






一 MapReduce
1.MapReduce1 架构设计
Client: 客户端
JobTracker: 主要负责 资源监控管理和作业调度 。
a.监控所有TaskTracker 与job的健康状况,一旦发现失败,就将相应的任务转移到其他节点;
b.同时JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度
器会在资源出现空闲时,选择合适的任务使用这些资源.
TaskTracker:是JobTracker与Task之前的桥梁
a.从JobTracker接收并执行各种命令:运行任务、提交任务、 Kill任务、重新初始化任务;
b.周期性地通过心跳机制,将节点健康情况和资源使用情况、各个任务的进度和状态等汇报给
JobTracker.
Task Scheduler: 任务调度器(默认FIFO,先按照作业的优先级高低,再按照到达时间的先后选择被执
行的作业)
Map Task: 映射任务
Reduce Task: 归约任务 
2. MapReduce2 架构设计( Yarn工作流程(mr提交应用程序) )
1:用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
2:ResourceManager为该应用程序分配第一个Container, 并与对应的Node-Manager通信,要求它在这个Container中启动应用
程序的ApplicationMaster。
3:ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后
它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
4:ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
5:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
6:NodeManager为任务设置好运行环境(包括环境变量、 JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通
过运行该脚本启动任务。
7:各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行
状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序
的当前运行状态。
8:应用程序运行完成后, ApplicationMaster向ResourceManager注销并关闭自己。
当用户向YARN中提交一个应用程序后, YARN将分两个阶段运行该应用程序:
a. 第一个阶段是启动ApplicationMaster;
b. 第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。

