







case 2 :Power Consumption in Computer Systems
习题1.4
题目背景:
A cell phone performs very different tasks, including streaming music, streaming video, and reading email. These tasks perform very different computing tasks. Battery life and overheating are two common problems for cell phones, so reducing power and energy consumption are critical. In this problem,we consider what to do when the user is not using the phone to its full computing capacity. For these problems, we will evaluate an unrealistic scenario in which the cell phone has no specialized processing units. Instead, it has a quad-core, general purpose processing unit. Each core uses 0.5 W at full use. For email-related tasks,the quad-core is 8× as fast as necessary.
一部智能手机需要执行多种截然不同的任务,包括音乐流媒体、视频流媒体和阅读电子邮件。这些任务涉及差异巨大的计算操作。电池续航和过热是智能手机的两个常见问题,因此降低功耗和能耗至关重要。在本问题中,我们将探讨当用户未充分使用手机计算能力时的优化方案。
在这些问题中,我们将评估一个非现实场景:假设该手机没有专用处理单元,而是搭载了一个四核通用处理器。每个核心在满载运行时功耗为0.5瓦。对于电子邮件相关任务,四核处理器的性能是实际所需速度的8倍。
问题:
(a)How much dynamic energy and power are required compared to running at full power? First, suppose that the quad-core operates for 1/8 of the time and is idle for the rest of the time. That is, the clock is disabled for 7/8 of the time, with no leakage occurring during that time. Compare total dynamic energy as well as dynamic power while the core is running。
翻译:与全功率运行相比,所需的动态能量和动态功耗是多少?首先假设四核处理器仅在 1/8 的时间 内运行,其余时间处于空闲状态(即时钟在 7/8 的时间 内被关闭,期间不发生漏电)。请比较 总动态能耗 以及 核心运行时的动态功率。
解答:由于间隔运转的时候,运转期间并未发生电压与频率的变化,(电容视为固定属性值,默认不会变化),由公式,(k>0)表示动态功率P与电压V平方,以及频率f成正比,则动态功率P未发生变化;而功耗E=功率P×时间t,由于处理器只有1/8 的时间在运行,因此E间隔运行/E满载运行=
,只有满载运转的动态能量的1/8.
(b)How much dynamic energy and power are required using frequency and voltage scaling? Assume frequency and voltage are both reduced to 1/8 the entire time.
翻译:在使用电压和频率调节(DVFS)的情况下,动态能量和动态功耗的需求是多少?假设电压和频率均全程降至原始值的 1/8。
解答:由公式 ,
(k>0),当电压和频率都相比原来下降到原来的1/8时候,则E降/E原=
=1/64约等于0.0156,P降/P原=
=1/512约等于0.00195,因此动态能耗需要是原来的0.0156倍,而动态功耗为原来的0.00195倍。
(c)Now assume the voltage may not decrease below 50% of the original voltage. This voltage is referred to as the voltage floor, and any voltage lower than that will lose the state. Therefore, while the frequency can keep decreasing, the voltage cannot. What are the dynamic energy and power savings in this case?
翻译:现在假设电压不能低于原始电压的50%。这一电压被称为“电压下限”(voltage floor),若电压低于此值,电路状态将丢失。因此,尽管频率可以持续降低,电压却无法进一步下降。
问:在此情况下,动态能量和动态功耗的节省幅度是多少?
解答:由于电压下限的存在,此时在(b)基础上,电压改为下降为原来1/2,频率仍为1/8,则E降/E原==1/4等于0.25,P降/P原=
=1/32约等于0.03125,因此节约了1-0.25=0.75倍的动态能量,以及1-0.03125=0.96875倍的动态功耗。
(d)How much energy is used with a dark silicon approach? This involves creating specialized ASIC hardware for each major task and power gating those elements when not in use. Only one general-purpose core would be provided, and the rest of the chip would be filled with specialized units.
For email, the one core would operate for 25% the time and be turned completely off with power gating for the other 75% of the time. During the other 75% of the time, a specialized ASIC unit that requires 20% of the energy of a core would be running.
翻译:采用“暗硅”(Dark Silicon)策略时,总能耗是多少?该策略通过以下方式实现:为每个主要任务设计专用ASIC硬件,并在闲置时通过电源门控(Power Gating)彻底关闭。仅保留1个通用计算核心,芯片其余部分由专用单元填充。以邮件处理为例:通用核心仅在 25%的时间 运行,其余 75%的时间完全关闭(电源门控,功耗=0)。在通用核心关闭的 75%时间 内,由 专用ASIC单元 接管任务,其能耗仅为通用核心的 20%。
解答:暗硅策略有题目可知,只保留一个核心,该核心 25%的时间 运行,期间电压按照(c)电压限制,为原来1/2, 75%的时间完全关闭,期间用ASIC单元接管任务,其能耗仅为通用核心的 20%(即运作时候20%的能耗),由(k>0),可知25%运转期间对应功耗为E暗硅运转/E原=
=1/16的原能耗,75%的停转时间ASIC单元处理能耗(20%的运转时候的能耗)为E暗硅停转/E原=
=3/80的原能耗,此时暗硅策略的总能耗为(E暗硅运转+E暗硅停转)/E原=1/16+3/80=1/10=0.1倍的原能耗。设运行时间为t(单位为秒),原单核功率为0.5w,则原能耗为0.5t J,则根据功耗E=功率P×时间t的公式,暗硅策略的当前总能耗为0.5t×0.1=0.05t J
习题1.5
题目背景:
As mentioned in Exercise 1.4, cell phones run a wide variety of applications. We’ll make the same assumptions for this exercise as the previous one, that it is 0.5 W per core and that a quad core runs email 3× as fast.
如习题1.4所述,手机需要运行多种应用程序。本题沿用之前的假设:
每个核心的功耗为 0.5 W;
四核处理器运行邮件任务的速度是单核的 3倍。
(a)Imagine that 80% of the code is parallelizable. By how much would the frequency and voltage on a single core need to be increased in order to execute at the same speed as the four-way parallelized code?
翻译:假设 80% 的代码可以并行化,单核处理器 需要通过 提升多少的频率和电压 来达到与 四核并行代码 相同的执行速度?
