







7.7.2.1 G - FAM概述
- G - FAM是一种高度可扩展的内存资源,CXL 架构内所有主机和对等设备都可访问。其范围可专门分配给单个主机 / 对等请求者,也可由多个主机 / 对等方共享。共享时,多请求者缓存一致性可由软件或硬件管理。对 G - FAM 范围的访问权限由请求者边缘端口的解码器和目标 GFD 强制实施。
- GFD HDM 空间:主机 / 对等方可通过 CXL.mem 从多个域访问,对等设备可通过 CXL.io UIO 从多个域访问。GFD(Generic Fabric Device 通用结构设备) 不实现 PCIe 配置空间,而是通过边缘 USPs 中的全局内存访问端点(GAE)或带外机制进行配置和管理。
- GFD 与 MLD 区别:MLD 为每个主机 / 对等接口(LD)有单独的设备物理地址(DPA)空间,而 GFD 有一个对所有主机和对等设备通用的 DPA 空间。GFD 使用存储在 GFD 解码器表中的请求前转换信息,将每个传入请求中的主机物理地址(HPA)转换为 DPA。为创建共享内存,可将两个或更多 HPA 范围(来自不同请求者)映射到相同 DPA 范围。当 GFD 需要发出 BISnp (back - invalidator snoop )时,会使用相同的 GFD 解码器信息将 DPA 转换为关联主机的 HPA。
- 请求处理:GFD 通过请求中的 SPID 识别请求者,称为请求者 PID 或 RPID ,这在描述 GFD 发送给请求者的消息时可避免混淆。
- 内存管理机制:GFD 上的所有内存容量都由动态容量(DC)机制管理。每个请求者最多可访问 8 个不重叠的 RPID(Requester PID,请求者 PID) 解码器,每个 SPID 的最大解码器数量取决于具体实现。每个解码器有从 HPA 空间到通用 DPA 空间的转换,还标记了缓存一致性维护方式(软件或硬件),以及多 GFD 交错信息(若使用)。请求者可通过 FM 在 DPA 空间定义 DC 区域,并将信息传达给主机上的 GAE,以映射主机程序访问所需的 DC 区域。
- G - FAM 内存范围交错:G - FAM 内存范围可以在 2 到 256 个 GFD 间交错,交错粒度有 256B、512B、1KB、2KB、4KB、8KB 或 16KB。位于 CXL 架构内任何位置的 GFD 都可为交错集提供内存。
- UIO 相关支持:如果 GFD 支持 UIO Direct P2P 到 HDM,所有 GFD 端口都应支持 UIO。对于每个其链路伙伴也支持 UIO 的 GFD 端口,应自动启用 VC3 。
-
7.7.2.2 host物理地址视图
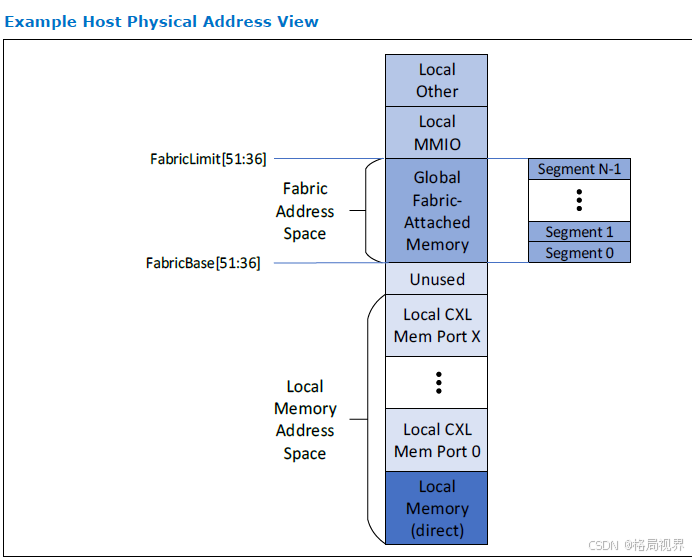
- 地址范围分配:主机访问 G - FAM,需在主机物理地址(HPA)空间内,分配一段连续的结构地址空间,该空间范围由 FabricBase 和 FabricLimit 寄存器确定。处于此范围内的主机请求,会被路由到选定的 CXL 端口。多 CXL 端口访问 G - FAM 的主机,可选择交错请求地址,或为每个端口单独分配结构地址空间。
