T>::operator=(const Stack<T> &st){
if(this == &st) return *this;
delete[] items;
size = st.size;
top = st.pop();
items = new T[size];
for(int i = 0;i < top;i++){
items[i] = st.items[i];
}
}
模板的非类型参数
一个简单的数组模板,其中使用了非类型参数template <class T,int n>
template <class T,int n>
class ArrayTP{
private:
T itmes[n];
public:
//...
};
- 有点类似于宏替换,当请求实例化
Array<string,12>时,会使用string类型代替所有T标识的类型,用常量12代替所有出现变量n的地方 - 能用做非类型参数的只有 整型、枚举、指针、引用
- 与在构造函数中使用动态内存分配来维护变长数组相比,这种方法的好处是执行更迅速
- 缺点是会生成过多的类声明实例化
模板多功能性
-
递归使用模板:模板之间可以嵌套,比如上个例子的
ArrayTP< ArrayTP<int,10>,5>,就创建了一个类似于int[5][10]的二维数组 -
使用多个类型参数,比如在
pair<int,double>这样的类模板中,使用了类似template<class T1,class T2> -
默认类型模板参数:向模板提供默认值,比如
template<class T,class P = int> class Pair{...};,在进行实例化请求时就可以Pair<double> p,来创建一个<double,int>的类型
模板类的具体化
-
隐式实例化:在创建一个对象时自动隐式地生成类声明。在编译器需要对象之前,并不会为类模板隐式实例化
vector<int> *p;只是声明指针,不需要创建对象,不进行实例化p = new vector<int>;,需要创建对象了,自动为类模板生成实例化的类定义
-
显式实例化:用关键词
template指出。例如template class ArrayTP<int,100>; -
显式具体化:
template <> class Classname<某个指明的类型参数列表> {...}- 用于给某个实例化显式地指定实现,比如在
Stack中,想要重载operator<<,别的类型都挺好,但是对于Stack<string>,我非得在重载中加点别的内容,比如在输出每一个元素后输出“我是傻逼!"。那就必须给Stack<string>指出一个显式的定义,不能让它自动的通过模板生成了 - 这就用到了
template<> class Stack<string> {...}
- 用于给某个实例化显式地指定实现,比如在
-
部分具体化:显式具体化其实是部分具体化的特殊情况,用
template<尚未具体化的参数>替换显式具体化中的声明- 比如我
ArrayTP遇到了上面一样的问题,但我还不想过早指定n取什么 - 使用
template<int n> class Array<string,int n>{...}
- 比如我
-
以上又是引起了模板实例化的选择问题
- 多个模板可供选择,选择具体化程度最高的模板
- 相同具体化程度,选择提供指针的具体化版本(用指针当模板参数实际上是一种特殊的部分具体化)
template<class T*>
成员模板
模板类的组合,以下例子中一个模板类使用另一个模板类和模板函数作为成员
狠狠地模板嵌套
template <class T>
class beta{
private:
template <class V>
class hold{
private:
V val;
public:
hold(V v = 0):val(v) {};
void show() const {cout << val << endl;}
V value() const {return val;}
};
hold<T> q;
hold<int> n;
public:
beta(T t,int i) : q(t),n(i) {};
template <class U> U blab (U u,T t) {return n.value()+q.value()+u/t;}
void show(){q.show();n.show();}
};
- 注意
hold模板是在私有部分声明的,所以只有在beta类中才能访问到该模板,类外无法访问
另一种方法是在类中对hold和blab两个模板成员声明,到类外进行定义:
template <class T>
class beta{
private:
template <class V> class hold;
hold<T> q;
hold<int> n;
public:
beta(T t,int i) : q(t),n(i) {};
template <class U> U blab (U u,T t);
void show(){q.show();n.show();}
};
template <class T>
template <class V>
class beta<T>::hold
{
private:
V val;
public:
hold(V v = 0):val(v) {};
void show() const {cout << val << endl;}
V value() const {return val;}
};
template <class T>
template <class U>
U beta<T>::blab (U u,T t)
{return n.value()+q.value()+u/t;}
注意在类外定义时用到的嵌套级的模板:
template <class T>
