







Arraylist优点(查询快,增删慢)
ArrayList缺点(增删慢,查询快)
其实想要明白这两点也比较简单,那就是对数据结构(数组有一个了解),每个数据结构都有它自身的时间空间复杂度,这就表示着效率问题类似于O(1),O(n),O(logn)这些就是复杂度,还有就是Java实现方式层面,本篇就从这几个层面来讲效率性能问题
第一部分 :数组(数据结构)
在数据结构一书中提到:数组可看作是一种扩展的线性数据结构,其特殊性不像栈与队列那样反应在对数据元素的操作方面受限,而是反应在数据元素的构成上。从组成线性表的元素角度分析,数组具有某种结构的数据元素构成,数组就是线性表的推广。
言归正传:
数组是我们都非常熟悉的数据结构,高级语言一般都支持这种数据类型。
数组是线性表,就是数据排成像一条直线一样的结构,除了数组,像链表,队列,栈都是线性结构
而非线性表就是二叉树,堆,图等,数据之间不是简单的先后关系
数组和链表的关系?
我们通常会回答:链表适合插入,删除,时间复杂度为O(1);数组适合查找,查找时间复杂度是O(1)
实际上,这种表达是不准确的,数组是适合查找,但是查找的时间复杂度并不是O(1).所以,正确的表述是,数组支持随机访问,根据下表(索引位子)随机访问的时间复杂度是O(1)
具体的数据结构数组方面的知识可以去翻一翻具体的书籍去涉猎一下,数组在计算机中的存储和计算方式等都是可以研究和学习一下的,对于深入理解作者的为什么要这么去选型以及设计会有很大的帮助,也有利于理解我们所提问的为什么?
第二部分:从ArrayList源码层面分析
上面已经说了一些关于数组的一些知识,现在肯定对数组会有一定的理解,其实不理解太深入也没关系,知道数组的固定特性就够了,所以说,arraylist底层就是基于数组进行实现的,所以我们现在肯定就明白为什么arraylist为什么会增删快查询慢了,下面从源码的角度进行分析这一点:
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
//入参为索引值,也就是下标
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
上面这段代码就是arraylist的源码实现,因为底层就是基于数组去实现的,数组的特性也是查询快增删慢,现在是直接根据下标进行获取数据,所以时间复杂度是O(1),而且arraylist实现了RandomAccess接口,支持随机访问,这就明确说了一点,查询效率是非常快的。
增删慢这个问题就可以深究一下了,话不多说:看源码可能更有助于理解数组数据结构
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
@SuppressWarnings("unchecked")
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);上述是往数组末尾添加元素的数据,时间复杂度没什么影响,只会验证一个扩容操作(在扩容过程中也是耗费性能的操作),用一张图形象描述一下:

但是如果指定位置添加就会非常影响性能了。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//在这一步执行native声明的方法的时候,就是耗费时间和性能的一步操作了,在底层具体的实现方式是这样的
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}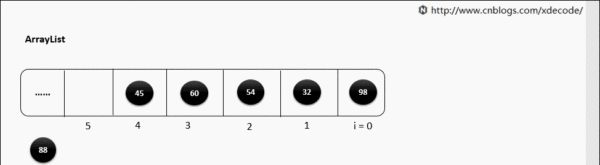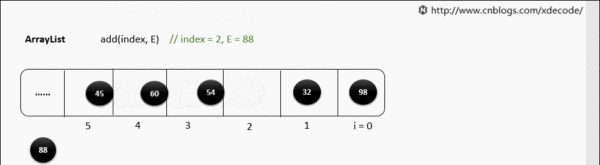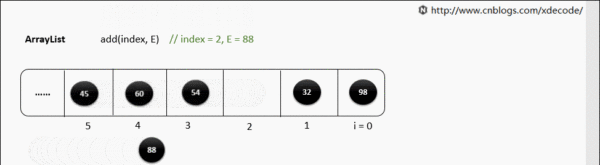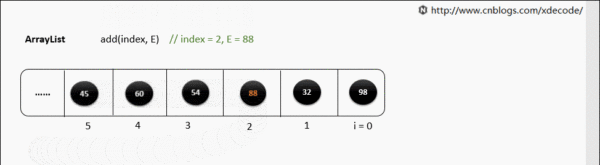
现在解释一下,之所以性能比较低,就是因为在每一次添加元素的时候,比如在位置2处添加元素,位置1之后的元素都要往后移动,移动的过程是影响性能的,就是上述代码中的arrayCopy这一步操作,而且扩容的验证一样也是会存在的。
remove方法:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}看下上述源码应该就很清楚了,这和add方法其实就是大同小异的,下面用张从动图来描述一下:

现在应该对于arrayList的查询快增删慢有一个很好的理解了吧,如果有描述的不对的地方,一起交流。可能本篇对数组的讲述不是特别的详细,如果不懂得,可以自己去学习一下,以后我会把基本的数据结构的一些内容补充进来。















 7320
7320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