- 地址分段处理:主机发往 G - FAM 的请求会流向 PBR Edge USP。在 USP 中,结构地址范围被划分为 N 个等大的段,段大小是 2 的幂次方,介于 64GB 到 8TB 之间,且需自然对齐。交换机实现的段数量因具体情况而异。主机软件要配置段大小,保证段数与段大小的乘积能覆盖整个结构地址空间,FabricBase 和 FabricLimit 寄存器能按段大小倍数编程。
- 段与设备关联及请求路由:每个段关联一个 GFD 或一组交错的 GFD。HPA 在段内的请求,会被路由到指定 GFD 或交错集中的 GFD。段仅用于请求路由,可能比 GFD 可访问部分大。此时,GFD 可访问部分从段内地址偏移 0 开始,段内超出 GFD 可访问部分的请求,在 GFD 中无法正确解码,按 8.2.4.20 节处理。
- 交错关系:主机跨根端口交错和 GFD 交错相互独立,用于两者的地址位可能完全重叠、部分重叠或不重叠。主机使用根端口交错时,对应 PBR Edge USP 中的 FabricBase、FabricLimit 和段大小必须配置一致 。
- 7.7.2.3 G-FAM 容量管理
1.1.3 G-FAM容量管理
- GFD 的管理与消息格式:GFD 和其他所有类别的 CXL 组件一样,使用 CCIs(组件控制接口)进行管理。GFD 在其 CXL 链路上需要支持 7.7.11.6 节中定义的 PBR 链路 CCI 消息格式,也可选择性地实现额外的基于 MCTP(平台控制管理协议)的 CCIs(如 SMBus)。
- G-FAM 的容量管理:G-FAM 完全依赖动态容量(DC)机制进行容量管理(见 8.2.10.9.9 节),GFD 没有第 9.0 章图 9-24 左侧所示的 “传统” 静态容量。G-FAM 的动态容量与 LD-FAM 的动态容量有很多共同之处,包括 DC Region、范围和块的概念相同;每个主机 / 对等接口最多支持 8 个 DC Region;CDAT(相干设备属性表)中与 DC 相关的参数相同;邮箱命令高度相似,但具体邮箱访问方法差异很大(LD-FAM 通过 LD 结构访问每个主机的 LD 的邮箱,G-FAM 中每个主机的管理见 7.7.2.6 节GAE)。
- 内存分配与绑定差异:LD-FAM DCD在一次操作中分配内存容量并将其绑定到特定主机 ID;GFD 则在一次操作中将动态容量分配给一个命名的内存组,并在单独的操作中将特定主机 ID 绑定到命名的内存组,因此 GFD 需要与 LD-FAM DCD 不同的 DCD 管理命令。
- DPA 空间与 DMP:与 LD-FAM 不同,每个 GFD 只有单一的 DPA(设备物理地址)空间,而非每个主机一个单独的 DPA 空间。G-FAM 的 DPA 空间由设备介质分区(DMPs)组织(见图 7-30)。DMP 是具有特定属性的 DPA 范围,基本属性包括介质类型(如 DRAM 或 PM),由 FM 配置的一个属性是 DC 块大小,DMP 公开了所有可分配给主机使用的 GFD 内存。DMP 的规则为:每个 GFD 包含 1 - 4 个由 FM 配置大小的 DMP;每个 DC Region由分配给主机 / 对等方的一个 DMP 的部分或全部组成,每个 DC Region可使用 GFD 解码器表映射到 RPID 的 HPA 空间;每个 DC Region继承相关的 DMP 属性。
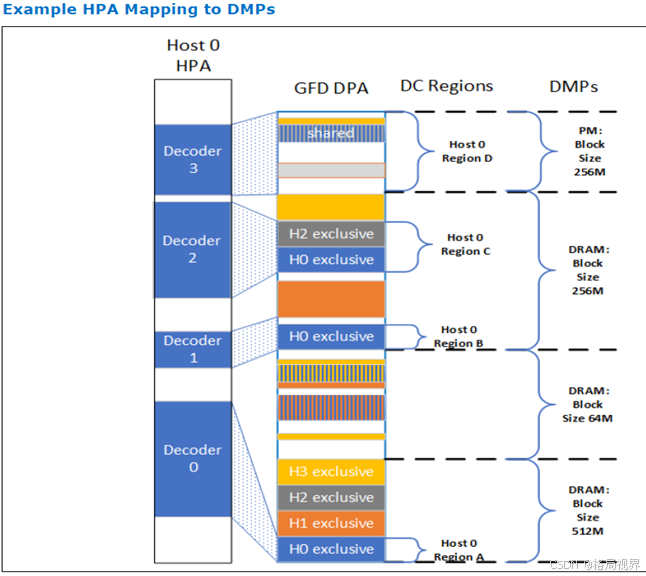