template <class V>
class beta<T>::hold
template <class T>
template <class U>
U beta<T>::blab (U u,T t)
将模板用作参数
还是嵌套!!!这次我们将模板类作为类型参数传给模板,像这样:template<template<class T> class P> DStack;
- 结构:
template<class T>class是参数类型,意思是“一个模板类”,P是类型参数名 - 这意味着,如果我写
DStack<Stack>,则Stack的声明必须类似于template<class T> class Stack{}
模板参数和其他参数也可以混用,为了完整演示,下面给出一个类DoubleStack,它只是同步地操作两个栈
template <template<class T>class S,class P,class R>
class DoubleStack{
S<P> x;
S<R> y;
public:
bool push(P a,R b) {return x.push(a) && y.push(b);}
bool pop(P a,R b) {return x.pop(a) && y.pop(b);}
};
DoubleStack<Stack,int,double> doublestack;
模板类和友元
-
模板类的非模板友元函数
-
需要对每个版本进行显式的具体化
-
意思是对于
template<class T> class A{public:friend void F(A<T> a);};这样的友元,由于每次实例化时,都会对上面的声明具体化一次,所以每次实例化时,都是在重载这个友元函数
比如我分别实例了一次A<int>和A<ouble>,则必须提供相应的友元void F(A<int> a){...} void F(A<double> a){...}
-
-
模板类的约束模板友元函数
-
首先在类定义之前声明每个模板友元函数
template<class T> void F(T t); -
在类中再次声明以上函数,并应提供一个根据类的具体化版本
template<class P> class A{ public: friend void F< A<P> > (A<P> t); }; -
完成函数的定义
template<class T> void F(T t){ cout << sizeof(t) << endl; };
-
-
模板类的非约束模板友元函数
-
在类的内部将友元搞成模板
template<class P> class A{ public: template<class T> friend void F (T t); }; -
这样在传给函数
F()这个类的参数时,进行模板的实例化
-
模板别名
使用using:
- 为某个模板指定别名
template<class T> using arrtype = std::array<T,12>;,这样任何时候使用arrtype<T>就相当于std::array<T,12> - 甚至直接代替
typedef:uisng ULL = unsigned long long int;
6 友元、嵌套类、异常、RTTI、类型转换
感觉这章全是恶心人的
友元
- 可以将类作为友元,这时友元类的所有方法都能访问原始类的私有成员和保护成员
- 也可以只将特定的成员函数作为友元
友元类
友元可以比较方便的表示需要频繁的传递消息的类,比如在接下来的例子中,是电视和遥控器类:我们希望电视机不能自己调台,只能通过遥控器挑;一个遥控器可以调多个电视机
class TV{
private:
int channel;
//...
public:
//...
friend class Remote;
}
class Remote{
private:
//...
public:
//...
void change(TV &tv,int channel);
}
void Remote::change(TV &tv,int channel){
tv.channel = channel;
}
与友元函数的做法没什么不同,那么能否使用别的手段来达到相同的效果呢?
- 将
channel暴露为public?显然不符合我们隐藏实现,提供接口的宗旨 - 创建一个更大的类,包含电视机和遥控器?实现太过复杂
友元成员函数
即将某个成员函数设为友元,这里需要调整声明的顺序,并采取一种称为“前向声明”的方法
class TV; //前向声明,也只是声明TV标识符标识了一个类,但并没有定义
class Remote{
private:
//...
public:
//...
void change(TV &tv,int channel);
}
class TV{
private:
int channel;
//...
public:
//...
friend class void change(TV &tv,int channel);
}
void Remote::change(TV &tv,int channel){
tv.channel = channel;
}
嵌套类
-
将类声明放在另一个类里面
-
类嵌套与类包含的区别在于,嵌套类声明只是定义了一种只有在被嵌套类中才有效的类型,而不是直接在类中创建对象成员
-
将类进行嵌套通常是为了更好的实现类
比如在下面的例子中,为了定义一个通过链表实现的队列类,在队列类的声明中嵌套节点类的声明
class Queue{
private:
class Node{
Item item;
Node *next;
Node(const Item &i) item(i),next(0) {}
};
//...
public:
bool enqueue(const Item &i);
//...