解答:由阿姆达尔定律,优化比例为a,优化倍数为b,优化速度为加速比=。由题意,并行代码占据80%,则意味着对于4核并行方式80%的执行会被优化,而采用4核并行代码,执行速度提升为单核的4倍,因此得到4核并行的加速比为
=2.5。由于单核频率与速度提升成正比,而电压通常可以认为和频率成正比提升(除了接近阈值低电压的时候可能呈非线性),因此我们认为提升2.5倍的频率和电压。
(b)What is the reduction in dynamic energy from using frequency and voltage scaling in part a?
解释:通过使用(问题a部分提到的)动态电压频率调节技术,动态能耗减少了多少?
解答:由(a)可知4核并行处理的时候频率和电压为单核的1/2.5倍(由上可知单核频率根电压增加到原来的2.5倍,4核则保持不变),由公式(k>0)则E4核/E单核=
=0.64倍的原能耗,因此减少了1-0.64=0.36即36%的动态能耗。
(c)How much energy is used with a dark silicon approach? In this approach, all hardware units are power gated, allowing them to turn off entirely (causing no leakage). Specialized ASICs are provided that perform the same computation for 20% of the power as the general-purpose processor. Imagine that each core is power gated. The video game requires two ASICs and two cores. How much dynamic energy does it require compared to the baseline of parallelized on four cores?
翻译:"采用暗硅方案时能耗是多少?在该方案中,所有硬件单元都采用电源门控技术,可以完全关闭(不产生任何漏电)。系统提供专用ASIC芯片,其完成相同计算任务所需功耗仅为通用处理器的20%。假设每个核心都能被电源门控。某款电子游戏需要调用2个ASIC芯片和2个核心。与基准方案(四个核心全开并行计算)相比,该方案需要多少动态能耗?"
解答:已知暗硅方案为专门ASICs使用原来核心功率的20%来作为通用处理器,而电子游戏需要2个ASICs和2个单核,则2个ASICs与2个单核各自的能耗之和就为该暗硅方案的能耗。根据公式能耗E=功率P×时间t,则有E暗硅/E4核==2.4/4=0.6倍,因此需要基准方案(4核并行)的0.6倍的动态能耗。
习题1.6
题目背景:
General-purpose processes are optimized for general-purpose computing. That is, they are optimized for behavior that is generally found across a large number of applications. However, once the domain is restricted somewhat, the behavior that is found across a large number of the target applications may be different from general-purpose applications. One such application is deep learning or neural networks. Deep learning can be applied to many different applications, but the fundamental building block of inference—using the learned information to make decisions—is the same across them all. Inference operations are largely parallel, so they are currently performed on graphics processing units, which are specialized more toward this type of computation, and not to inference in particular. In a quest for more performance per watt, Google has created a custom chip using tensor processing units to accelerate inference operations in deep learning.1 This approach can be used for speech recognition and image recognition, for example. This problem explores the trade-offs between this process, a general-purpose processor (Haswell E5-2699 v3) and a GPU (NVIDIA K80), in terms of performance and cooling. If heat is not removed from the computer efficiently, the fans will blow hot air back onto the computer, not cold air. Note: The differences are more than processor—on-chip memory and DRAM also come into play. Therefore statistics are at a system level, not a chip level.
通用处理器针对通用计算进行了优化。也就是说,它们针对的是在大量应用程序中普遍存在的行为模式而优化。然而,当应用领域有所限定时,目标应用程序中常见的行为模式可能与通用程序有所不同。深度学习或神经网络正是此类应用的典型代表。虽然深度学习可应用于众多领域,但其核心的推理运算(利用学习所得信息进行决策)在所有应用中都是相通的。
推理运算具有高度并行性,因此目前主要在图形处理器(GPU)上运行。GPU本身专为这类计算而优化,但并非专门针对推理任务。为了追求更高的能效比,谷歌开发了采用张量处理单元(TPU)的定制芯片,专门加速深度学习中的推理运算。这种方案可应用于语音识别、图像识别等场景。
本问题将探讨三种硬件在性能和散热方面的优劣对比:定制TPU、通用处理器(Haswell E5-2699 v3)和GPU(NVIDIA K80)。若计算机散热不良,风扇将循环排出热空气而非吸入冷空气。需注意:差异不仅存在于处理器——片上内存和DRAM同样会影响结果,因此统计数据均为系统级而非芯片级。
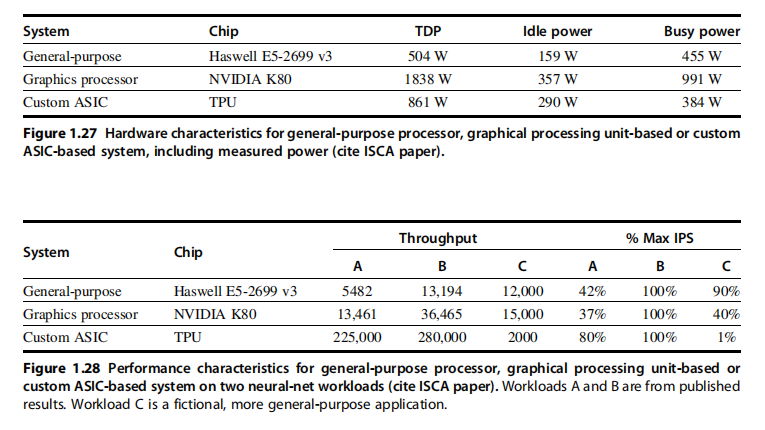
(a) If Google’s data center spends 70% of its time on workload A and 30% of its time on workload B when running GPUs, what is the speedup of the TPU system over the GPU system?
翻译:如果谷歌数据中心在使用 GPU 运行时,70% 的时间用于工作负载 A,30% 的时间用于工作负载 B,那么 TPU 系统相比 GPU 系统的加速比是多少?
解答:由图1.28可知,对于GPU系统(NVIDIA K80芯片)对应的工作负载A吞吐量为13461,而TPU系统为225000,可计算其工作负载A加速比=TPU负载A吞吐量/GPU负载A的吞吐量=225000/13461 ≈16.7,GPU系统同时负载B的吞吐量为36465,而TPU系统对应的吞吐量为280000,因此计算对应的工作负载B加速比=TPU负载B吞吐量/GPU负载B的吞吐量=280000/36465 ≈7.7,因此使用阿姆达尔定律,优化比例为a,优化倍数为b,优化速度为加速比=,可得TPU 系统相比 GPU 系统的加速比为
≈12.36
(b)If Google’s data center spends 70% of its time on workload A and 30% of its time on workload B when running GPUs, what percentage of Max IPS does it achieve for each of the three systems?