LD(多逻辑设备)和 GFD(全局结构设备)在处理请求的方式上存在额外差异:
- MLD 处理请求的方式:MLD 有三种类型的解码器,对传入请求按顺序进行操作。
- 每个逻辑设备(LD)的 HDM 解码器将主机物理地址(HPA)空间转换为每个 LD 的设备物理地址(DPA)空间,并去除交织位。
- 每个 LD 的解码器确定 DPA 位于哪个LD 的动态容量(DC) Region内,然后判断该 Region内被寻址的 DC 块是否可被该 LD 访问。
- 每个 LD 根据具体实现的解码器将 DPA 转换为介质地址。
- GFD 处理请求的方式:GFD 有两种类型的解码器,对传入请求按顺序进行操作。
- 每个请求者 PID(RPID)的 GFD 解码器将 HPA 空间转换为通用的 DPA 空间,并去除交织位。这个 DPA 可以直接用作介质地址,也可以通过简单映射后使用。
- 一个通用解码器确定 DPA 位于哪个设备介质分区(DMP)内,然后判断在该 DMP 内被寻址的块是否可被 RPID 访问。
1.1.4 G-FAM FAST and GDT Decoder
GFD(全局结构设备)在边缘入口端口和其自身内部的请求路由、交织以及地址转换机制在下图中展示,GFD 的请求可能来自主机并到达边缘上游端口(Edge USP),或者来自对等设备并到达边缘下游端口(Edge DSP),并将其统称为边缘请求端口。
边缘请求端口需要对请求的主机物理地址(HPA)进行解码,通过使用结构地址段表(FAST)和交织设备物理地址表(IDT)来确定目标全局结构设备(GFD)的设备物理地址标识符(DPID)。FAST 中每个段有一个表项,其深度必须是 2 的幂次方且取决于具体实现。段大小由 FSegSz [2:0] 寄存器指定(见表 7-81)。所访问的 FAST 表项由请求地址的 X:Y 位确定,其中 Y 是段大小(以字节为单位)的以 2 为底的对数,X = Y + FAST 深度(以表项为单位)的以 2 为底的对数。对于一些示例 FAST 深度和所有支持的段大小,最大的结构地址空间以及用于寻址 FAST 的 HPA 位见表 7-81。对于具有 52 位 HPA 的主机,最大结构地址空间是 4PB,在结构地址空间上方和下方各减去一个用于本地内存和 MMIO 的段(如图 7-29 所示)。

- FAST解码器:FAST与LD - FAM段表(LDST)解码器功能基本相同,仅有少数例外。每个结构地址段表(FAST)表项包含一个有效位(V)、交织方式数量(Intlv)、交织粒度(Gran)以及一个设备物理地址标识符(DPID)或交织设备物理地址表(IDT)索引(DPID/IX)。其中,Intlv 和 Gran 字段的编码分别在表 7-82 和表 7-83 中定义。如果主机物理地址(HPA)处于结构基地址(FabricBase)和结构限制地址(FabricLimit)之间(包含这两个端点),并且 FAST 表项的有效位被置位,那么就会出现 FAST 命中情况,此时使用 FAST 来确定 DPID。否则,目标设备将由其他符合架构的解码器来确定。
- 请求发送与解码器选择:确定全局结构设备(GFD)的设备物理地址标识符(DPID)后,将包含边缘请求端口的源 PID(SPID)和未修改的主机物理地址(HPA)的请求发送到目标 GFD。GFD 使用 SPID 访问 GFD 解码器表(GDT),选择与请求者关联的解码器。由于主机及其相关 CXL 设备各有唯一的请求者 PID(RPID),会使用 GDT 中不同表项,GDT 每个 RPID 最多提供 8 个解码器,每个解码器包含 8.2.10.9.10.19 节定义的结构。
