






目录
一、引言
(一)多模态与强化学习的结合背景
随着人工智能技术的快速发展,单一模态的数据处理已经无法满足复杂场景下的需求。例如,在智能驾驶中,仅靠图像识别无法完全理解道路环境,还需要结合语音指令和文本信息。多模态融合技术应运而生,它通过整合多种模态的数据(如图像、视频、音频、文本等),使模型能够更全面地理解和处理复杂场景。与此同时,强化学习作为一种通过试错学习来最大化累积奖励的方法,也在许多领域取得了显著的成果。将多模态融合与强化学习结合起来,可以进一步提升模型在复杂环境中的决策能力和适应性。
(二)多模态强化学习的定义
多模态强化学习是指在强化学习框架中,结合多模态数据(如图像、音频、文本等),让智能体在复杂环境中进行试错学习,以最大化累积奖励。多模态强化学习的目标是通过跨模态的协同学习,使模型能够更好地适应多样化的任务需求。
二、多模态强化学习的基本概念
(一)多模态数据的类型
多模态数据通常包括以下几种类型:
-
图像数据:如照片、图表等。
-
视频数据:如监控视频、电影片段等。
-
音频数据:如语音、音乐等。
-
文本数据:如句子、段落等。
(二)强化学习的关键组件
-
智能体(Agent):学习和决策的主体。
-
环境(Environment):智能体所处的外部环境,提供反馈和奖励。
-
状态(State):智能体在环境中的当前情况。
-
动作(Action):智能体在环境中可以采取的行为。
-
奖励(Reward):环境对智能体行为的反馈,用于指导智能体的学习。
-
策略(Policy):智能体选择动作的规则。
-
价值函数(Value Function):评估状态或动作的长期价值。
三、多模态强化学习的实现方法
(一)环境设计
环境设计是多模态强化学习的关键步骤之一。需要定义清晰的状态、动作和奖励机制,以引导模型的学习。在多模态环境中,状态可以包括多种模态的数据,例如图像、音频和文本。
(二)策略网络与价值网络
策略网络用于选择动作,价值网络用于评估状态或动作的价值。在多模态强化学习中,策略网络和价值网络通常需要处理多模态输入。可以通过早期融合、中期融合或晚期融合的方法将多模态数据整合到网络中。
(三)多模态数据融合
多模态数据融合是多模态强化学习的核心。可以通过以下几种方法实现:
-
早期融合(Early Fusion):在数据预处理阶段将不同模态的数据合并,然后输入到模型中。
-
中期融合(Intermediate Fusion):在特征提取阶段将不同模态的特征进行融合。
-
晚期融合(Late Fusion):在模型的输出阶段将不同模态的结果进行融合。
四、代码示例
(一)多模态环境搭建
以下是一个基于Python的多模态环境搭建代码示例:
import numpy as np
import cv2
import librosa
class MultiModalEnvironment:
def __init__(self):
self.image_state = np.random.rand(64, 64, 3) # 示例图像状态
self.audio_state = np.random.rand(16000) # 示例音频状态
self.text_state = "示例文本状态" # 示例文本状态
def reset(self):
self.image_state = np.random.rand(64, 64, 3)
self.audio_state = np.random.rand(16000)
self.text_state = "新的示例文本状态"
return self.get_state()
def step(self, action):
reward = np.random.rand() # 示例奖励
done = np.random.choice([True, False], p=[0.1, 0.9]) # 示例终止条件
