







| 一、Lucene版本的选择 |
首先在我打算学习Lucene,在我开始写这个系列的文章的时候Lucene已经出了6.2.0。但是我学习的版本是3.5.0,之所以选择这个版本是因为郑浩老师有一个视频讲解,能带我从具体的实践中了解Lucene,为了不陷入到版本的不兼容的泥潭中,我打算学习Lucene3.5.0,弄明白了具体的原理和操作,在学习新的版本。
解压后的Lucene3.5.0的文件夹的内容如下图:
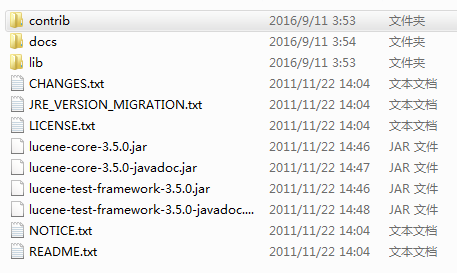
对于初学者,知道只需要知道两个jar包:
1. lucene-core-3.5.0.jar包,这个是Lucene的主要功能包。
2. lib文件夹下面的junit的jar包,做单元测试使用。尽量使用lucene压缩包中的junit,不然会出现版本不兼容的问题。
还要了解docs文件夹下的index.html,这个是对应版本的Lucene的API说明文档,很有用。
| 二、HelloLucene工程创建 |
看一下HelloLucene的工程目录:
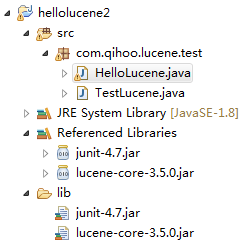
其中lib文件夹下存放的是需要用到的两个jar包,Referenced Libraries 中是通过 add build path 生成的。
| 三、HelloLucene建立索引 |
索引的建立就是针对原始的数据生成一个用于检索的索引,这个索引可以存储在内存中,也可以存储在硬盘上。
public void index() {
IndexWriter writer = null;
try {
//1、创建Directory
//Directory directory = new RAMDirectory(); //将索引建立在内存中
Directory directory = FSDirectory.open(new File("d:/lucene/index01"));
//2、创建IndexWriter
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35));
writer = new IndexWriter(directory, conf);
//3、创建文档Document对象
Document doc = null;
//4、为文档Document添加域Field
File f = new File("d:/lucene/example");
for(File file: f.listFiles()) {
doc = new Document();
doc.add(new Field("content", new FileReader(file)));
doc.add(new Field("filename", file.getName(), Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("path", file.getAbsolutePath(), Field.Store.YES, Field.Index.NOT_ANALYZED));
//5、通过IndexWriter添加文档到索引中
writer.addDocument(doc);
} //for
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if(writer != null)
try {
writer.close();
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} //index()
| 四、Lucene通过索引检索 |
索引建立之后,接下来就是通过索引对数据进行检索:
public void searcher() {
try {
//1、创建Directory
Directory directory = FSDirectory.open(new File("d:/lucene/index01"));
//2、创建IndexReader
IndexReader reader = IndexReader.open(directory);
//3、根据IndexReader创建IndexSeacher
IndexSearcher searcher = new IndexSearcher(reader);
//4、创建搜索的query
// 创建parser来确定要搜索的文件的内容,第二个参数表示文件的域
QueryParser parser = new QueryParser(Version.LUCENE_35, "content", new StandardAnalyzer(Version.LUCENE_35));
//创建query,表示搜索域content中包含java的文档
Query query = parser.parse("language");
//5、根据searcher搜索并且返回TopDocs
TopDocs tds = searcher.search(query, 10);
//6、根据TopDocs获取ScoreDoc对象
ScoreDoc[] sds = tds.scoreDocs;
for(ScoreDoc sd: sds) {
//7、根据searcher和ScoreDoc对象获取具体的Document对象
Document d = searcher.doc(sd.doc);
//8、根据Document对象获取需要的值
System.out.println(d.get("filename") + "[" + d.get("path") + "]");
}
//9、关闭reader
reader.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
} // searcher()
注意:整个工作流程很简单,建立索引的过程就是读取磁盘上的某一个目录,然后依次对该目录中的文件建立索引,把索引存储在硬盘的一个目录中。检索的过程就是读取这个索引目录的过程。
在建立索引的时候,content 这个域仅仅是读取了文件,没有指定是否存储,通过看Field的源代码可以发现默认是不存储、要索引、要分词的。所以检索的时候可以在content 中检索language 这个检索关键词,并等得到相应的文档,但是得到的文档不能通过d.get("content") 得到文档的内容,因为索引文件中没有存储这个域的原始数据。
Lucene的三个大的步骤就是:
- 建立索引
- 分词
- 检索
具体的一些概念,这里先不讲,本文只是针对Lucene做一个实战的认知,有了实战的认知之后,在讲述原理的部分才不会那么枯燥。
说明几个Eclipse的快捷键:
- shift+ctrl+o:快速导入包名(前提已经build path)
- ctrl + /:快速添加注释
- alt + /:自动不全或者提示补全

















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