};
bool Queue::enqueue(const Item &i){
if(isfull()) return false;
Node *add = new Node(i);
//...
}
嵌套类和访问权限
| 嵌套类的声明位置 | 被嵌套的类是否可以使用它 | 从被嵌套类派生的类是否能使用 | 在外部是否可使用 |
|---|---|---|---|
| 私有 | 是 | 否 | 否 |
| 保护 | 是 | 是 | 否 |
| 共有 | 是 | 是 | 是,需要通过类限定符:: |
模板类的嵌套
该咋用还是咋用,模板类又尤其适用于Queue这样的容器类
template <class Item>
class Queue{
private:
class Node{
Item item;
Node *next;
Node(const Item &i):item(i),next(nullptr) {}
};
//...
public:
bool enqueue(const Item &i);
//...
};
template<class T>
bool Queue::enqueue(const Item &i){
if(isfull()) return false;
Node *add = new Node(i);
//...
}
异常
(这块春春的在Java课上听过一遍)
传统的实现异常处理的方法:
- 使用
abort()或者exit()直接退出程序 - 用函数的返回值提醒,比如用
EOF标识到达文件尾
异常机制
下边以“不小心除以了0为例”
double divide(double a,double b);
int main(){
double a,b,c;
while(cin >> a >> b){
try {
c = divide(a,b);
}
catch(const char *s){
cout << s <<endl;
cout << "Enter" << endl;
continue;
}
}
cout << a << "divided by" << b <<"equals" << c << endl;
}
double divide(double a,double b){
if(b == 0){
throw "divided by zero!!";
}
return a/b;
}
try后跟的代码块是可能引发异常的代码块- 异常通过
throw抛出,抛出的可以是任何C++的类型,但是一般会选择抛出一个类对象 try后需要跟至少一个catch块,用于捕捉try块中发送的异常并进行处理catch块类似函数定义的语法,如上述的例子中,catch(const char *s){...},后面括号里的东西类似参数列表- 抛出的异常将与匹配的
catch块匹配,并将值赋给括号中的参数 - 如果没有接受到任何异常,则跳过
catch块
将对象用作异常类型
- 一方面是因为类对象是用户自定义类型,方便进行区别
- 一方面是对象能携带的信息更多
例如将上面的稍作修改
class Divide0{
double a,b;
public:
Divide0(double aa,double bb):a(aa),b(bb) {}
void show(){cout << "tring to divide" << a << "by zero" ; }
};
double divide(double a,double b);
int main(){
double a,b,c;
while(cin >> a >> b){
try {
c = divide(a,b);
}
catch(const Divide0 &exc){
exc.show();
continue;
}
}
cout << a << "divided by" << b <<"equals" << c << endl;
}
double divide(double a,double b){
if(b == 0){
throw Divide0(a,b);
}
return a/b;
}
注意到,像return一个类对象一样,将对象作为异常throw出去,一般会创建一个临时拷贝,还有一种语法是下面这样:
double divide(double a,double b) throw (Divide0){
if(b == 0){
Divide0 exception(a,b);
throw exception;
}
return a/b;
}
(不过编译器会报警告[警告] dynamic exception specifications are deprecated in C++11 [-Wdeprecated])
栈解退
首先是关于throw和return在函数嵌套调用中的区别
