目录 引言 零样本学习与少样本学习的概念 零样本学习(Zero-Shot Learning, ZSL) 少样本学习(Few-Shot Learning, FSL) 零样本学习与少样本学习的技术手段 零样本学习技术 类别描述 属性学习 跨模态学习 少样本学习技术 元学习 数据增强 迁移学习 应用场景 自然语言处理 计算机视觉 音频处理 注意事项 数据质量 模型复杂度 持续优化 用户体验 结论 引言 随着人工智能技术的飞速发展,大模型在自然语言处理(NLP&#x








 超级会员免费看
超级会员免费看
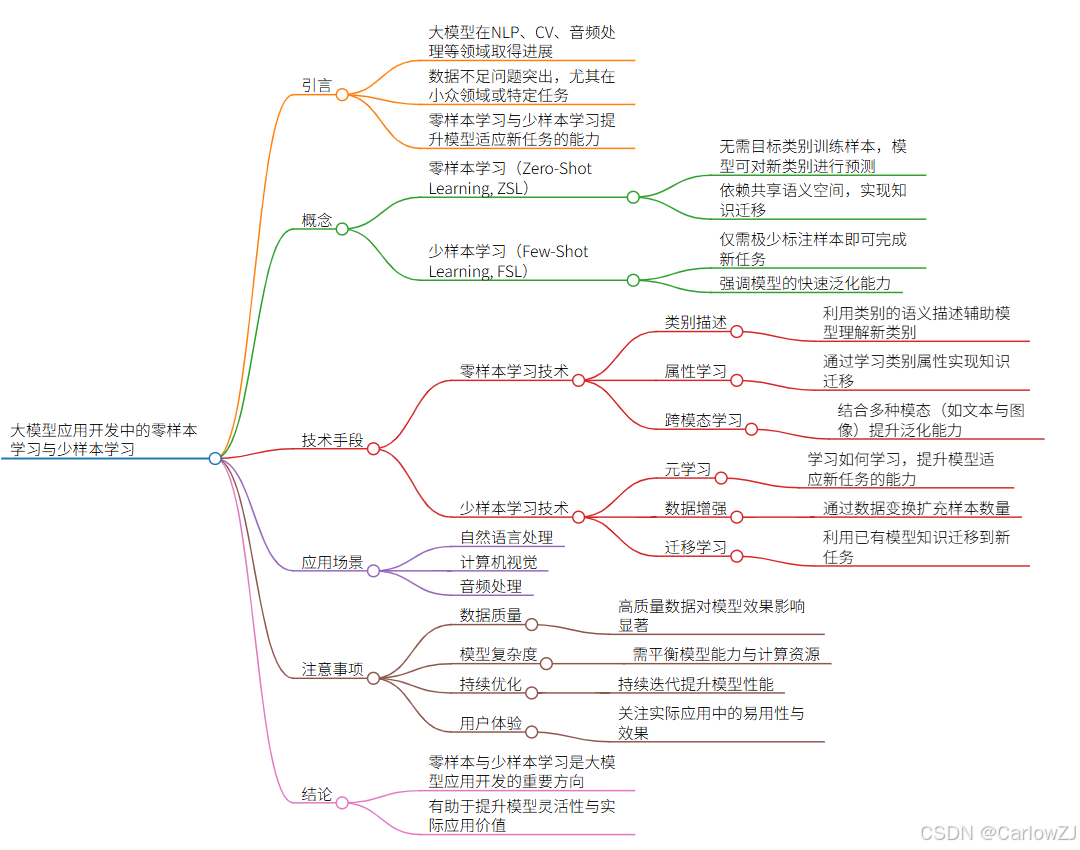 目录
目录


 引言
引言
 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