翻译:如果谷歌数据中心在使用 GPU 运行时,70% 的时间用于工作负载 A,30% 的时间用于工作负载 B,那么三种系统(TPU、通用处理器 Haswell E5-2699 v3、GPU NVIDIA K80)各自能达到的最大 IPS(每秒指令数)百分比是多少?
解答:由图1.28可知,General-purpose系统的工作负载A最大IPS百分比为42%,负载B为100%;Graphics processor系统的工作负载A最大IPS百分比为37%,负载B为100%;Custom ASIC系统(TPU)的工作负载A最大IPS百分比为80%,负载B为100%,当三个系统均为70%时间用于工作负载A,30%时间用于工作负载B。系统的IPS百分比上限取决于系统中各个单元(负载)的加权平均指令执行效率,即每个模块(负载)对应使用的频率(时间占比)乘上每个模块(负载)的IPS,因此本题中各个系统最大IPS百分比=负载A的使用时间比例×A的最大IPS百分比+负载B的使用时间比例。Haswell E5-2699 v3系统的最大IPS=0.7×0.42+0.3×1=0.594即59.4%,GPU NVIDIA K80最大IPS=0.7×0.37+0.3×1=0.559即55.9%, TPU最大IPS=0.7×0.8+0.3×1=0.86即86%
(c)Building on (b), assuming that the power scales linearly from idle to busy power as IPS grows from 0% to 100%, what is the performance per watt of the TPU system over the GPU system?
翻译:承接问题 (b) 的设定,假设系统功耗随着 IPS(每秒指令数)从 0% 增长到 100% 而呈线性增加(从空闲功耗到满载功耗),那么 TPU 系统相对于 GPU 系统的 能效比(性能/瓦特) 是多少?
解答:耗从空闲功耗(Idle Power)到满载功耗(Busy Power)随IPS增长线性增加,对应公式为:实际功耗=空闲功耗+(满载功耗−空闲功耗)×% 系统最大IPS;由(b)可知,TPU系统最大IPS百分比为86%,GPU系统对应百分比为55.9%,同时由图1.27可知TPU系统的空闲功耗为290W,满载功耗为384W,GPU系统的空闲功耗为357W,满载功耗为991W,由此可计算TPU系统的实际功耗=290+(384-290)×0.86=370.84W,GPU系统的实际功耗=357+(991-357)×0.559=711.41W。在本题中性能没有明确定义,此处定义为系统的吞吐量。由(b)时间加权条件和图1.28的各个负载吞吐量,TPU系统的吞吐量=0.3×225000+0.7×280000=263500,则TPU的性能功效比=263500/370.84≈972.9吞吐每瓦特,同理GPU系统的吞吐量=0.3×13461+0.7×36465= 29563.8 ,则GPU的性能功效比=29563.8/711.41≈41.56吞吐每瓦特,因此TPU与GPU的性效比为972.9/41.56≈23.41
(d)If another data center spends 40% of its time on workload A, 10% of its time on workload B, and 50% of its time on workload C, what are the speedups of the GPU and TPU systems over the general-purpose system?
翻译:若某数据中心运行时间的40%用于工作负载A、10%用于工作负载B、50%用于工作负载C,则GPU系统和TPU系统相比通用系统的加速比分别是多少?
解答:已知通用系统的负载A,B,C的吞吐量分别为5482,13194,12000,GPU系统的A,B,C吞吐量分别为13461,36465,15000,TPU系统的A,B,C吞吐量分别为225000,280000, 2000,A占比40%时间,B占比10%的时间,C占比50%的时间。对于GPU和通用系统,在负载A,B,C上分别的加速比为对应吞吐量之比,即13461/5482≈2.46,36465/13194≈2.76,15000/12000≈1.25;对于TPU和通用系统,在负载A,B,C上分别的加速比为对应吞吐量之比,即225000/5482≈41.04,280000/13194≈21.22,2000/12000≈0.17;由阿姆达尔定律优化比例为a,优化倍数为b,优化速度为加速比=,则GPU相对于通用系统的加速比=
≈1.67,TPU相对于通用系统的加速比=
≈0.34
(e)A cooling door for a rack costs $4000 and dissipates 14 kW (into the room; additional cost is required to get it out of the room). How many Haswell-, NVIDIA-, or Tensor-based servers can you cool with one cooling door, assuming TDP in Figures 1.27 and 1.28?
翻译:一个机架冷却门的成本为4000美元,可消散14千瓦热量(热量排入机房,如需排出机房还需额外成本)。假设热设计功耗(TDP)如图1.27和1.28所示,单个冷却门可为多少台基于Haswell、NVIDIA或Tensor的服务器提供冷却?
解答:由图1.27的热设计功耗(TDP),可知Haswell(通用系统),NVIDIA(GPU系统),Tensor(TPU系统)对应的TDP为504 W,1838 W,861 W。每个冷却门14000W的散热,则单个冷却门给Haswell、NVIDIA和Tensor各自服务器冷却的数量为14000/504≈27台,14000/1838≈7台,14000/861≈16台
(f)Typical server farms can dissipate a maximum of 200 W per square foot. Given that a server rack requires 11 square feet (including front and back clearance), how many servers from part (e) can be placed on a single rack, and how many cooling doors are required?
翻译:典型服务器机房的最大散热能力为每平方英尺200瓦。已知单个服务器机架占地11平方英尺(含前后维护通道),根据问题(e)中的服务器型号,单个机架可部署多少台服务器?需要配备多少个冷却门?
解答:已知单个服务武器架子11平方英尺,每平方英尺散热200瓦,则每个架子的散热能力为200×11=2200W,每个机架部署的服务器数量为单个机架散热能力/每个服务器的散热功耗,由1.27可知Haswell(通用系统),NVIDIA(GPU系统),Tensor(TPU系统)对应的TDP为504 W,1838 W,861 W,则每个机架最多盛放的Haswell,NVIDIA,Tensor服务器分别为2200/504≈4台,2200/1838≈1台,2200/861≈2台。如果按照题目要求,每种服务器型号只用一个冷却门就够了(504×4<14000;1838×1<14000;861×2<14000),但可能不是原作者命题所问(题目提问表述不对),因此第二问改为一个冷却门最多支持多少个每种型号的机架。一个冷却门最多支持机架的数量为冷却功耗上限/(每个机架的服务器数量×每台服务器的散热值),此时冷却门对Haswell的机架支持数量为14000/504×4≈6个,对NVDIA的机架支持数量为14000/1838×1≈7个,对Tensor的机架支持数量为14000/861×2≈8个
习题1.7
题目背景:
One challenge for architects is that the design created today will require several years of implementation, verification, and testing before appearing on the market. This means that the architect must project what the technology will be like several years in advance. Sometimes, this is difficult to do.