- return是在栈中逐层退出
throw一旦触发,直接回到try所在的位置,并将栈内的所有东西都弹出- 意思是所有因调用创建的栈中的临时变量都弹出,有析构函数的自然调用析构函数
其他异常特性
-
选取类作为异常抛出还有一个好处就是:
catch后一直写接受类的引用,这样就可以利用自动向上转换,只要catch一个基类的引用,就可以捕获所有的派生类的异常- 这时候可能需要对多个
catch块的顺序进行合理的排列,使得捕获到正确的异常
- 这时候可能需要对多个
-
可以通过写
catch(...){//statement},即在括号里写省略号,捕获任意的异常
exception类
-
可以通过
#include <exception>来使用exception类,该类是所有异常类的共有基类-
通常是从
exception中进行派生,并重写what()虚方法#include <exception> using std::exception class MyException:public exception { public: const char * what() {return "My Exception."} }
-
-
通过头文件
<stdexcept>使用stdexcept类,这里就不列举了,现用现查 -
使用头文件
<new>来引入bad_alloc异常,当使用new分配内存失败时,将返回这个异常- 也可以保持让失败的内存分配返回空指针的老传统,像这样:
int *p = new (std::nothrow) int;
- 也可以保持让失败的内存分配返回空指针的老传统,像这样:
类,异常
这里大概就是说把异常当作一种类,这样可以和类进行类与类那样的操作,来达到许多骚目的
比如通过嵌套异常类搞一个能报告下标越界的数组
#include <iostream>
#include <stdexcept>
#include <string>
using namespace std;
template <class T>
class Array{
int size;
T *doc;
public:
class bad_index:public logic_error{
int i;
public:
explicit bad_index(int is,const string & st = "bad index!\n"):logic_error(st),i(is) {}
};
Array(int s):size(s) {doc = new T[size];}
T & operator[](int i);
~Array(){delete[] doc;}
};
template <class T> T & Array<T>::operator[](int i){
if(i < 0 || i > size) throw bad_index(i);
return doc[i];
}
后面的东西纯恶心人,以后想整理了再说
看的我真是太生气了,简直就是被人喂了一斤屎
RTTI (运行阶段类型识别)
RTTI的用途
在类层次结构中,总是可以将派生类的对象赋给基类的指针或者引用,对于虚函数来说,似乎并不需要直到某个引用或者指针指向的指针类型,但是遇到下面的情形:
- 只有某些对象能使用的方法
- 出于调试的目的,试图跟踪生成对象的类型
需要知道指针指向了什么类型
这就需要RTTI
RTTI工作原理
三个支持RTTI的元素:
dynamic_cast运算符总是尝试使用一个基类的指针生成一个指向派生类的指针,否则返回空指针typeid运算符返回一个指出对象的类型的值type_info结构存储了有关特定类型的信息
只能将RTTI用于包含虚函数的层次类系统
-
dynamic_cast运算符- 回答“是否能安全的将对象的地址赋给特定类型的指针”
- 其中“不安全”指,试图将基类的对象赋给派生类指针
- 安全,则返回地址;不安全,返回空指针
- 语法:
Superb *pm = dynamic_cast<Superbu *> (pg)
- 对于引用来说:
Superb &rs = dynamic_cast<Superbu &> (rg)- 请求不正确时,抛出
bad_cast异常对象,在头文件<typeinfo>中定义的
- 回答“是否能安全的将对象的地址赋给特定类型的指针”
-
type_info类- 该类也位于
<typeinfo> - 重载了
operator==和operator!=,可以用来进行比对 - 包含一个
name()成员,其实现因厂商而异,通常返回类的名称
- 该类也位于
-
typeid运算符- 接受类名或者结果为对象的表达式为操作数
- 返回一个
type_info对象的引用,包含了被作用的操作数的类型的信息- 比如
