






 文章描述了一个开发者使用Python和PyPDF2库开发了一个简单的PDF拆分工具,用户可以选择按页、按文件大小或页码范围拆分PDF,且提供了一个包含文件选择、输出目录选择和开始拆分功能的界面。
文章描述了一个开发者使用Python和PyPDF2库开发了一个简单的PDF拆分工具,用户可以选择按页、按文件大小或页码范围拆分PDF,且提供了一个包含文件选择、输出目录选择和开始拆分功能的界面。
在训练我的"大模型应用-玄助"(支持文本检查,文件翻译,人像转动漫,表格识别,语音合成)时,我发现自己的知识集合需要拆分成一个个小文件。而这个大模型应用的要求是,每个文件大小不能超过20M。在网上找了一圈,我发现大部分的PDF拆分工具都需要付费,最少的也要3元。于是我心想,既然如此,不如自己动手,代码如下:
一、提供了一个简单的页面进行选择:
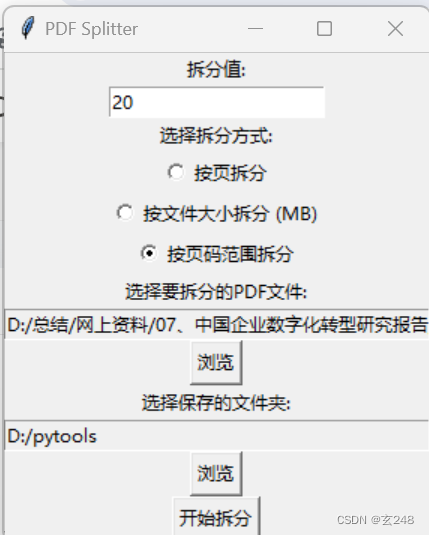
import PyPDF2
import tkinter as tk
from tkinter import filedialog
import os
class PDFSplitterApp1:
def __init__(self, filepath):
self.root = filepath
self.root.title("PDF Splitter")
self.input_filepath = tk.StringVar()
self.output_folder = tk.StringVar()
self.split_type = tk.StringVar()
self.split_type.set("pages") # 默认按页拆分
self.split_value = tk.StringVar()
self.split_value_label = tk.Label(filepath, text="拆分值:")
self.split_value_label.pack()
self.split_value_entry = tk.Entry(filepath, textvariable=self.split_value)
self.split_value_entry.pack()
self.split_options_label = tk.Label(filepath, text="选择拆分方式:")
self.split_options_label.pack()
self.pages_radio = tk.Radiobutton(filepath, text="按页拆分", variable=self.split_type, value="pages")
self.pages_radio.pack()
self.size_radio = tk.Radiobutton(filepath, text="按文件大小拆分 (MB)", variable=self.split_type, value="size")
self.size_radio.pack()
self.range_radio = tk.Radiobutton(filepath, text="按页码范围拆分", variable=self.split_type, value="range")
self.range_radio.pack()
self.input_label = tk.Label(filepath, text="选择要拆分的PDF文件:")
self.input_label.pack()
self.input_entry = tk.Entry(filepath, textvariable=self.input_filepath, width=40, state='readonly')
self.input_entry.pack()
self.browse_button = tk.Button(filepath, text="浏览", command=self.browse_file)
self.browse_button.pack()
self.output_label = tk.Label(filepath, text="选择保存的文件夹:")
self.output_label.pack()
self.output_entry = tk.Entry(filepath, textvariable=self.output_folder, width=40, state='readonly')
self.output_entry.pack()
self.browse_output_button = tk.Button(filepath, text="浏览", command=self.browse_output_folder)
self.browse_output_button.pack()
self.split_button = tk.Button(filepath, text="开始拆分", command=self.split_pdf)
self.split_button.pack()
def browse_file(self):
file_path = filedialog.askopenfilename(filetypes=[("PDF files", "*.pdf")])
self.input_filepath.set(file_path)
def browse_output_folder(self):
folder_path = filedialog.askdirectory()
self.output_folder.set(folder_path)
def split_pdf(self):
input_filepath = self.input_filepath.get()
output_folder = self.output_folder.get()
split_value = self.split_value.get()
# 添加检查,确保文件路径不为空
if not input_filepath:
tk.messagebox.showerror("错误", "请选择要拆分的PDF文件")
return
# 添加检查,确保文件存在
if not os.path.isfile(input_filepath):
tk.messagebox.showerror("错误", "选择的PDF文件不存在")
return
# 添加检查,确保输出文件夹不为空
if not output_folder:
tk.messagebox.showerror("错误", "请选择保存的文件夹")
return
# 添加检查,确保拆分值不为空
if not split_value:
tk.messagebox.showerror("错误", "请输入拆分值")
return
try:
split_value = int(split_value)
if split_value <= 0:
raise ValueError("拆分值必须为正整数")
except ValueError as e:
tk.messagebox.showerror("错误", f"无效的拆分值:{str(e)}")
return
pdf_reader = PyPDF2.PdfReader(input_filepath)
if self.split_type.get() == "pages":
self.split_by_pages(pdf_reader, output_folder, split_value)
elif self.split_type.get() == "size":
self.split_by_size(pdf_reader, output_folder, split_value)
elif self.split_type.get() == "range":
print(split_value)
start_page, end_page = self.get_page_range(pdf_reader, split_value)
self.split_by_range(pdf_reader, output_folder, start_page, end_page)
tk.messagebox.showinfo("拆分完成", "PDF拆分完成!")
def split_by_pages(self, pdf_reader, output_folder, split_value):
total_pages = len(pdf_reader.pages)
for page_start in range(0, total_pages, split_value):
page_end = min(page_start + split_value, total_pages)
pdf_writer = PyPDF2.PdfWriter()
for page_num in range(page_start, page_end):
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filepath = f"{output_folder}/pages_{page_start + 1}-{page_end}.pdf"
with open(output_filepath, 'wb') as output_file:
pdf_writer.write(output_file)
def split_by_size(self, pdf_reader, output_folder, split_value):
total_pages = len(pdf_reader.pages)
# 计算每页的大小
pdf_stream = pdf_reader.stream
pdf_stream.seek(0, 2) # 将流的位置移到文件末尾
total_size_bytes = pdf_stream.tell()
page_size_bytes = total_size_bytes / total_pages
# 计算拆分的页数
bytes_per_file = int(split_value * 1024 * 1024) # 转换为字节
pages_per_file = int(bytes_per_file / page_size_bytes)
current_page = 0
while current_page < total_pages:
pdf_writer = PyPDF2.PdfWriter()
for page_num in range(current_page, min(current_page + pages_per_file, total_pages)):
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filepath = f"{output_folder}/split_{current_page + 1}-{current_page + len(pdf_writer.pages)}.pdf"
with open(output_filepath, 'wb') as output_file:
pdf_writer.write(output_file)
current_page += len(pdf_writer.pages)
def split_by_range(self, pdf_reader, output_folder, start_page, end_page):
for page_num in range(start_page - 1, end_page):
pdf_writer = PyPDF2.PdfFileWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filepath = f"{output_folder}/pages_{page_num + 1}.pdf"
with open(output_filepath, 'wb') as output_file:
pdf_writer.write(output_file)
if __name__ == "__main__":
root = tk.Tk()
app = PDFSplitterApp1(root)
root.mainloop()
















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









