






多模态大模型有许多经典的模型,如transformer, bert, vit, blip等等。transformer作为最基础、最重要的模型,掌握其结构以及相关细节知识是十分有必要。本系列将对于transformer进行简要介绍。
1.总体介绍
首先,直观的感受下transformer是做什么的。transformer可以用于翻译任务,如下图所示,将中文文本输入后,得到的输出是对应的英文翻译。
在这个过程中,可以看到有两个重要的部分,编码器encoder和解码器decoder。这里要注意的是,decoder是一个单词一个单词的输出的,最终得到整个翻译的结果,不是一个翻译句子整体一起输出。encoder可以理解为将 输入(中文文本)的特征 提取出来,decoder可以理解为,根据 输入的特征 和 已经输出的句子 的特征,得到 下一个要输出的单词 是什么。接下来,我们就要理解encoder和decoder分别是怎么实现的。
2. 注意力机制
在具体介绍encoder和decoder之前,首先需要介绍最重要的attention注意力机制。通过下图的transformer结构图可以发现在左右两边都有这个attention结构。
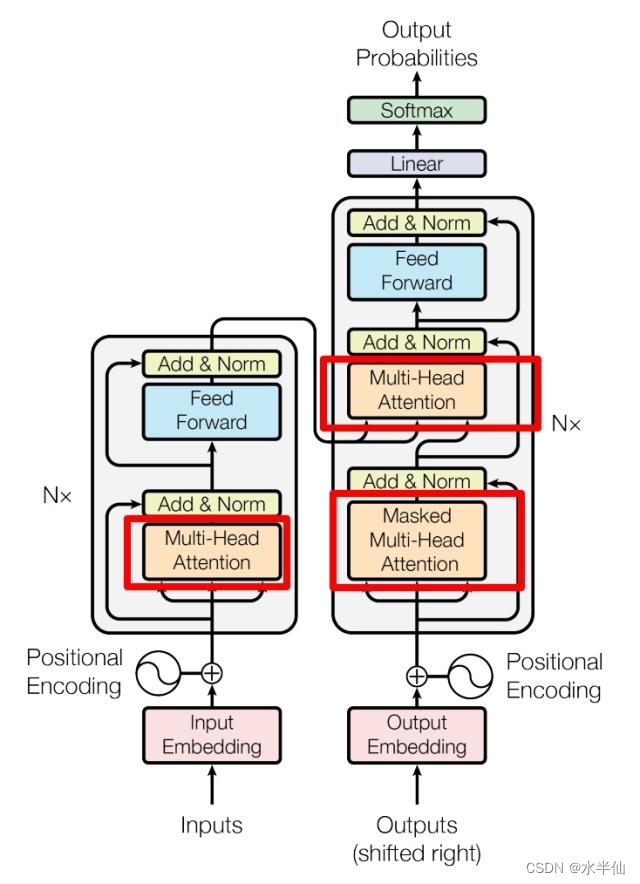
下面就要来理解attention是什么东西。由下图可以看到attention有q, k, v三个元素,q, k先做了些运算,然后这个结果再跟v做了运算,最终得到一个输出。
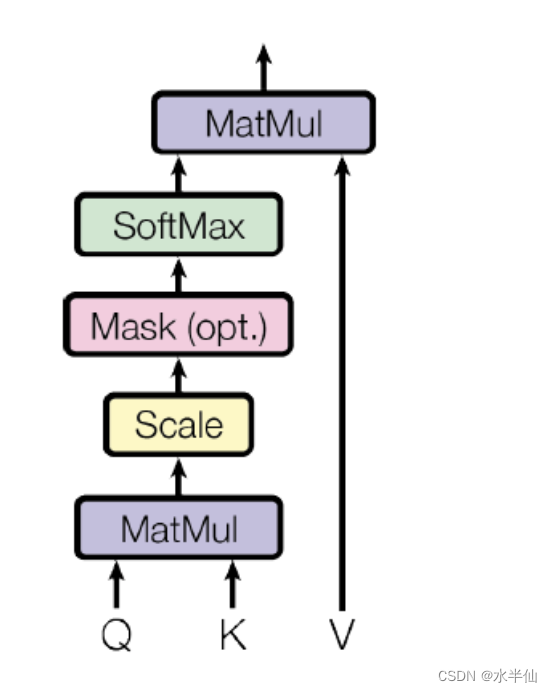
为了更好的理解,我们先看一个例子。假设在一个队伍中,有三个队员,张三、李四、王五(V),他们的身高分别是165、170、195(K)。现在我们想要找到与 身高172(Q)最接近的人。首先,肯定是先去拿 172(Q)跟每个队员的身高 165、170、195(K) 进行比较 (计算相似度),假设,相似度分别是0.2、0.7、0.1。但是只是给出这种计算的数值结果,我们还是不知道谁的身高最接近。所以,要把具体的人的信息(V)跟相似度结合起来。结果为:张三(0.2)、李四(0.7)、王五(0.1)。由此,我们可以知道想要找的人是李四(0.7)。
