






1.MapReduce是什么?
mapreduce是一个分布式计算编程框架
优点
- 易于编程。用户不需要考虑多个节点任务的分配,以及节点之间的沟通。
- 高容错性。能够把出现故障的节点的任务转交给其他节点完成。
- 高扩展性。可以通过添加节点数量提高,计算能力。
- 可以处理海量数据的计算
缺点
- 不能够实时处理数据。
- 不能够处理流式数据。
- 不适合处理有向无环图,就是不适合处理,一个任务的结果是另一个任务的开始条件。
2.MapReduce的编程思想?
mapreduce分为map阶段和reduce阶段,map阶段的并发maptask并行运行,互不干扰。
reduce阶段互不干扰,数据依赖于maptask实例的输出。
3.Mapreduce实例wordcount环境准备
1.设置maven依赖
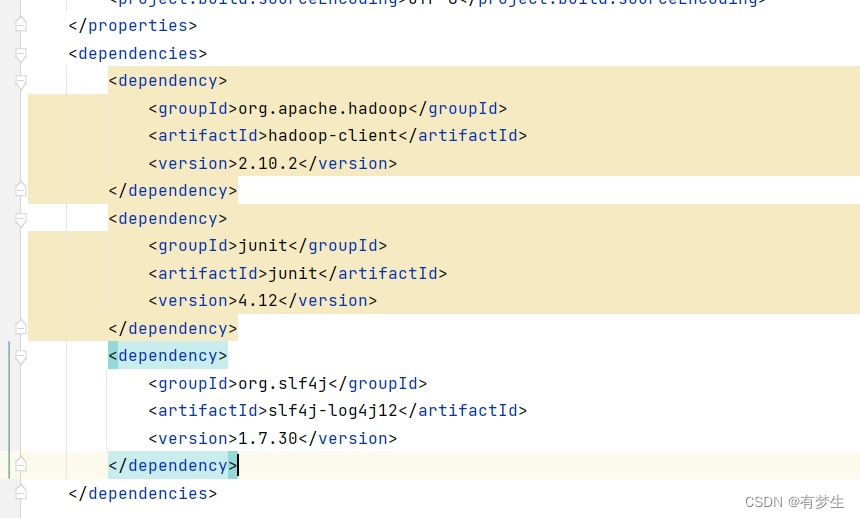
可以在终端,输入 hadoop version查看hadoop的版本。
2.创建三个类用来实现mapreduce的三部分功能
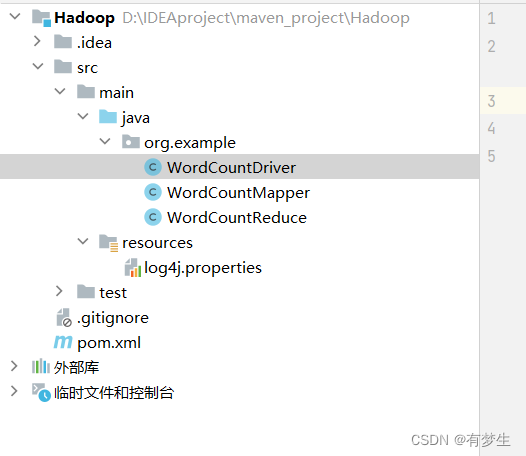
3.分别创建三个类的内容
Mapper类
package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//map中有两对键值对参数,根据问题设置参数类型
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text text = new Text();
private IntWritable outV=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取一行
String string = value.toString();
// 对一行数据按照空格切分
String[] s = string.split(" ");
// 循环写出
for(String word: s){
text.set(word);
// 使用context.write写出