typeid(a) == typeid(b)比较类型 typeid(a).name()返回类名
- 比如
- 接受空对象时,返回
bad_typeid异常
很多人觉得RTTI是大傻逼,书中给出了一个你不该瞎用RTTI的例子:如果你尝试在if-else中使用typeid判断类型,你是大傻逼
类型转换运算符
更加严格的类型转换限制
-
dynamic_cast<>():只能“向上转换” -
const_cast<>():只能增添或删除const,即不允许类型变化,只能在cosnt和非const转换 -
static_cast<typename>(P):只有typename的类型和P的类型能够进行隐式转换时,才允许转化 -
reinterpret_cast<>():除了:- 删除
const - 将函数指针转换成数据指针
- 将指针转换到不能储存其值的小整形或者浮点型
外的基本上所有强制转换,就是用于干危险的转换。比如下面的例子:查看长整型的前两个字节
struct dat{short a;short b;} long v = 0xA224B118 dat *p = reinterpret_cast<dat *>(&v); cout << p->a; - 删除
7 智能指针和泛型
对于太细节的东西,统统没记
智能指针
如果你在用new和delete管理内存,你总是要记得把分配的指针释放掉。这可太急眼了,智能指针就是用来干这个事情的。总的来说,只能指针是一种类对象,将在指针过期时自动调用析构函数释放指针的内存
该类定义在头文件<memory>,基本上类定义都如下所示:
template <class T>
class auto_ptr{
public:
explicit auto_ptr(T *p = 0) throw();
}
接受一个类型的指针作为参数的构造函数
常用的有三种:
-
auto_ptr和unique_ptr:建立“所有权”概念,保证对于特定的对象,只有一个智能指针可以拥有他auto_ptr的策略相对简单:当有赋值的行为出现时,将旧指针的所有权转交给新指针,同时将旧指针制空unique_ptr:更加严格的限制,在将一个unique_ptr赋值给另一个时:- 如果旧的指针并不会立即过期,则该赋值行为被编译器禁止
- 如果该指针是临时右值,即在执行完赋值后会被马上销毁(比如函数返回一个
unique_ptr指针),则会执行所有权转让 - 使用
move()将一个unique_ptr安全的赋值给另一个p1 = move(p2)
-
shared_ptr:跟踪特定对象的指针数,即“引用计数”。当且仅当最后一个指针过期时,调用delete -
注意,只有
unique_ptr能接受[]型的指针,即unique_ptr<int []> p(new int[10]) -
可以将一个
unique_ptr赋值给shared_ptr
泛型编程
STL提供了一套表示
- 容器:储存同质数据的单元
- 迭代器:用于遍历容器的对象,可以视为是广义指针
- 函数对象
- 算法
的模板
泛型编程的思想不同于面向对象,但是重点仍是抽象和复用代码
泛型编程的总之在于编写独立于数据类型的代码
迭代器简介
为什么要使用迭代器?书中给出了一个例子:实现一个对所有容器都使用的find()函数,这需要我们从头将整个容器遍历一遍,并挨个比较值。为什么不用下标索引或者指针呢?因为容器的实现不同,有是顺序储存的,有链式储存的等等等等。一般来说,需要一个迭代器能干下面这些事
- 能够解引用,即应该定义
operator*,效果是获得其指向的内容 - 能够进行赋值,用于更新或初始化,即需要定义
operator= - 能够进行比较,即定义
operator==和operator!= - 应该能进行迭代,遍历所有元素,一般是同定义
operator++(前缀+后缀)
相应的,为了配合迭代器的工作,STL也做出了一些约定
- 对于每个容器类,都将定义其相应的迭代器类型
- 每个容器类都有超尾标记,当迭代器迭代到最后一个值之后,再迭代一次,该值将赋给迭代器
- 每个容器类都有
begin()和end()方法,分别返回指向第一个元素的迭代器和指向超尾标记的迭代器 - 每个容器都能使用
++来自增迭代器,使得迭代器从指向第一个元素迭代到超微标记,并遍历所有元素
迭代器类型
对于所有迭代器:
- 可以通过
*解引用 - 可以通过
==和!=进行比较 - 支持
++从头遍历到尾
有五种迭代器:
- 输入迭代器:
- 只读:只能通过解引用查看数据,不能修改
- 单通
- 可以遍历全体成员,但不能保证每次遍历的顺序都一样
- 可以通过
++递增,但是迭代器的历史值不一定能被解引用。
- 只能递增
- 输出迭代器:
- 只写:解引用只能被用作修改数据,不能查看数据
- 单通
- 递减
- 正向迭代器:
- 递增
- 总是按照相同的顺序遍历值
- 迭代器的历史值可以被保存下来用于解引用,且一个历史值解引用只会得到相同的数据
- 可读可写
- 双向迭代器
- 正向迭代器的所有功能加上可以用
--倒回去
- 正向迭代器的所有功能加上可以用
- 随机访问迭代器:
- 支持你能想到的对一个数组指针的所有操作,比如下标访问,比如和任意整数做加减,比如比较大小(用上
>和<) - 直接当数组用
- 支持你能想到的对一个数组指针的所有操作,比如下标访问,比如和任意整数做加减,比如比较大小(用上
迭代器的层次结构:
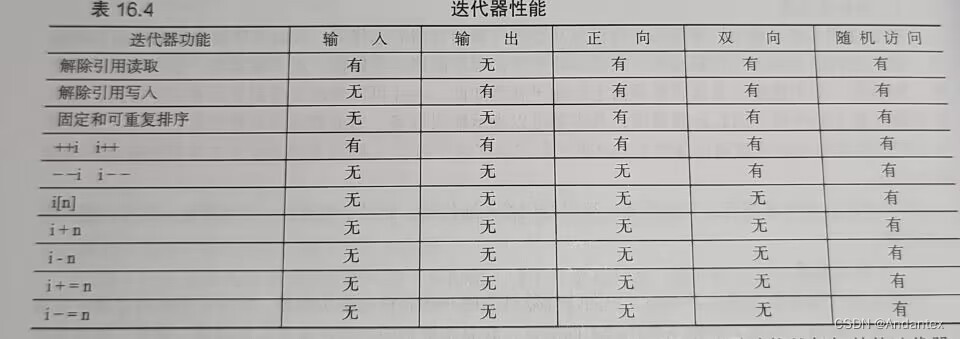
容器种类
deque,list,queue,priority_queue,stack,vector,map,multymap,set,multiset
forward_list,unordered_map,unordered_multimap,unordered_set,unordered_multiset
要求容器储存的类型必须是可复制构造和可赋值的

序列
序列,包括deque,list,queue,priority_queue,stack,vector,forward_list
即线性表

关联容器
(键,值)对,允许插入和删除值,不许指定位置,快速查询值
有序关联:map,multymap,set,multiset,通过树实现
- set,键和值相同
- map,键是唯一的
无序关联:unordered_map,unordered_multimap,unordered_set,unordered_multiset,通过哈希表实现
函数对象
即functor,代表可以以函数方式与()结合使用的任意东西,也称为函数符
包括函数名,指向函数的指针,重载了operator()的类对象(这使得函数能有私有数据成员),还有新标准中的Lambda表达式
为了使用“函数对象”这种东西作为参数,需要引入模板。比如下面这个函数
template<class InputIterator,class Functor>
void each(InputIterator begin,InpputIterator end,Functor f){
for(InputIterator i = bgein;i != end;i++){
(*i) = f(*i);
}
}
中的函数符概念
函数符作以下分类
- 生成器(generator):不使用参数可以调用
- 一元函数(unary_function):一个参数可以调用
- 一元函数(binary_function):二个参数可以调用
- 谓词(predicate):返回bool的一元函数
- 二元谓词(binary_predicate):返回bool的二元函数
重载operator()的“仿函数”有什么用
给出一个例子说明:
不同的STL函数对于参数的要求不同,这里以list中的remove_if成员,该函数将将谓词作用于每个成员,如果返回true,则删除元素。
如果我想在函数中频繁的使用这个成员,对于每一个要求,我都需要定义相关的函数对象。
但是有些要求是很相似的,比如“大于200”和“大于500”这两个要求没什么不同,但是由于成员函数只接受 谓词 作为参数,所以对于一般的函数而言,必须不断的定义新的函数来满足要求
使用仿函数可以做到代码重用:
template<class T>
class TooBig{
private:
T cutoff;
public:
TooBig(const T &t) : cutoff(t) {}
bool opeartor()(const T &v) {return v>cutoff}
};
传参的时候直接这么传MyList.remove_if(MyList.begin(),MyList.end(),TooBig<double>(200))
有点像一个函数工厂
预定义的函数符
STL预定义好了很多函数符,大部分放在<functional>里面,都是带模板的。

自适应函数符和函数适配器
这块写的真是一坨,我不如死了得了
买C++ primer plus真是买错了,真是烂这书

看不懂,贴个源码先
template<class _Arg1,
class _Arg2,
class _Result>
struct binary_function
{ // base class for binary functions
typedef _Arg1 first_argument_type;
typedef _Arg2 second_argument_type;
typedef _Result result_type;
};
template<class _Ty>
struct plus