架构师面临的一项挑战是,如今设计出的方案需要经过数年实施、验证与测试才能面市。这意味着架构师必须提前数年预测技术发展趋势,而这一点有时很难做到。
(a) According to the trend in device scaling historically observed by Moore’s Law, the number of transistors on a chip in 2025 should be how many times the number in 2015?
翻译:根据摩尔定律历史观察到的器件缩放趋势,2025年单个芯片上的晶体管数量应该是2015年的多少倍?
解答:根据摩尔定律,单个芯片的晶体管数量,每年增长40%55%,或者每隔18-24个月翻一倍。因此 从15年到25年这10年,单个芯片的晶体管数量将增长~
倍(即28.9~80倍),或者增长
~
(即32~101.6倍)
(b)The increase in performance once mirrored this trend. Had performance continued to climb at the same rate as in the 1990s, approximately what performance would chips have over the VAX-11/780 in 2025?
翻译:性能的提升曾一度与这一趋势同步。若性能增速持续保持1990年代的水平,到2025年芯片的性能预计将达到VAX-11/780的多少倍?(本题需要参考1.1节的图1.1)
解答:按照90年代的性能增长速度,从2003年以后芯片的MIPS性能应该保持每年增长52%,因此从03年到25年这22年之间的性能理应提升为≈10012.88倍,而03年的代表奔腾4芯片的MIPS性能为6043,因此预计到达VAX-11/780(其性能为1MIPS)的10012.88×6043≈60507834(约六千万倍)
(c)At the current rate of increase of the mid-2000s, what is a more updated projection of performance in 2025?
翻译:按照2000年代中期(2005年左右)以来的性能增速趋势,2025年的性能水平更现实的预测值是多少?
解答:按照00年代的性能增长速度,从2011年以后芯片的MIPS性能应该保持每年增长22%,因此从11年到25年这14年之间的性能理应提升为≈16.18倍,而11年的代表酷睿i7-2600K芯片的MIPS性能为31999,因此预计到达VAX-11/780(其性能为1MIPS)的16.18×31999≈517814(约五十万倍)
(d)What has limited the rate of growth of the clock rate, and what are architects doing with the extra transistors now to increase performance?
翻译:哪些因素限制了时钟频率的提升速度?如今的架构师们如何利用额外增加的晶体管来提升性能?
解答:限制因素:①由动态功耗公式,可知时钟频率越高,会引起功耗越大,芯片发热急剧上升,从而引起芯片性能的降低②静态功耗也会转化为热量,而温度升高又会指数级增加漏电流,这种互相的静态静态正反馈使得散热功耗被限制,频率也被间接限制;架构师可以通过把单核变成多核并行,使用专用加速器,缓存与内存层级优化等方法提升性能
(e)The rate of growth for DRAM capacity has also slowed down. For 20 years, DRAM capacity improved by 60% each year. If 8 Gbit DRAM was first available in 2015, and 16 Gbit is not available until 2019, what is the current DRAM growth rate?
翻译:DRAM容量的增长速度同样在放缓。过去20年间,DRAM容量每年提升60%。若8 Gbit DRAM于2015年首次上市,而16 Gbit直到2019年才问世,当前的DRAM增长率是多少?
解答:设增长率为r,由题意,15年为8 Gbit,19年为16 Gbit,则4年的增长有=16,解出增长率r为18.9%
习题1.8
题目背景:
You are designing a system for a real-time application in which specific deadlines must be met. Finishing the computation faster gains nothing. You find that your system can execute the necessary code, in the worst case, twice as fast as necessary
你正在为一个实时系统设计应用程序,该系统必须满足严格的截止时间要求。计算完成得再快也无法带来额外收益。经测试发现,你的系统在最坏情况下能以所需速度的两倍执行完必要代码。
(a)How much energy do you save if you execute at the current speed and turn off the system when the computation is complete?
翻译: 若保持当前速度运行,并在计算完成后立即关闭系统,可节省多少能耗?
解答:通常在关闭电源后,芯片仍有电流泄露,通常静态功耗仍有50%会存在,因此只能节省50%
(b)How much energy do you save if you set the voltage and frequency to be half as much?
翻译:若将电压和频率均设为原值的一半,可节省多少能耗?
解答:电压改为下降为原来1/2,频率下降为1/2,由公式(k>0,则E降/E原=
=1/4等于0.25,因此可以节省1-0.25=0.75即75%的能耗。
习题1.9
题目背景:
Server farms such as Google and Yahoo! provide enough compute capacity for the highest request rate of the day. Imagine that most of the time these servers operate at only 60% capacity. Assume further that the power does not scale linearly with the load; that is, when the servers are operating at 60% capacity, they consume 90% of maximum power. The servers could be turned off, but they would take too long to restart in response to more load. A new system has been proposed that allows for a quick restart but requires 20% of the maximum power while in this “barely alive” state.
诸如谷歌和雅虎等企业的服务器集群会按照每日最高请求负载来配置计算容量。但实际上,这些服务器大部分时间仅以60%的容量运行。进一步假设功耗与负载并非线性关系——即当服务器以60%负载运行时,仍会消耗最大功率的90%。虽然可以关闭服务器以节能,但重启响应时间过长,无法及时应对负载突增。为此,有人提出一种新系统,可在"低活状态"下快速重启,但此状态下仍需消耗最大功率的20%。
(a)How much power savings would be achieved by turning off 60% of the servers?
翻译:若关闭60%的服务器,可实现多少功耗节约?
解答:每个服务器的功耗视为一致,则关闭60%服务器,则节约60%的功耗。
(b)How much power savings would be achieved by placing 60% of the servers in the “barely alive” state?
翻译:若将60%的服务器置于"低活状态"(barely alive),可实现多少功耗节约?