context.write(text,outV);
}
}
}
Reduce类
package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable outV=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
// 统计出现次数
for(IntWritable val:values){
sum=sum+val.get();
}
outV.set(sum);
// 写出
context.write(key, outV);
}
}
Deriver类
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 创建job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 添加jar包路径
job.setJarByClass(WordCountDriver.class);
// 关联mapper和reduce
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 设置map阶段的输出键值对类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入路径输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
4.利用maven打包成jar包
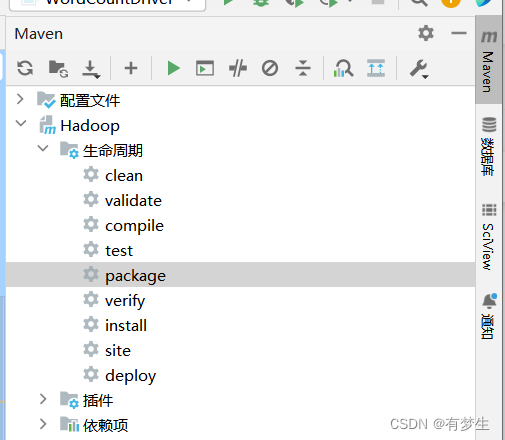
5.上传jar包
1.使用xftp把jar包放到/usr/local/hadoop目录下
2.要计算单词数目的txt文件上传到hdfs的/input目录
hdfs dfs -put hello.txt /input3.运行jar包
hadoop jar jar包名称 Deriver类的完整路径 /input /output4.在HDFS网页端查看运行结果
进入hadoop网页端:在浏览器地址栏输入