3.mapreduce常用命令
mapred job :
[-kill <job-id>]
[-list [all]]
4.mapreduce的运行流程
1、向client端提交MapReduce job.
2、随后yarn的ResourceManager进行资源的分配.
3、由NodeManager进行加载与监控containers.
4、通过applicationMaster与ResourceManager进行资源的申请及状态的交互,由NodeManagers进行MapReduce运行时job的管理.
5、通过hdfs进行job配置文件、jar包的各节点分发。
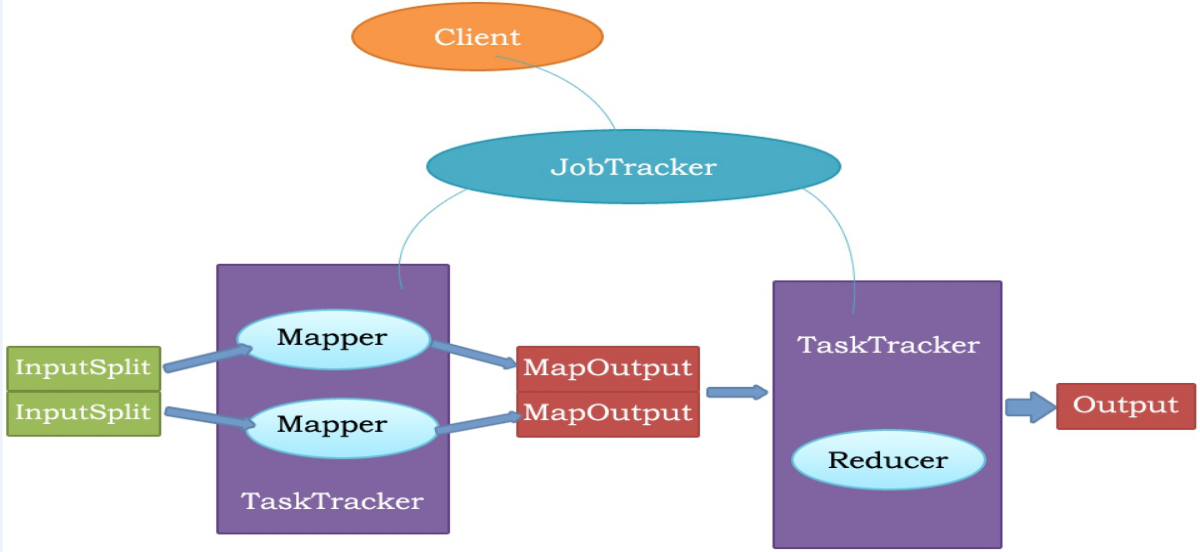
5.mapreduce的运行原理
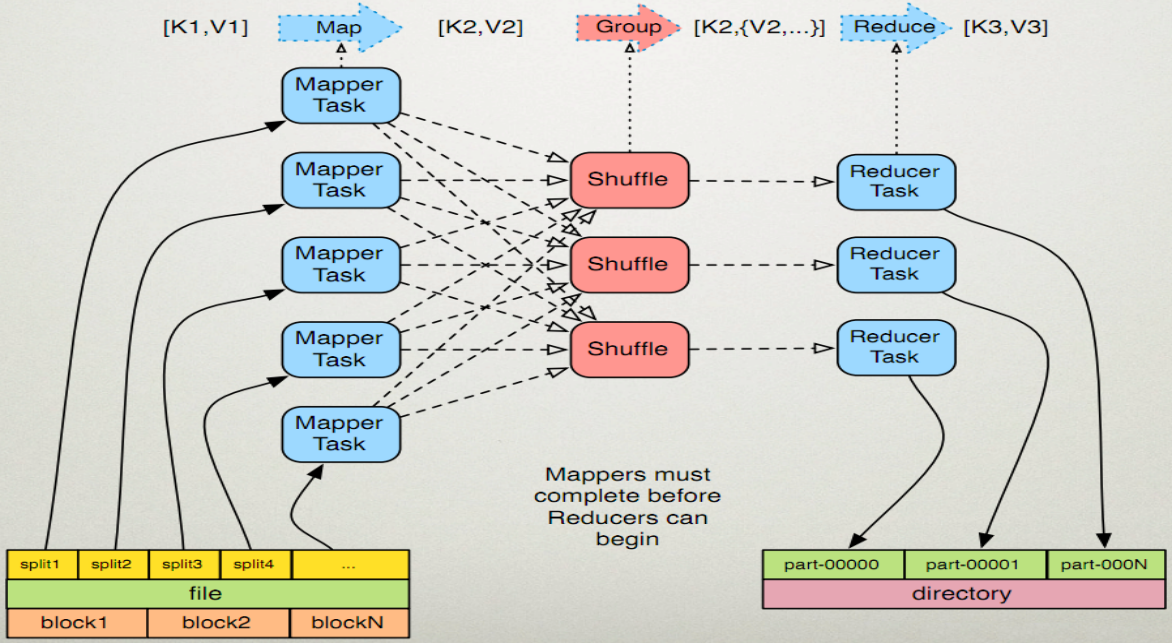
1、Map任务处理
读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。之后覆盖map(),接收前面产生的<k,v>,进行处理,转换为新的<k,v>输出。然后对输出的<k,v>进行分区。默认分为一个区。对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后, 分组 , 对分组后的数据进行归约。
2、Reduce任务处理
多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑 , 处理后,产生新的<k,v>输出。 对reduce输出的<k,v>写到HDFS中。
6. mapreduce的shuffle机制
mapreduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 mapreduce 框架中最关键的一个流程,这个流程就叫 shuffle ; 将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;

-
maptask 收集我们的 map() 方法输出的 kv 对,放到内存缓冲区中
-
从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
-
多个溢出文件会被合并成大的溢出文件
-
在溢出过程中,及合并的过程中,都要调用 partitoner 进行分组和针对 key 进行排序
-
reducetask 根据自己的分区号,去各个 maptask 机器上 取相应的结果分区数据
-
reducetask 会取到同一个分区的来自不同 maptask 的结果文件, reducetask 会将这些文件再进行合并(归并排序)
-
合并成大文件后, shuffle 的过程也就结束了,后面进入 reducetask 的逻辑运算过程(从文件中取出一个一个的键值对 group ,调用用户自定义的 reduce() 方法)
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁盘 io 的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整 , 参数: io.sort.mb 默认 100M
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31496956/viewspace-2199368/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31496956/viewspace-2199368/














 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