self.image_state = np.random.rand(64, 64, 3)
self.audio_state = np.random.rand(16000)
self.text_state = "更新的示例文本状态"
return self.get_state(), reward, done
def get_state(self):
return {
"image": self.image_state,
"audio": self.audio_state,
"text": self.text_state
}
# 测试环境
env = MultiModalEnvironment()
state = env.reset()
print("初始状态:", state)
next_state, reward, done = env.step(0)
print("下一步状态:", next_state)
print("奖励:", reward)
print("是否终止:", done)(二)多模态强化学习训练
以下是一个基于PyTorch的多模态强化学习训练代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义多模态策略网络
class MultiModalPolicyNetwork(nn.Module):
def __init__(self):
super(MultiModalPolicyNetwork, self).__init__()
self.image_encoder = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten()
)
self.audio_encoder = nn.Sequential(
nn.Conv1d(1, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2),
nn.Flatten()
)
self.text_encoder = nn.Sequential(
nn.Embedding(10000, 128), # 示例文本嵌入
nn.LSTM(128, 128, batch_first=True),
nn.Flatten()
)
self.fc = nn.Sequential(
nn.Linear(128 * 3, 64),
nn.ReLU(),
nn.Linear(64, 4) # 示例动作空间大小为4
)
def forward(self, image, audio, text):
image_features = self.image_encoder(image)
audio_features = self.audio_encoder(audio)
text_features = self.text_encoder(text)
combined_features = torch.cat((image_features, audio_features, text_features), dim=1)
action_logits = self.fc(combined_features)
return action_logits
# 初始化网络和优化器
policy_net = MultiModalPolicyNetwork()
optimizer = optim.Adam(policy_net.parameters(), lr=1e-4)
# 训练循环
for episode in range(100):
state = env.reset()
done = False
while not done:
image = torch.tensor(state["image"], dtype=torch.float32).unsqueeze(0)