- 请求命中判断与处理:GFD 并行地将请求 HPA 与所有解码器比较,判断是否命中。通过计算 DPA 偏移量(HPA 减去 HPABase 并去除交织位,去除交织位的最低有效位由交织粒度决定,去除位数由交织方式数量决定),若偏移量在有效范围内且有效位设置,则请求命中该解码器。若只有一个解码器命中,计算 DPA(DPABase 加上偏移量);若零个或多个解码器命中,返回访问错误。
- 动态容量访问检查与窥探过滤器操作:请求 HPA 转换为 DPA 后,使用 RPID 和 DPA 进行动态容量访问检查(见 7.7.2.5 节)并访问 GFD 窥探过滤器(其设计不在本规范范围内)。当窥探过滤器需向主机 / 对等方发出回写无效(back-invalidate)时,反向执行 HPA 到 DPA 的步骤将 DPA 转换为 HPA。使用 RPID 访问 GDT 选择请求者的解码器,并行比较 DPA 与所选解码器判断是否命中。通过计算 DPA 偏移量判断命中情况,若只有一个解码器命中,计算 HPA(插入交织位并加上 HPABase,插入交织位的相关参数由交织粒度、交织方式数量和交织集中的方式决定);若零个或多个解码器命中,视为内部窥探过滤器错误,未来规范更新中定义处理方式。
- 回写无效消息发送:计算出 HPA 后,使用窥探过滤器中存储的 PID 作为 DPID,将包含 GFD 的 SPID 和 HPA 的回写无效消息(BISnp)发送到包含拥有此 HDM-DB Region的主机 / 对等方的 FAST 解码器的边缘端口。FAST 解码器可选择检查 HPA 是否在其结构地址空间内,然后去除 DPID 和 SPID,以 HBR 格式将 BISnp 发送给主机 / 对等方。
1.1.5 G-FAM Access Protection
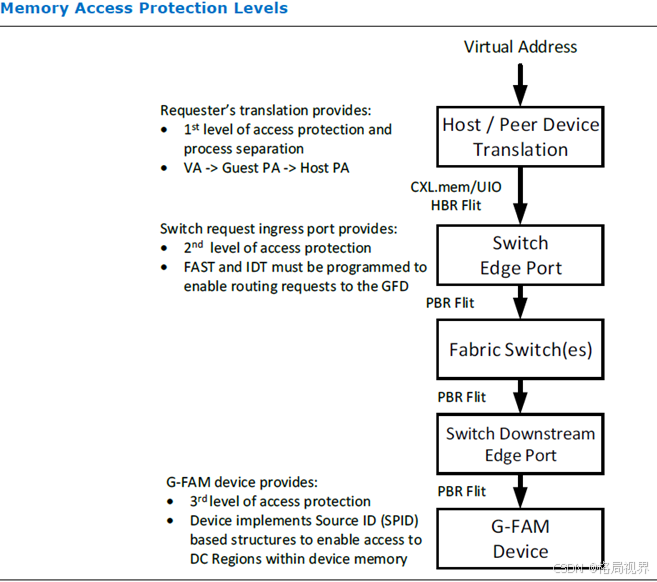
G - FAM(全局结构连接内存)的访问保护存在于层次结构的三个级别(见图 7-32):
第一级保护:通过主机(或对等设备)的页表来实现。这种细粒度的保护用于将每个进程可访问的结构地址空间限制在主机 / 对等设备可访问的结构地址空间的一个子集内。
第二级保护:以全局内存映射向量(GMV)的形式在全局内存访问端点(GAE)中体现,具体内容在 7.7.2.6 节中描述。
第三级保护:位于目标全局结构设备(GFD)自身,且属于细粒度保护。本部分内容主要介绍的就是 GFD 的这第三级保护。
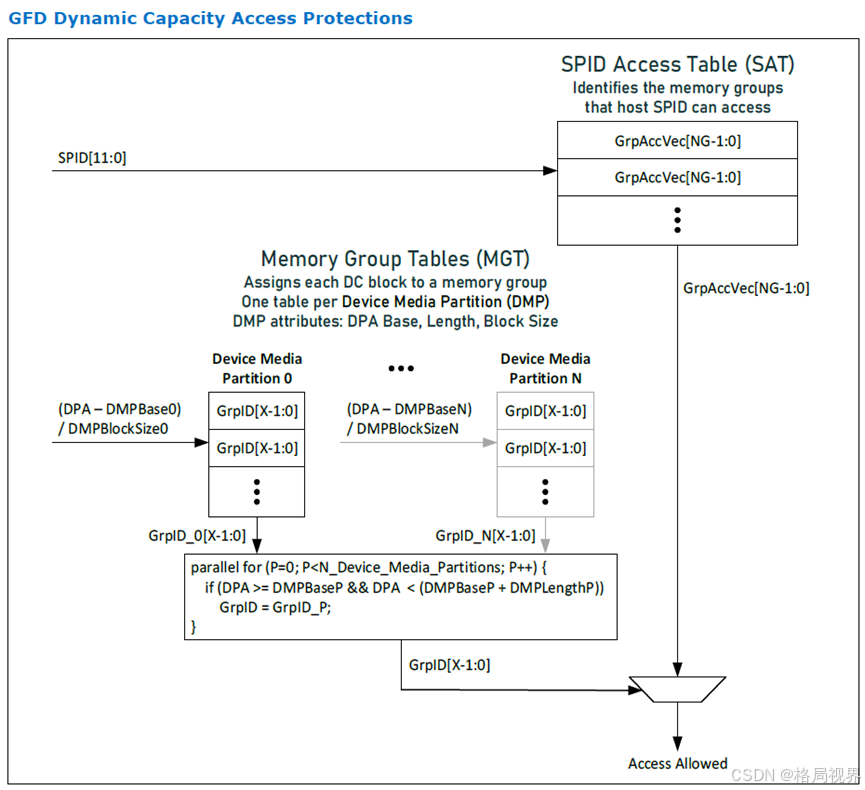
- GFD 的 DPA 空间与 DMP:全局结构设备(GFD)的设备物理地址(DPA)空间被划分为一个或多个设备介质分区(DMP)。每个 DMP 由 DPA 空间内的基地址(DMPBase)、长度(DMPLength)和块大小(DMPBlockSize)定义。DMPBase 和 DMPLength 必须是 256MB 的倍数,DMPBlockSize 必须是 2 的幂次方字节大小,设备支持的 DMPBlockSize 值因设备而异,在 GFD 支持的块大小掩码寄存器中定义。每个 GFD 解码器针对单个 DMP 内动态容量(DC) Region的 DPA 范围(即不能跨越 DMP 边界),DC Region的块大小由相关 DMP 的块大小决定,DMP 的数量取决于设备的具体实现。通常,不同的 DMP 用于不同的介质类型(如 DRAM、NVM 等),并提供足够的 DC 块大小以满足客户需求。
