






目录
一、引言
(一)多模态融合的背景与意义
随着人工智能技术的飞速发展,单一模态的数据处理已经无法满足复杂场景下的需求。例如,在智能驾驶中,仅靠图像识别无法完全理解道路环境,还需要结合语音指令和文本信息。多模态融合技术应运而生,它通过整合多种模态的数据(如图像、视频、音频、文本等),使模型能够更全面地理解和处理复杂场景。
(二)多模态融合的定义
多模态融合是指将来自不同模态的数据(如视觉、听觉、文本等)进行整合,以提升模型对复杂场景的理解和决策能力。多模态融合的目标是通过跨模态的协同学习,使模型能够更好地适应多样化的任务需求。
二、多模态融合的概念
(一)多模态数据的类型
多模态数据通常包括以下几种类型:
-
图像数据:如照片、图表等。
-
视频数据:如监控视频、电影片段等。
-
音频数据:如语音、音乐等。
-
文本数据:如句子、段落等。
(二)多模态融合的方法
多模态融合的方法可以分为以下几类:
-
早期融合(Early Fusion):在数据预处理阶段将不同模态的数据合并,然后输入到模型中。
-
中期融合(Intermediate Fusion):在特征提取阶段将不同模态的特征进行融合。
-
晚期融合(Late Fusion):在模型的输出阶段将不同模态的结果进行融合。
三、多模态融合的应用场景
(一)智能驾驶
在智能驾驶场景中,多模态融合可以结合摄像头图像、雷达信号、语音指令等多种数据,帮助自动驾驶系统更全面地感知环境。
(二)智能客服
在智能客服场景中,多模态融合可以结合语音识别、文本对话和用户画像等多种数据,提升客服系统的响应能力和用户体验。
(三)内容创作
在内容创作场景中,多模态融合可以结合图像、视频和文本等多种数据,帮助创作者生成更丰富、更具吸引力的内容。
四、多模态融合的实现方法
(一)数据准备
多模态融合的第一步是数据准备,需要收集和整理不同模态的数据,并确保它们之间的对齐和一致性。
(二)模型选择
选择适合多模态融合的模型架构是关键。常见的模型包括Transformer、CLIP等,这些模型能够处理多种模态的数据。
(三)训练与优化
在训练过程中,需要设计合理的损失函数和优化策略,以确保模型能够从多模态数据中学习到有效的特征。
五、代码示例
(一)多模态数据处理
以下是一个基于Python的多模态数据处理代码示例:
import json
import cv2
import numpy as np
# 加载文本数据
with open('text_data.json', 'r', encoding='utf-8') as f:
text_data = json.load(f)
# 加载图像数据
image_path = 'image_data/image1.jpg'
image = cv2.imread(image_path)
# 将图像数据转换为numpy数组
image_array = np.array(image)
# 打印数据
print("Text Data:", text_data)
print("Image Shape:", image_array.shape)(二)多模态模型训练
以下是一个基于Hugging Face Transformers库的多模态模型训练代码示例:
from transformers import AutoModelForVisionTextDualEncoder, AutoTokenizer, AutoFeatureExtractor
