






背景色表示可以自己做实验搞定
1 入 限定符 'one'
2 入 'two'
3 入 'three'
4 four
5 five...

HBase 存储,分裂。算法的精妙在何处? 求大神
答:当看书到 HBase 底层的时候就不需要大神来回答了 = =! 。。。。
因为HBase 底层用了 LSM树。 LSM 树 大部分都在内存处理增删改。 当内存中数据达到一定阈值的时候,才会从左至右遍历内存树子节点 与 磁盘树子节点合并。 当被合并的数量达到磁盘存储页大小(个人理解为 MemStore 达到一定量)时。才会被 DFS Clinet 持久化到 HDFS 磁盘上,同时更新父节点对子节点的指针,并且 同步内存树 与 磁盘树 非子节点的节点。增加寻道命中率。
2 版本取数据问题。
Rowkey、Column、Version 组合在一起称为HBase的一个单元格。
HBase 中 ,版本是按照倒序排列的, 因此当读取这个文件时候,最先找到的是最近的版本。
(版本倒序排列我认可,可你妹的文件指针都是从头扫到尾啊。咋个意思???)
在一个 put 数据的时候 如果 有一个2015的当前数据。而我 put 一个 2014 年的 取得是15 还是14?
答:取得是15
3 HBase 如何从HMaster
找到 具体的某一行
答 首先从HBase 客户端 出请求
, HMaster 返回此rowkey 在那些

首先写:Client写入 写入到 LSM 内存中,LSM内存写到一定阈值后 -> 存入
MemStore
,一直到MemStore满 -> Flush成一个
StoreFile
,直至增长到一定阈值 -> 出发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile -> 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split 成2个
Region
,Region会下线,新Split出的2个子Region会被
HMaster
分配到相应的
HRegionServer
上,使得原先1个Region的压力得以分流到2个Region上由此过程可知,HBase只是增加数据,有所得更新和删除操作,都是在Compact阶段做的
《未完》
3 LSM树合并之后是几级树层次? 还有LSM树从内存中释放后, 他的节点树 会不会因为太大导致内存不够?。
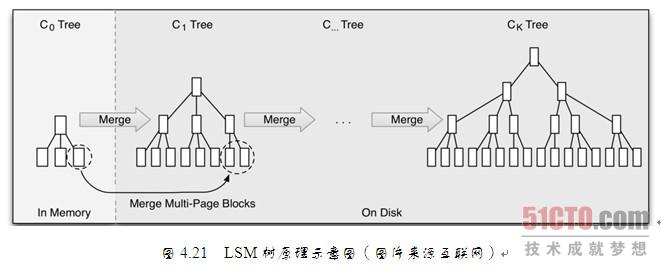
LSM合并之后是 : 一坨层次树,要根据设定的阈值来计算。
LSM树不会因为太大导致内存不够。LSM树从内存中释放后,数据便不复存在,相当于一颗大树到冬天把衣服(叶子)全
脱了,只留树干树枝。 占用的内存就少啦。















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