解答:对于低活状态,有题目含义仍要消耗20%的能耗,由题意,目前保持60%的服务器为”低活状态“因此,”低活状态“下的功耗为启动服务器比例+关闭服务器比例×20%=0.4+0.6×0.2=0.52,因此节约了1-0.52=0.48即48%的功耗
(c)How much power savings would be achieved by reducing the voltage by 20% and frequency by 40%?
翻译:若将电压降低20%且频率降低40%,可实现多少功耗节约?
解答:由公式(k>0),可知,降低20%电压(为原来的1-0.2=0.8倍电压),降低 40%频率(为原来的1-0.4=0.6倍频率),则由P降/P原=
=0.64×0.6=0.384倍原功率,因此节约了1-0.384=0.616即61.6%的功耗。
(d)How much power savings would be achieved by placing 30% of the servers in the “barely alive” state and 30% off?
翻译:若将30%的服务器置于"低活状态"(barely alive),同时关闭另外30%的服务器,可实现多少功耗节约?
解答:对于低活状态,有题目含义仍要消耗20%的能耗,由题意,目前保持30%的服务器为”低活状态“因此,”低活状态“下的功耗为启动服务器比例+关闭服务器比例×20%=0.7+0.3×0.2=0.72,因此节约了1-0.72=0.28即28%的功耗
习题1.10
题目背景:
Availability is the most important consideration for designing servers, followed closely by scalability and throughput
可用性是服务器设计的首要考量因素,可扩展性与吞吐量紧随其后。
(a)We have a single processor with a failure in time (FIT) of 100. What is the mean time to failure (MTTF) for this system?
翻译:假设某单处理器系统的失效率(FIT)为100,求该系统的平均无故障时间(MTTF)。
解答:FIT(Failure in Time)表示每10亿(10⁹)小时运行中预期的故障次数,由题意FIT为100次故障每10的9次方小时。因此系统的平均无故障时间(MTTF)为考虑的总时间/该时间内出现故障的次数==
小时
(b)If it takes one day to get the system running again, what is the availability of the system?
翻译:若系统故障后需要1天时间恢复运行,则该系统的可用性(Availability)是多少?
解答:可用性通常为平均无故障时间/(恢复时间+平均无故障时间)之比,由(a)可知平均无故障时间为小时,回复时间为1天即24小时,因此该系统的可用性为
≈0.9999976可以视为1。
(c) Imagine that the government, to cut costs, is going to build a supercomputer out of inexpensive computers rather than expensive, reliable computers. What is the MTTF for a system with 1000 processors? Assume that if one fails, they all fail
翻译:假设政府为了削减成本,计划用廉价计算机(而非高可靠性计算机)构建一台超级计算机。若该系统由1000个处理器组成,且任一处理器故障会导致整个系统故障,求该系统的平均无故障时间(MTTF)。
解答:由(a)可知系统的FIT为100,每个设备各自发生故障的概率独立同分步,因此,可以认为1000个处理器,的总共FIT为1000×100=,由系统的平均无故障时间(MTTF)为考虑的总时间/该时间内出现故障的次数=
=
小时.。
习题1.11
题目背景:
In a server farm such as that used by Amazon or eBay, a single failure does not cause the entire system to crash. Instead, it will reduce the number of requests that can be satisfied at any one time
在亚马逊或eBay等企业使用的服务器集群中,单个故障不会导致整个系统崩溃,而是会降低系统在同一时间内能够处理的请求数量。
(a)If a company has 10,000 computers, each with an MTTF of 35 days, and it experiences catastrophic failure only if 1/3 of the computers fail, what is the MTTF for the system?
翻译:如果一家公司拥有10,000台计算机,每台的平均故障间隔时间(MTTF)为35天,且仅当1/3的计算机发生故障时才会导致系统灾难性失效,那么该系统的MTTF是多少?
解答:本题要使用部分冗余系统求解。这里涉及串行,并行和部分冗余系统模型,故先做介绍。对于n个设备,如果每个设备单独的MTTF为m,对于串行系统(要求n个设备都都要正常运作无故障),则对应的系统MTTF为m/n;对于并行系统(要求n个设备中至少有一个设备需求运作),则系统的MTTF为m(1+1/2+....+1/n);对于部分冗余系统(n个设备中至少有k个在运作),对应的系统的MTTF为m(1/k+1/(k+1)+...+1/n)。由题意,已知系统由n=10000台计算机构成,每台的平均故障间隔时间(MTTF)为m=35天,至少1/3的故障会引起系统瘫痪,因此至少保持10000-10000/3≈6666台计算机运作系统才能无故障, 因此系统的MTTF为35(1/6666+1/6667+...+1/10000 )≈14.19天
(b)If it costs an extra $1000, per computer, to double the MTTF, would this be a good business decision? Show your work.
翻译:若每台计算机额外投入1000美元可将MTTF延长一倍,这是否是明智的商业决策?请给出计算过程。
解答:入宫MTTF可以延长一倍,由(a)可知系统原来的MTTF为14.19天则系统的MTTF将变为14.19×2=28.38天,假设每次故障的维护时间为t,每小时付出维护成本和期间累计损失为c,优化的平均每年平均故障间隔数为f,我们可以得出节省的成本m=f×t×c=×t×c。而当前累计额外投入需要1000×10000=1千万美元,如果成本m=
×t×c≥1千万美元。我们是有必要投入的(事实上系统崩溃带来的损失一般都是多到难以估计的,在大部分情况下是值得的)
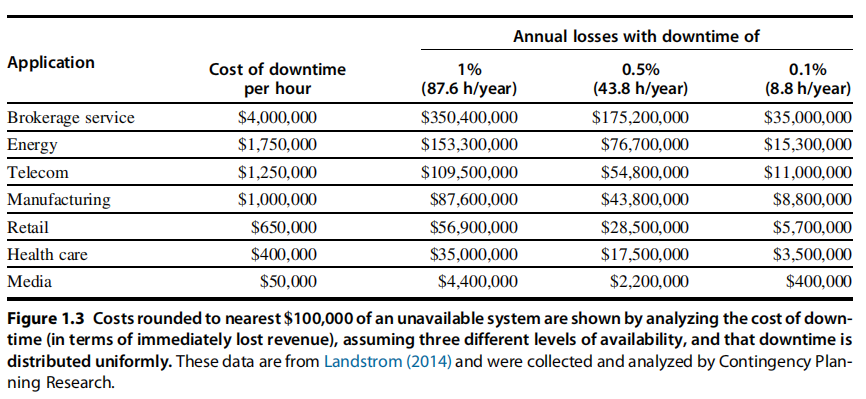
(c)Figure 1.3 shows, on average, the cost of downtimes, assuming that the cost is equal at all times of the year. For retailers, however, the Christmas season is the most profitable (and therefore the most costly time to lose sales). If a catalog sales center has twice as much traffic in the fourth quarter as every other quarter, what is the average cost of downtime per hour during the fourth quarter and the rest of the year?