from datasets import load_dataset
# 加载预训练模型
model_name = "clip-italian/clip-italian"
model = AutoModelForVisionTextDualEncoder.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
# 加载数据集
dataset = load_dataset("path_to_your_dataset")
# 数据预处理
def preprocess_function(examples):
text = tokenizer(examples["text"], truncation=True)
images = feature_extractor(examples["image"], return_tensors="pt")
return {"text": text, "images": images}
encoded_dataset = dataset.map(preprocess_function, batched=True)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
num_train_epochs=3,
weight_decay=0.01,
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset["validation"],
)
# 开始训练
trainer.train()六、多模态融合的注意事项
(一)数据预处理
多模态数据的预处理是关键步骤,需要确保不同模态的数据能够对齐和融合。例如,图像和文本数据需要进行标准化处理。
(二)模型架构设计
选择合适的模型架构是多模态融合成功的关键。需要考虑模型的复杂度和计算资源的需求。
(三)性能评估
多模态融合模型的性能评估需要综合考虑不同模态的贡献。可以使用多模态数据集进行验证和测试。
七、架构图与流程图
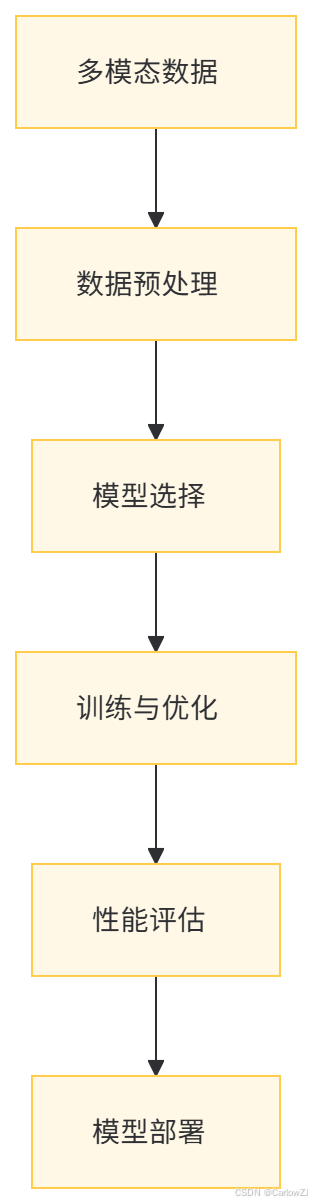
(一)架构图
以下是一个多模态融合的整体架构图:
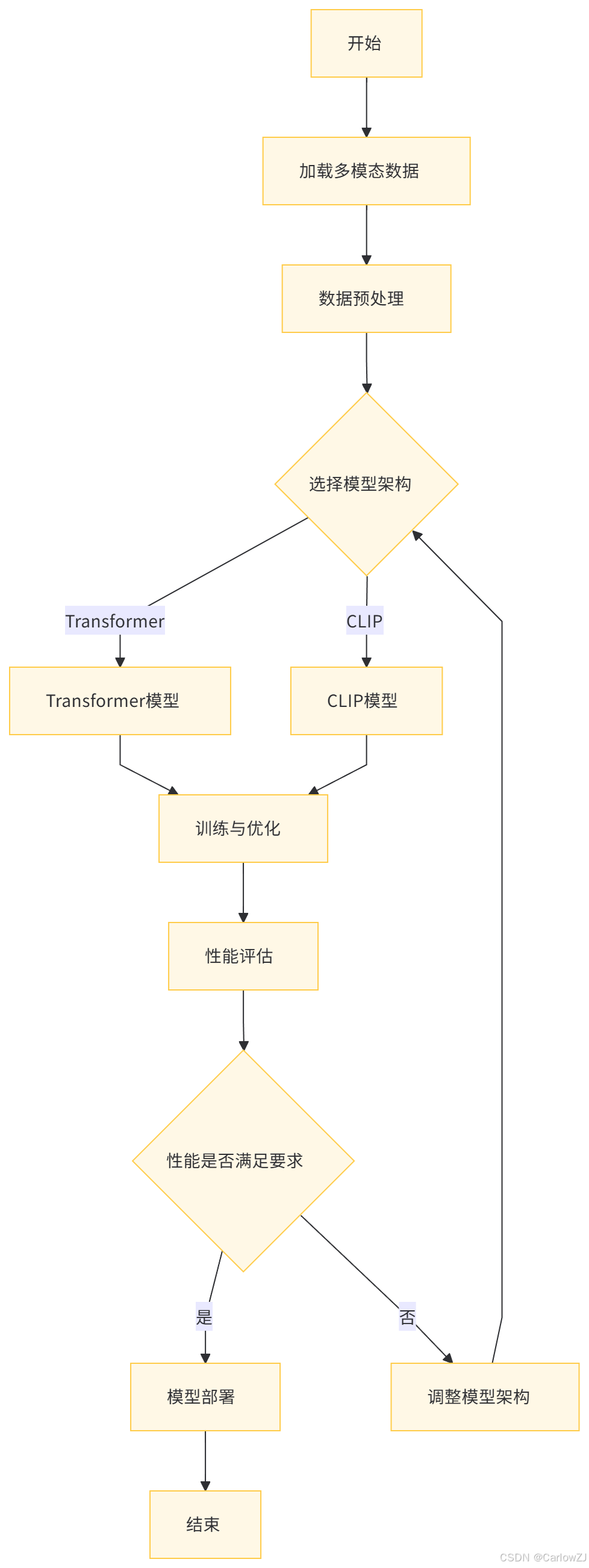
(二)流程图
以下是一个多模态融合的详细流程图:
八、总结
多模态融合技术是人工智能领域的重要发展方向之一,它通过整合多种模态的数据,提升了模型对复杂场景的理解和决策能力。本文详细介绍了多模态融合的概念、应用场景、实现方法、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。希望本文对您有所帮助!如果您有任何问题或建议,欢迎在评论区留言。
在未来的文章中,我们将继续深入探讨大语言模型的更多高级技术,如强化学习、联邦学习等,敬请期待!
九、参考文献
-
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
-
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901.
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