现在,我们到文本的情况下,再通过一个例子去理解。对于一句话,“Love is powerful beacuse it gives us hope to live.”对于这样的一个句子,我们希望模型能学习到什么?其实就是语义信息和句法信息。语义信息是指单词的意思,句法信息可以理解为语法,名词,动词,指代等等。
那模型怎么去学习呢?很简单,对于"love"(q)这个单词,把整个句子看一遍,看看love在句子里是什么意思,是怎么用的,跟句子里 每个单词(k) 的关系是什么。(q,k计算) 最终,学习到"love"是个名词,是“爱”的意思。love是powerful的,love是能给予hope的,等等。这样,当模型再去看这句话的时候,就能理解到love在其中的含义。(将学习到的信息和原来的句子v结合起来)。比如,在学习前,模型不知道 “it gives us hope to live” 中的it 是什么,通过学习,他知道是指love。
下图是表示对于某个单词,计算跟句子中单词之间的关系的示意图,可以参考。
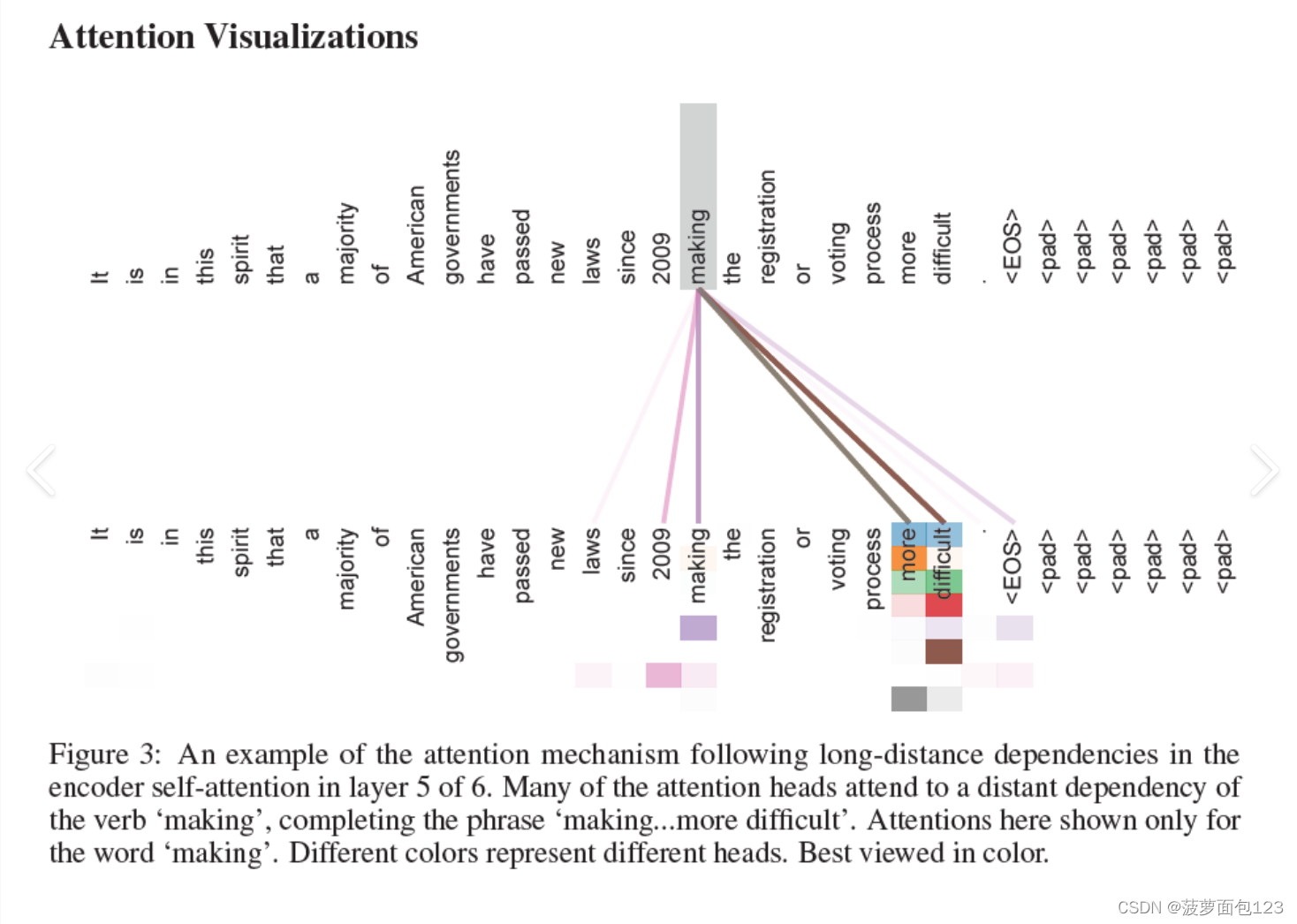
通过上面两个例子,我们对q,k,v有了一定直观的认识,接下来我们将再深入一些,探讨下attention注意力机制是如何实现的。对于这个简单的句子,“Thinking Machines”,看看模型是如何计算的。

(1)对于每个单词,肯定是不能输入thinking这种东西的,计算机只能理解数字。所以要通过一种方法(embeding),将单词(word)变成数值(vector)。这里会用到,embeding和位置编码,这里暂且不讲,以后会说。这一步就理解成将 人类理解的单词 变成 计算机理解的数字,即变成一种向量。x1就代表thinking, x2代表machines。
(2)得到q, k, v。q, k,v都是由第一步得到的x,通过不同的矩阵(wq, wk, wv)得到,可以理解为都蕴含了x的特征信息。
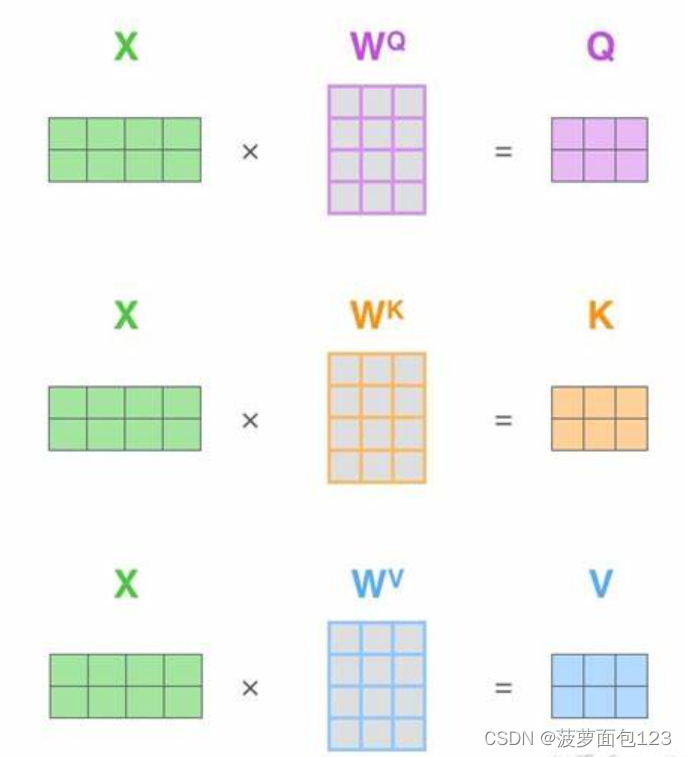