ip地址:50070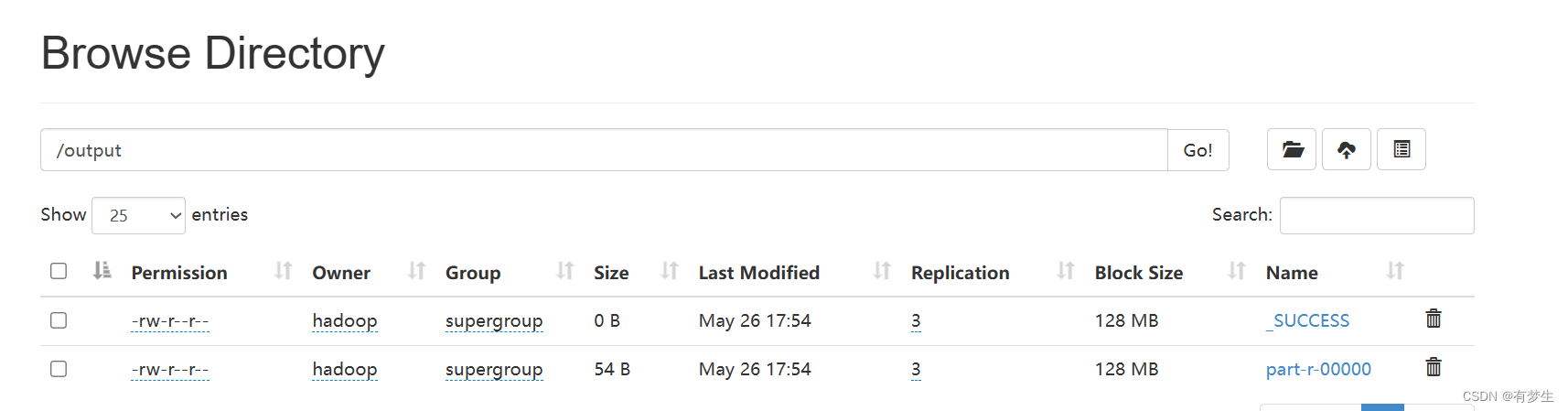
如果没有执行程序之前就有output目录,就会报错
//删除output目录
hdfs dfs -rm -r /output6.切片与并行度
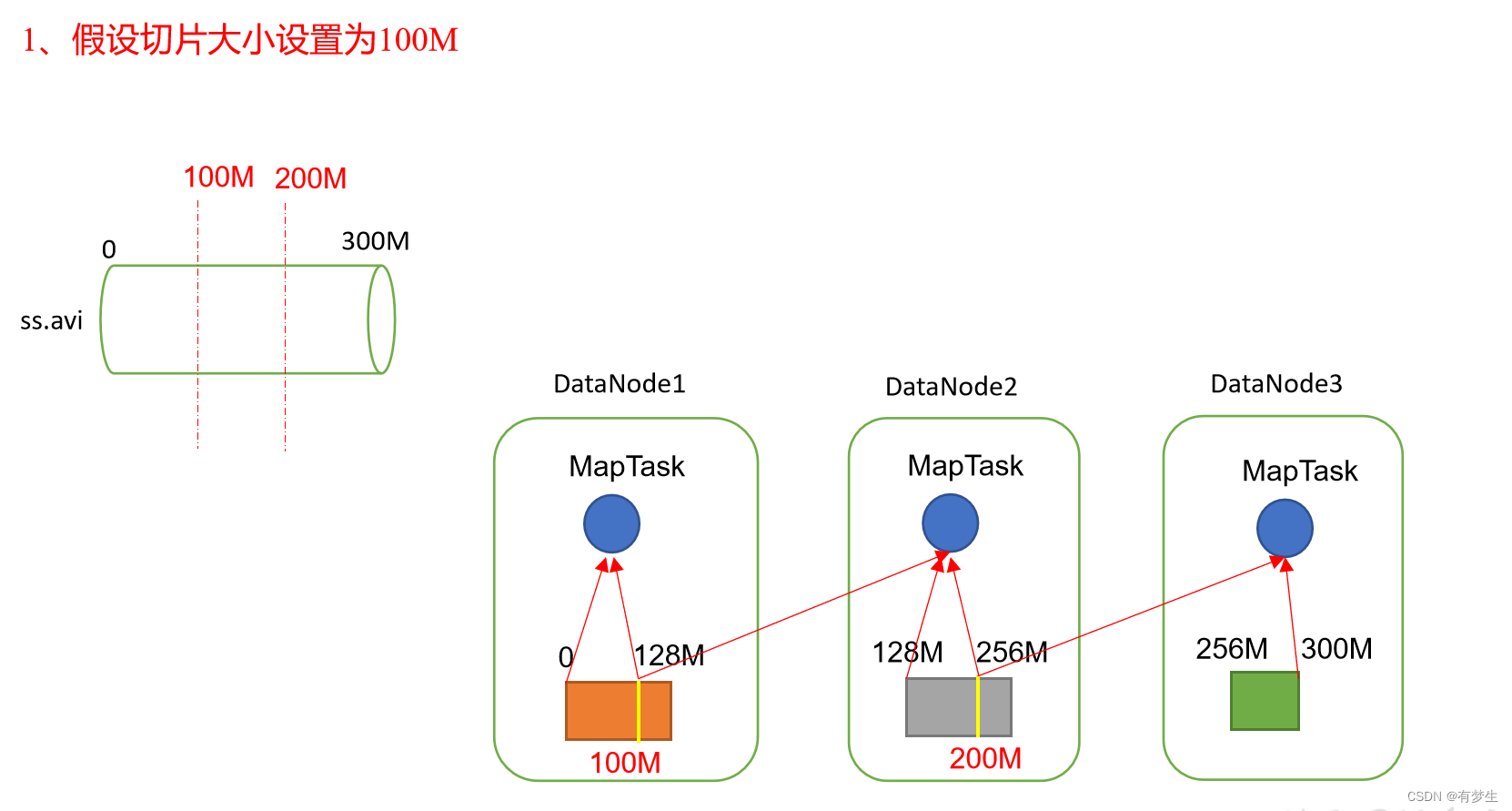
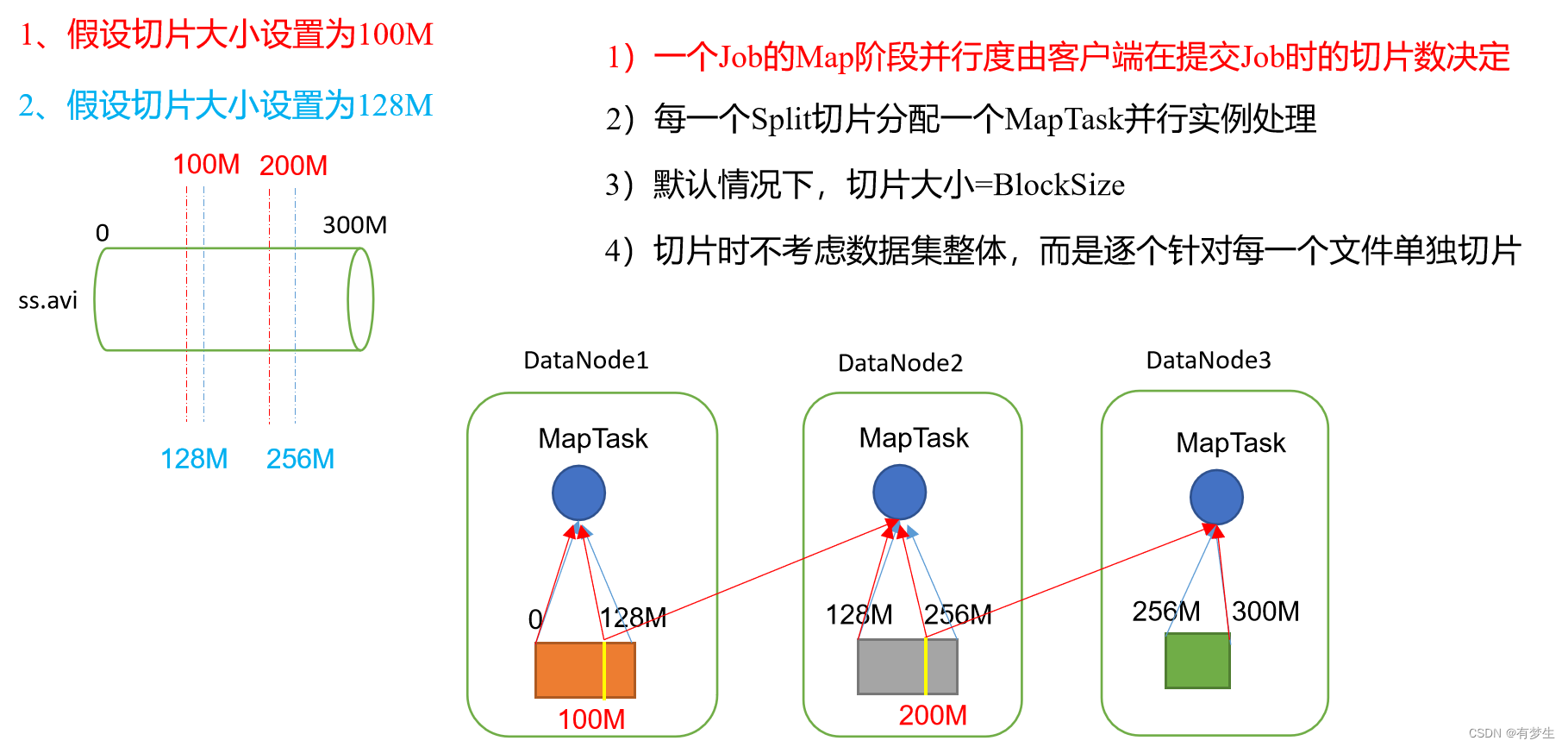
1.MapTask开启个数就是并行度
2.在HDFS中一个块的大小是128M,是把数据在物理上分成不同的块存储在不同的节点上。
3.分片是在逻辑上对数据进行划分,分片的大小一般是等于块大小,但是用户也可以修改分片的大小。
4.分片大小=块大小,可以减少节点联系其他节点获取块数据
6.2 TextInputFormat
TextInputFormat是FileInputFormat的实现类,按照文件进行切片,按行读取数据,键是字节索引LongWritable类型,值是一行内容Text类型。
6.3 CombineTextInputFormat
是把多个小文件合并成一个切片,有两个过程虚拟存储过程,切片过程
虚拟存储:把输入目录下多个文件的大小和setMaxInputSplitSize进行比较,如果小于则单独形成一个文件,如果大于max且小于2*max则分成两个文件,大于2*max,先按照最大值进行切分,判断剩余大小与max的关系如果大于max小于2*max则对半分。
切片过程:如果大于max则单独形成一个切片,如果小于max则与下一个文件形成一个切片。
7.MapReduce的执行流程
1.对原始数据进行切片,切片个数确定开启多少个maptask
2.向yarn提交job的相关信息(job.split:切片信息,jar包,job的相关参数)。
3.yarn开启Mrappmaster,Mrappmaster通过读取切片信息确定开启多少个maptask。