翻译:图1.3显示了停机时间的平均成本(假设全年各时段成本相同)。然而对零售商而言,圣诞季是利润高峰期(此时销售损失的成本也最高)。若某邮购销售中心第四季度的访问量是其他季度的两倍,则其第四季度与其他季度的每小时停机成本分别是多少?
解答:由图1.3可看到零售商对应的全年平均停机成本为65000美元,设第一,二,三季度的停机成本为x美元,第四季度为2x美元,因此由(3x+2x)/4=65000美元,解得x=52000美元,因此第四季度停机成本为52000×2=104000美元,而其余季度为52000美元。
习题1.12
题目背景:
In this exercise, assume that we are considering enhancing a quad-core machine by adding encryption hardware to it. When computing encryption operations, it is 20 times faster than the normal mode of execution. We will define percentage of encryption as the percentage of time in the original execution that is spent performing encryption operations. The specialized hardware increases power consumption by 2%
在本练习中,我们考虑通过添加加密硬件来增强一台四核机器。在进行加密运算时,该硬件的速度是正常执行模式的20倍。我们将加密百分比定义为原始执行过程中用于加密操作的时间所占的比例。该专用硬件会使功耗增加2%。
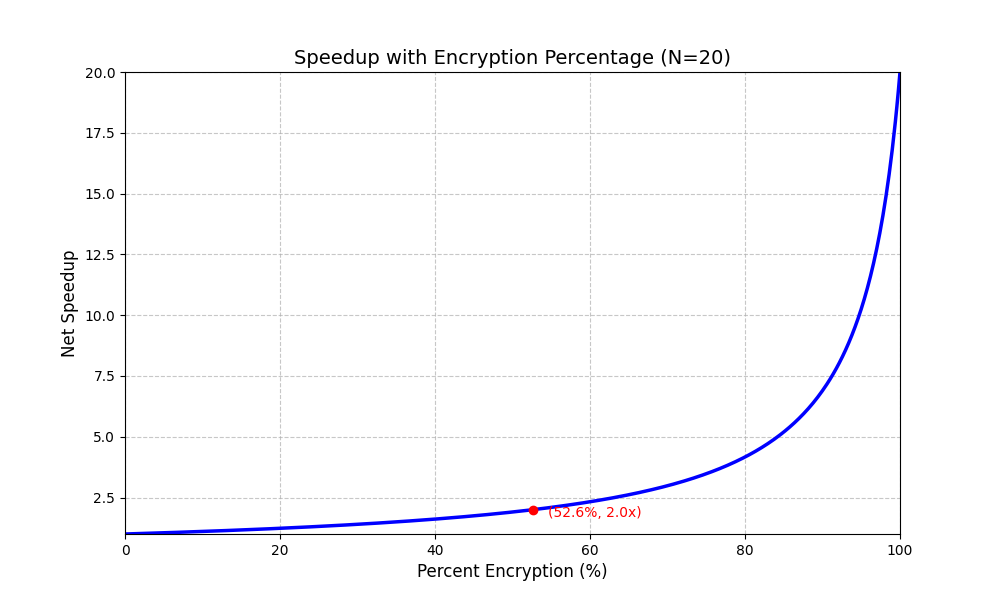
(a)Draw a graph that plots the speedup as a percentage of the computation spent performing encryption. Label the y-axis “Net speedup” and label the x-axis “Percent encryption.”
翻译:请绘制一张图表,展示 加速比(Speedup) 与 加密计算百分比(Percent Encryption) 的关系。y 轴(纵轴)标注为 "Net speedup"(净加速比),x 轴(横轴)标注为 "Percent encryption"(加密百分比)
解答:由题意,要求加速比与加密百分比的关系图,首先需要直到表达式(y为加速比,x为加密百分比)根据阿姆达尔定律,优化比例为a,优化倍数为b,优化速度为加速比=,而题目可知加密专用硬件的提速20倍,因此公式加速比与加密百分比定义为y=
,对应的图像如下:
(b)With what percentage of encryption will adding encryption hardware result in a speedup of 2?
翻译:我们需要计算:加密计算所占的比例(百分比)达到多少时,引入加密硬件才能使整体系统速度提升至原来的2倍?
解答:设加密设备占比为x时候可以达到加速2倍,由上可知加速比y=,当y=2时候,此时解出x≈52.6%,因此加密计算百分比为52.6%达到2倍提速。
(c)What percentage of time in the new execution will be spent on encryption operations if a speedup of 2 is achieved?
翻译:我们需要计算:当系统整体加速比达到2倍时,在新执行时间中,加密操作所占的时间百分比是多少?
解答:加密操作所占时间百分比为加密操作所用时间/(非加密操作所用时间+加密操作所用时间)。由(b)可知,当前加密计算的百分比为0.526,则其余操作占比为1-0.526=0.474,设其余操作执行的速度为v,则加密操作速度提速为20v,由题意加密操作所占时间百分比为(0.526/20v)/(0.526/20v+0.474/v)≈0.053即5.3%
(d)Suppose you have measured the percentage of encryption to be 50%. The hardware design group estimates it can speed up the encryption hardware even more with significant additional investment. You wonder whether adding a second unit in order to support parallel encryption operations would be more useful. Imagine that in the original program, 90% of the encryption operations could be performed in parallel. What is the speedup of providing two or four encryption units, assuming that the parallelization allowed is limited to the number of encryption units?
解答: 假设已测得加密操作占比为50%。硬件设计团队认为,通过大幅增加投资可以进一步提升加密硬件的速度。此时,您考虑是否增加第二套加密单元以支持并行加密操作会更有效。假设在原程序中,90%的加密操作可以并行执行。若并行化程度受限于加密单元数量,则提供2个或4个加密单元能带来多少加速比?