(3)学习q在句子中的意思。比如,这一步是要学习thinking在句子中的意思,所以我们拿thinking的q,去和句子中的每个单词的k相乘(包括thinking自己),得到注意力的分数,再通过缩放和softmax,得到注意力分数的概率。这里先不用管太多的细节,具体后面会说。可以就先类比成身高例子中,计算170跟每个身高的相似度。
(4)得到学习后的结果。在得到softmax结果后,与每个单词的v相乘,最后再求和,得到z。这个最终求和得到的值z,就是在把 注意力 放在thinking这个单词上,去理解这个句子的结果,蕴含了thinking这个单词,与句子里每个单词的联系,语义和句法特征等等。比如,对于“Love is powerful beacuse it gives us hope to live.”,在通过计算得到Love 的结果 z, 这个z就蕴含了love是名词,句子中it也是指的love,love能带来hope。现在这个z就代表了新的x,而原来的x是不懂这些的,只是代表love而已。
(5)对于句子中的其他单词,再进行上述的过程,进行学习、理解。最终的一系列z,就是在经过学习后,包含了语义和句法信息的x,而不再是一开始单纯的x了。
所以attention这一模块,其实就是把句子原本的x,经过学习,得到z。原来的x只是认识一个个单词,但这个z是经过良好教育的,是能够理解意图,理解语法,脱离了低级趣味,能够吟诗作赋的。
结语:这一篇先简单讲个attention吧。主要是概念上的理解,以后会逐步对具体细节进行解释。我觉得刚接触这些模型的时候,重要的先能明白模型的基本思路,细节的问题可以后续慢慢探究。
后续会继续更新encoder,decoder等其他模块。也许会做个transformer代码实现。我目前的打算是重点讲transformer,因为感觉这个是重中之重,后面的bert,gpt等等都是基于transformer来的。本人也只是刚开始学习这些内容而且也是第一次写博客,有讲的不对的地方,希望大家能够斧正,也欢迎有问题可以随时交流。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









