






导入项目运行
下载代码后,终端运行命令
python pacman.py得到吃豆人的游戏界面说明项目运行成功:

如果运行失败,检查python是否安装成功,主要检查两点,终端输入python有没有python提示的显示,如果弹出的是微软商店,记得在环境变量中删除微软商店的路径,最后有个APP的路径就是。然后确保python安装目录已添加到系统变量的path中。
编写评估函数
第一个函数getAction并不需要去修改它,是一个获取下一步行动的函数。而行动则是根据一定分数来评估,这个分数需要调用函数evaluationFunction来获取。最初的evaluationFunction只有基础的功能,需要自己来编写评估函数,返回一个分数。这个分数的设计方式就是计算当前位置与所有食物的曼哈顿距离,取反,和所有鬼魂的距离向乘,加上获取的分数。
# 计算当前位置与鬼魂之间的曼哈顿距离
ghost_distances = []
for gs in newGhostStates:
ghost_distances += [manhattanDistance(gs.getPosition(), newPos)]
# 计算食物到当前位置距离之和
food_distances = []
for food_position in foodList:
food_distances += [manhattanDistance(newPos, food_position)]
inverse_food_distances = 0;
if len(food_distances) > 0 and min(food_distances) > 0:
inverse_food_distances = 1.0 / min(food_distances)
# 计算分数
currscore += min(ghost_distances) * (inverse_food_distances ** 4)
currscore += successorGameState.getScore()同时,如果下一步能够吃到食物或者鬼魂正处于恐惧状态,则可以获得额外的加分。
# 鬼魂处于害怕状态则所有时间都可以加入评估分数
for st in newScaredTimes:
current_score += st
# 新位置有食物分数更高
if newPos in curfoodList:
current_score = current_score * 1.1Minimax
开始编写Minimax智能代理,需要在getAction中编写新的函数,从注释可以获取一些函数的作用。根据提示信息编写函数,在min中会有多个ghost分支需要全部求min。
def maxValue(gameState, d):
# 初始化为负无穷
val = float('-inf')
# 最佳移动方式默认为停止
bestAction = 'Stop'
# 对所有min分支求最大值
for action in gameState.getLegalActions(0):
tempState = gameState.getNextState(0, action)
tempVal, tempAction = minimaxDecision(tempState, 1, d)
if tempVal > val:
val = tempVal
bestAction = action
return (val, bestAction)
def minValue(gameState, ghost, d):
val = float('inf')
for action in gameState.getLegalActions(ghost):
tempState = gameState.getNextState(ghost, action)
tempVal, action = minimaxDecision(tempState, ghost + 1, d)
if tempVal < val:
val = tempVal
return val
# 选择最大最小值
def minimaxDecision(gameState, agent, d):
if agent >= gameState.getNumAgents():
agent = 0
d += 1
# 若当前状态已经赢了或输了或者已经到达了规定的深度
if (gameState.isWin() or gameState.isLose() or self.depth < d):
return (self.evaluationFunction(gameState), '')
# agent=0(吃豆人)则吃豆人获取最大值,反之鬼魂获得最小值
if 0 == agent:
return maxValue(gameState, d)
else:
return (minValue(gameState, agent, d), '')
# d位0是吃豆人
d = 1
firstAgent = 0
value, action = minimaxDecision(gameState, firstAgent, d)
return action运行测试


虽然通过,但是得分很低,运行命令
python pacman.py -p MinimaxAgent -l minimaxClassic -a depth=4会发现得分不稳定,并且有时糖豆人会输掉,有时会胜利。

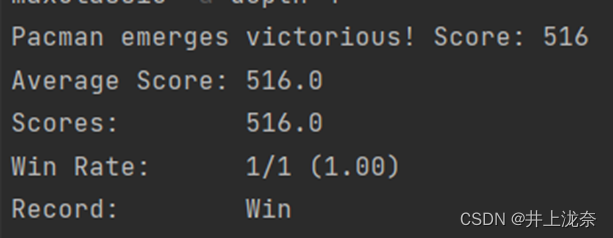
可以尝试树长为4,放置两个鬼魂,发现每走一步都非常困难,时间复杂度很高,这就需要进行剪枝。
αβ剪枝
剪枝只需要在minimax基础上对max、min函数中的不必要搜索的路径剪去,其他部分几乎一样。
# 若已经比beta要大了 就没有搜索下去的必要了
if val > beta:
return (val, action)同理修改minValue
# 若比alpha还要小了 就没搜索的必要了
if val < alpha:
return val
beta = min(beta, tempVal)运行命令
python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic发现得分比之前会高很多,每走一步所需要的时间花费更少了。
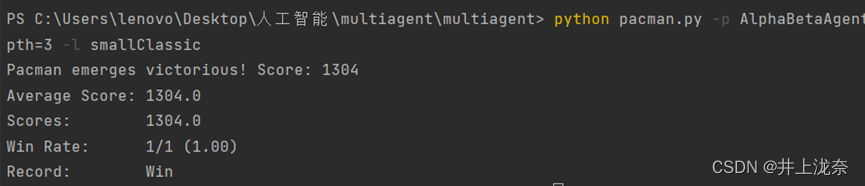
Expectimax
Expectimax要求不能所有的幽灵都采取min,而是需要根据幽灵的行动方式来采取期望,因此在minimax的基础上修改min函数。
def expectiValue(gameState, ghost, d):
val = 0
legalActions = gameState.getLegalActions(ghost)
# 加和所有行动值
for action in legalActions:
tempState = gameState.getNextState(ghost, action)
tempVal, action = expectimaxDecision(tempState, ghost + 1, d)
val += tempVal
# 返回平均值
return val / len(legalActions)执行αβ剪枝十次

然后执行期望

可以看到αβ剪枝总是输,而Expectimax大约能赢一半。当吃豆人陷入困境,在Expectimax中他至少会尝试脱困或者自杀,这样就能减少分数惩罚。
更好的评价函数
betterEvaluationFunction要求编写一个更好的评估值函数。可以使用鬼魂的启发值、食物的启发值和恐惧胶囊的启发值来作为返回参数。首先幽灵的启发值就是所有幽灵的距离,距离较远则有较高的启发值。
# 计算幽灵启发值
for ghostState in currentGameState.getGhostStates():
mDistance = manhattanDistance(ghostState.configuration.getPosition(), newPos)
# 不在恐惧时间内
if ghostState.scaredTimer <= 1:
# 距离较远
if 5 > mDistance:
evaluation -= (10 - mDistance)
# 距离太近
elif 2 > mDistance:
evaluation -= 100
for capsule in currentGameState.getCapsules():
evaluation -= manhattanDistance(capsule, newPos)食物的启发值则是获取最近的食物,距离近则启发值高。
for food in currentGameState.getFood().asList():
closestFood = min(manhattanDistance(food, newPos), closestFood)
evaluation -= closestFood + currentGameState.getNumFood()胶囊则是使用个数作为启发值,个数越多启发值越高。
# 胶囊启发值
newCapsule = currentGameState.getCapsules()
# 计算胶囊的个数
numberOfCapsules = len(newCapsule)
evaluation += numberOfCapsules
return evaluation最后运行命令
python autograder.py -q q5 --no-graphics
MiniMax

闲话
知乎上可能有和此文章重复度比较高的段落,是我之前做软件测试的时候自动写的,详见selenium简单的UI测试,测试知乎点赞、收藏、搜索、写文章、浏览五个功能_selenium 知乎发布文章_井上泷奈的博客-CSDN博客















 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