解答:本题分成两层次加速,一个为加密硬件内部的加速,以及整个系统的加速。本题全部围绕阿姆达尔定律(优化比例为a,优化倍数为b,优化速度为加速比=)计算;对于加密部件,90%的加密操作可以并行执行,当加密单元有两个时候则加密部件的提速为
≈1.82,四个的时候提速为
≈3.08,原来已经有20倍的提速,因此2个加密单元的累计提速为20×1.82=36.4倍,4个加密单元的累计提速为20×3.08=61.6倍,而已知加密操作占比50%,因此2个加密单元的总体加速比=
≈1.95倍的加速,而4个加密单元的总体加速比=
≈1.97倍的加速
习题1.13
题目背景:
Assume that we make an enhancement to a computer that improves some mode of execution by a factor of 10. Enhanced mode is used 50% of the time, measured as a percentage of the execution time when the enhanced mode is in use. Recall that Amdahl’s Law depends on the fraction of the original, unenhanced execution time that could make use of enhanced mode. Thus we cannot directly use this 50% measurement to compute speedup with Amdahl’s Law.
题目假设我们对计算机进行了一项改进,使得某种执行模式的性能提升至原来的10倍(加速因子为10)。改进后的模式在实际运行中被使用了50%的时间(即在启用增强模式时,该模式占总执行时间的50%)。然而,阿姆达尔定律(Amdahl's Law) 的计算依赖于原始未改进程序中可被增强的部分所占的时间比例,而题目给出的50%是增强模式启用后的时间占比,因此不能直接用于计算加速比。
(a) What is the speedup we have obtained from fast mode?
翻译:我们从快速模式中获得了多少加速比?
解答:本题不需要也不能使用阿姆达尔定律(题目背景已经说明),题目已知改进后,改进模式的运行时间占比50%,设快速模式执行操作时间用时为t,因为有50%的时间用于改进模式,且改进模式的速度提升10倍(原来模式该部分所花时间则番为10倍),因此原来模式所花的时间为0.5t+0.5×10t=5.5t的时间,因此快速模式的加速比为原来时间/改进时间=5.5t/t=5.5倍
(b)What percentage of the original execution time has been converted to fast mode?
翻译:原始执行时间中有多少百分比被转换为快速模式?
习题1.14
题目背景:
When making changes to optimize part of a processor, it is often the case that speeding up one type of instruction comes at the cost of slowing down something else. For example, if we put in a complicated fast floating-point unit, that takes space, and something might have to be moved farther away from the middle to accommodate it, adding an extra cycle in delay to reach that unit. The basic Amdahl’s Law equation does not take into account this trade-off.
在对处理器进行部分优化时,加速某类指令的执行往往会以降低其他部分性能为代价。例如,若增加一个复杂的快速浮点运算单元,其占用空间可能导致其他组件必须远离核心布局,进而增加一个时钟周期的访问延迟。阿姆达尔定律的基本公式并未考虑此类权衡。
(a)If the new fast floating-point unit speeds up floating-point operations by, on average, 2x, and floating-point operations take 20% of the original program’s execution time, what is the overall speedup (ignoring the penalty to any other instructions)?
翻译:"如果新的快速浮点单元平均将浮点运算速度提升2倍,且浮点运算原本占程序总执行时间的20%,那么整体加速比是多少(忽略对其他指令的影响)?"
解答:由阿姆达尔定律(优化比例为a,优化倍数为b,优化速度为加速比=),已知20%的操作(浮点运算)被加速2倍,得到整体加速比为
≈1.11倍
(b)Now assume that speeding up the floating-point unit slowed down data cache accesses, resulting in a 1.5x slowdown (or 2/3 speedup). Data cache accesses consume 10% of the execution time. What is the overall speedup now?
翻译:"现在假设加速浮点单元会降低数据缓存访问速度,导致其速度变为原来的1.5倍慢(或者说速度降至原来的2/3)。数据缓存访问原本占总执行时间的10%,此时整体加速比是多少?
解答:由阿姆达尔定律(优化比例为a,优化倍数为b,优化速度为加速比=),已知20%的操作(浮点运算)被加速2倍,同时10%操作(数据缓存操作)降速2/3,得到整体加速比为
≈1.05倍
(c)After implementing the new floating-point operations, what percentage of execution time is spent on floating-point operations? What percentage is spent on data cache accesses?
翻译:在实现新的浮点运算优化后,浮点运算占总执行时间的百分比是多少?数据缓存访问占总执行时间的百分比又是多少?
解答:设原来的总用时为t,浮点操作占20%对应0.2t,数据缓存占比10%对应0.1t,浮点操作加速2倍,用时为原来0.5倍即0.2t×0.5=0.1t;数据缓存减速2/3,用时增加为原来1.5倍,即0.1t×1.5=0.15t,没有加速的操作用时为t-0.2t-0.1t=0.7t.此时总共的时间为原来的0.7t+0.1t+0.15t=0.95t,则浮点数占总执行时间比例为0.1/0.95≈10.5%,数据缓存占总执行时间比例为0.15/0.95≈15.8%
习题1.15
题目背景:
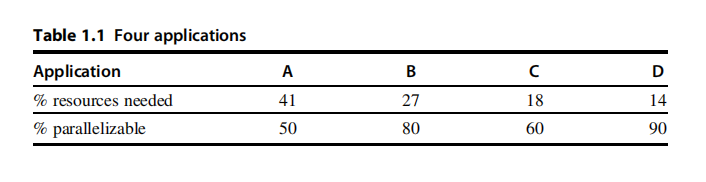
Your company has just bought a new 22-core processor, and you have been tasked with optimizing your software for this processor. You will run four applications on this system, but the resource requirements are not equal. Assume the system and application characteristics listed in Table 1.1.
贵公司新购置了一款22核处理器,您需负责对此处理器进行软件优化。该系统将运行四个应用程序,但各应用的资源需求并不均等。请基于表1.1所列系统及应用程序特性开展优化工作。
(a)How much speedup would result from running application A on the entire 22-core processor, as compared to running it serially?
翻译:与串行运行相比,将应用程序A在整个22核处理器上运行能获得多少加速比?
解答:由阿姆达尔定律(优化比例为a,优化倍数为b,优化速度为加速比=),由表1.1可知A可并行化的部分为50%,采用22核并行,提速22倍,则程序A的加速比为
≈1.91倍
(b)How much speedup would result from running application D on the entire 22-core processor, as compared to running it serially?
翻译:与串行运行相比,将应用程序D在整个22核处理器上运行能获得多少加速比?