: public binary_function<_Ty, _Ty, _Ty>
{ // functor for operator+
_Ty operator()(const _Ty& _Left, const _Ty& _Right) const
{ // apply operator+ to operands
return (_Left + _Right);
}
};
template<class _Fn2,
class _Ty> inline
binder1st<_Fn2> bind1st(const _Fn2& _Func, const _Ty& _Left)
{ // return a binder1st functor adapter
typename _Fn2::first_argument_type _Val(_Left);
return (_STD binder1st<_Fn2>(_Func, _Val));
}
8 C++11新特性
移动语义和右值引用
为何要使用移动语义
为了避免频繁的创建和删除对象。比如我有一个函数f(),返回一个vector<string>的对象temp,接着用复制构造创建一个新对象vector<string> a(f()),这时整个过程是:
- 首先为函数返回的东西创建一个临时对象
- 调用复制构造函数进行深拷贝
- 删除临时对象
这时候我们说,啊?这是否有点。。。你既然搞了个临时对象出来,就是为了复制然后删掉。那不如直接转让数据的所有权,直接把临时对象的数据转交给a这个名字得了
右值和右值引用
右值就是“不能寻址的”值,包括字面常量(1,3.14,'a'),表达式(a+b),返回值的函数
右值引用的语法是int && r = x+y,注意r关联到的就是“值”,比如在初始化时x+y的值是33,那么r关联到的就是33,就算后面x,y的值发生改变了,r关联到的值也不变
移动语义的例子
#include <iostream>
#include <cstring>
using namespace std;
class Words{
int size;
char *c;
public:
Words(int s = 0):size(s) {c = new char[s];}
Words(const char *s);
Words(const Words &w);
Words(Words && ww);
Words operator+(const Words &w);
~Words(){delete[] c;}
friend ostream & operator<<(ostream &os,const Words &w);
};
Words::Words(const char *s){
size = strlen(s)+1;
c = new char[size];
strcpy(c,s);
}
Words::Words(const Words &w){
cout << "normal copy constructor" << endl;
size = w.size;
c = new char[size];
strcpy(c,w.c);
}
Words::Words(Words && ww){
cout << "move semantics" << endl;
size = ww.size;
c = ww.c;
ww.c = nullptr;
ww.size = 0;
}
Words Words::operator+(const Words &w){
Words temp(size+w.size);
strcpy(temp.c,c);
strcat(temp.c,w.c);
return temp;
}
ostream & operator<<(ostream &os,const Words &w){
os << w.c << endl;
return os;
}
int main(){
Words a("hello "),b("world.");
Words c = a+b;
cout << c;
}
就像是执行浅复制一样
- 首先把地址偷过来
c=ww.c - 为了不让一个地址被delete两次,直接将原来的地址置空
ww.c = nullptr
这样在执行Words c = a+b时,由于a+b是一个右值,则会调用移动复制构造函数
移动赋值
移动赋值也是一样的
Words & Words::operator=(Words && w){
if(this == &w) return *this;
delete[] c;
c = w,c;
size = w.size;
w.c = nullptr;
w.size = 0;
}
强制使用移动语义
移动语义一般情况下只对右值起作用,但是我偏想对左值移动怎么办?