4.maptask使用InputFormat读取数据,InputFormat读取数据后生成 <k,v>把数据交给map( k,v)方法,map()方法把生成的<k,v>键值对数据,把数据输出到环形缓冲区(默认是100M的内存,一半存储索引,一半存储内存) 数据在环形缓冲区从起点开始向两侧写索引和数据写到80%时(索引+数据占据80M空间)停止写入数据,在环形缓冲区剩余20%的中间开始向两侧反向写数据和索引,同时把占据80M的数据进行溢写 产生多个多个溢写文件
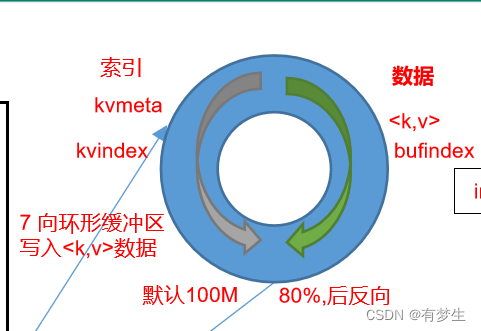
5.数据进入环形缓冲区之后会把数据进行分区,并在分区内部进行排序(当数据到达80%时再进行排序,排序方法是快排 ,对key的索引进行排序,按照字典顺序排)然后进行溢写形成溢写文件
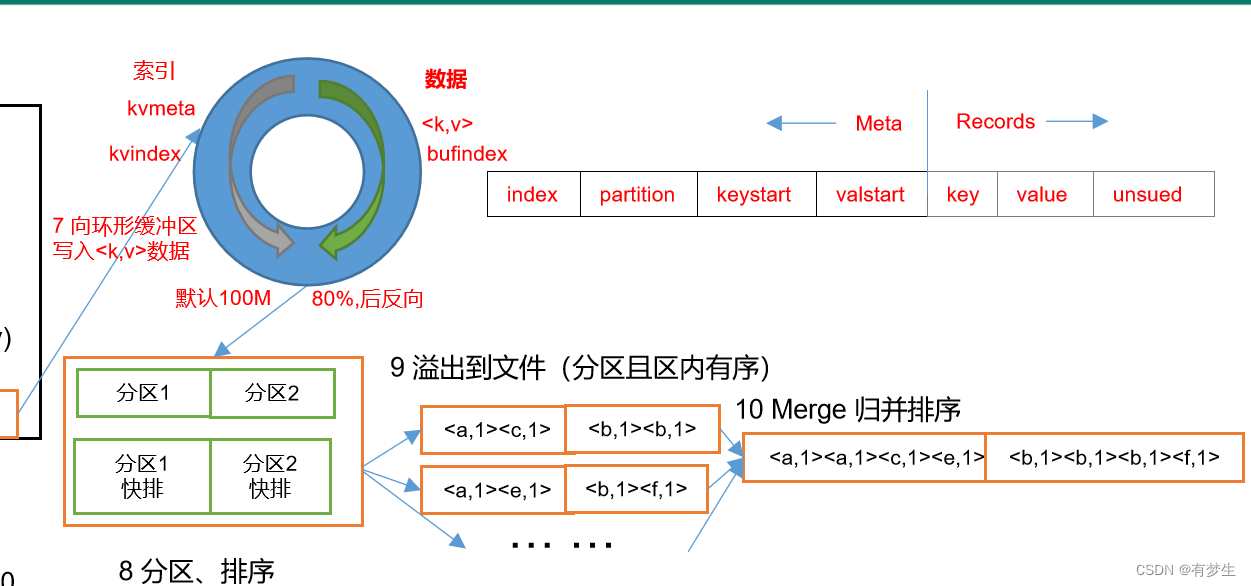 6.溢写会产生多个溢写文件(因为溢写文件的大小是80M,原始数据如果远大于80M,每进行一次溢写就会产生一个溢写文件),根据分区对文件进行归并排序 (对已经有序的文件进行排序)保证每个分区内部有序,放到磁盘上。
6.溢写会产生多个溢写文件(因为溢写文件的大小是80M,原始数据如果远大于80M,每进行一次溢写就会产生一个溢写文件),根据分区对文件进行归并排序 (对已经有序的文件进行排序)保证每个分区内部有序,放到磁盘上。
7. Mrappmaster在MapTask任务完成后(如果maptask的数量多的话可以先将一部分已经完成的maptask的结果合并交给reducetask)启动reducetask(有多少个分区就开启多少个reducetask),相同分区的数据在同一个reducetask 。
8.然后在对数据合并文件,然后归并排序,最后把数据交给reduce()方法。
9.reduce()方法处理完毕之后使用outputFormat方法写到结果文件
8.Shuffe机制
1.shuffe是从map()之后reduce()方法之前的过程
8.1分区
分区在输出结果目录中就是多个文件。
自定义分区:
1.创建一个类继承partitioner< >类,重写getPartition()方法
2.在job驱动内设置自定义partitioner