解答:由阿姆达尔定律(优化比例为a,优化倍数为b,优化速度为加速比=),由表1.1可知D可并行化的部分为90%,采用22核并行,提速22倍,则程序A的加速比为
≈1.91倍
(c)Given that application A requires 41% of the resources, if we statically assign it 41% of the cores, what is the overall speedup if A is run parallelized but everything else is run serially?
翻译:已知应用程序A占用41%的资源,若我们静态分配41%的核心给A(使其并行化运行),而其余任务保持串行执行,此时整体加速比是多少?
解答:程序A占比41%,由题意只使用41%的核进行并行加速;一共22核,则使用22×41%≈9核,则对A程序的50%可并行部分加速9倍,则程序A的加速比为≈1.8倍,而程序A占比资源41%,则总体加速比为
≈1.22倍
(d)What is the overall speedup if all four applications are statically assigned some of the cores, relative to their percentage of resource needs, and all run parallelized?
翻译:若将四个应用程序按其资源需求比例静态分配处理器核心,且全部以并行化方式运行,此时整体加速比是多少?(相对于完全串行执行)
解答:除了(c)已经求出程序A的加速比,接着B,C,D的加速比求法如下:根据程序B,C,D资源分别占比27% 18% 14%,对应瓜分22×27%≈6核加速,22×18%≈4核加速,22×14%≈3核加速,分别可并行加速部分为80%,60%,90%,则对应加速比分别为≈3倍,
≈1.82倍,
≈2.5倍.因此整个程序加速比=
≈2.12
(e)Given acceleration through parallelization, what new percentage of the resources are the applications receiving, considering only active time on their statically-assigned cores?
翻译: 在考虑并行化加速的情况下,若仅计算应用程序在其静态分配核心上的活跃运行时间,它们实际获得的资源百分比是多少?
解答:由表1.1可知,A,B,C,D各自程序的资源占比为41% 27% 18% 14%,由(c)(d)可知对其中的可并行部分(分别占比为50%,80%。60%,90%)分别进行9核,6核,4核,3核的加速,则对应实际每个程序优化后占原来资源百分比=不可并行部分+可并行部分/并行数得,41%×50%+41%50%/9≈22.78%,27%×20%+27%80%/6≈ 9%,18%×40%+18%60%/4≈9.9%, 14%×10%+14%×90%/3≈5.6%,因此优化后总共占比原来所需运行的22.78%+9%+9.9%+5.6%=47.28%,因此A B C D对应实际资源占比(有效的运转时间)为22.78%/47.88≈48.18%,9%/47.88%≈19.04%,9.9%/47.88%≈20.94%,5.6%/47.88%≈11.84%
习题1.16
题目背景:
When parallelizing an application, the ideal speedup is speeding up by the number of processors. This is limited by two things: percentage of the application that can be parallelized and the cost of communication. Amdahl’s Law takes into account the former but not the latter
在并行化应用程序时,理想加速比为处理器数量倍数的提速。这受到两个因素的限制:应用程序中可并行化的比例以及通信开销。阿姆达尔定律考虑了前者,但未考虑后者。
(a)What is the speedup with N processors if 80% of the application is parallelizable, ignoring the cost of communication?
翻译:如果应用程序的 80% 可以并行化,并且忽略通信开销,那么使用 N 个处理器时的加速比是多少?
解答:由阿姆达尔定律(优化比例为a,优化倍数为b,优化速度为加速比=),加速部分占比80%,N个处理器提速N倍,因此整体加速比=
(b)What is the speedup with eight processors if, for every processor added, the communication overhead is 0.5% of the original execution time.
翻译:如果每增加一个处理器,通信开销就占原始执行时间的 0.5%,那么使用 8 个处理器时的加速比是多少?
解答:阿姆达尔定律的本质为原始所用时间/加速后所用时间,如果令原始时间为t,则加速后的时间由题意可以分为三部分-----未加速部分所花的时间,加速部分所化时间,通信开销增加的额外时间。由提议得8核并行,加速8倍(加速比例同(a)),每个处理器并行增加0.5%时间开销,因此新的时间可以算出为(1-0.8)t+0.8t/8+0.005×8t=0.34t,因此加速比为1/0.34≈2.94
(c)What is the speedup with eight processors if, for every time the number of processors is doubled, the communication overhead is increased by 0.5% of the original execution time?
翻译:如果处理器数量每翻一倍,通信开销就增加原始执行时间的0.5%,那么使用8个处理器时的加速比是多少?
解答:仍然使用阿姆达尔定律的本质定义(原始所用时间/加速后所用时间),原始时间为t,对应得加速后也为三部分(未加速,加速,通信开销),但是通信开销得定义改为处理器每翻一倍通信通信开销增加0.5%,因此对应得通信开销部分为log8×0.005=3×0.005t,因此新的时间可以算出为(1-0.8)t+0.8t/8+0.005×3t=0.315t,因此加速比为1/0.315≈3.17
(d)What is the speedup with N processors if, for every time the number of processors is doubled, the communication overhead is increased by 0.5% of the original execution time?
翻译:若处理器数量每增加一倍,通信开销就增长原始执行时间的0.5%,那么使用N个处理器时的加速比是多少?
解答:由(c)可以推广得新的时间可以算出为(1-0.8)t+0.8t/N+0.005×logN×t,因此N个处理器对应加速比为1/(0.2+0.8/N+0.005logN)
(e)Write the general equation that solves this question: What is the number of processors with the highest speedup in an application in which P% of the original execution time is parallelizable, and, for every time the number of processors is doubled, the communication is increased by 0.5% of the original execution time?
翻译: 试写出通用方程以求解以下问题:在一个原始执行时间中有P%可并行化的应用中,当处理器数量每翻倍一次,通信开销就增加原始执行时间的0.5%时,可获得最高加速比的处理器数量是多少?
解答:设加速比为y,根据题目,我们要构造加速比在给定可并行部分p,关于处理器数量N得函数,即y=f(N)函数,并求导使得y'=0时候,所对应得N值(极值点)。就为最高加速比获取的位置。根据(d)降0.8的固定比例换为任意0到1的常数p,则y=1/(1-p+p/N+0.005logN),对y=f(N)求导,得到y'=,令y'=0,则
=0,解得N=
时候满足y’=0,为唯一极值点,因此当处理器N为
时候可以认为取得最大加速比。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