- 强制类型转换
static_cast<Words &&> - 使用头文件
<utility>中的函数std::move(),如Words d = std::move(c)
新的类功能
默认方法和禁用方法
- 默认方法:通过使用
=default;来声明默认的方法- 比如你一旦定义了构造函数,默认的构造函数就不会提供了,使用
Words()=default;将默认提供的构造函数声明出来
- 比如你一旦定义了构造函数,默认的构造函数就不会提供了,使用
- 禁用方法,用
=delete;来声明- 比如,不允许类进行任何形式的赋值,可以
Words operator=(const Words &) = delete;
- 比如,不允许类进行任何形式的赋值,可以
委托构造函数
就是在构造函数中用其他的构造函数来简化实现,在JAVA里是经典操作了
在JAVA课上讲的是,先创建一个保罗万象的构造函数,把能干的都干了,然后其他构造函数通过调用该函数来实现特定的初始化
委托的构造函数在初始化列表里调用。
一个不算正确的示例:
class X{
int x;
double y;
char z;
public:
X(int xx,double yy,char zz):x(xx),y(yy),z(zz) {}
X(int xx):X(xx,3.14,'a') {}
};
管理虚方法override和final
我现在有一个基类Base和一个派生类Dertived,虚方法virtual vod f()
- 将
overide放在最后表示重写某虚方法,如果你不是在重写,编译器报错。- 在
Derived类中,这么声明:virtual void f() override
- 在
- 将
final放在最后表示该虚函数不许再在派生类中被重写了- 在
Base类中,这么声明:virtual void f() final
- 在
Lambda函数
匿名函数,同属于functor大家族 ,结构式[捕获变量](参数列表)->返回类型{函数体}
- 捕获变量:可以捕获当前作用域内的任何自动变量,并用于函数体中
- 将变量名放进去进行按值捕获如
[z,a],或者捕获为引用[&z] [=]按值捕获所有当前作用域内变量,[&]作为引用捕获所有- 可以各种混用,比如
[&a,b],甚至[=,&a],后者意思是按值捕获所有变量,但是把a捕获为引用
- 将变量名放进去进行按值捕获如
- 参数列表:与正常函数完全一样
- 返回类型:可选项,如果函数体中
return了单一值就可以不写。这是一种返回类型后置的手法 - 函数体:与正常函数完全一样
- 可以为Lambda表达式命名,命名后完全可以当正常函数使用:
auto f = [](int i)->double{return 0.3+i}
为何使用Lambda表达式
- 代码易读性:将定义位于使用的附近
- 简洁
包装器
bind,men_fn,reference_wrapper,function
这块讲的是实例化的问题,之前我们说到,为了使用functor,我们不得不使用模板。在这里就出现了效率上的问题
- 一个接受
double返回double的函数,和一个接受double返回double的Lambda表达式,对应的是否是相同的实例化? - 答案还真不是。会产生两个实例化
- 但是这与我们的期望不符,因为行为上,该两个类型没有任何不同。所以按理说产生两个实例化是没必要的
function模板按照调用特征标来定义对象。
- 调用特征标只关心:接受什么参数,返回什么类型
- 比如上面的两个例子都是
double(double)的调用特征标 - 语法
std::function<double(double)> f = [](double)->{.....},这样声明出来的f可以接受任意调用特征标相同的functor的赋值 - 将相同的
std::function<调用特征标>类型的变量传给模板,只会生成相同的实例化
或者与模板进行混用
template<class T>
T f(T t,std::function<T(T)> f){
return f(t);
}
可变参数模板
模板和函数参数包
template<typename... Args>
void show_list(Args... args){
//...
}
-
使用省略号
...来声明参数包- 在
template中使用,声明模板参数包 - 在函数参数列表中使用,声明函数参数包
- 两者一一对应,例如调用
show_list(1,'a',"Hello"),模板的参数包就是[int,char,char*],函数参数包就是[1,‘a’,“Hello”]。(int,1),(char,‘a’),(char*,“Hello”)是相应的映射
- 在
-
在函数参数包中可以添加
const和&。比如void show_list(const Args&... args)
展开参数包
不能使用索引来获得包中的值
将...放在参数包的右边来将整个包打开,比如下面这个没有任何逼用的代码:
template<typename... Args>
void show_list(Args... args){
show_list(args...);
}
这个代码虽然是循环调用,会陷入死循环,但是给我们提供了展开参数包的思路,就是递归。
以下内容,与广义表关系紧密。大致的思路,就是将一个参数包分成“包头”和“包尾”(就像广义表里的head和tail的定义)。每次递归的形式:处理包头,递归进包尾
template<typename T,typename... Args>
void show_list(T value,Args... args){
cout << value << ",";
show_list(args...)
}














 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