audio = torch.tensor(state["audio"], dtype=torch.float32).unsqueeze(0).unsqueeze(0)
text = torch.tensor([ord(c) for c in state["text"][:10]], dtype=torch.long).unsqueeze(0)
action_logits = policy_net(image, audio, text)
action = torch.argmax(action_logits)
next_state, reward, done = env.step(action.item())
optimizer.zero_grad()
loss = -reward * action_logits[action]
loss.backward()
optimizer.step()
state = next_state
print(f"Episode {episode + 1}, Loss: {loss.item()}")五、多模态强化学习的应用场景
(一)智能驾驶
在智能驾驶场景中,多模态强化学习可以结合摄像头图像、雷达信号、语音指令等多种数据,帮助自动驾驶系统更全面地感知环境并做出最优决策。
(二)智能机器人
在智能机器人场景中,多模态强化学习可以结合视觉、听觉和触觉等多种模态的数据,帮助机器人更好地理解和适应复杂的环境。
(三)智能教育
在智能教育场景中,多模态强化学习可以结合视频、音频和文本等多种模态的数据,帮助教育系统更好地理解学生的需求并提供个性化的教学内容。
六、多模态强化学习的注意事项
(一)数据预处理
多模态数据的预处理是关键步骤,需要确保不同模态的数据能够对齐和融合。例如,图像和音频数据需要进行标准化处理,文本数据需要进行分词和嵌入处理。
(二)模型架构设计
选择合适的模型架构是多模态强化学习成功的关键。需要考虑模型的复杂度和计算资源的需求。例如,可以使用Transformer架构处理文本数据,使用CNN架构处理图像数据。
(三)性能评估与调试
多模态强化学习模型的性能评估需要综合考虑不同模态的贡献。可以使用多模态数据集进行验证和测试,以确保模型的泛化能力。调试过程中需要仔细分析模型的行为和性能。
七、架构图与流程图
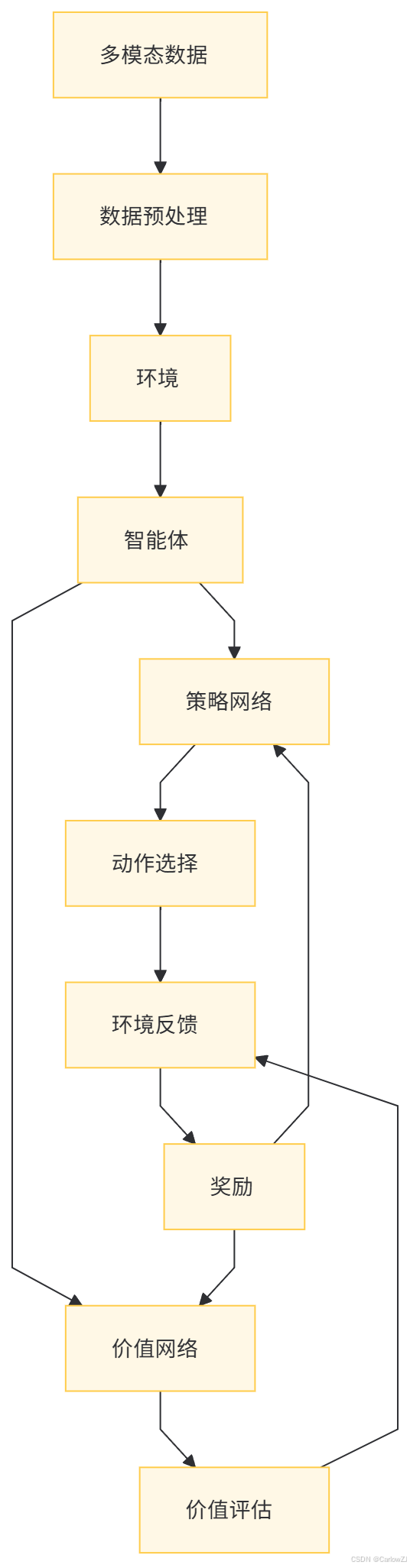
(一)架构图
以下是一个多模态强化学习的整体架构图:
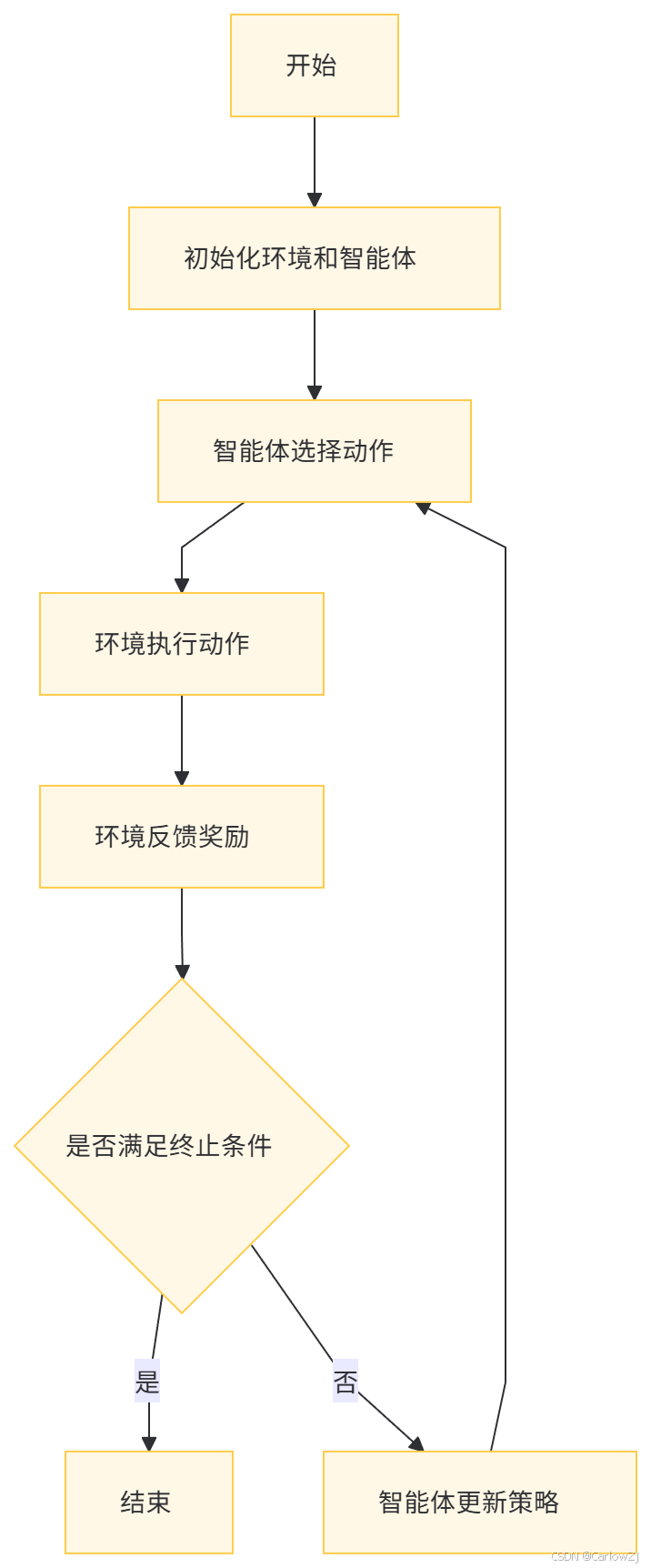
(二)流程图
以下是一个多模态强化学习的详细流程图:
八、总结
多模态强化学习是大语言模型训练中的重要技术之一,它通过结合多模态数据和强化学习,显著提升了模型在复杂环境中的决策能力和适应性。本文详细介绍了多模态强化学习的基本概念、应用场景、实现方法、代码示例以及注意事项,并通过架构图和流程图帮助读者更好地理解整个过程。希望本文对您有所帮助!如果您有任何问题或建议,欢迎在评论区留言。
在未来的文章中,我们将继续深入探讨大语言模型的更多高级技术,如联邦学习、多模态融合等,敬请期待!
九、参考文献
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
-
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing Atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
-
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., ... & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