- GFD 动态容量保护机制与内存组:GFD 的动态容量保护机制如图 7-33 所示。为了支持扩展到 4096 个 CXL 请求者,GFD 的 DC 保护机制采用了一种称为内存组(Memory Groups)的概念。内存组是一组可被同一组请求者访问的 DMP 块。GFD 支持的最大内存组数量(NG)取决于具体实现。每个 DMP 块通过一组内存组表(MGT)被分配一个内存组 ID(GrpID),每个 DMP 对应一个 MGT。每个 MGT 中每个 DMP 块有一个表项,MGT 中的表项 0 对应 DMP 中的块 0,每个 MGT 的深度取决于具体实现。对 DPA 进行解码以确定请求属于哪个 DMP,然后使用该 DMP 的 MGT 来确定 GrpID,GrpID 的宽度 X = 上限(以 2 为底对 NG 取对数)位。例如,一个有 33 到 64 个组的设备需要 6 位的 GrpID。
- 访问权限判断:在确定请求的 GrpID 的同时,请求的源PID(SPID)用于索引 SPID 访问表(SAT),生成一个向量来标识该 SPID 被允许访问的内存组(GrpAccVec)。确定请求的 GrpID 后,使用 GrpID 选择 GrpAccVec 中的一位来判断访问是否被允许。
- Note of MGT:建议设备在每个内存组表(MGT)中至少实现 1K 个表项。在实现方式上,既可以为每个 MGT 选择使用单独的随机存取存储器(RAM),也可以为所有的 MGT 使用一个分区的 RAM。关于内存组数量的建议:为了支持足够数量的具有不同主机访问列表的内存范围,建议设备至少实现 64 个内存组。
1.1.5 Global Memory Access Endpoint
- 全局内存访问端点(GAE)的作用和性质:通过基于端口的路由(PBR)结构边缘交换机对 G-FAM(全局结构连接内存)/GIM(全局互连内存)资源的访问以及对结构地址段表(FAST)的配置,是由全局内存访问端点(GAE)来辅助实现的。GAE 是一种邮箱组件控制接口(CCI),支持全局内存访问端点命令集以及配置和启用 FAST 使用所需的操作码,包括获取 PID 访问向量和配置 FAST。GAE 作为具有 7.2.9 节中定义的 0 型配置空间的 PCIe 端点呈现给主机。
- 主机边缘端口 USP 暴露 GAE 的两种配置之一:主机边缘端口上游端口(USP)会在两种配置下暴露 GAE。第一种配置如图 7-34 所示,为主机提供基于逻辑设备的 FAM(LD-FAM)以及 G-FAM/GIM 资源。在此配置中,GAE 邮箱 CCI 用于为 USP 以及连接到端点(EP)的任何下游端口(DSP)配置 G-FAM/GIM 访问权限,还可能包括支持管理提供 LD-FAM 资源的 CXL 交换机功能所需的操作码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