job.setPartitionerClass(CustomPartitioner.class)3.根据partition的个数设置redtask的个数
job.setNumReduceTasks(5)分区总结:
如果reducetask的个数大于分区个数:会产生几个空文件。
reducetask的个数大于一但小于分区个数:会报错。
reducetask的个数=1,不论有多少个分区都只会形成一个文件。
9.序列化和反序列化
序列化:就是把内存中的对象转换成字节序列 便于存储到磁盘和网络传输。
反序列化:把收到的字节序列转换成内存中的对象。
常用的基本序列化类型无法满足需要,所以需要实现一个对象的序列化
要求是:实现Writable接口,重写序列化和反序列化方法,重写toString()方法。
10.自定义排序
对象作为key进行传输需要,设置自定义排序
1.实现WriteComparable接口
2.重写comparaTo()方法。
comparaTo实现正序排列
public class Person implements Comparable<Person> {
private int age;
// 省略構造方法和其他方法
@Override
public int compareTo(Person p) {
return this.age - p.getAge();
}
}
comparaTo实现倒序排列
public class Person implements Comparable<Person> {
private int age;
// 省略構造方法和其他方法
@Override
public int compareTo(Person p) {
// 倒序排列,直接取相反數即可
return p.getAge() - this.age;
}
}
自我理解就是:如果comparaTo()如果返回正数,则当前数放到比较数的上面,否则放到比较数的下面。















 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









